Download to read offline

![Motivations
• Only 1% of the Twitter stream contains geographical information [Graham et al.,
2014].
• This sample of tweets is insufficient for several applications such as Disaster
and Emergency Management or Traffic Incident Detection (Chapter 6)
• Inferring the geolocation of non-geotagged tweets can increase the sample of
actionable geotagged data.
• Previous tweet geolocalisation approaches work at a coarse-grained level
(country or city level) [Eisenstein et al., 2010a; Han and Cook, 2013; Kinsella et al., 2011; Schulz et al.,
2013a]
• We aim to infer the geolocation of tweets at a fine-grained level (street or
neighbour level).
In this thesis, we aim to achieve an error distance of at most 1 km!
2](https://image.slidesharecdn.com/thesis-jorge-gonzalez-v2-190422171532/75/Inferring-the-Geolocation-of-Tweets-at-a-Fine-Grained-Level-PhD-Thesis-2-2048.jpg)
![Thesis Statement
“The geolocalisation of non-geotagged tweets at a fine-grained
level can be achieved by exploiting the characteristics of already
available individual finely-grained geotagged tweets.”
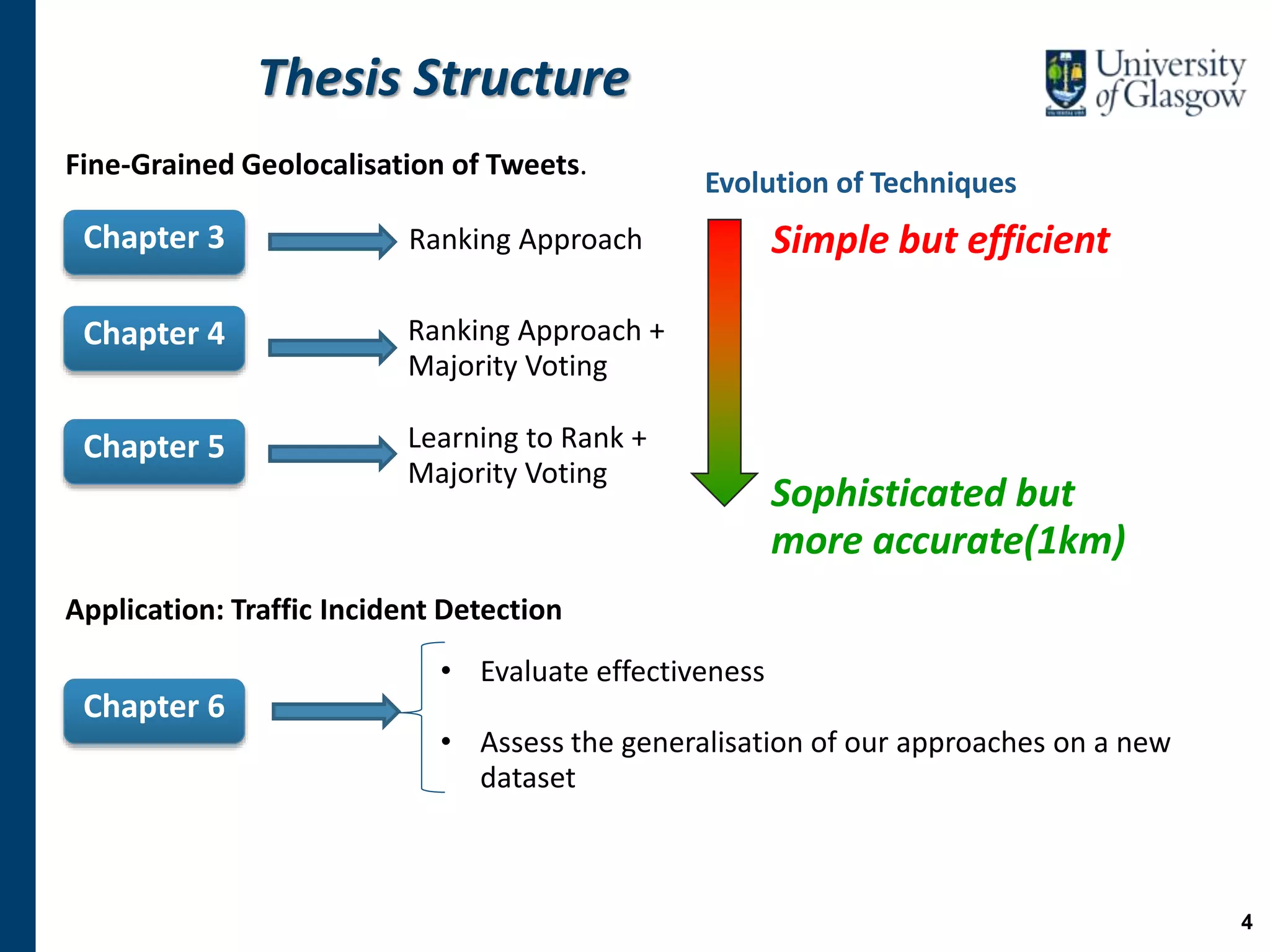
Chapter 3
Chapter 4
Chapter 5
Chapter 6
H4: By geolocalising non-geotagged tweets we can obtain a more representative sample of
geotagged data and, therefore, improve the effectiveness of the traffic incident detection task.
H3: By improving the ranking of geotagged tweets with respect to a given non-geotagged tweet, […]
we can obtain a higher number of other fine-grained predictions.
H2: The predictability of the geolocation of tweets at a fine-grained level is given by the correlation
