Download as PDF, PPTX




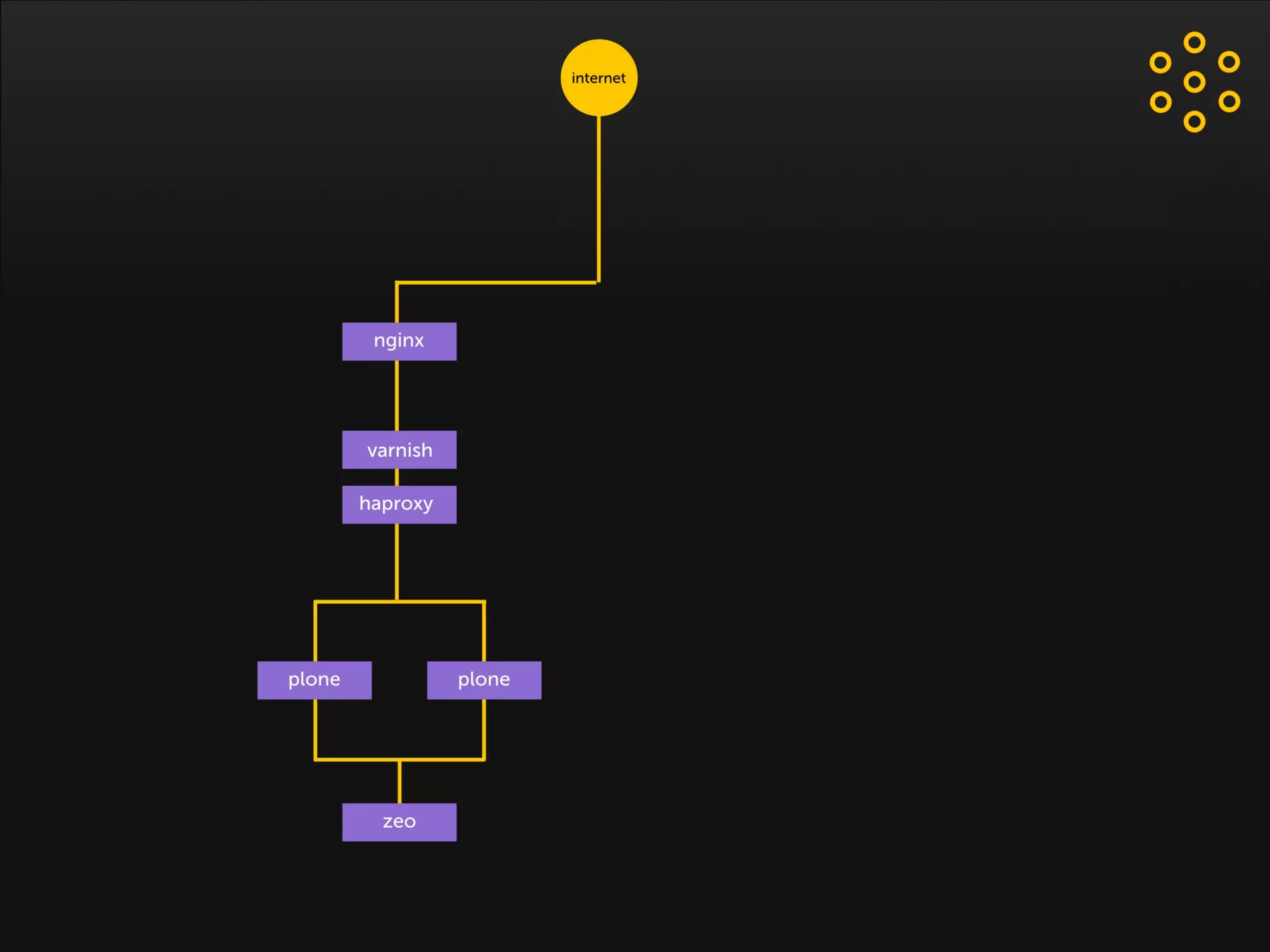
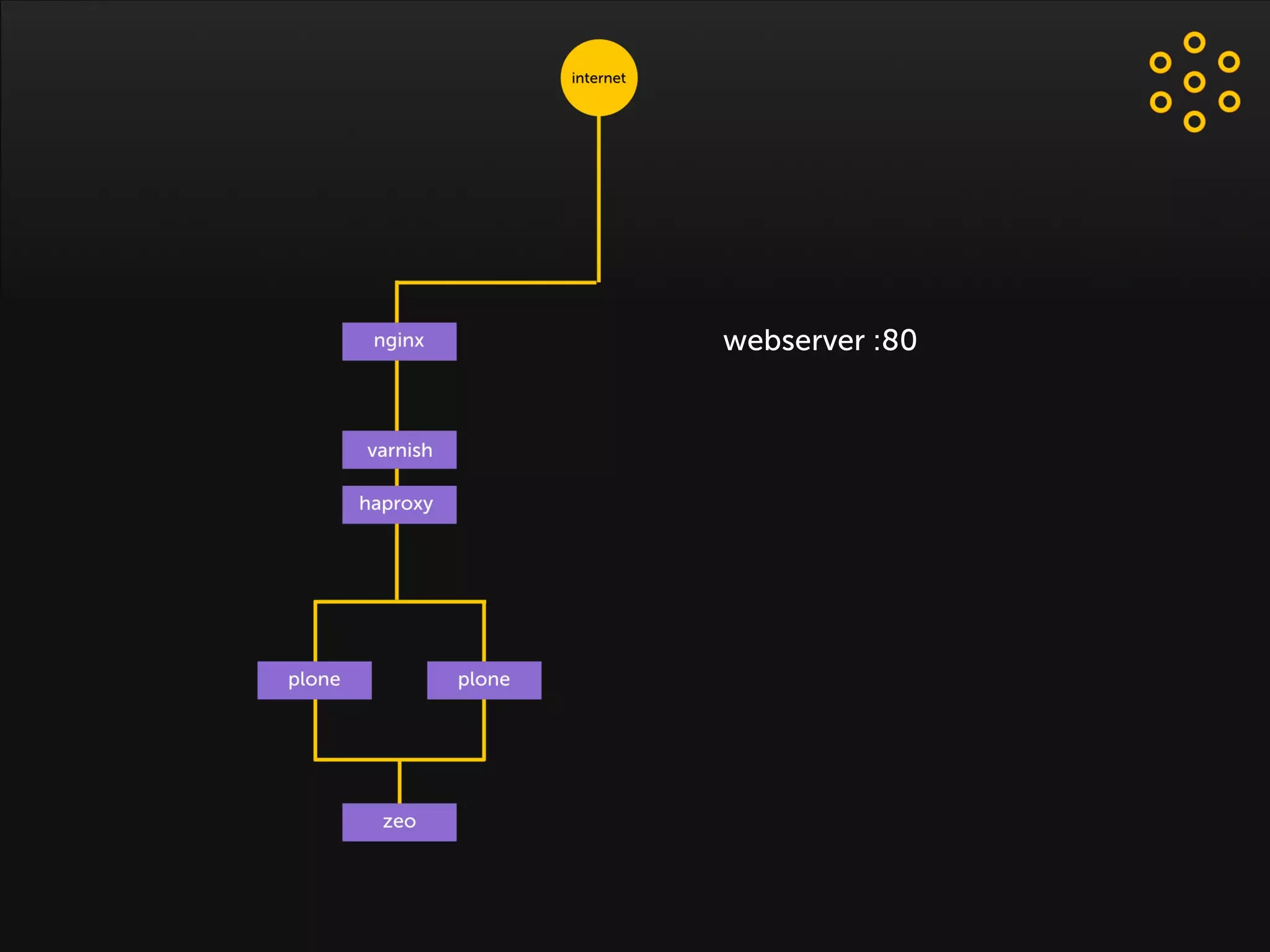
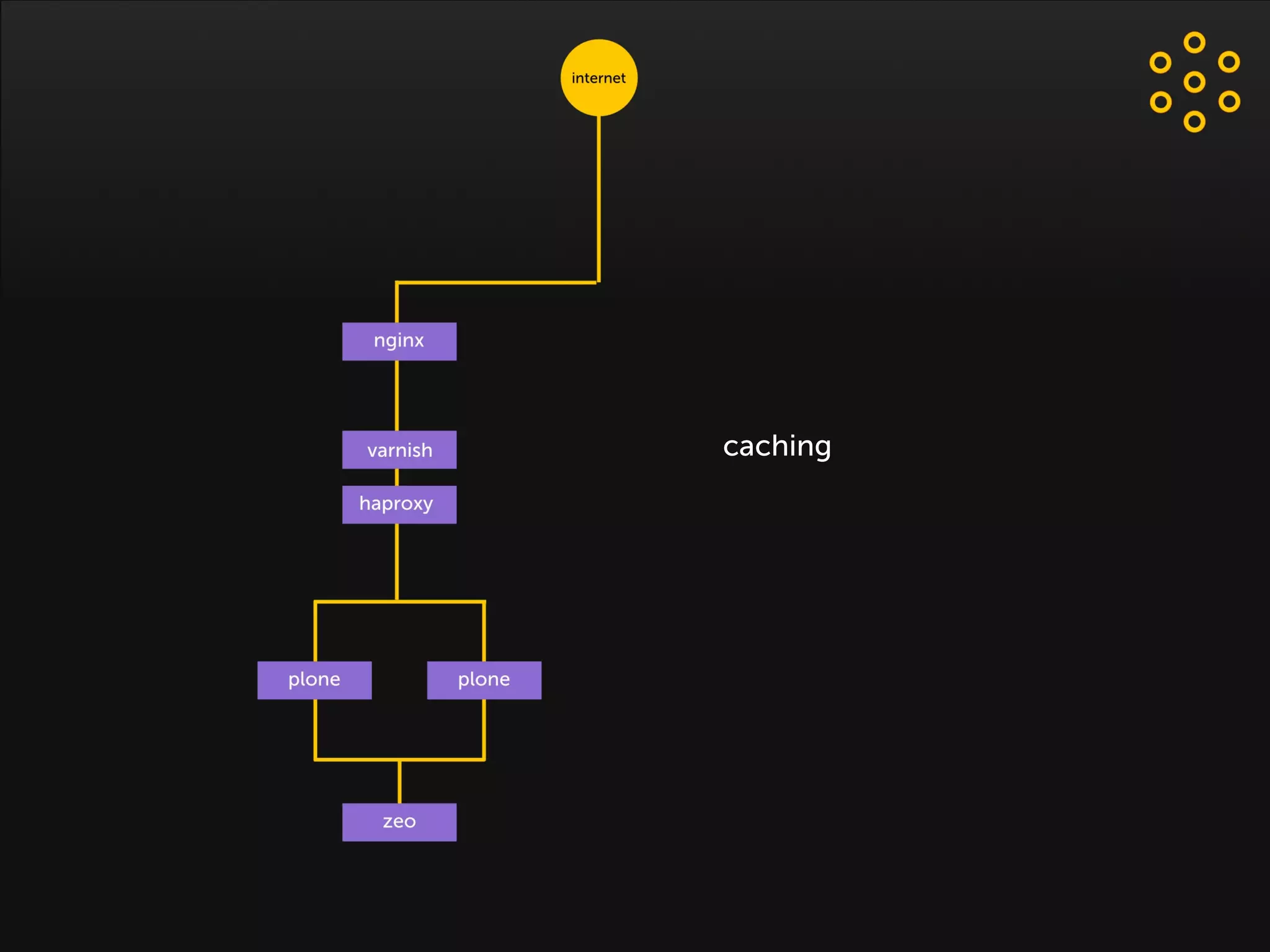
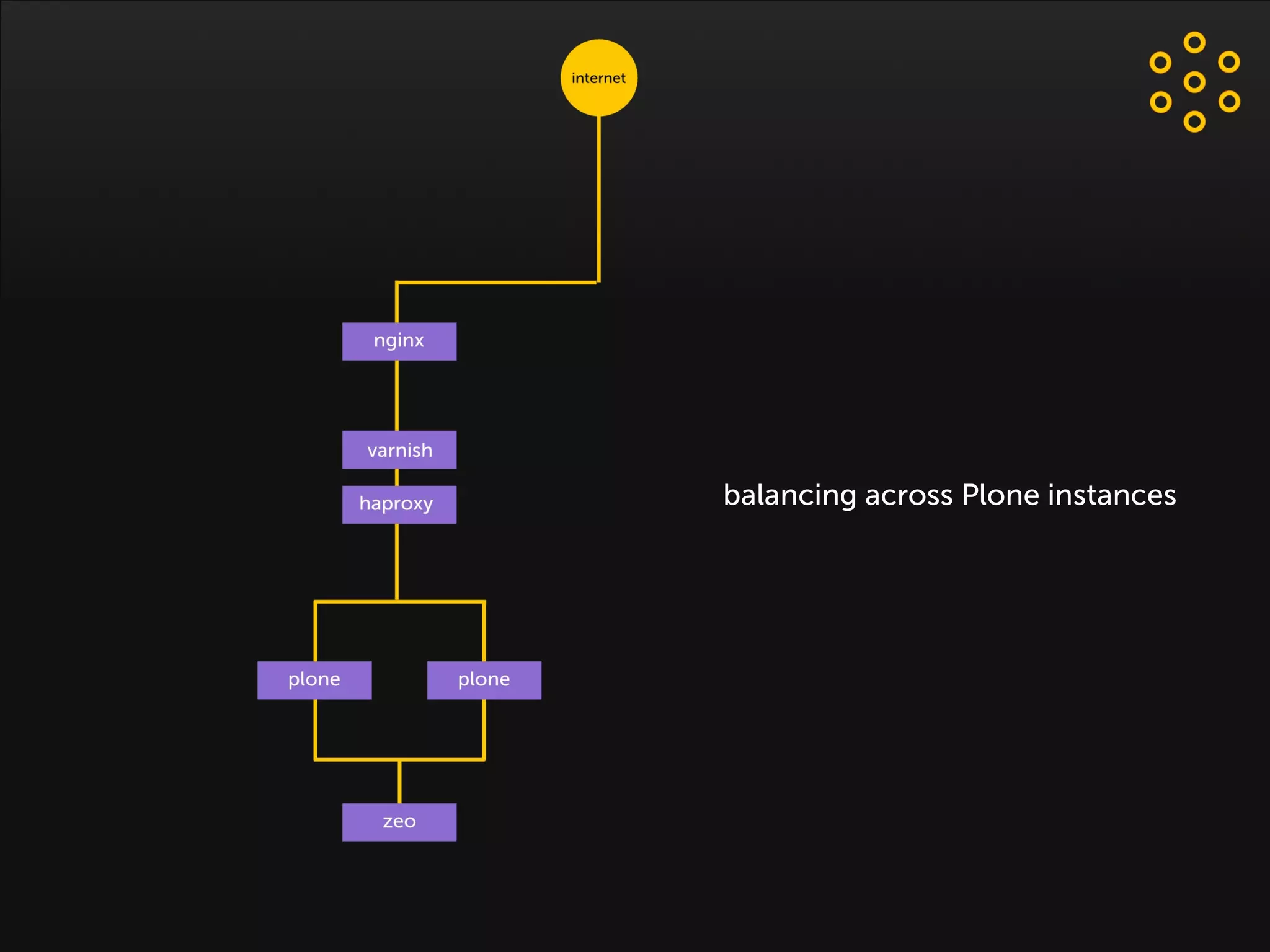
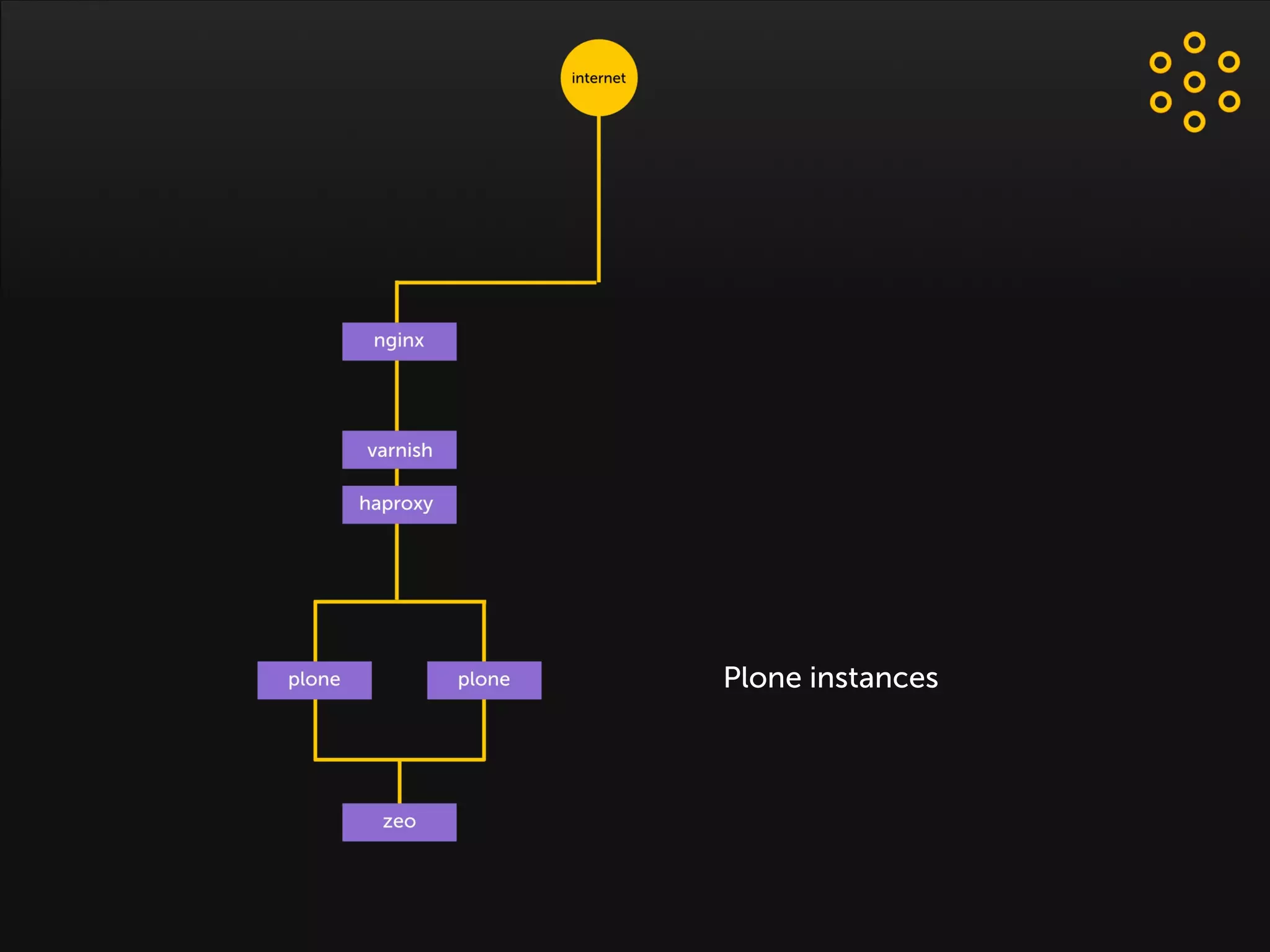
