Download as PDF, PPTX

















![PGroonga & Zulip Powered by Rabbit 2.2.1
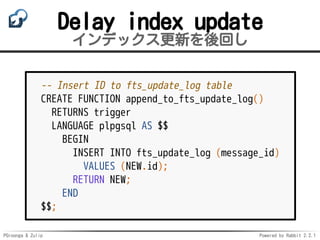
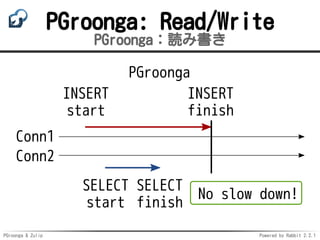
Delay index update
インデックス更新を後回し
cursor.execute("LISTEN ftp_update_log") # Wait
cursor.execute("SELECT id, message_id FROM fts_update_log")
ids = []
for (id, message_id) in cursor.fetchall():
cursor.execute("UPDATE zerver_message SET search_tsvector = "
"to_tsvector('zulip.english_us_search', "
"rendered_content) "
"WHERE id = %s", (message_id,))
ids.append(id)
cursor.execute("DELETE FROM fts_update_log WHERE id = ANY(%s)",
(ids,))](https://image.slidesharecdn.com/zpnight-pgroonga-and-zulip-170904063306/85/PGroonga-Zulip-21-320.jpg)





The document discusses the integration of pgroonga, a PostgreSQL extension for fast full-text search, with the chat tool Zulip. It compares the performance of pgroonga against other text search methods, highlighting its speed, support for all languages, and ability to maintain performance during index updates. Additionally, it details features such as query expansion, synonym support, and fuzzy search capabilities.
















































