Download to read offline

![•
[…] To design and build innovative and robust prototypes and
demos for tools that analyse and/or integrate open web data for
educational purposes.](https://image.slidesharecdn.com/yourhistory-slides-131129043905-phpapp01/75/yourHistory-entity-linking-for-a-personalized-timeline-of-historic-events-3-2048.jpg)






![Extract text
attributes
•
•
•
•
•
•
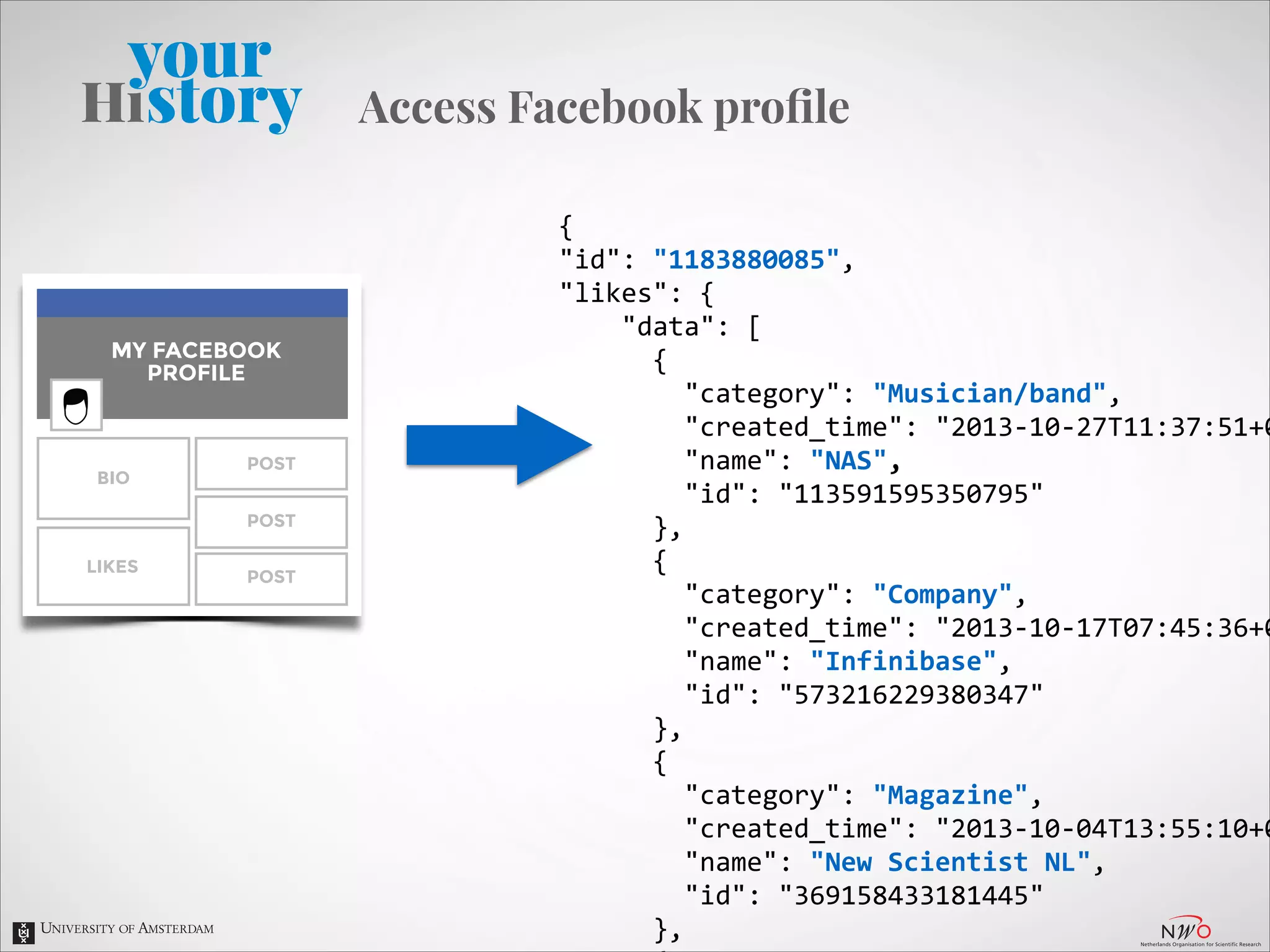
{
"id":
"1183880085",
"likes":
{
"data":
[
{
"category":
"Musician/band",
"created_time":
"2013-‐10-‐27T11:37:51+0000",
"name":
"NAS",
"id":
"113591595350795"
},
{
"category":
"Company",
"created_time":
"2013-‐10-‐17T07:45:36+0000",
"name":