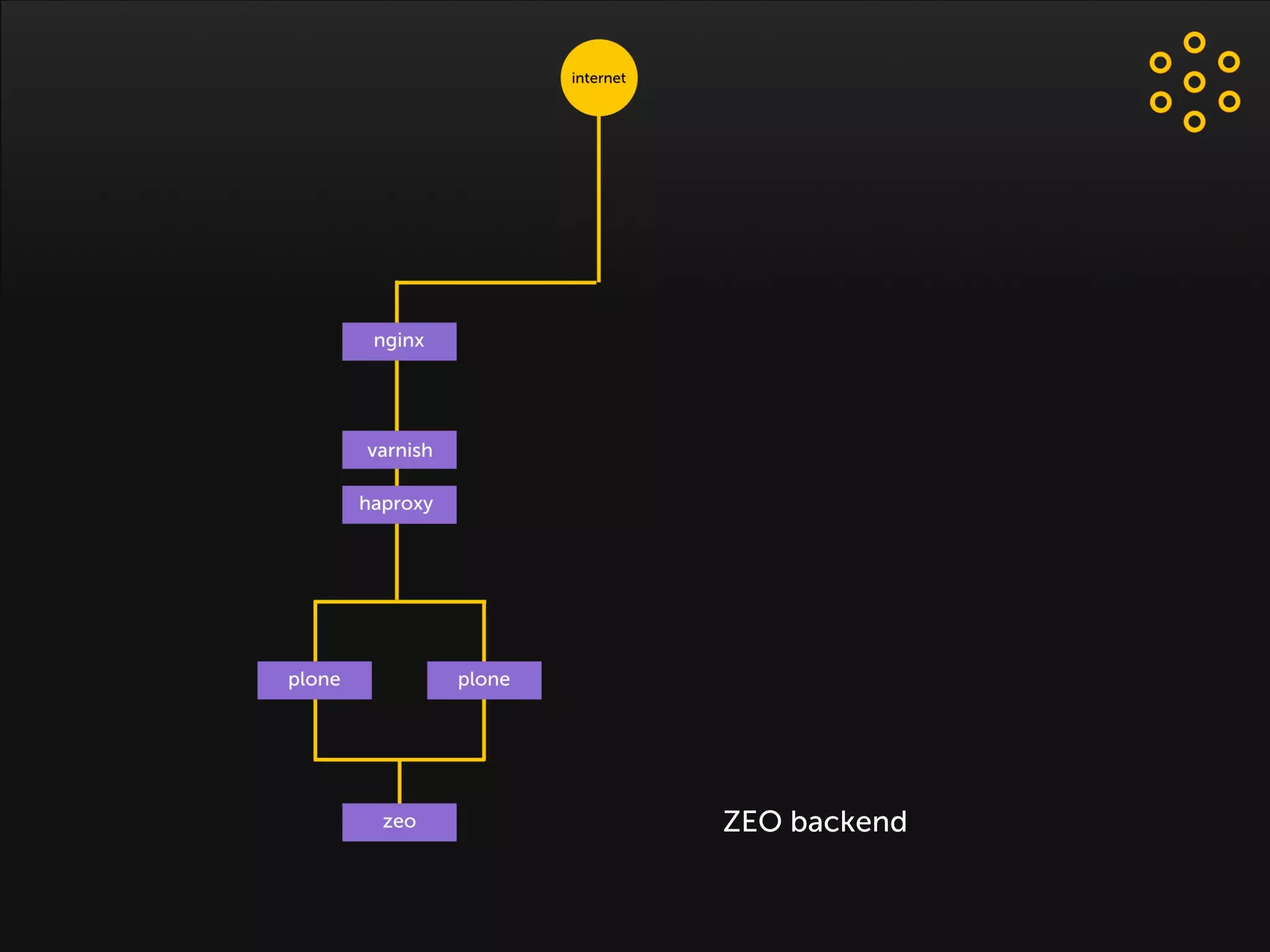

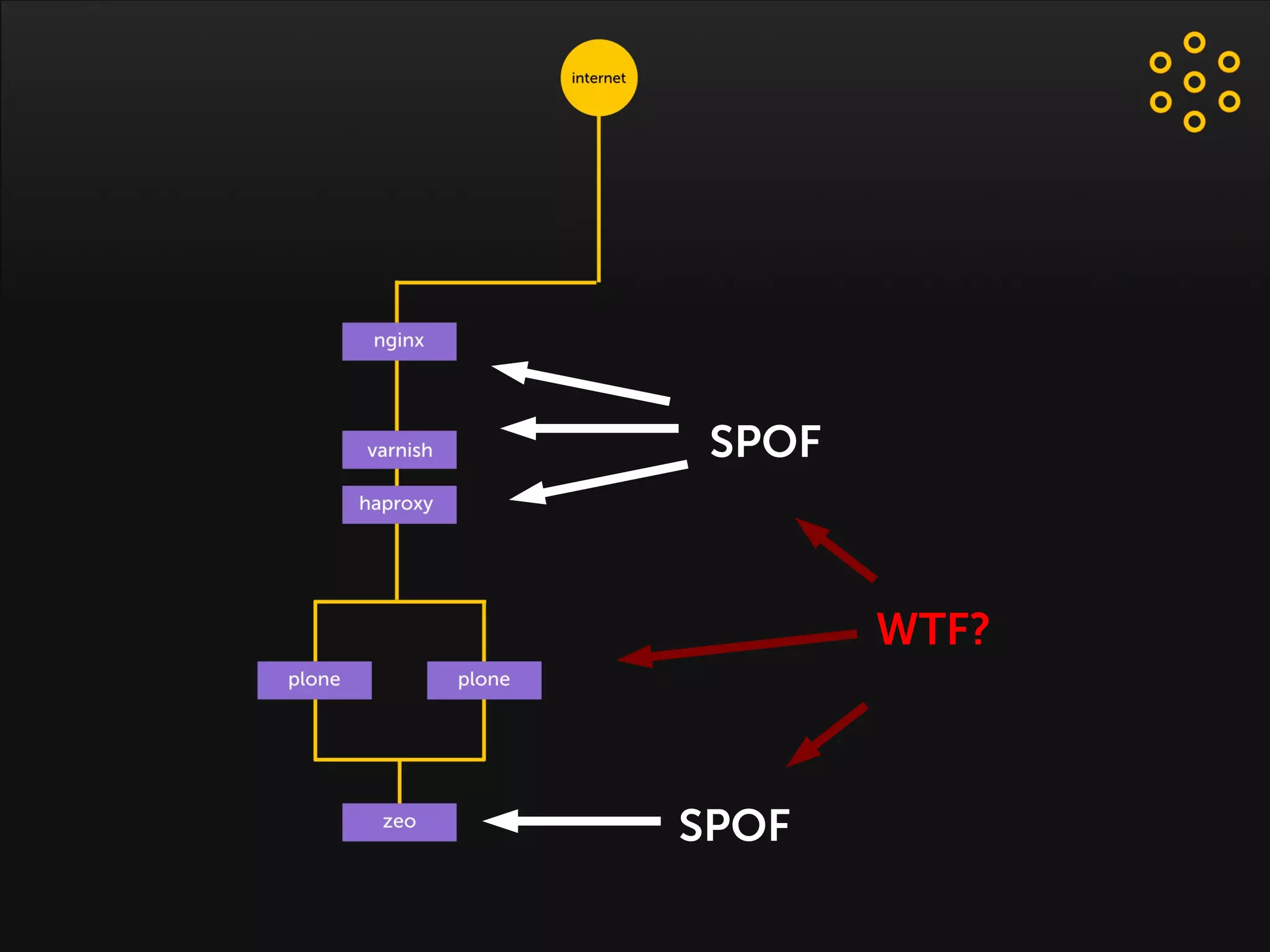


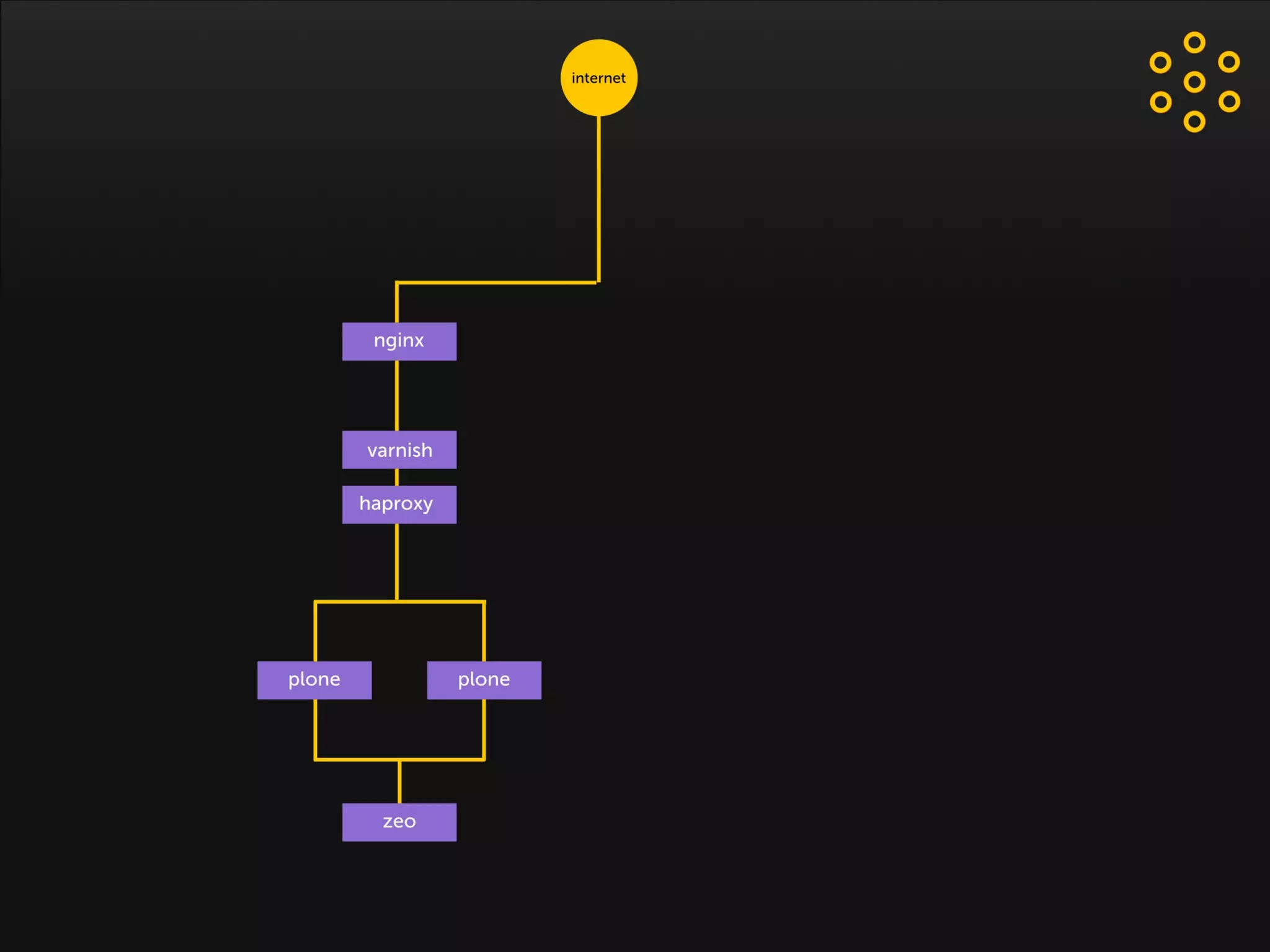
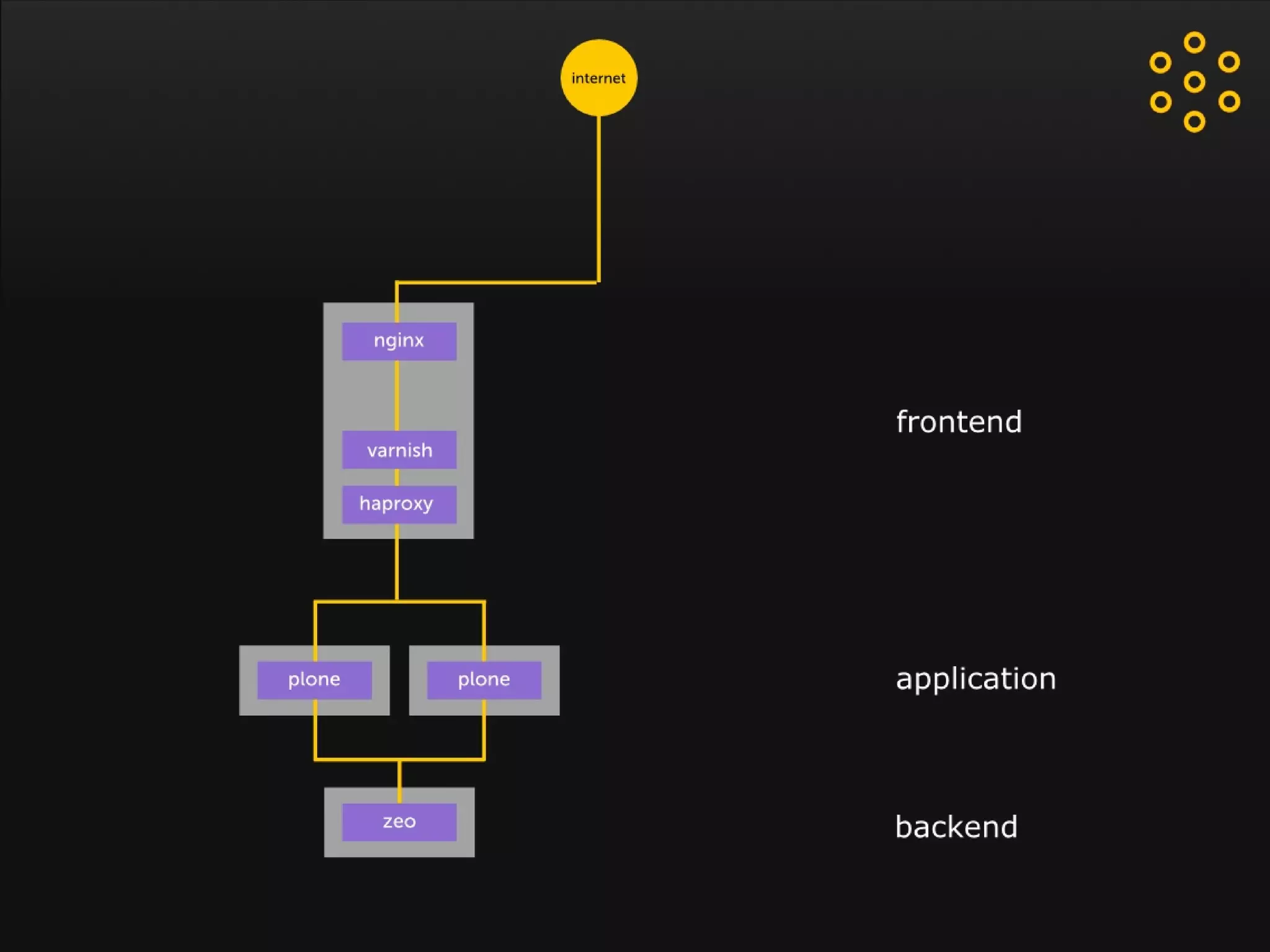
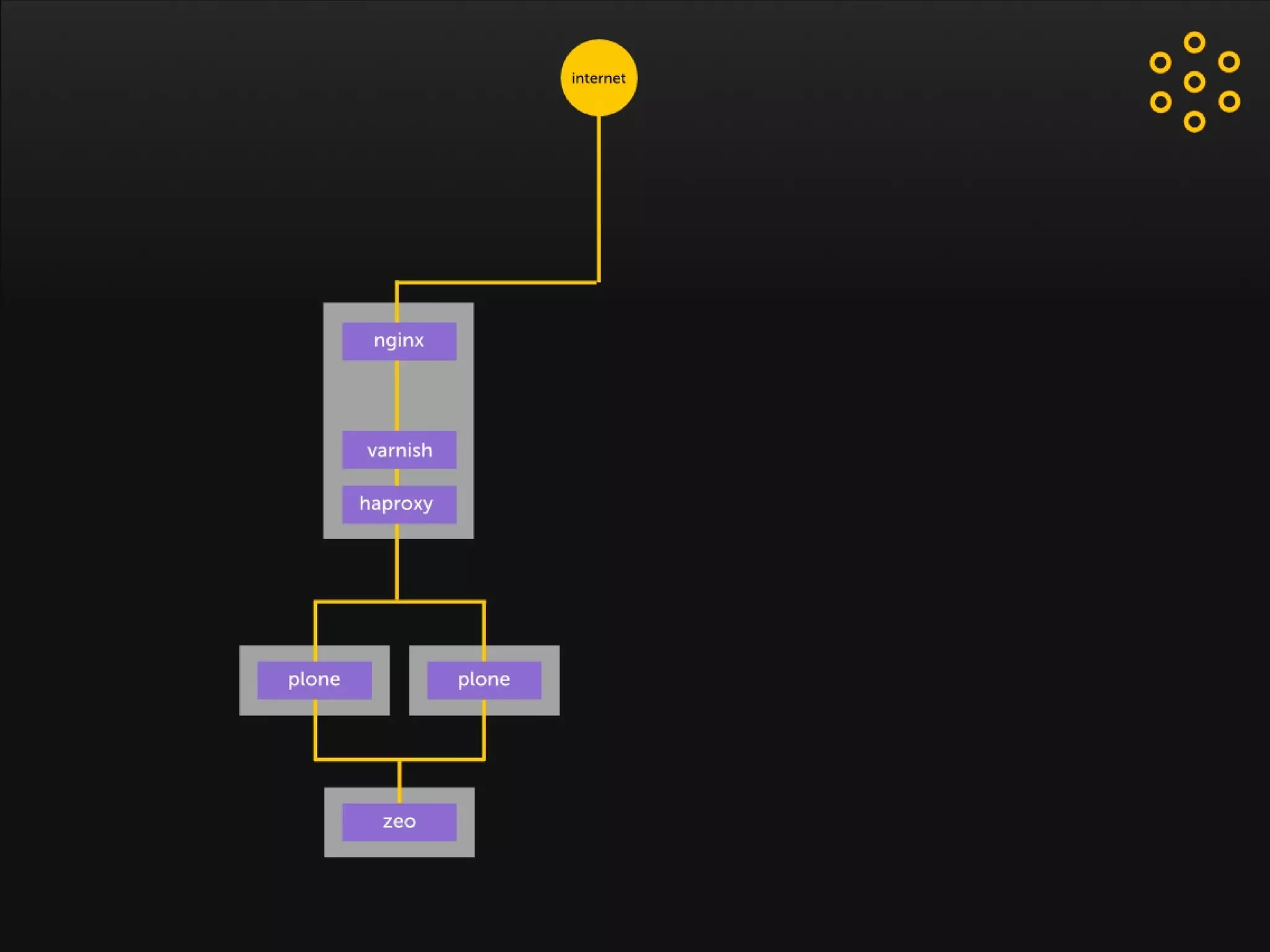