between their content similarity and geographical distance to finely-grained geotagged tweets.
H1: By considering geotagged tweets individually […] we can improve the performance of fine-
grained geolocalisation.
3](https://image.slidesharecdn.com/thesis-jorge-gonzalez-v2-190422171532/75/Inferring-the-Geolocation-of-Tweets-at-a-Fine-Grained-Level-PhD-Thesis-3-2048.jpg)

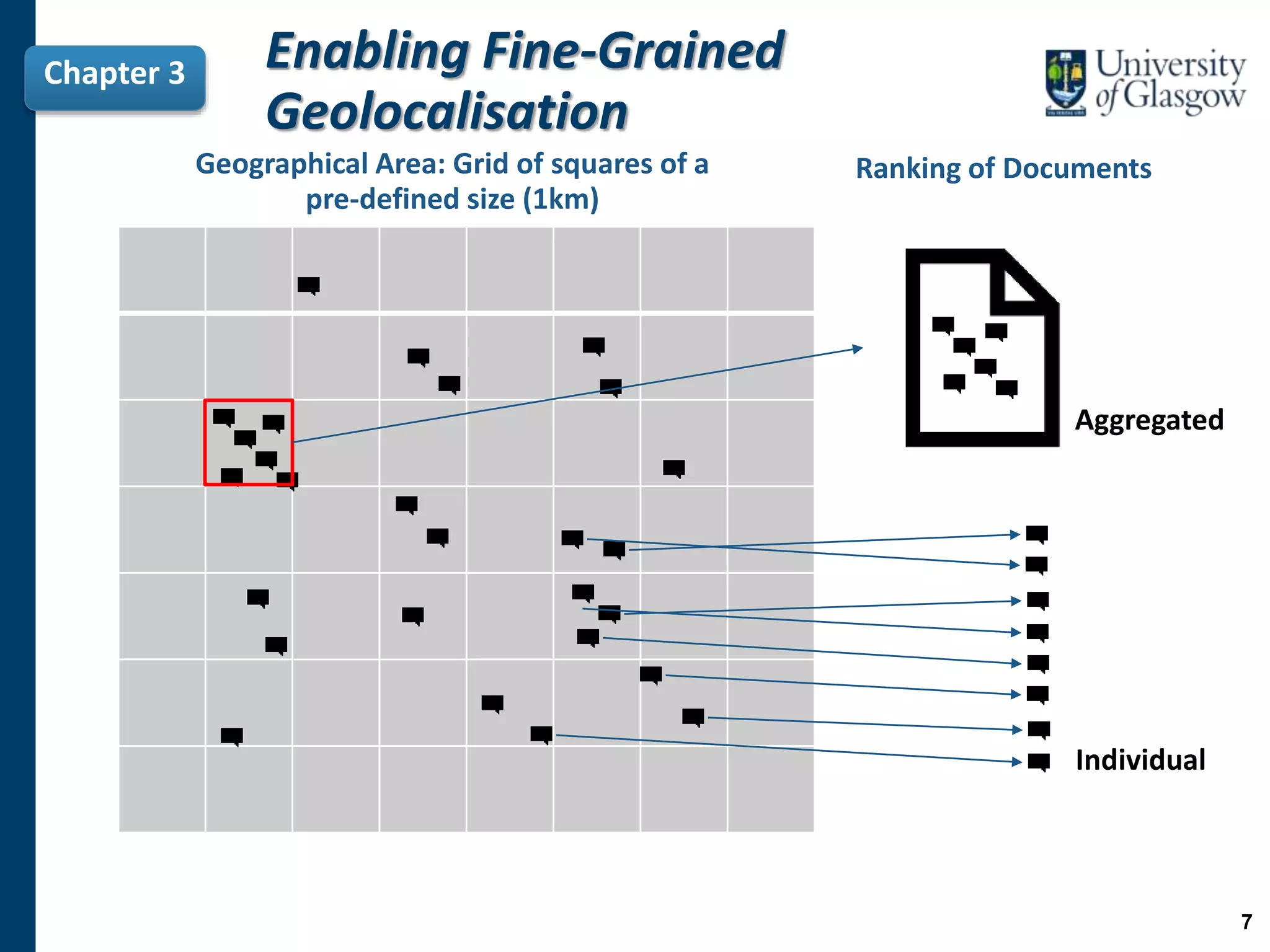
![Motivation
• Existing approaches in the literature have limitations when they are adapted
to work at a fine-grained level [Kinsella et al. (2011), Paraskevopoulos et al. (2015)].
−To represent a location, these approaches aggregate the text of the tweets in this
location into a virtual document.
−We postulate that this aggregation approach can lead to a loss of important
evidence.
Chapter 3
H1:
By considering geotagged tweets individually we can preserve the
