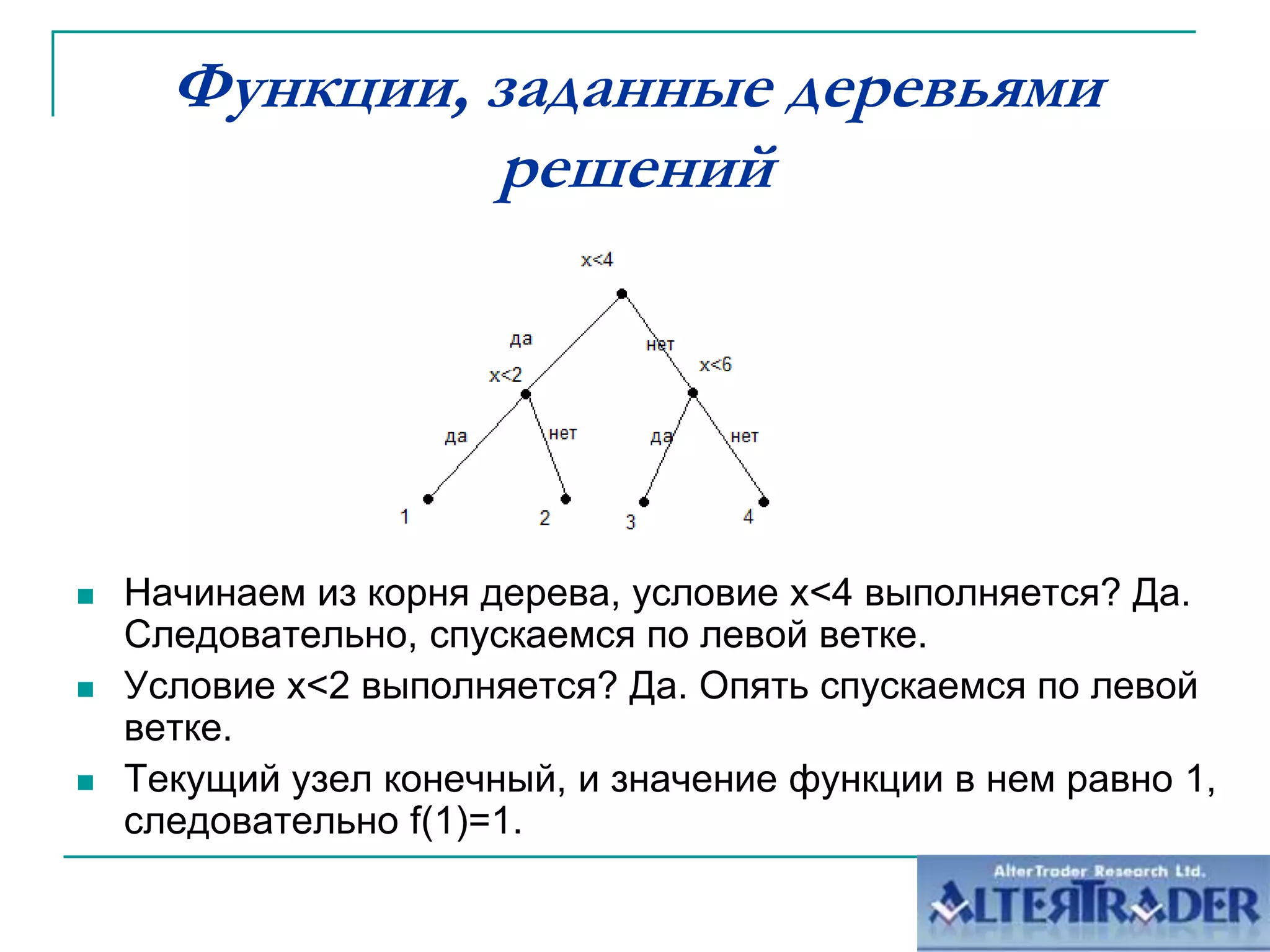
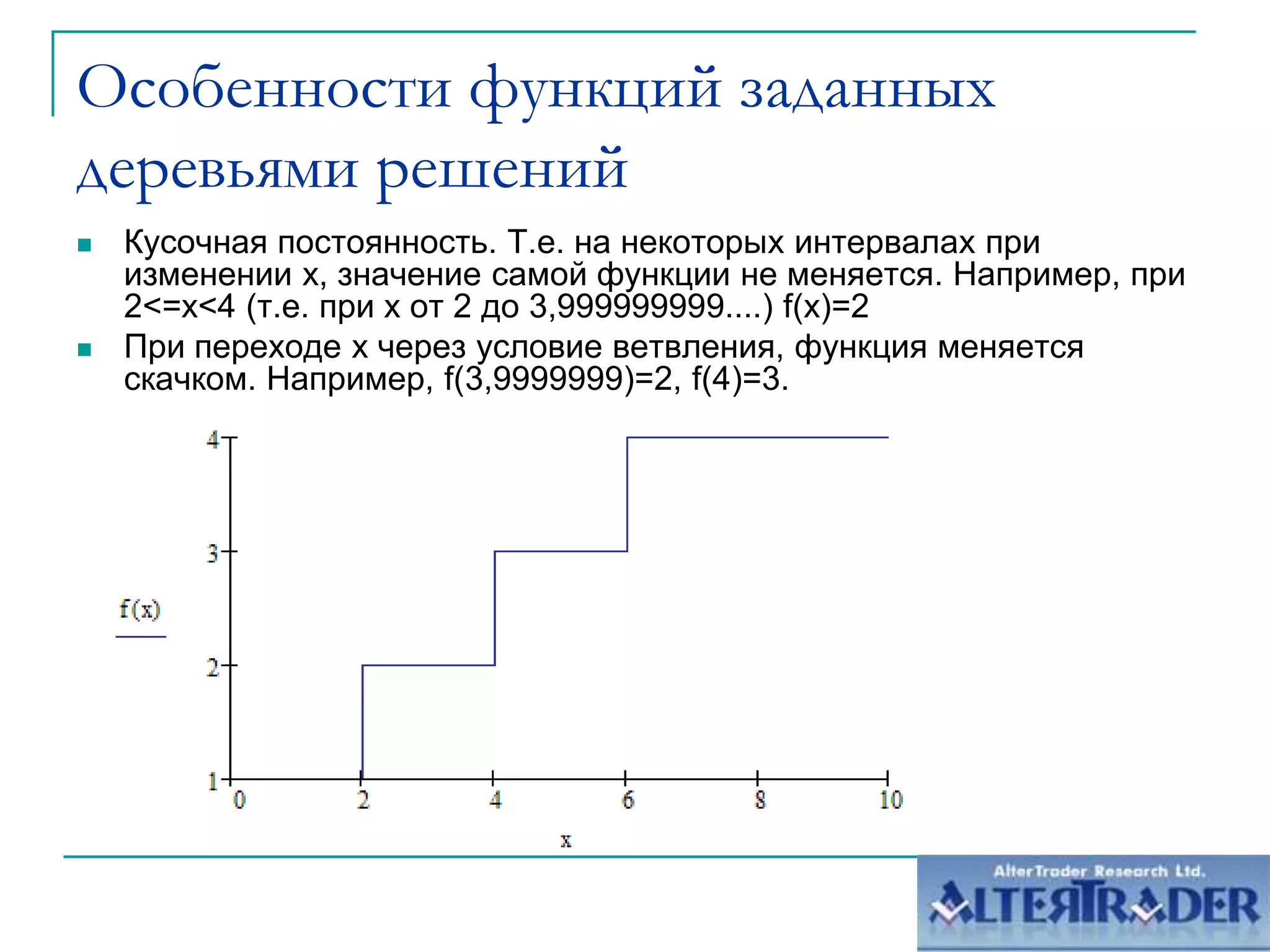
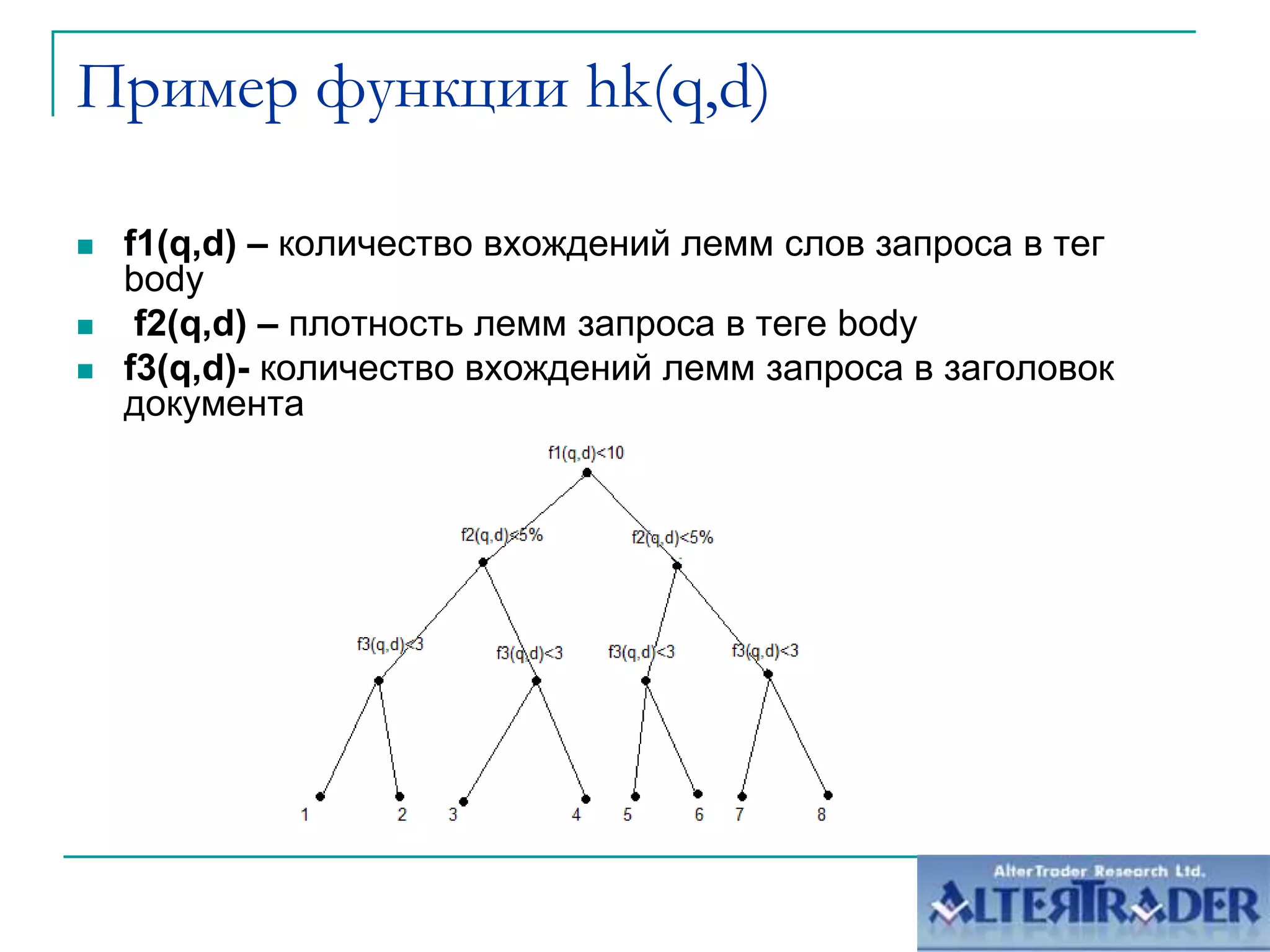