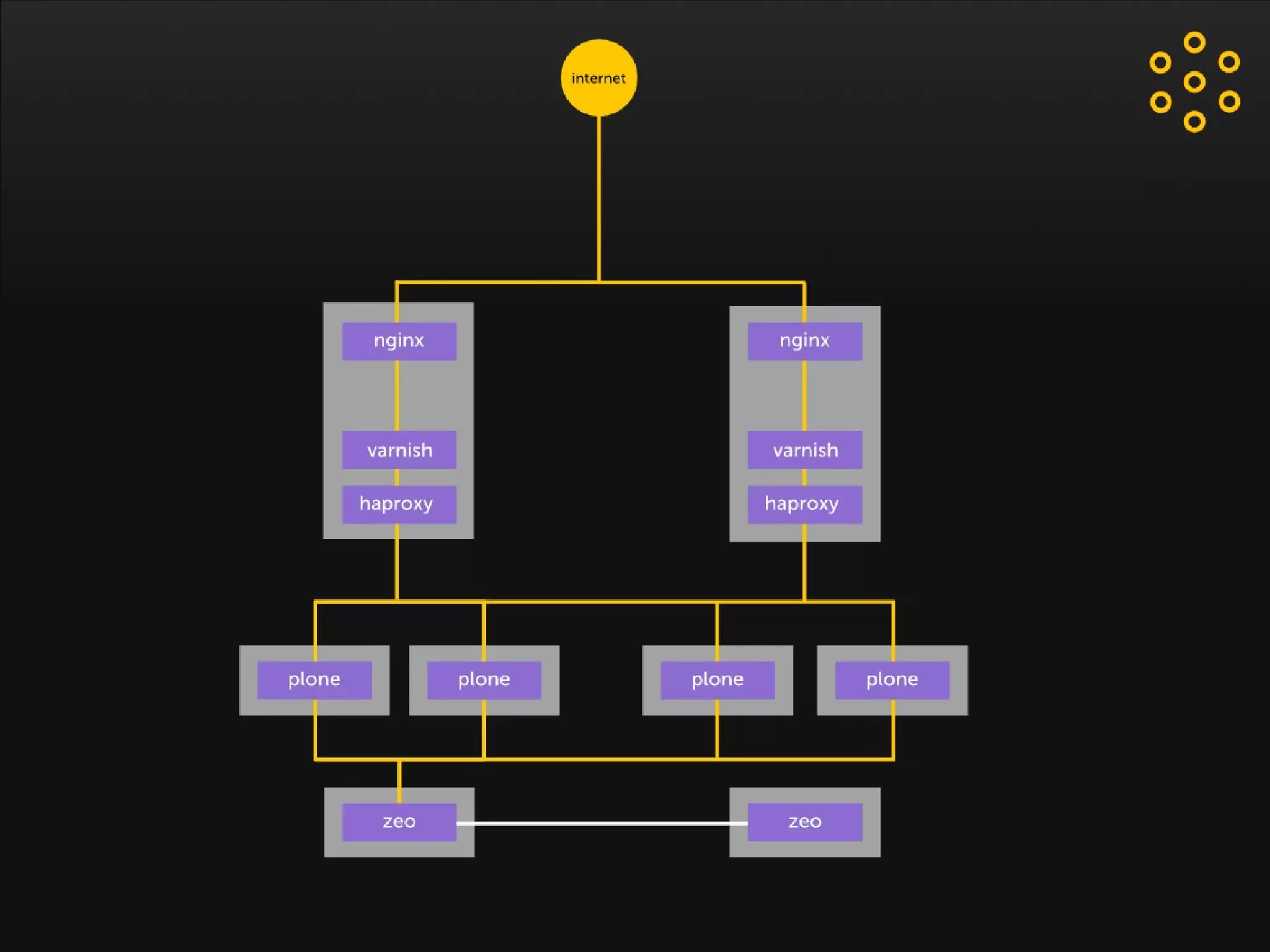
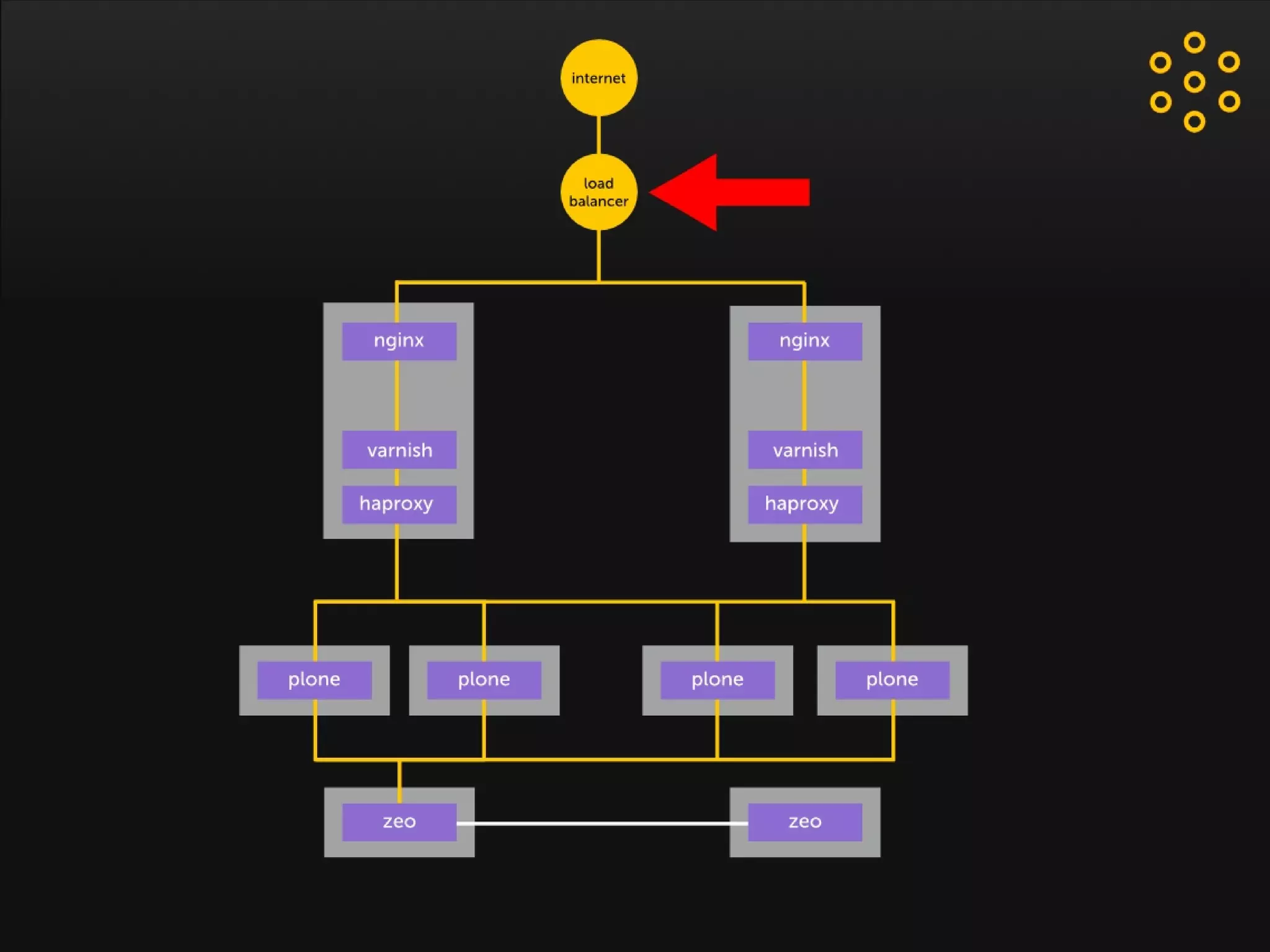

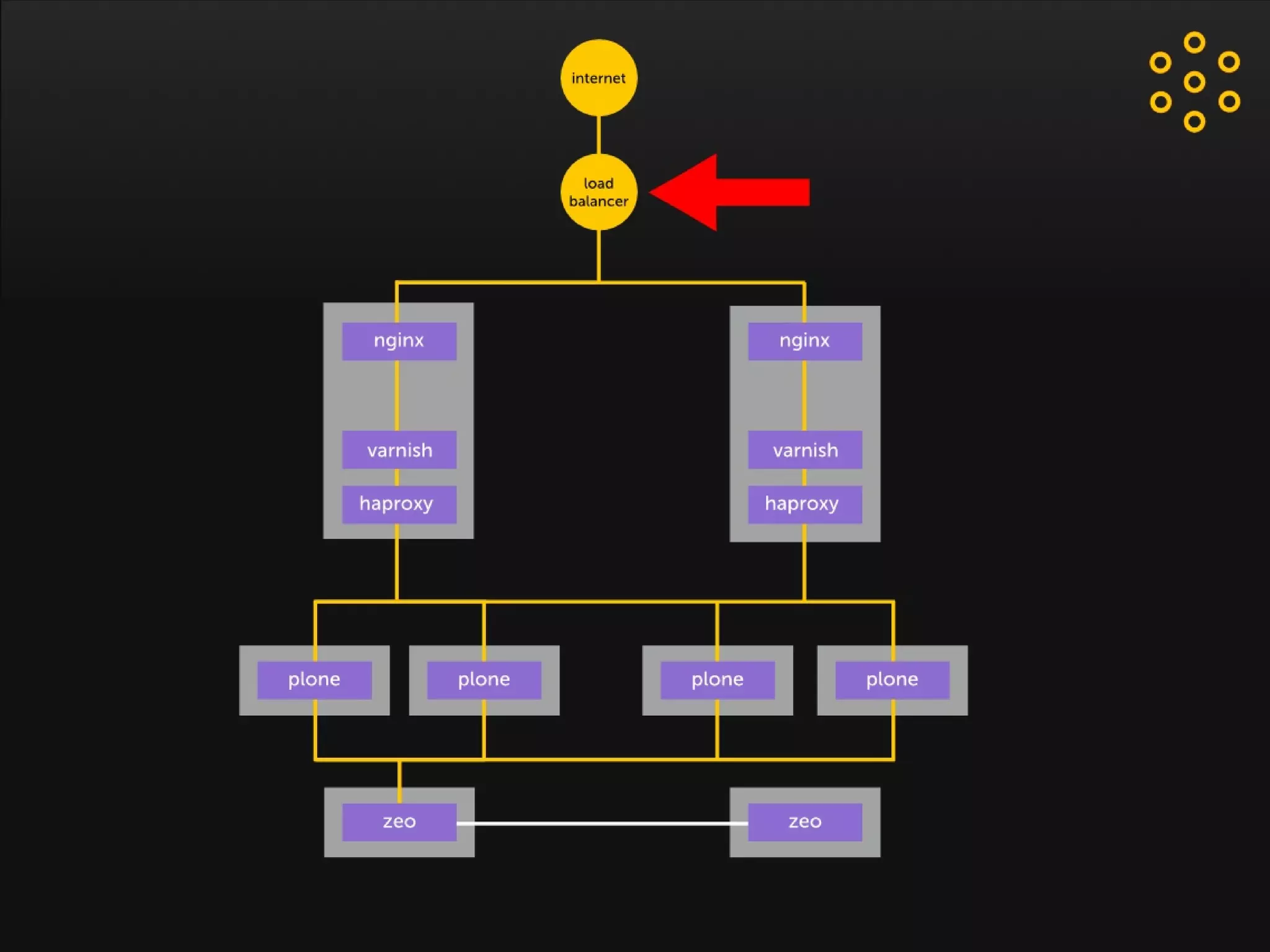

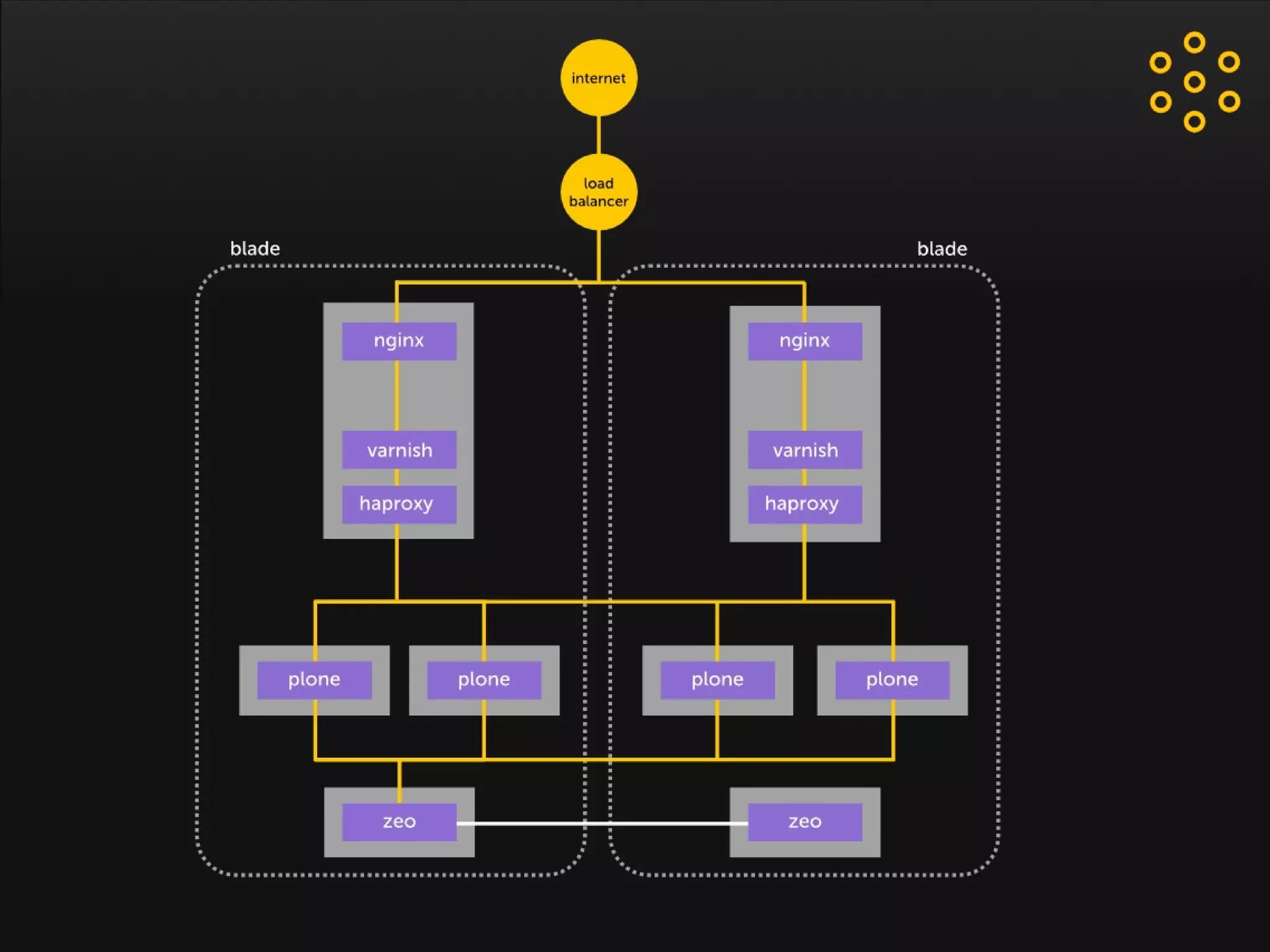
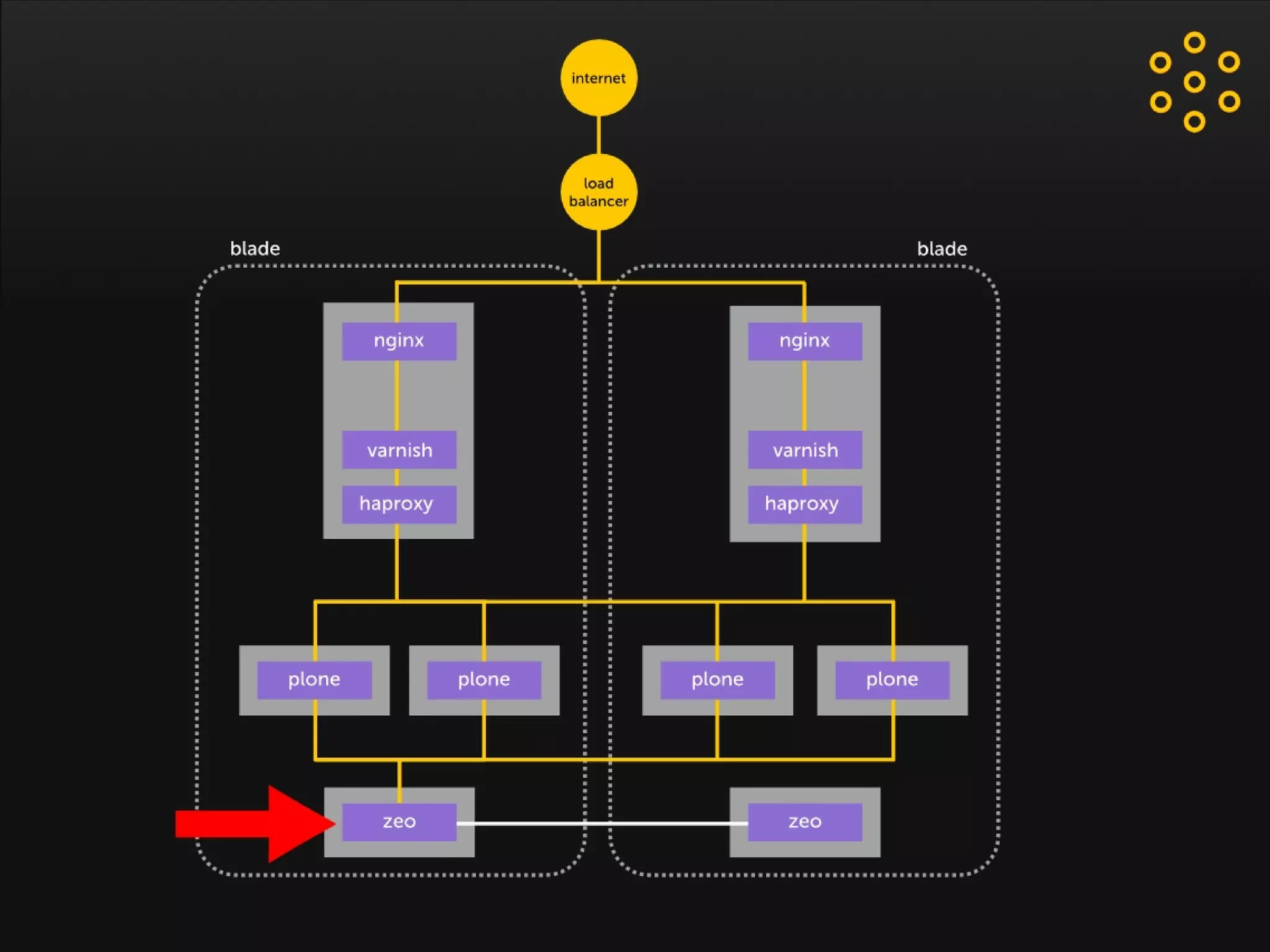

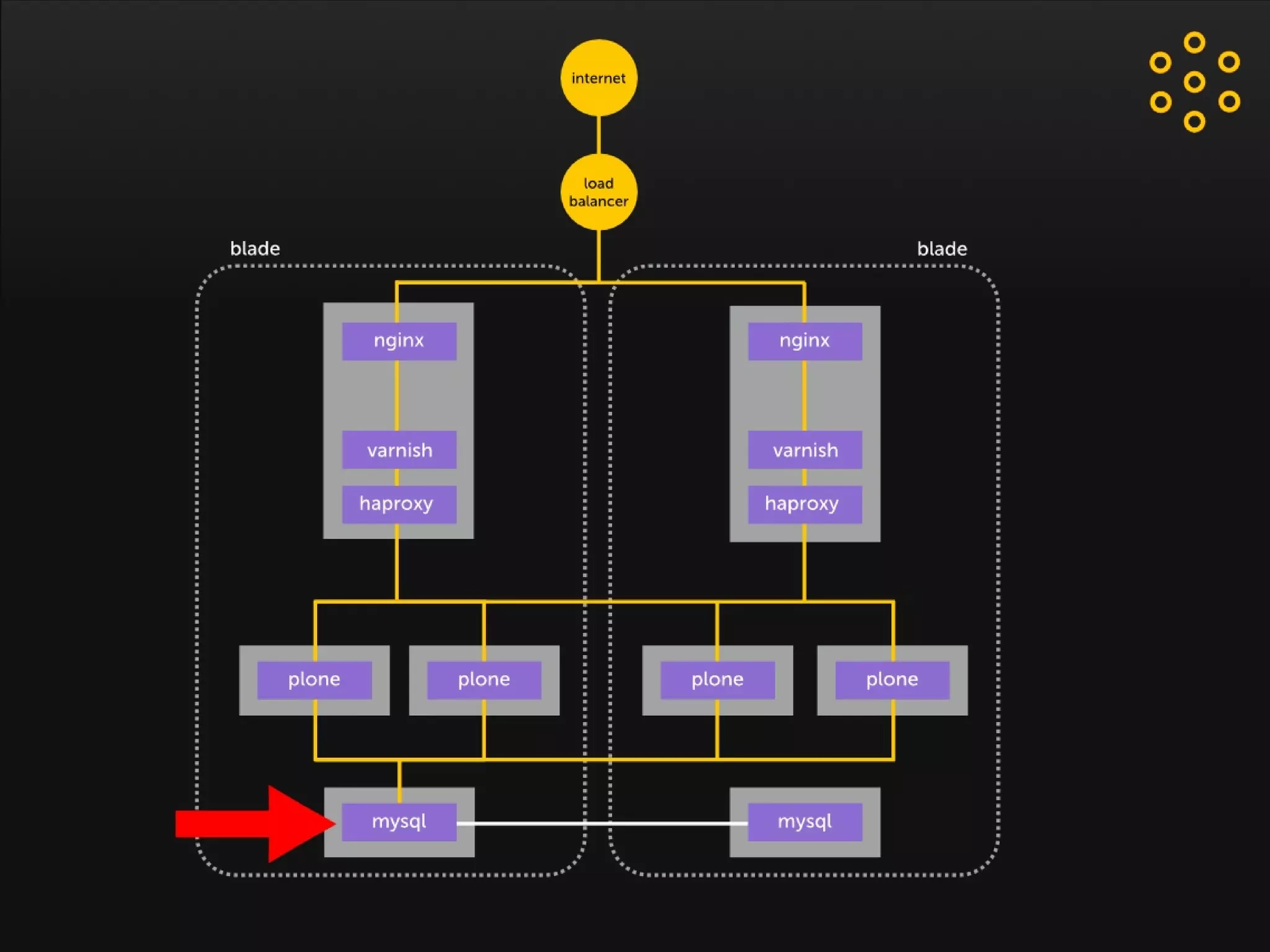

