Download as PDF, PPTX



![CYPHER AND OPENCYPHER
Cypher: query language of the Neo4j graph database.
„Cypher is a declarative, SQL-inspired language for describing
patterns in graphs visually using an ascii-art syntax.”
MATCH
(p:Person)-[:PRESENTER_OF]->(:Presentation)-[:AT]->(m:Meetup)
WHERE m.date = 'Monday, December 18, 2017'
RETURN p
„The openCypher project aims to deliver a full and open
specification of the industry’s most widely adopted graph
database query language: Cypher.” (late 2015)](https://image.slidesharecdn.com/montreal-spark-meetup-171219060925/85/Compiling-openCypher-graph-queries-with-Spark-Catalyst-7-320.jpg)


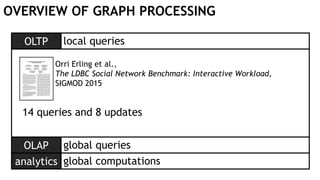
![OLAP global queries
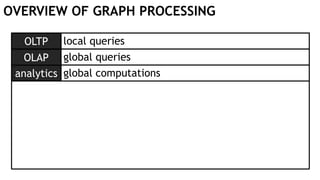
OVERVIEW OF GRAPH PROCESSING
OLTP
analytics
local queries
global computations
Example: „Friends’ recent likes”
MATCH (u:User {id: $userId})-[:FRIEND]-
(f:User)-[l:LIKES]->(p:Post)
RETURN f, p
ORDER BY l.timestamp DESC
LIMIT 10](https://image.slidesharecdn.com/montreal-spark-meetup-171219060925/85/Compiling-openCypher-graph-queries-with-Spark-Catalyst-11-320.jpg)
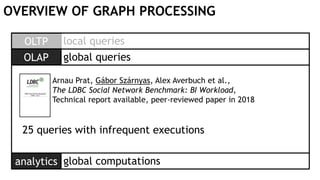
![OVERVIEW OF GRAPH PROCESSING
OLTP
analytics
local queries
global computations
OLAP global queries
Example: „One-sided friendships”
MATCH (u1:User)-[:FRIEND]-(u2:User)-[l:LIKES]->(p:Post),
(u1)-[:AUTHOR_OF]->(p)
WITH u1, u2, count(l) AS likes
WHERE likes > 10
AND NOT (u1)-[:LIKES]->(:Post)<-[:AUTHOR_OF]-(u2)
RETURN u1, u2](https://image.slidesharecdn.com/montreal-spark-meetup-171219060925/85/Compiling-openCypher-graph-queries-with-Spark-Catalyst-13-320.jpg)

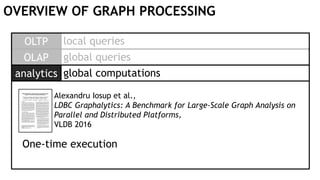



![PROXIMITY DETECTION
seg
1
NEXT: 1..2
t1
ON
MATCH
(t1:Train)-[:ON]->(seg1:Segment)
-[:NEXT*1..2]->(seg2:Segment)
<-[:ON]-(t2:Train)
RETURN t1, t2, seg1, seg2
seg
2
t2
ON
≤ 𝟏 segments](https://image.slidesharecdn.com/montreal-spark-meetup-171219060925/85/Compiling-openCypher-graph-queries-with-Spark-Catalyst-21-320.jpg)
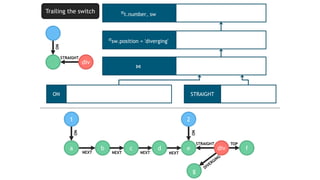
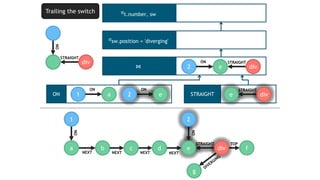
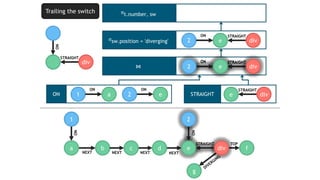
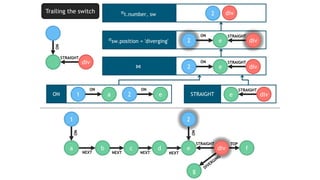
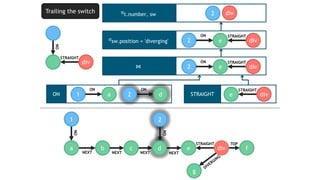
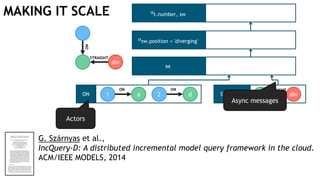
![TRAILING THE SWITCH
seg div
t
STRAIGHT
ON
MATCH (t:Train)-[:ON]->(seg:Segment)
<-[:STRAIGHT]-(sw:Switch)
WHERE sw.position = 'diverging'
RETURN t.number, sw
Evaluate
continuously](https://image.slidesharecdn.com/montreal-spark-meetup-171219060925/85/Compiling-openCypher-graph-queries-with-Spark-Catalyst-22-320.jpg)








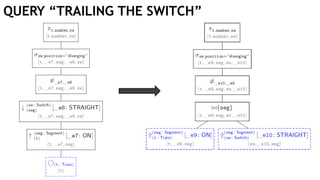

![t, seg
t, seg, t.number
sw, seg
sw, seg, sw.position
t.number, sw.position
πt.number, sw
σsw.position = ′diverging′
⋈
(sw:Switch)−[:STRAIGHT]−>(seg:Segment)(t:Train)−[:ON]−>(seg:Segment)
t.number, sw
t.number, sw
t, seg, sw
t, seg, t.number, sw, sw.position
t, seg, sw
t, seg, t.number, sw, sw.position
t.number
t.number, sw.position
sw.positiont.number
2
1. external schema
2. extra attributes
3. internal schema
This is the current
implementation
SCHEMA
INFERENCING](https://image.slidesharecdn.com/montreal-spark-meetup-171219060925/85/Compiling-openCypher-graph-queries-with-Spark-Catalyst-40-320.jpg)

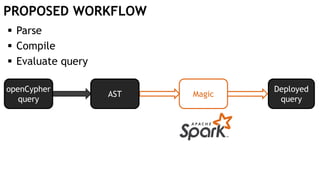
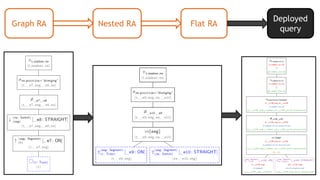
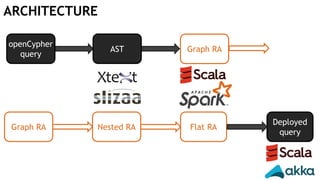
![MATCH (t:Train)-[:ON]->(seg:Segment)
<-[:STRAIGHT]-(sw:Switch)
WHERE sw.position = 'diverging'
RETURN t.number, sw
openCypher
query
AST Graph RA](https://image.slidesharecdn.com/montreal-spark-meetup-171219060925/85/Compiling-openCypher-graph-queries-with-Spark-Catalyst-42-320.jpg)











The document discusses the development of a scalable graph query engine utilizing OpenCypher and Spark Catalyst, focusing on incrementally maintaining views of large graphs with complex queries. It explains the use of a cache for efficient evaluation and highlights various research objectives, including support for incremental views and pattern matching in graph databases. Key research initiatives and benchmarks, such as the LDBC social network benchmark, are also addressed, showcasing the framework and tools supporting graph data management and analytics.



























