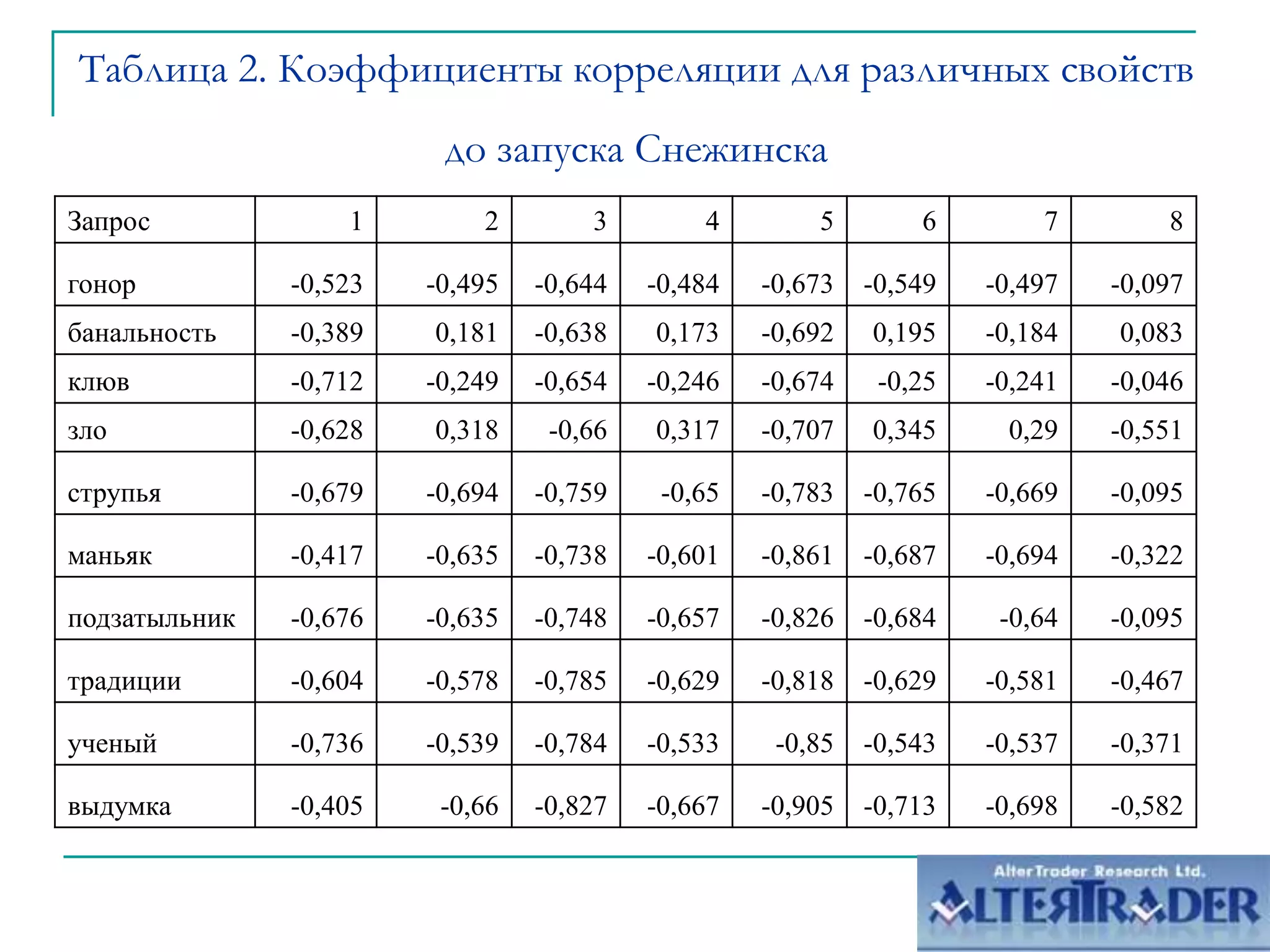
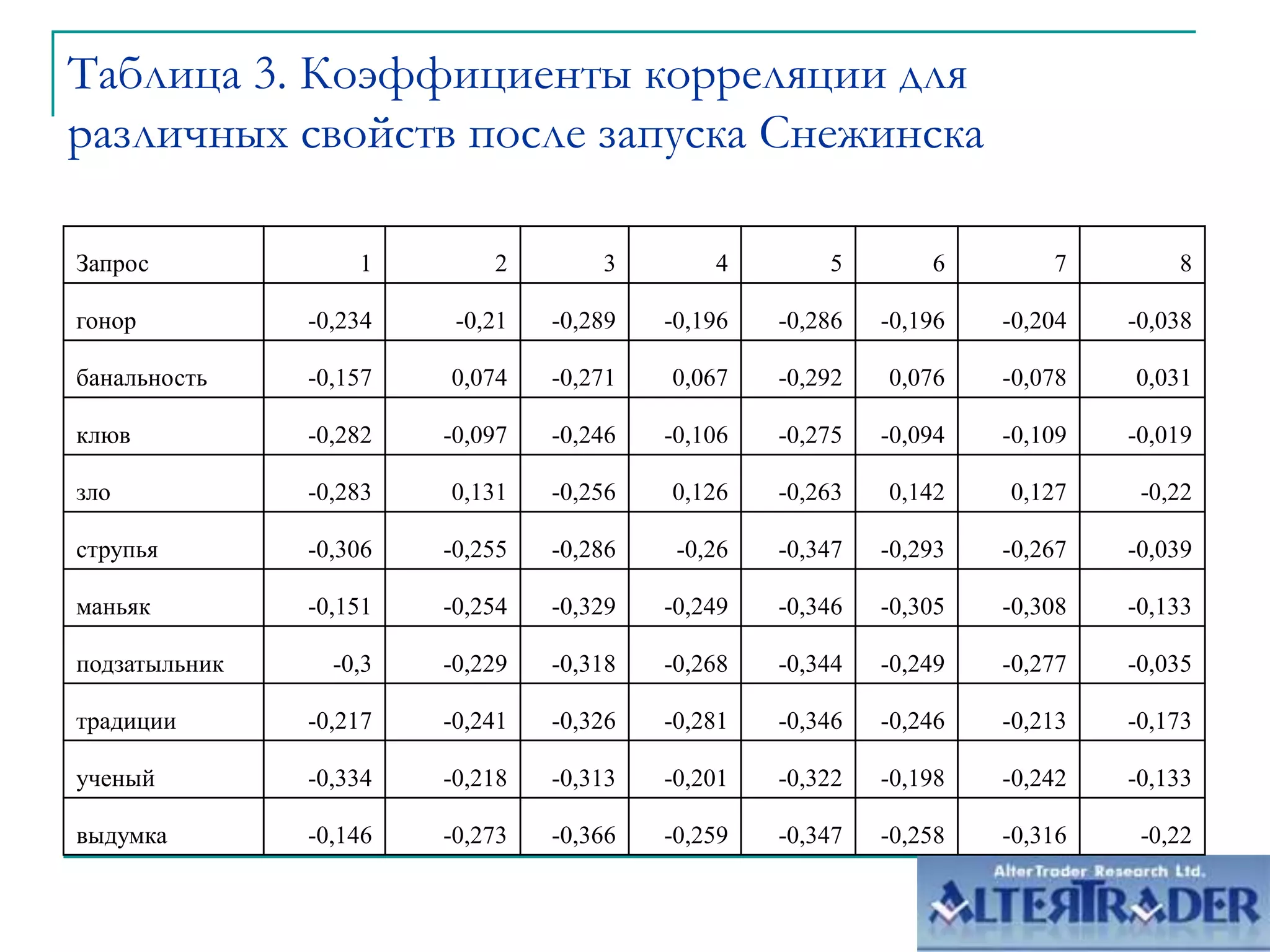