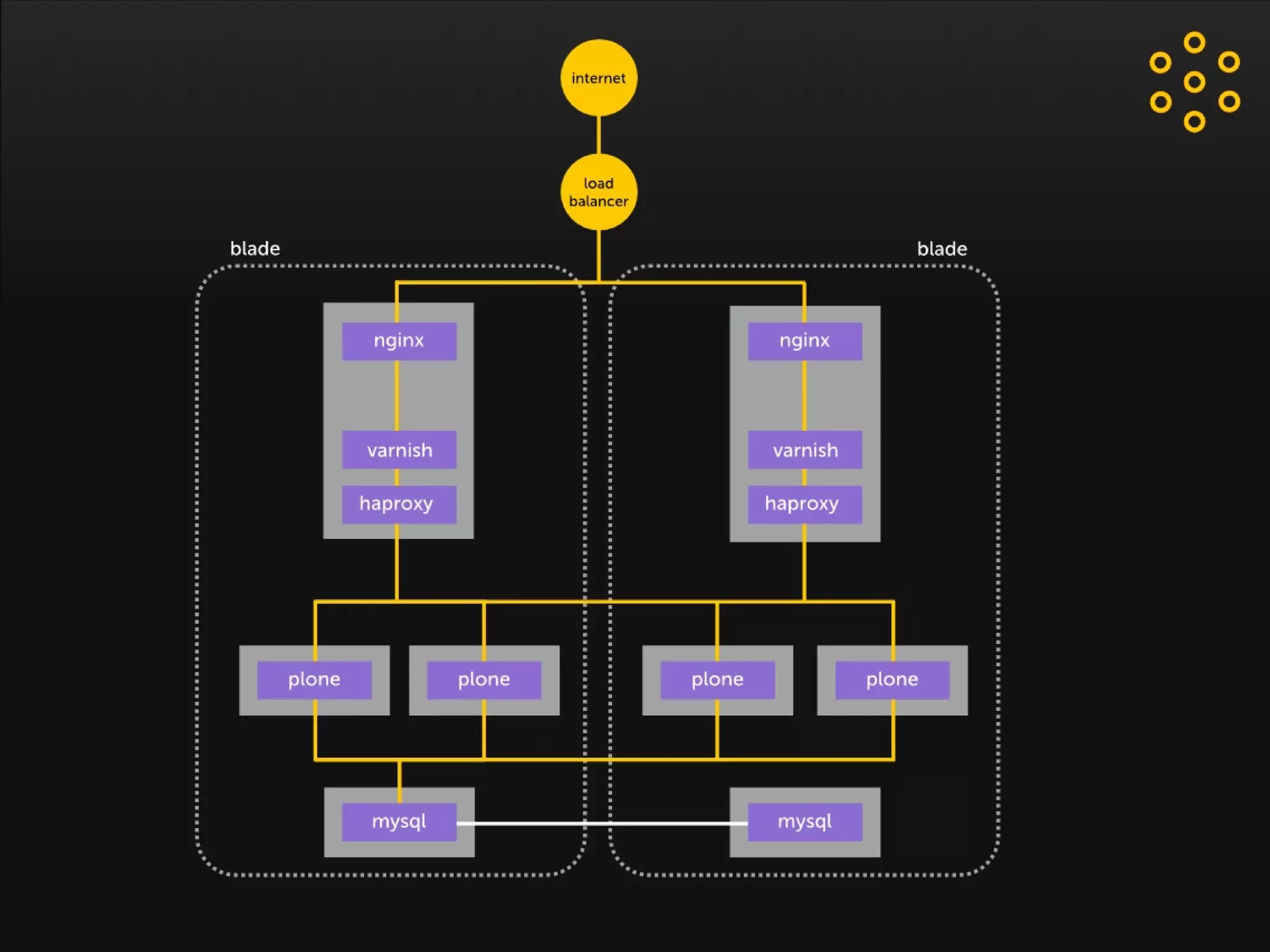
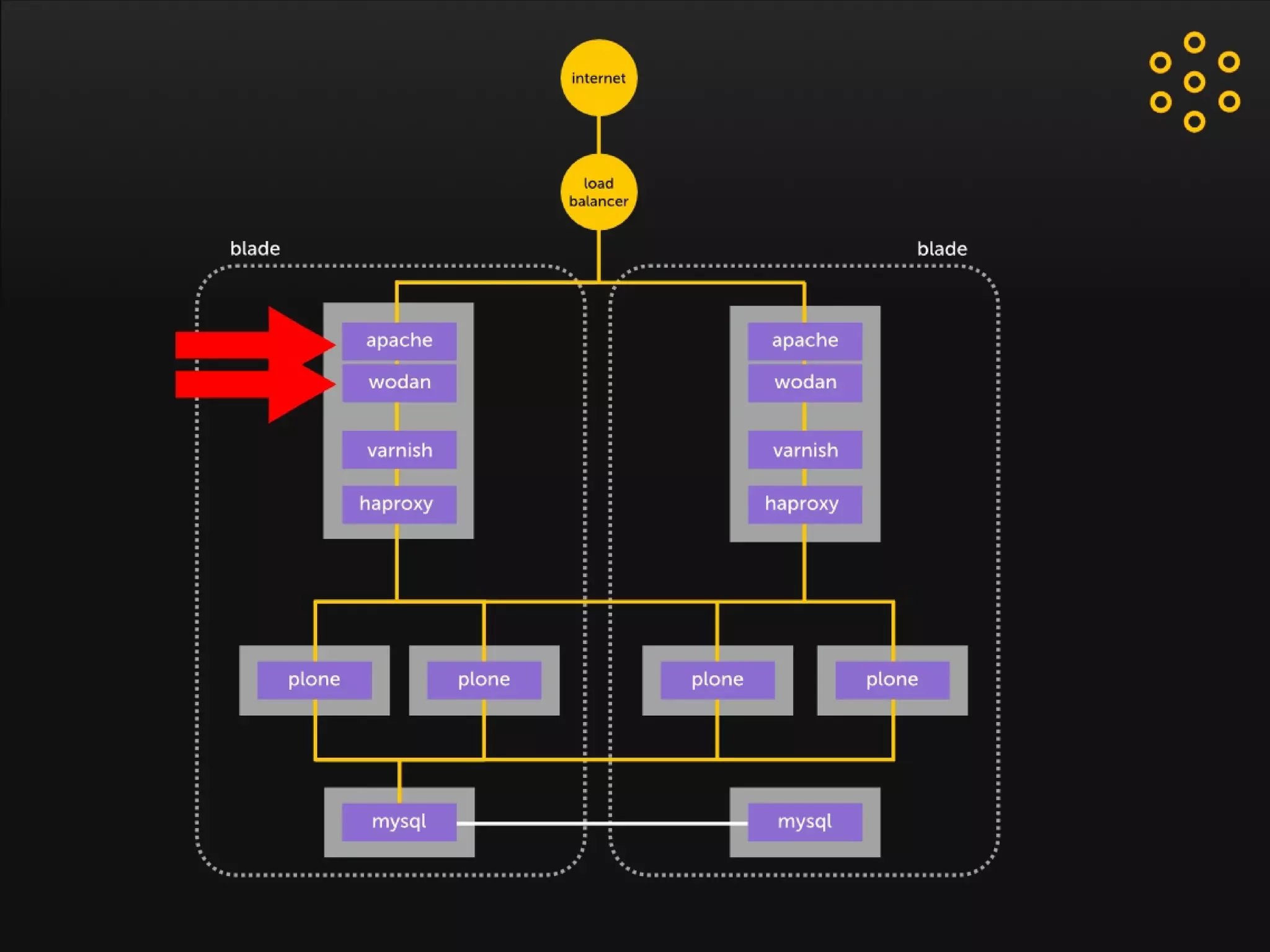




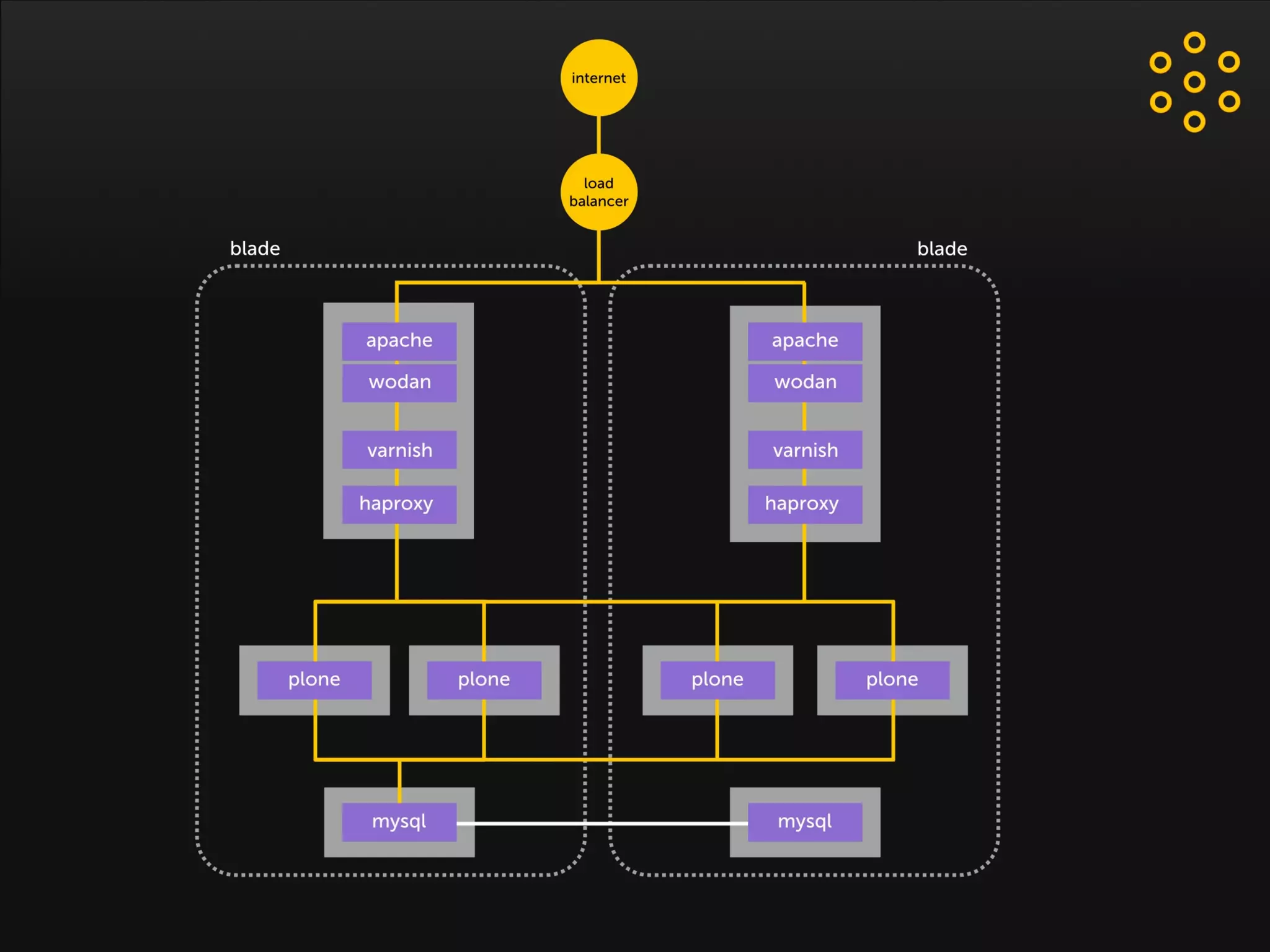
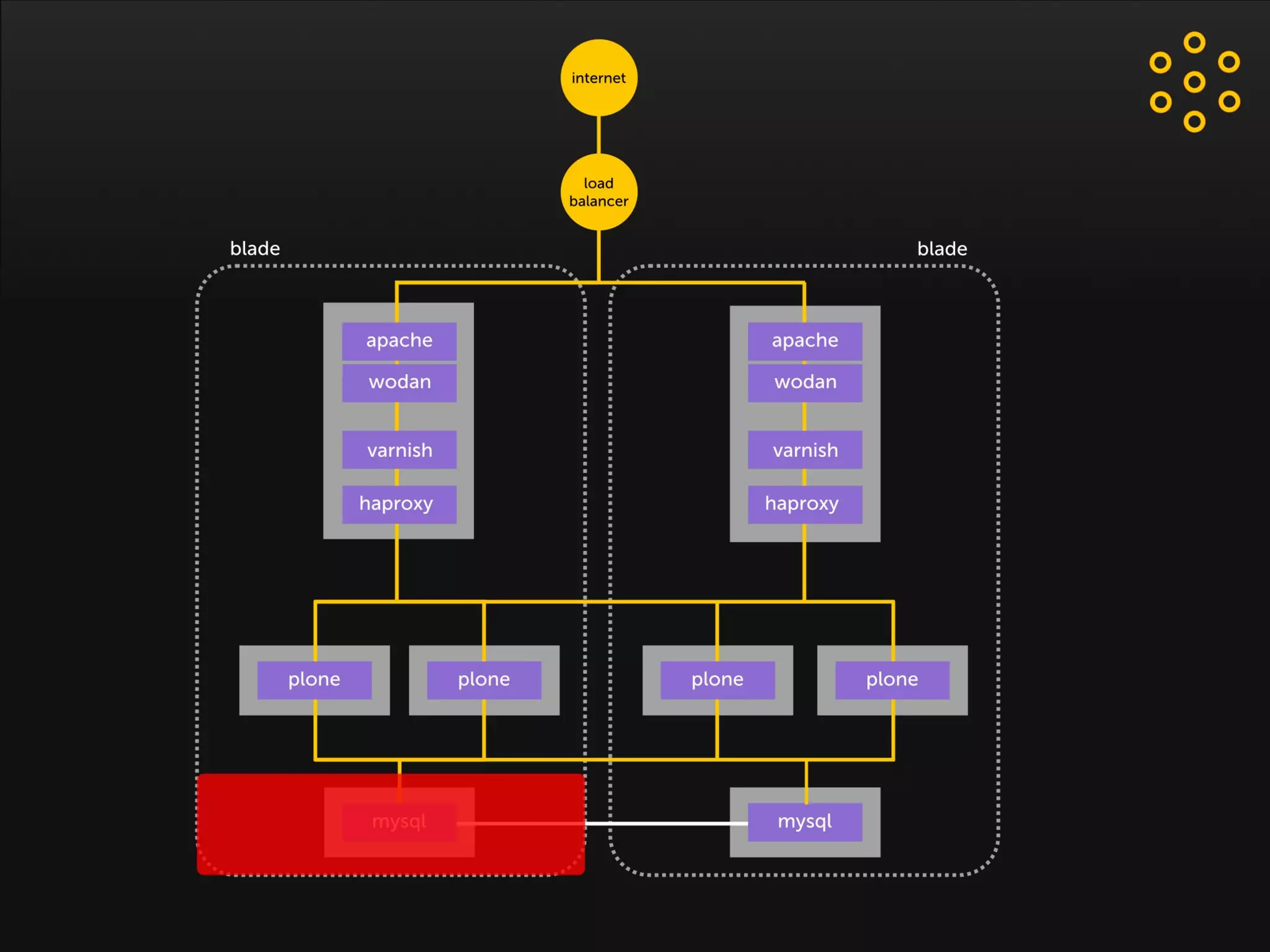

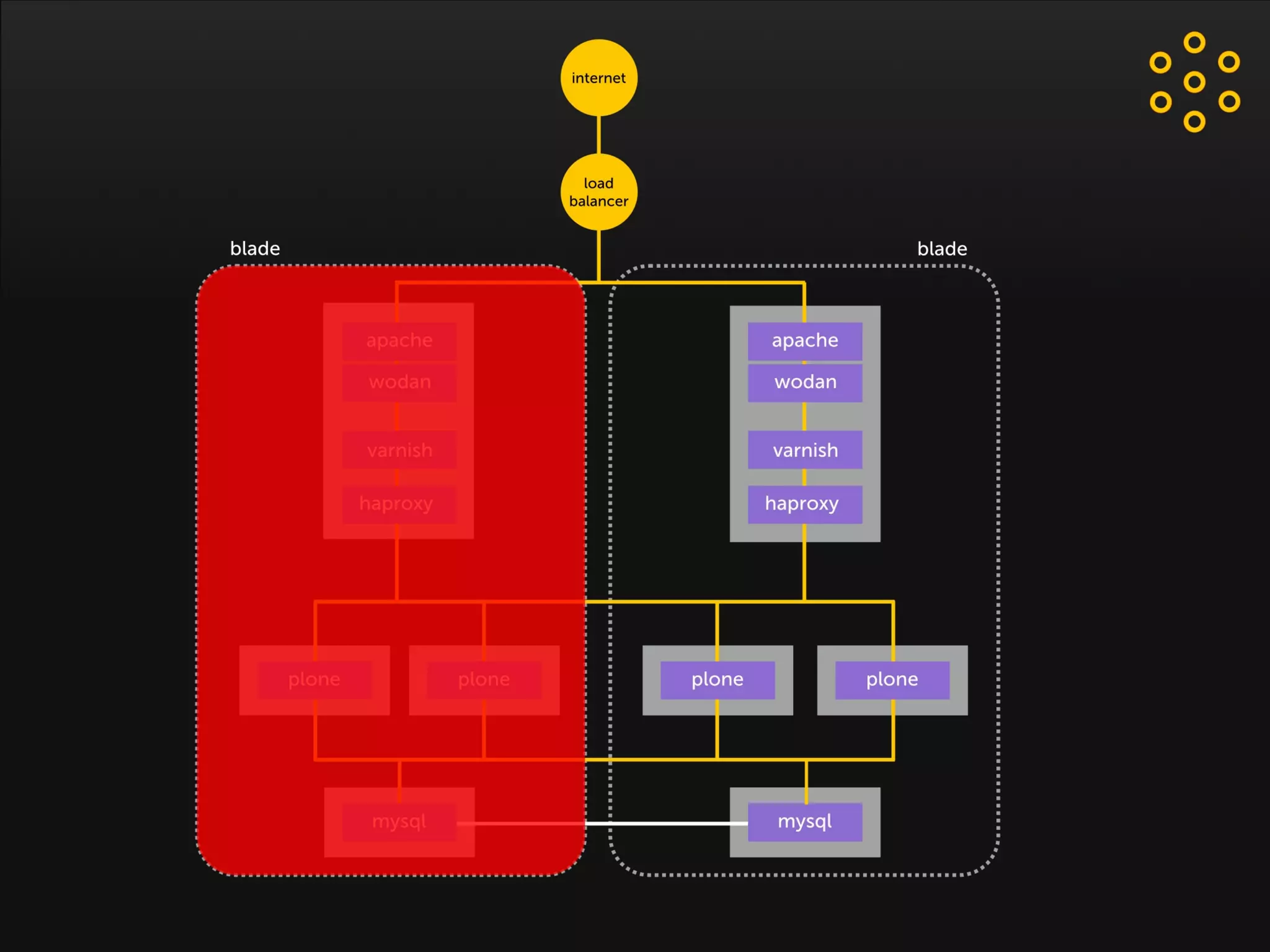