evidence lost when adapting previous approaches at a fine-
grained level, and thus we can improve the performance of fine-
grained geolocalisation.
Enabling Fine-Grained
Geolocalisation
6](https://image.slidesharecdn.com/thesis-jorge-gonzalez-v2-190422171532/75/Inferring-the-Geolocation-of-Tweets-at-a-Fine-Grained-Level-PhD-Thesis-6-2048.jpg)


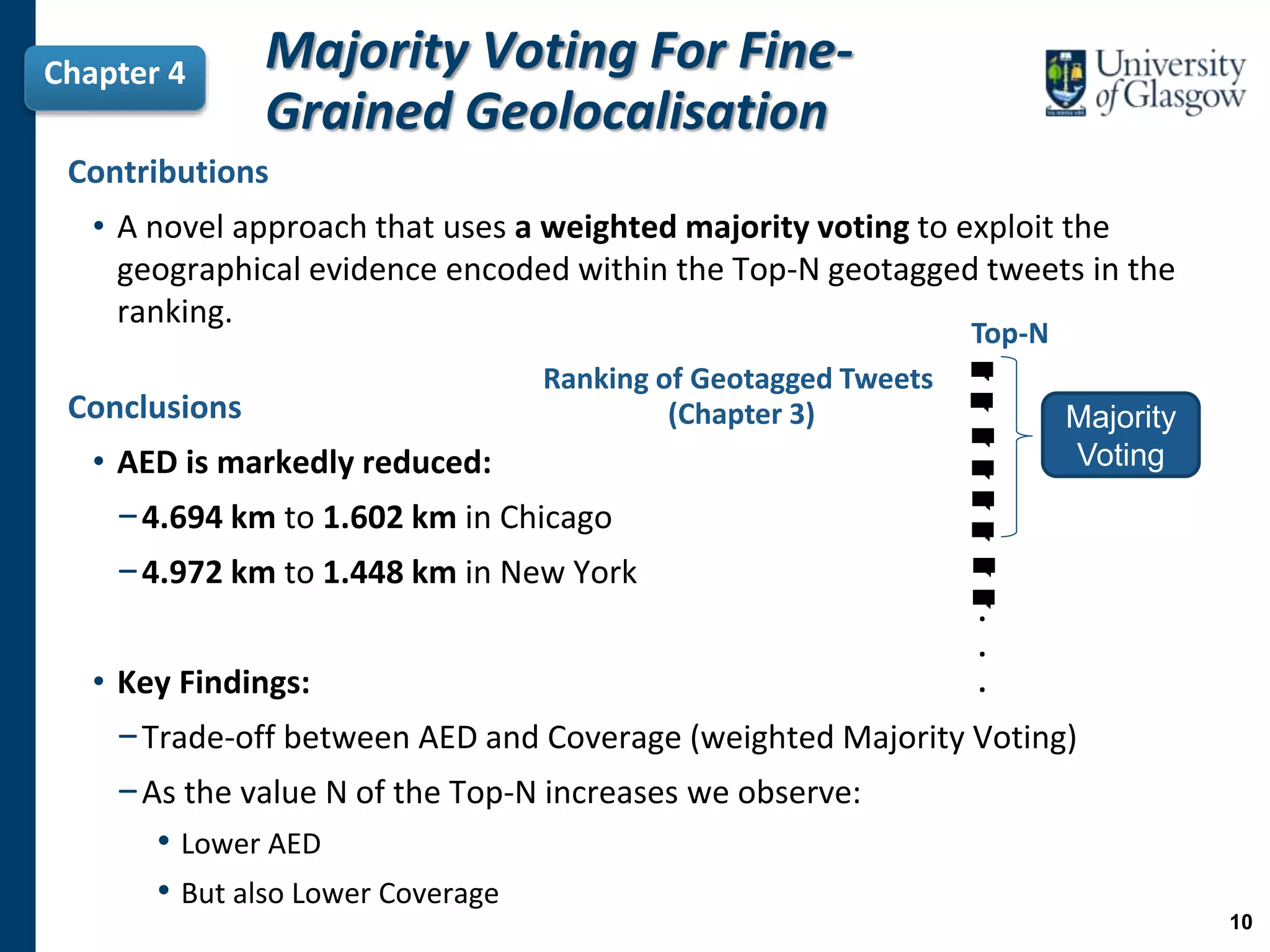
![Learning to GeolocaliseChapter 5
H3:
By improving the ranking of geotagged tweets with respect to a given
non-geotagged tweet, […] we can obtain a higher number of other fine-
grained predictions.
Motivation
• The approaches of Chapters 3 & 4 use traditional retrieval models
−Similarity is based only on document frequency information (IDF weighting).
• Considering only IDF can limit the quality of the Top-N geotagged tweets.
