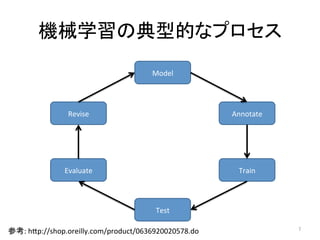
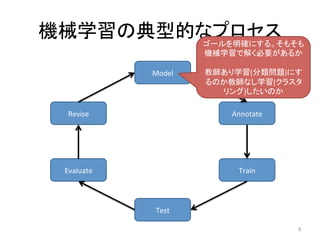
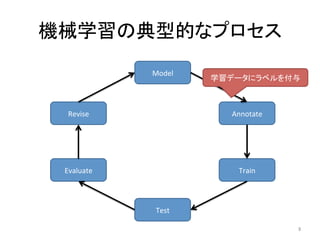
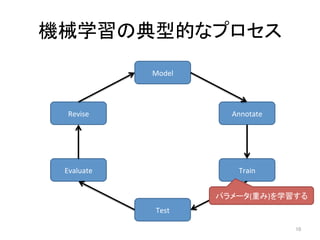
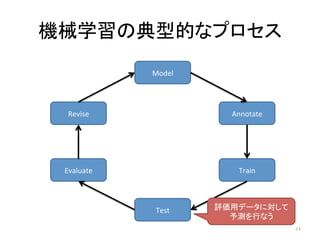
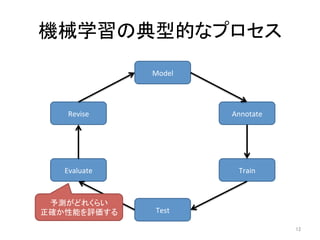
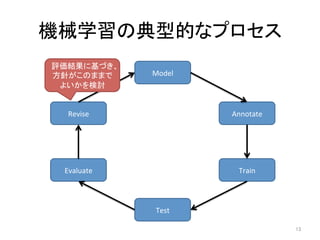
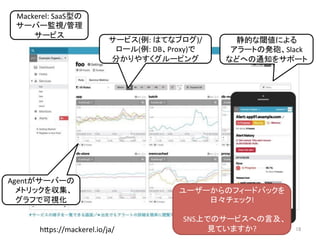
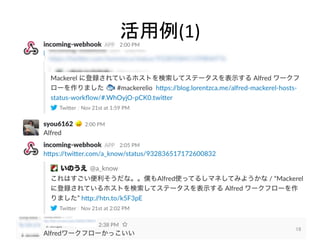
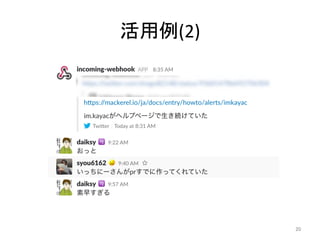
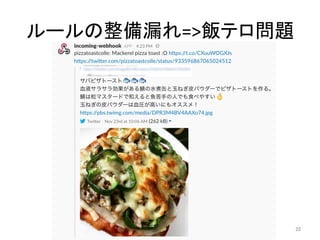
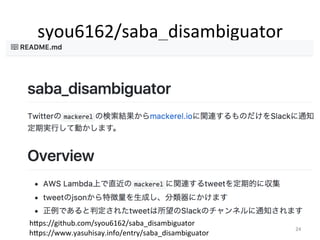
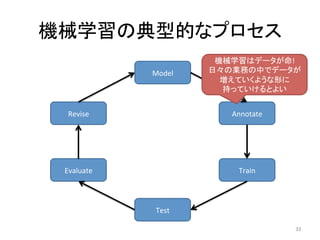
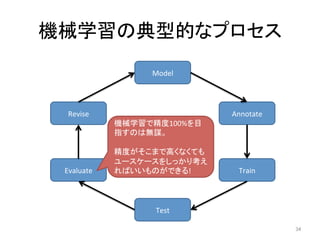
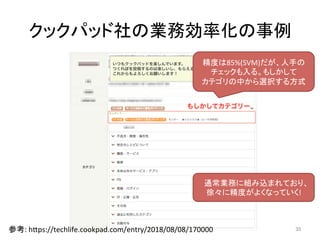
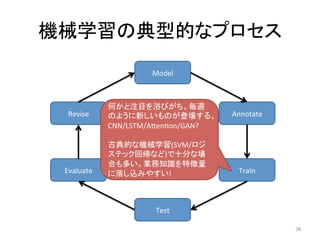
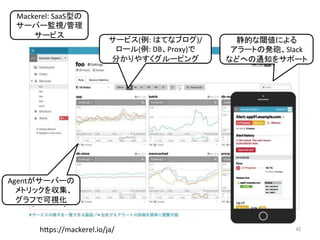
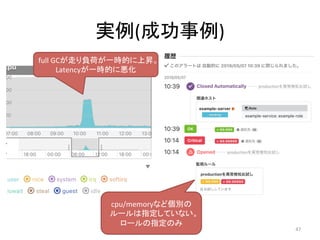
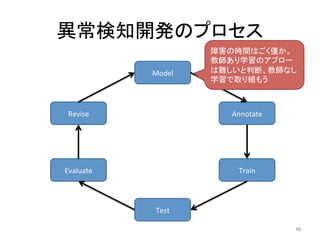
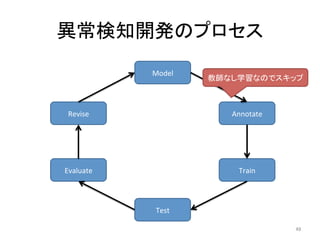
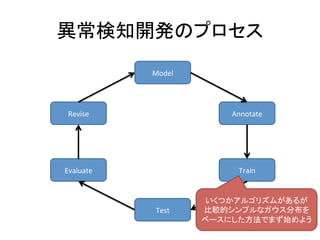
