Downloaded 79 times
















![-XX:AutoBoxCacheMax=size
Sets IntegerCache.high value :
class Integer {
public static Integer valueOf(int i) {
if(i >= -128 && i <= IntegerCache.high)
return IntegerCache.cache[i + 128];
else
return new Integer(i);
}
}](https://image.slidesharecdn.com/jvmoptions-130213134018-phpapp02/75/JVM-performance-options-How-it-works-19-2048.jpg)



![-XX:-OptimizeStringConcat
String twenty = «12345678901234567890»;
String sb = new StringBuilder()
.append(twenty).append(twenty)
.append(twenty).append(twenty).toString();
new char[16];
new char[34];
new char[70];
new char[142];](https://image.slidesharecdn.com/jvmoptions-130213134018-phpapp02/75/JVM-performance-options-How-it-works-23-2048.jpg)
![-XX:+OptimizeStringConcat
String twenty = «12345678901234567890»;
String sb = new StringBuilder()
.append(twenty).append(twenty)
.append(twenty).append(twenty).toString();
new char[80];](https://image.slidesharecdn.com/jvmoptions-130213134018-phpapp02/75/JVM-performance-options-How-it-works-24-2048.jpg)
![-XX:+OptimizeStringConcat
String twenty = «12345678901234567890»;
StringBuilder sb1 = new StringBuilder();
sb1.append(new StringBuilder()
.append(twenty).append(twenty)
.append(twenty).append(twenty)
);
new char[80];](https://image.slidesharecdn.com/jvmoptions-130213134018-phpapp02/75/JVM-performance-options-How-it-works-25-2048.jpg)
![XX:+OptimizeFill
Arrays.fill(), Arrays.copyOf() or code
patterns :
for (int i = fromIndex; i < toIndex; i++) {
a[i] = val;
}
Native machine instructions](https://image.slidesharecdn.com/jvmoptions-130213134018-phpapp02/75/JVM-performance-options-How-it-works-26-2048.jpg)


![-XX:+UseCompressedStrings
For ASCII characters:
char[] -> byte[]](https://image.slidesharecdn.com/jvmoptions-130213134018-phpapp02/75/JVM-performance-options-How-it-works-29-2048.jpg)

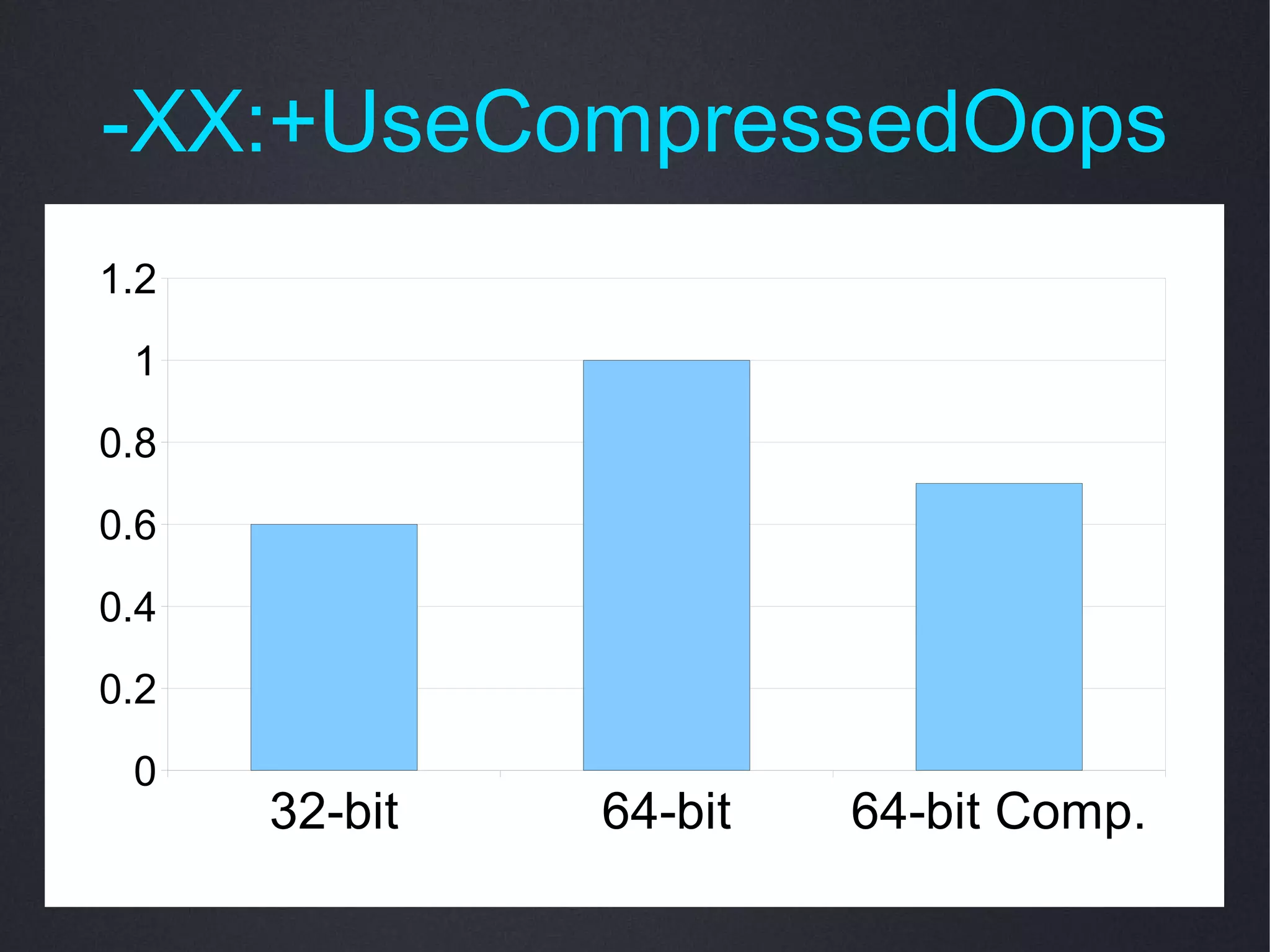







The document discusses JVM performance options, including various flags and their configurations for garbage collection, performance tuning, and debugging. It details the impact of specific options like escape analysis, autoboxing, and optimized string concatenation on performance improvements. Additionally, it highlights memory optimization techniques such as compressed object pointers and large pages for enhancing JVM efficiency.















































