Downloaded 24 times
![Automatic Assessment of Failure Recovery in Erlang Applications Jan Henry Nyström [email_address]](https://image.slidesharecdn.com/erlangfactoryhenry2009-090721091541-phpapp02/75/Automatic-Assessment-of-Failure-Recovery-in-Erlang-Applications-1-2048.jpg)


























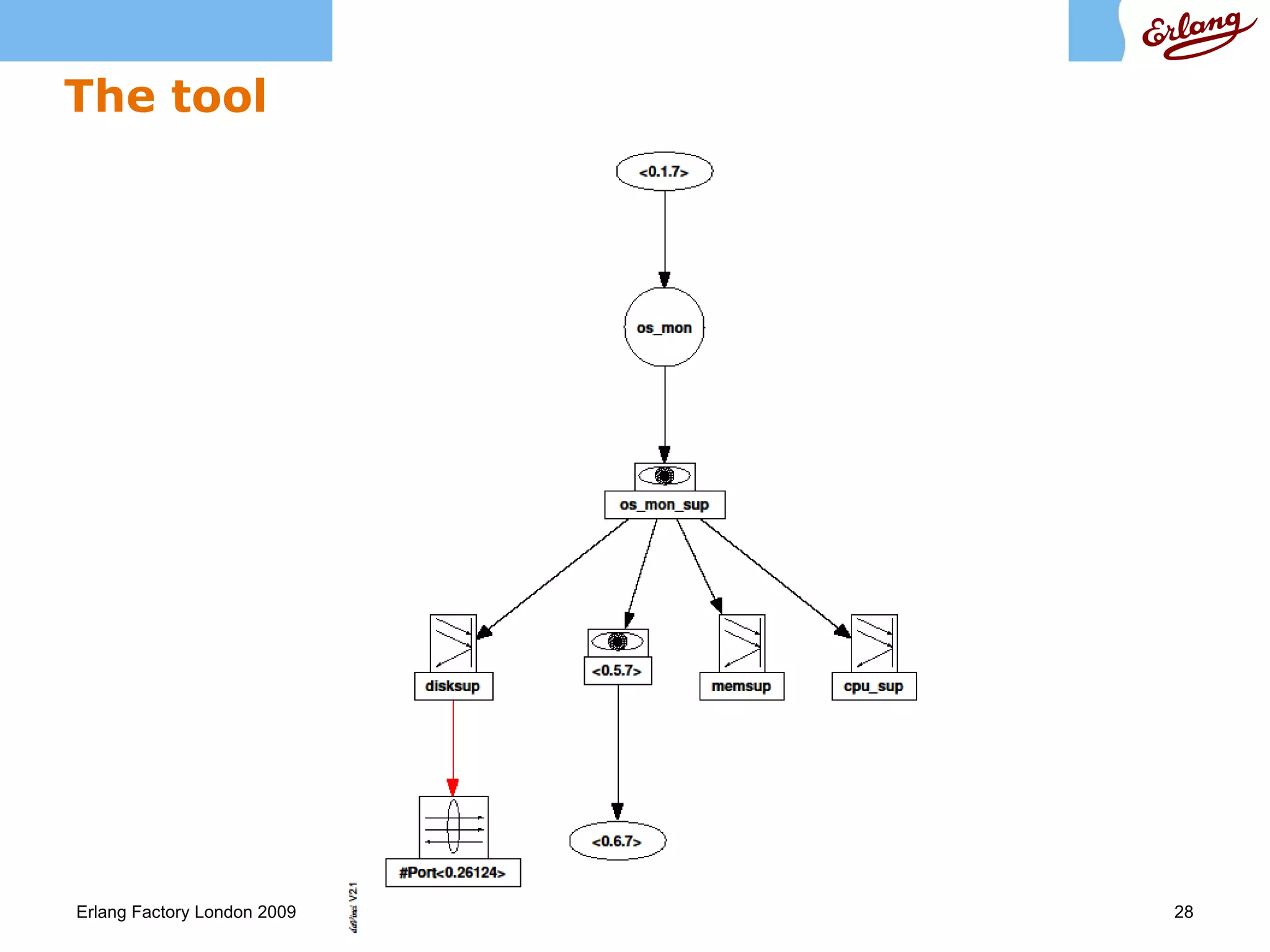


The document discusses fault tolerance in Erlang applications and proposes a tool to extract supervision structures from Erlang code. It explains that fault tolerance is achieved through process supervision hierarchies and restarting failed processes. The tool analyzes Erlang applications and outputs supervision structures to help understand fault tolerance properties. The structures can be inspected manually or animated to reason about properties like repair and non-concealment. The tool is work-in-progress but has been used to analyze some OTP applications.

























