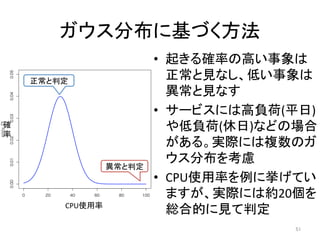
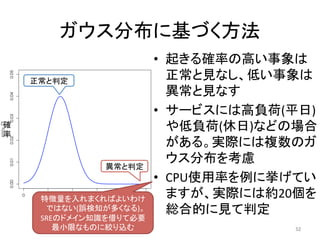
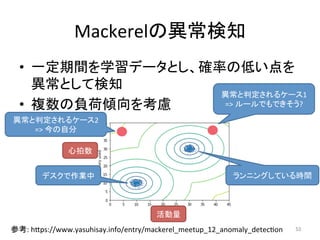
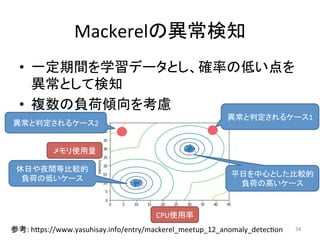
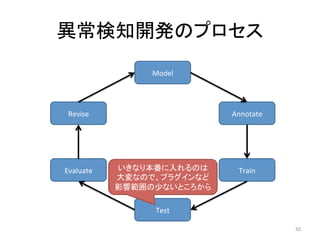
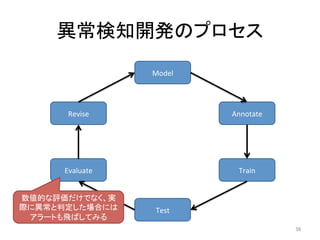
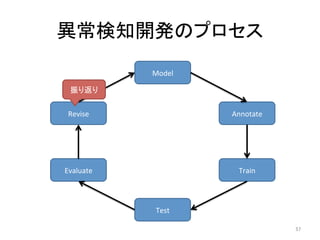
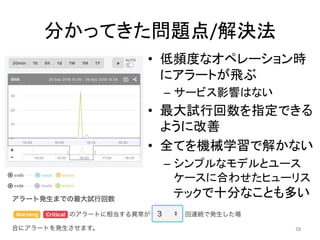
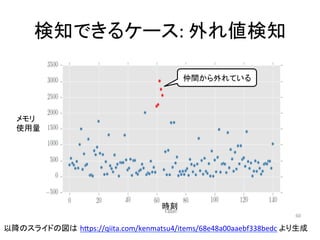
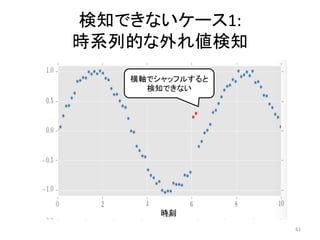
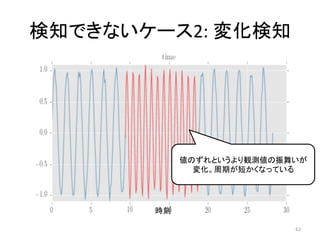
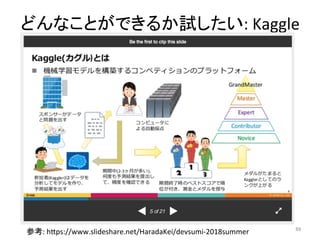
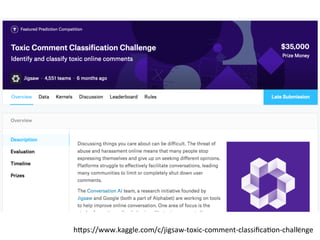
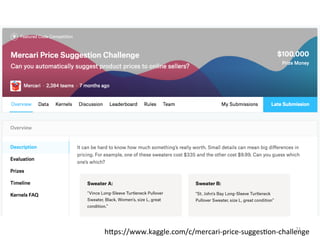
人工知能ブームに伴ない機械学習関係のニュースを聞かない日はないほど機械学習は普及しつつありますが、自分でやってみる/自社で導入するにはまだハードルが高いと感じる方も多いかと思います。このセッションでは、いわゆるデータサイエンティストではなくアプリケーションエンジニアが機械学習を使った機能開発を行なうメリットやその楽しさについて、はてなでの事例を交えながらお話ししたいと思います。 https://event.shoeisha.jp/devsumi/20180928/session/1802/