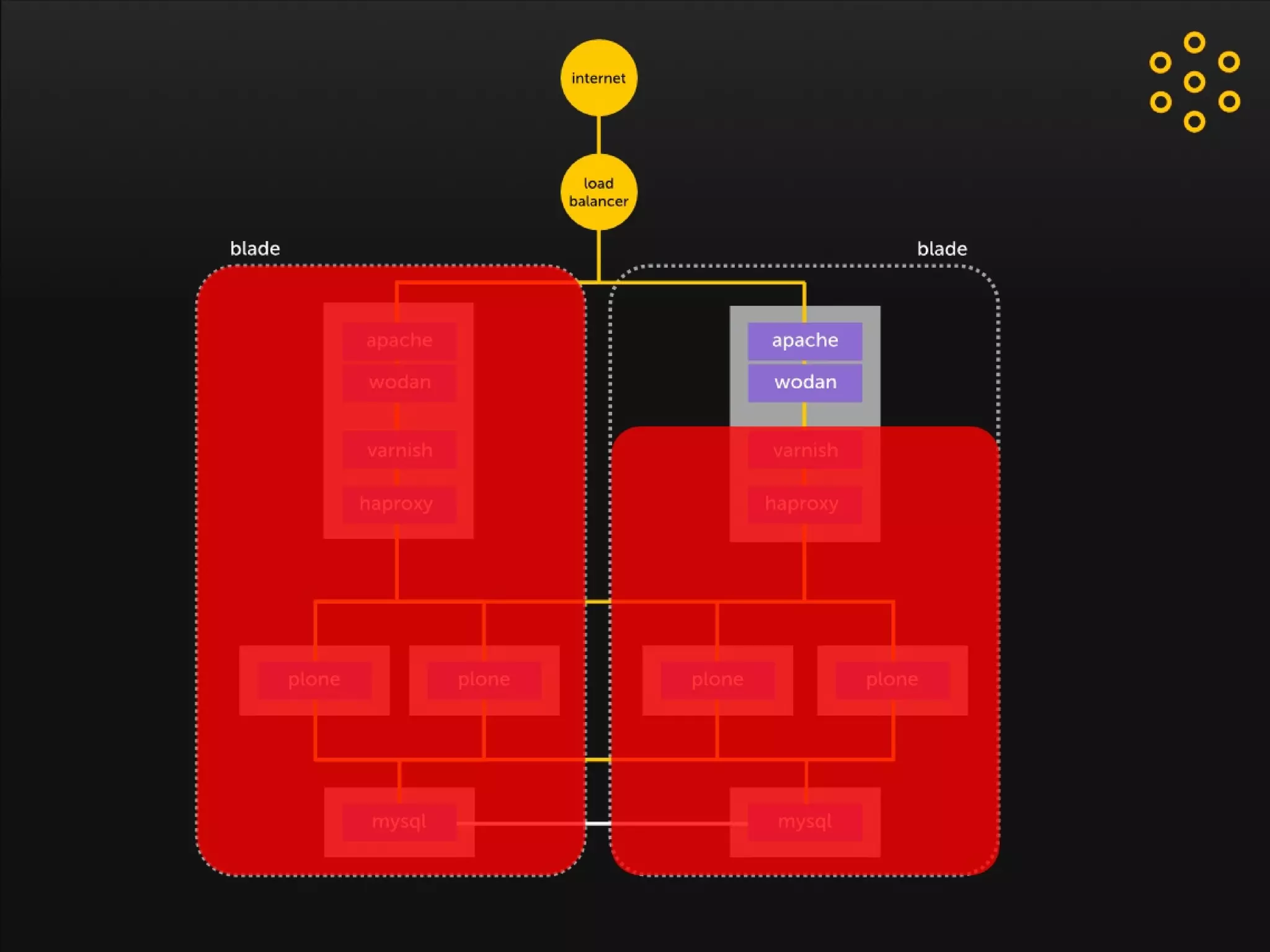
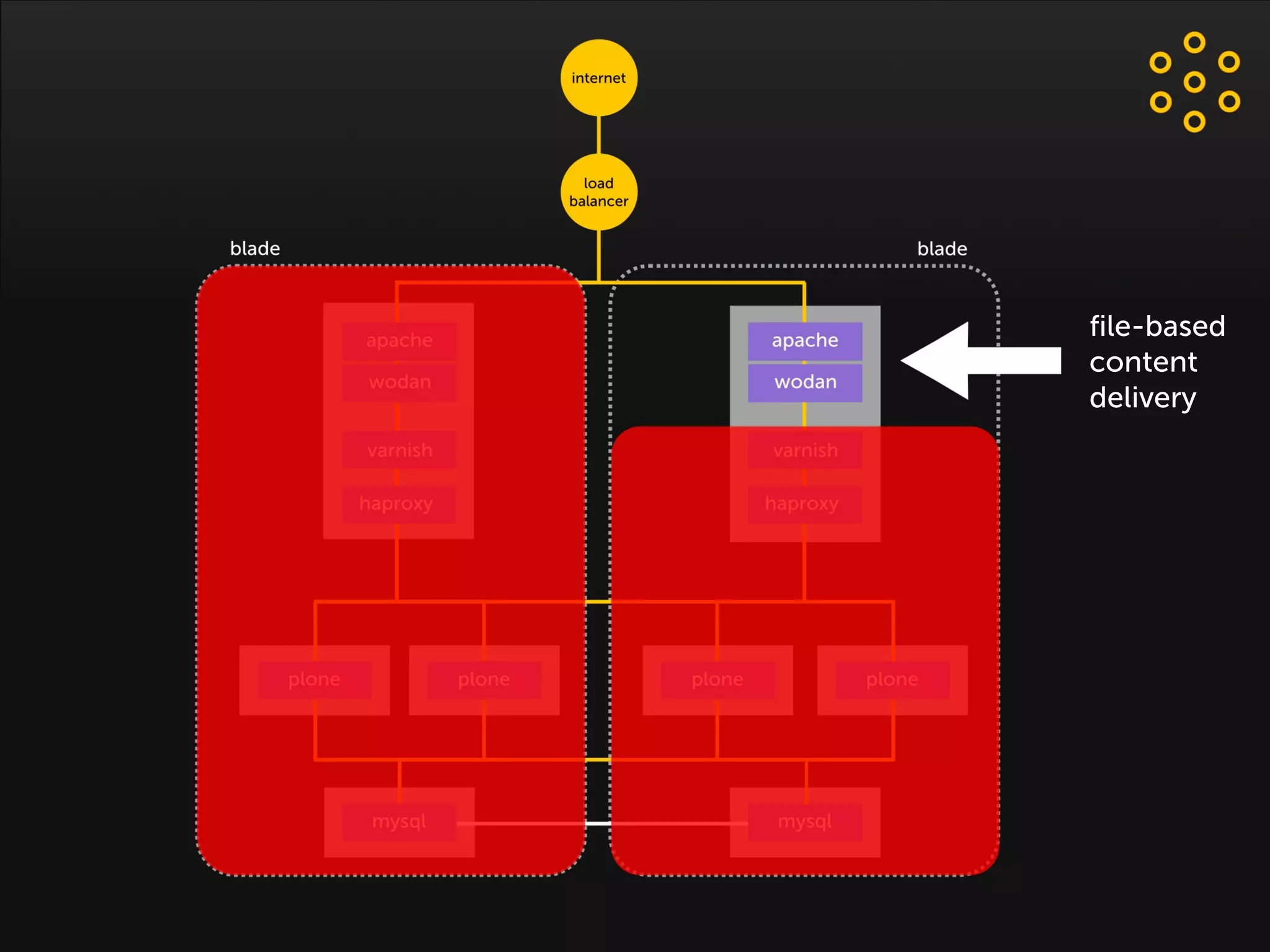

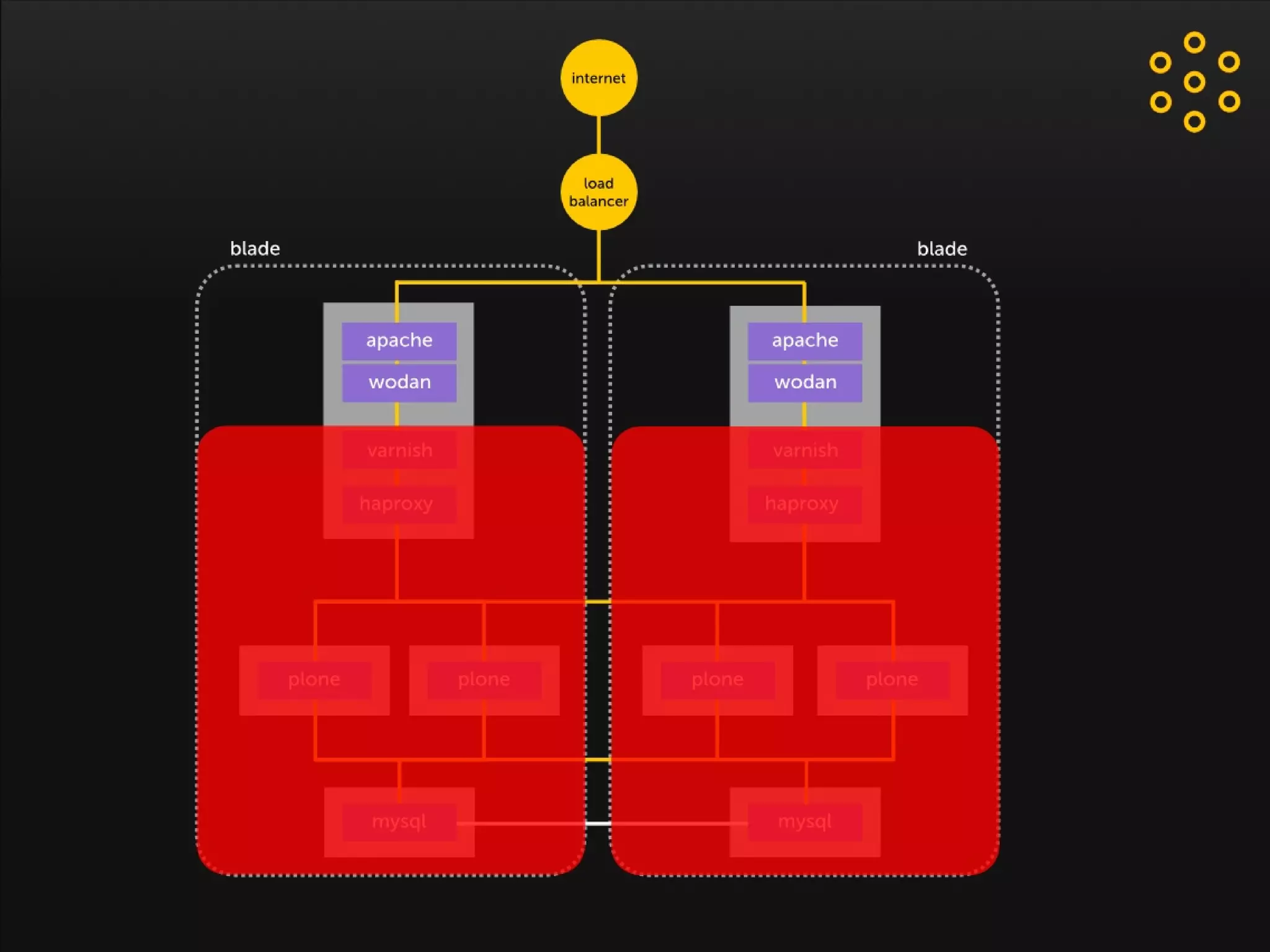
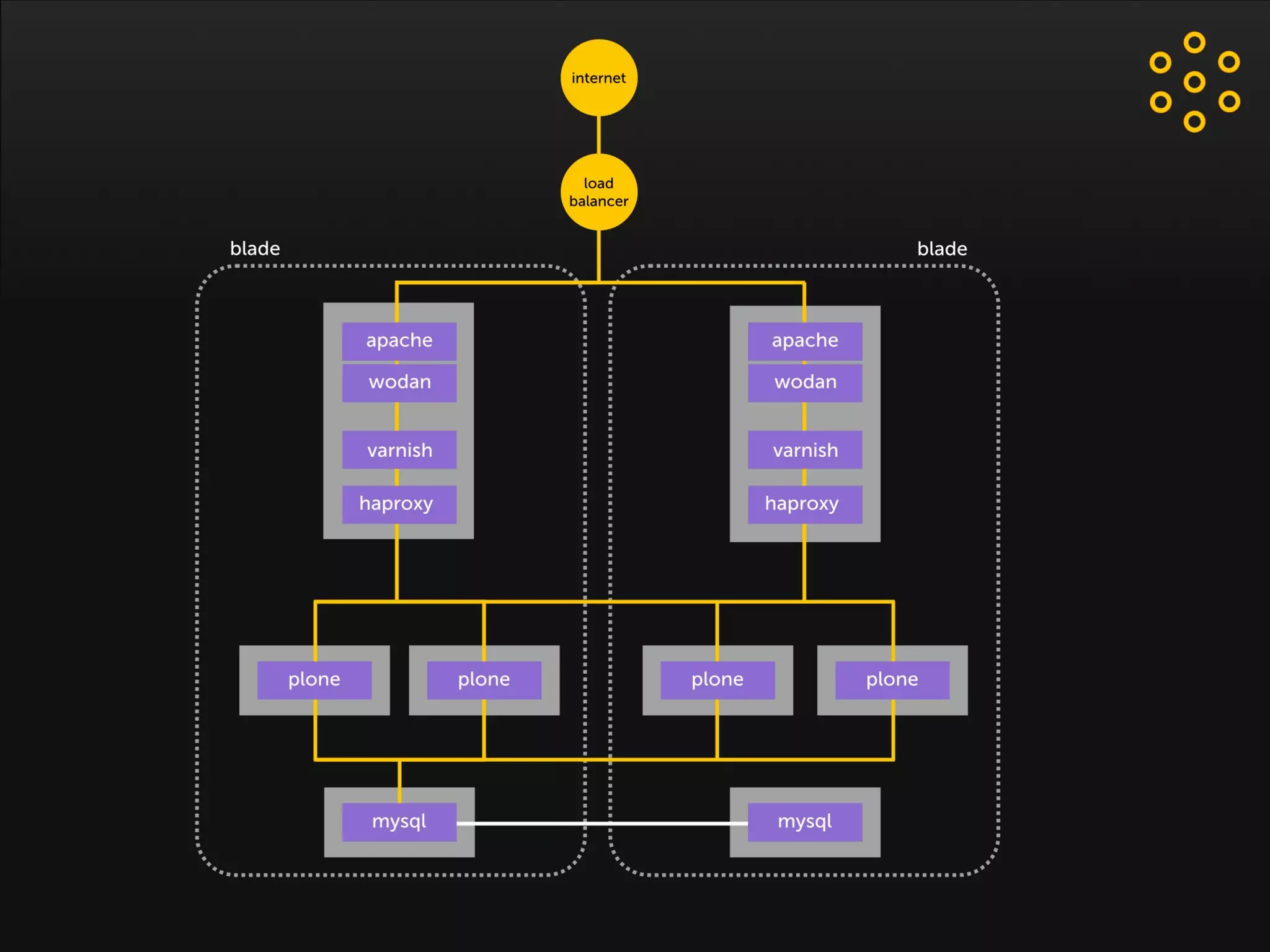

- The document discusses an architecture for providing high availability and performance for a Plone site handling high traffic volumes with a requirement for 100% uptime. - The proposed architecture uses multiple Plone instances behind a load balancer, with Relstorage (MySQL) replication providing redundancy. Mod_wodan and Varnish are used for caching to improve performance. The design eliminates all single points of failure and allows automated failover.



![Nginx [engine x] and you (and WordPress)](https://cdn.slidesharecdn.com/ss_thumbnails/nginxenginexandyouandwordpress-150529132927-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)


































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)

