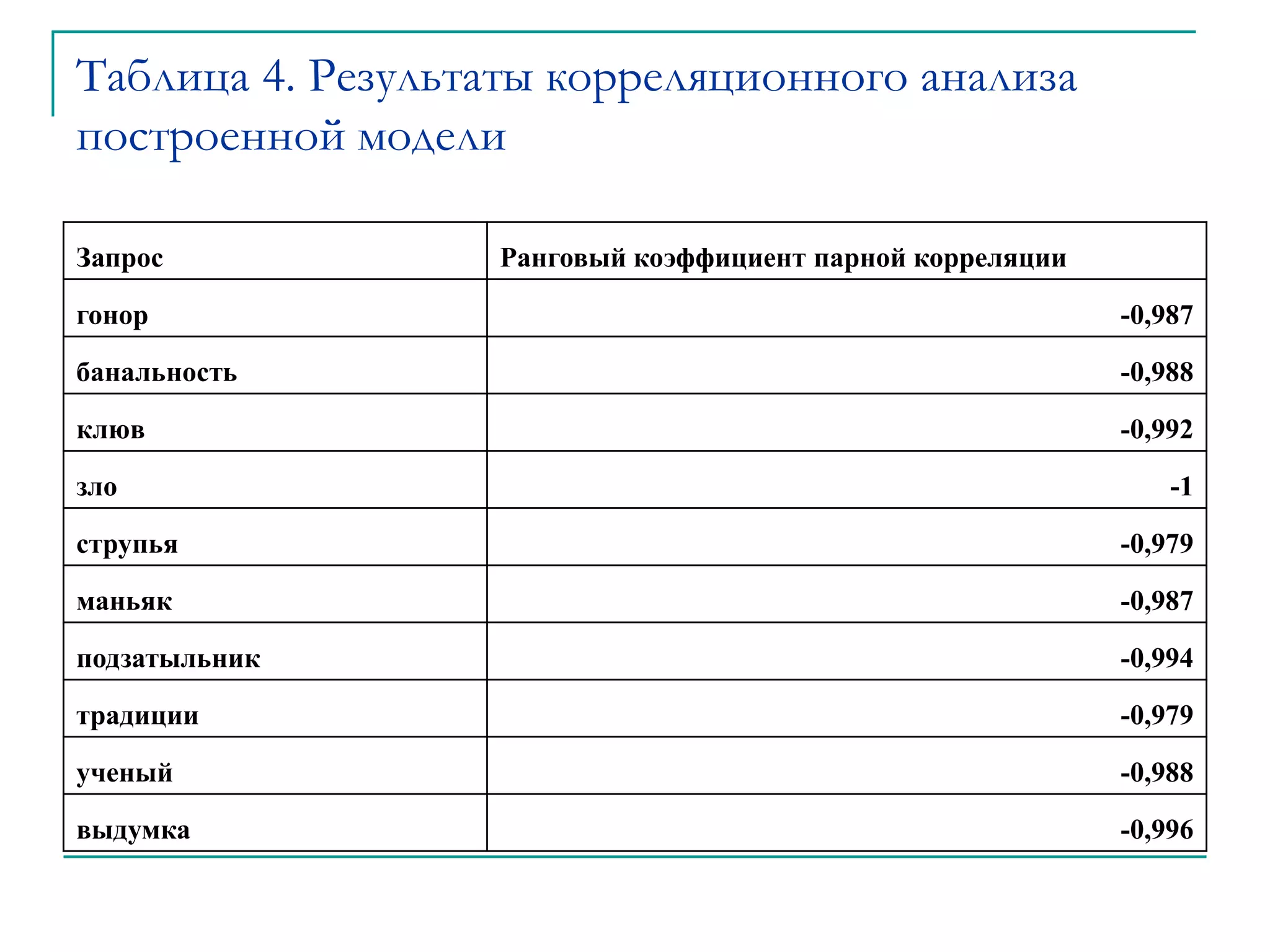
Документ обсуждает оптимизацию сайтов под алгоритм MatrixNet на основе метрического анализа. Он описывает функционал ранжирования, свойства деревьев решений и методы корреляционного анализа, применяемые для улучшения позиций сайтов в поисковой выдаче. Основное внимание уделяется современным вызовам в корреляции и плюсам и минусам подхода к созданию моделей ранжирования.