11](https://image.slidesharecdn.com/thesis-jorge-gonzalez-v2-190422171532/75/Inferring-the-Geolocation-of-Tweets-at-a-Fine-Grained-Level-PhD-Thesis-11-2048.jpg)



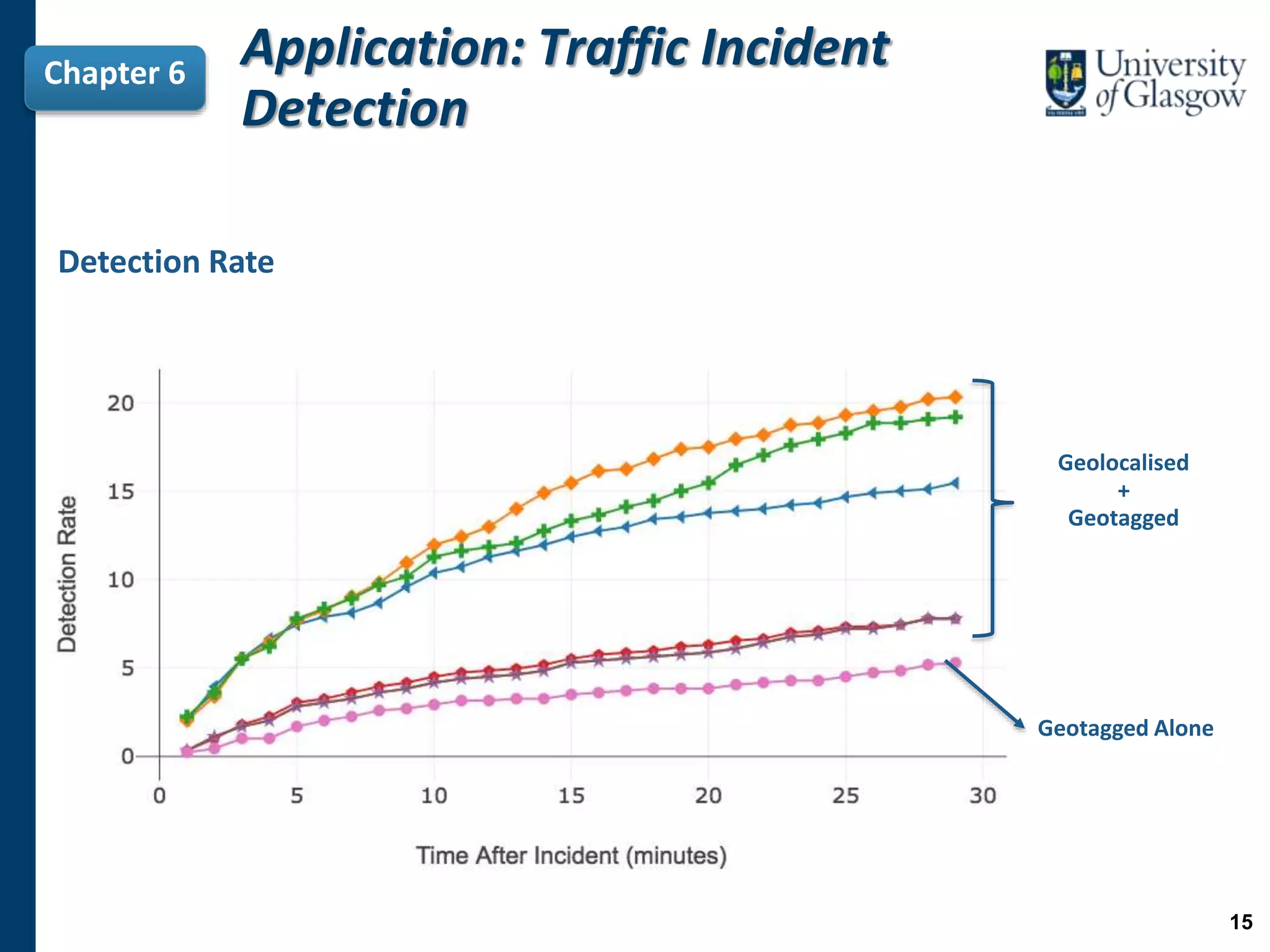
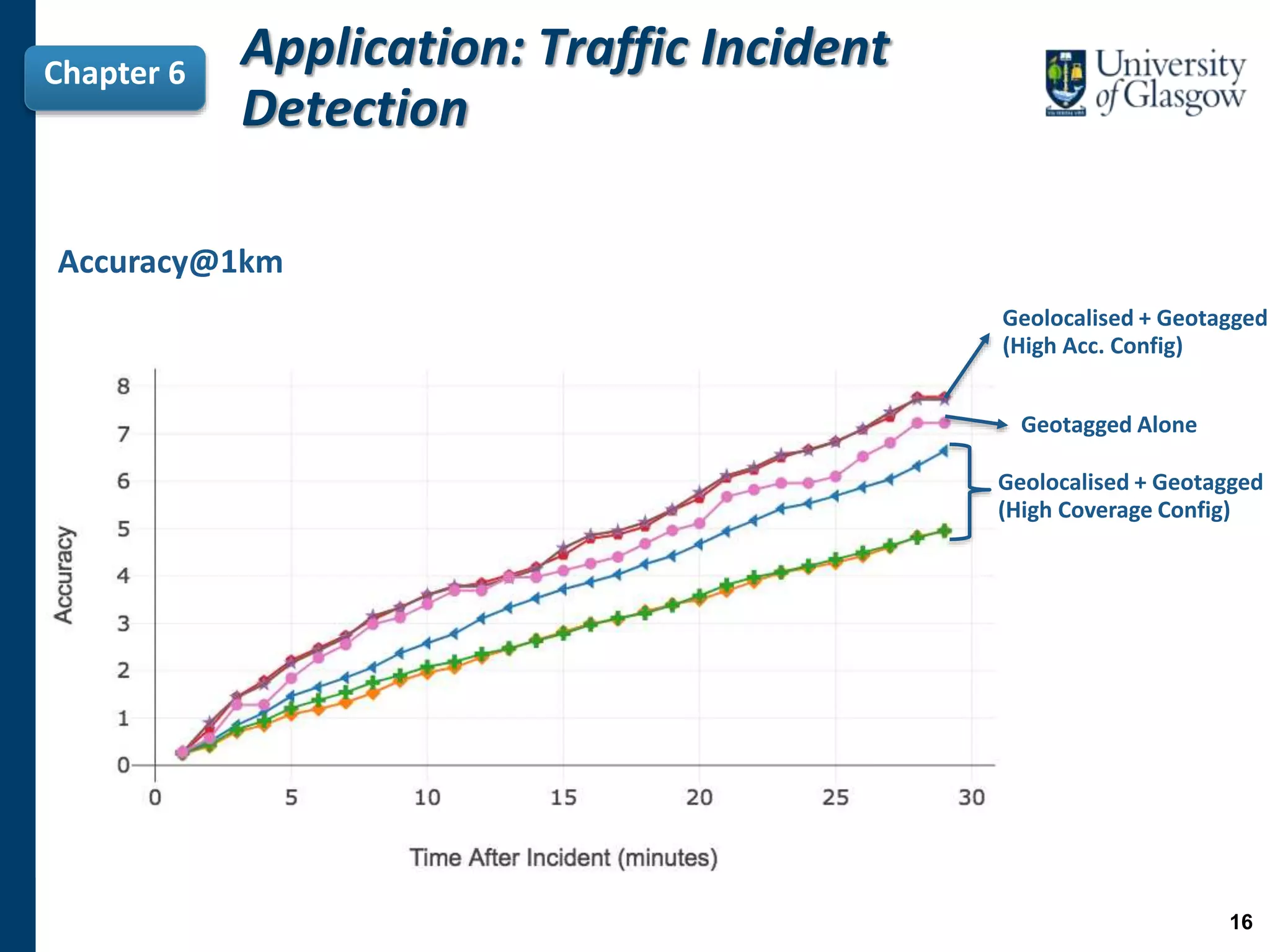





The document presents a PhD thesis defending research on inferring the geolocation of non-geotagged tweets at a fine-grained level to enhance applications like traffic incident detection. It argues that previous methods were limited by working only at coarse levels and proposes a novel approach using individual tweet analysis, majority voting, and learning to rank methods to improve accuracy. The findings demonstrate that these approaches significantly improve the geolocation accuracy of tweets, which is vital for effective emergency management and traffic monitoring.
![[Seminar] hyunwook 0624](https://cdn.slidesharecdn.com/ss_thumbnails/seminarhyunwook0624-200725001151-thumbnail.jpg?width=640&height=640&fit=bounds)














