"Infinibase",
"id":
"573216229380347"
},
{
"category":
"Magazine",
"created_time":
"2013-‐10-‐04T13:55:10+0000",
"name":
"New
Scientist
NL",
"id":
"369158433181445"
},
{
"category":
"Tv
show",
"created_time":
"2010-‐05-‐09T01:06:27+0000",
"name":
"The
Wire",
"id":
"5991693871"
}
]
}
•
•
•
•
•
•
•
•
•
•
•
•
•
•
Story
Omroep
Maxim
Gamer01
Breaking
Bad
AT5
Mad
Men
The
Wire
Monty
Python's
Flying
Circus
Flight
of
the
Conchords
Donnie
Darko
Flevopark
Film
Festival
Do
The
Right
Thing
A
Clockwork
Orange
Wild
Style
Princess
Mononoke
The
Fountain
Pi
Northfork
La
Haine
Zen
and
the
Art
of
Motorcycle
Maintenance
Moon
Palace
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
Fountainhead
The
Wind-‐Up
Bird
Chronicle
Wu-‐Tang
J.Cole
NAS
Pusha
T
ASAP
Rocky
Ab-‐Soul
Chance
The
Rapper
Cannibal
Ox
Bonobo
Aesop
Rock
Boards
Of
Canada
Jurassic
5
GREMS
Quasimoto
Strange
Journey
Volume
Three
Drop
Velvet
MODESELEKTOR
IAM
Derek
The
Onion
Imgur
De
Speld
Wu-‐Tang](https://image.slidesharecdn.com/yourhistory-slides-131129043905-phpapp01/75/yourHistory-entity-linking-for-a-personalized-timeline-of-historic-events-22-2048.jpg)









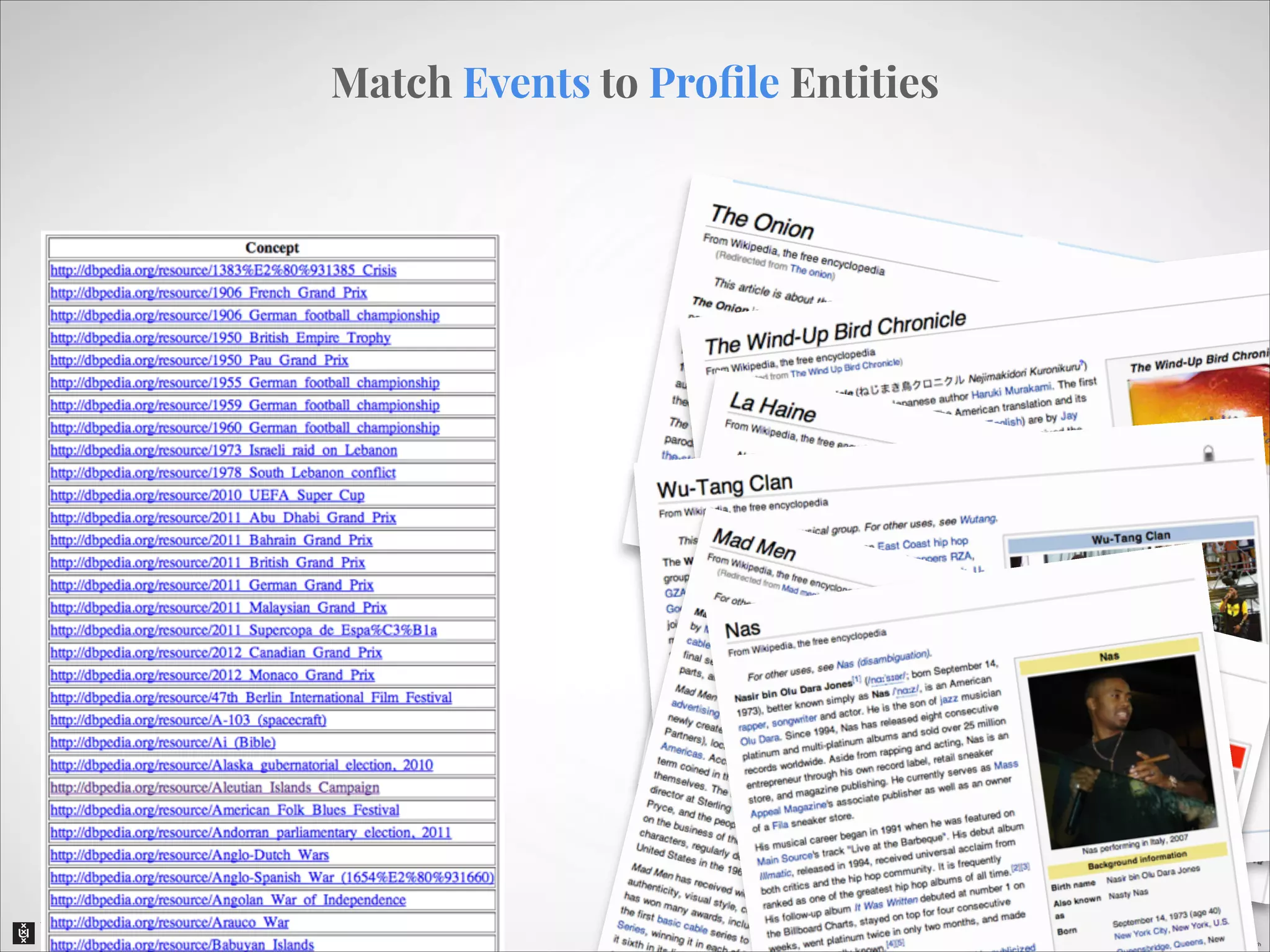
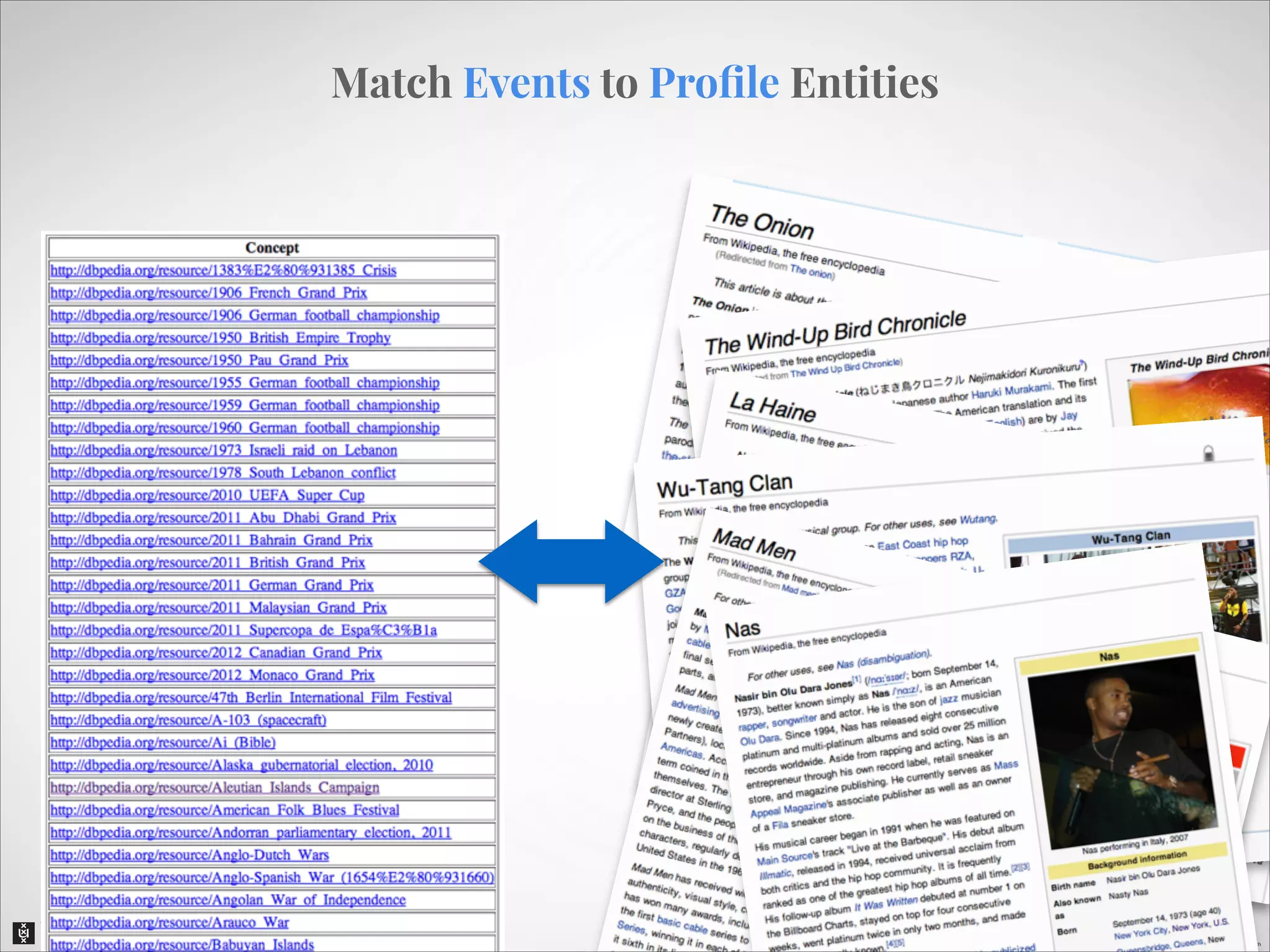
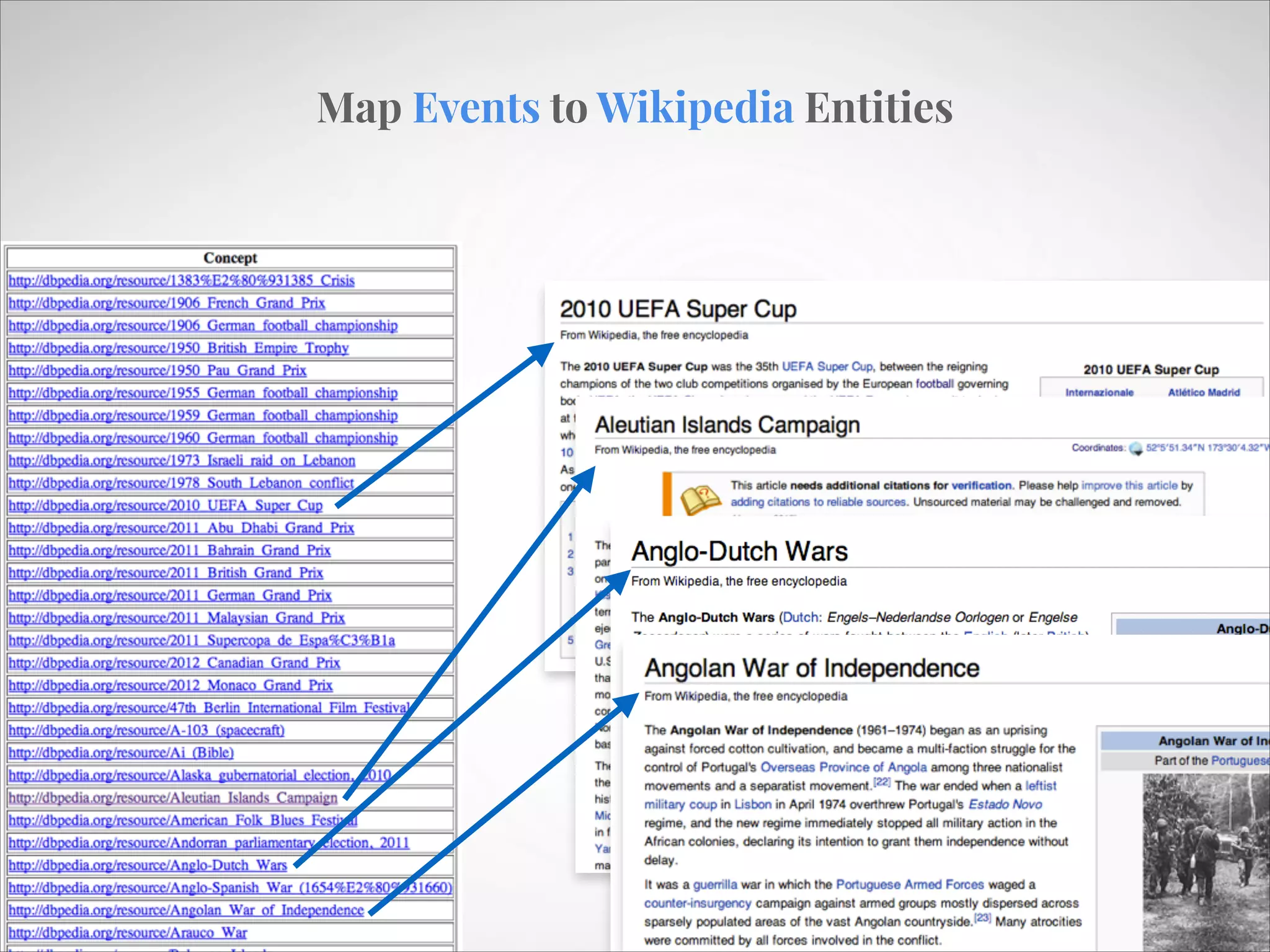

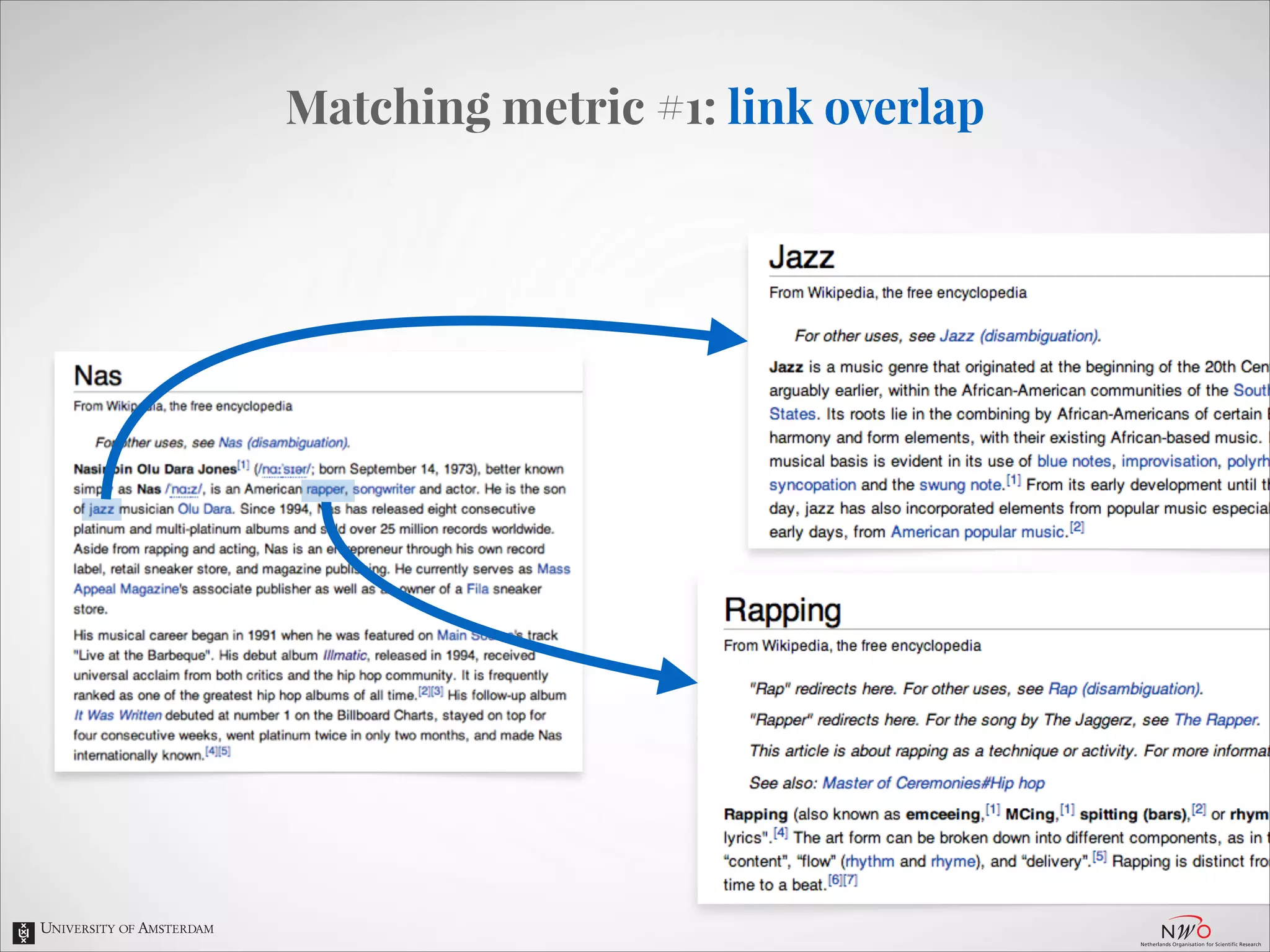
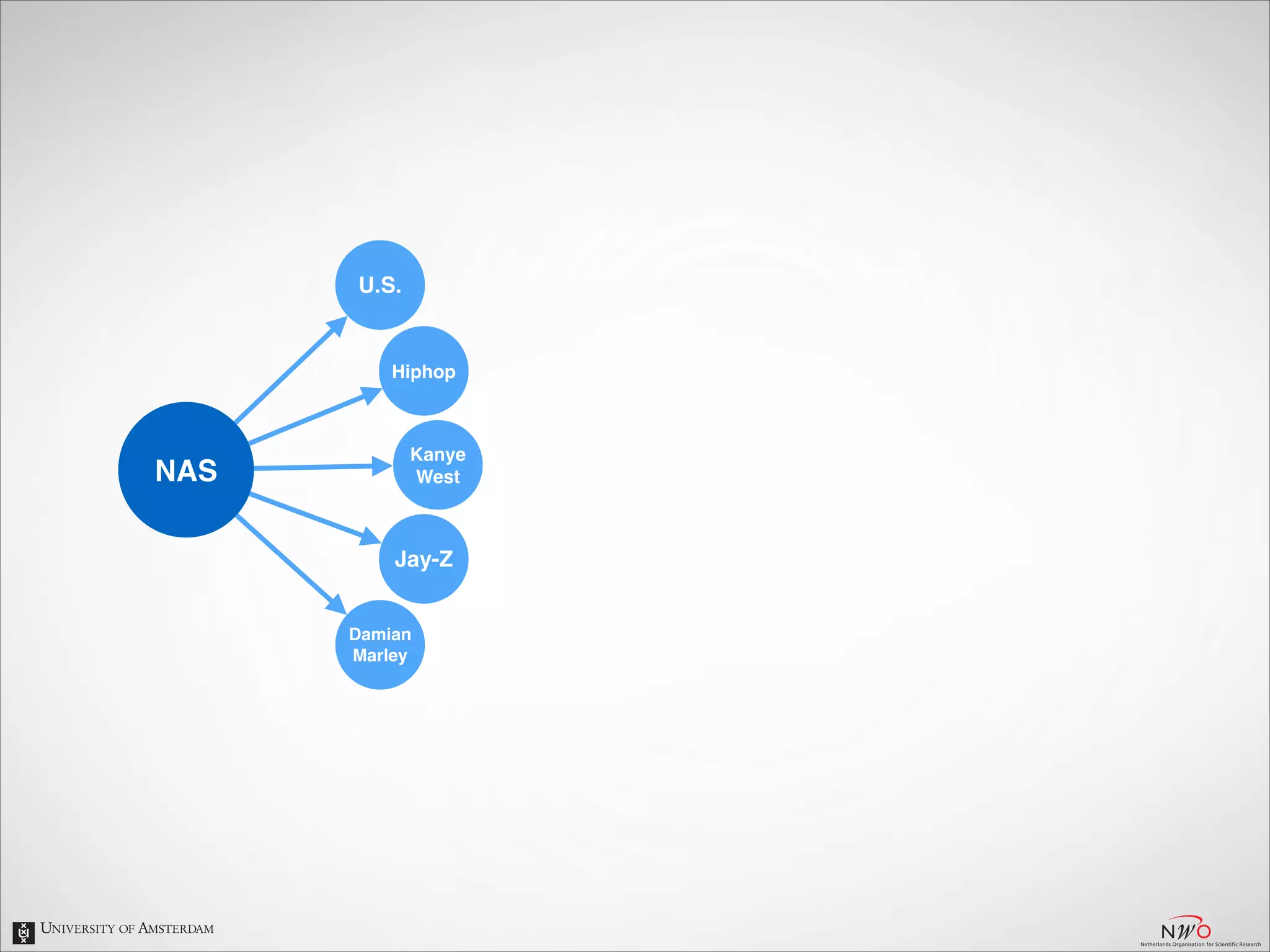
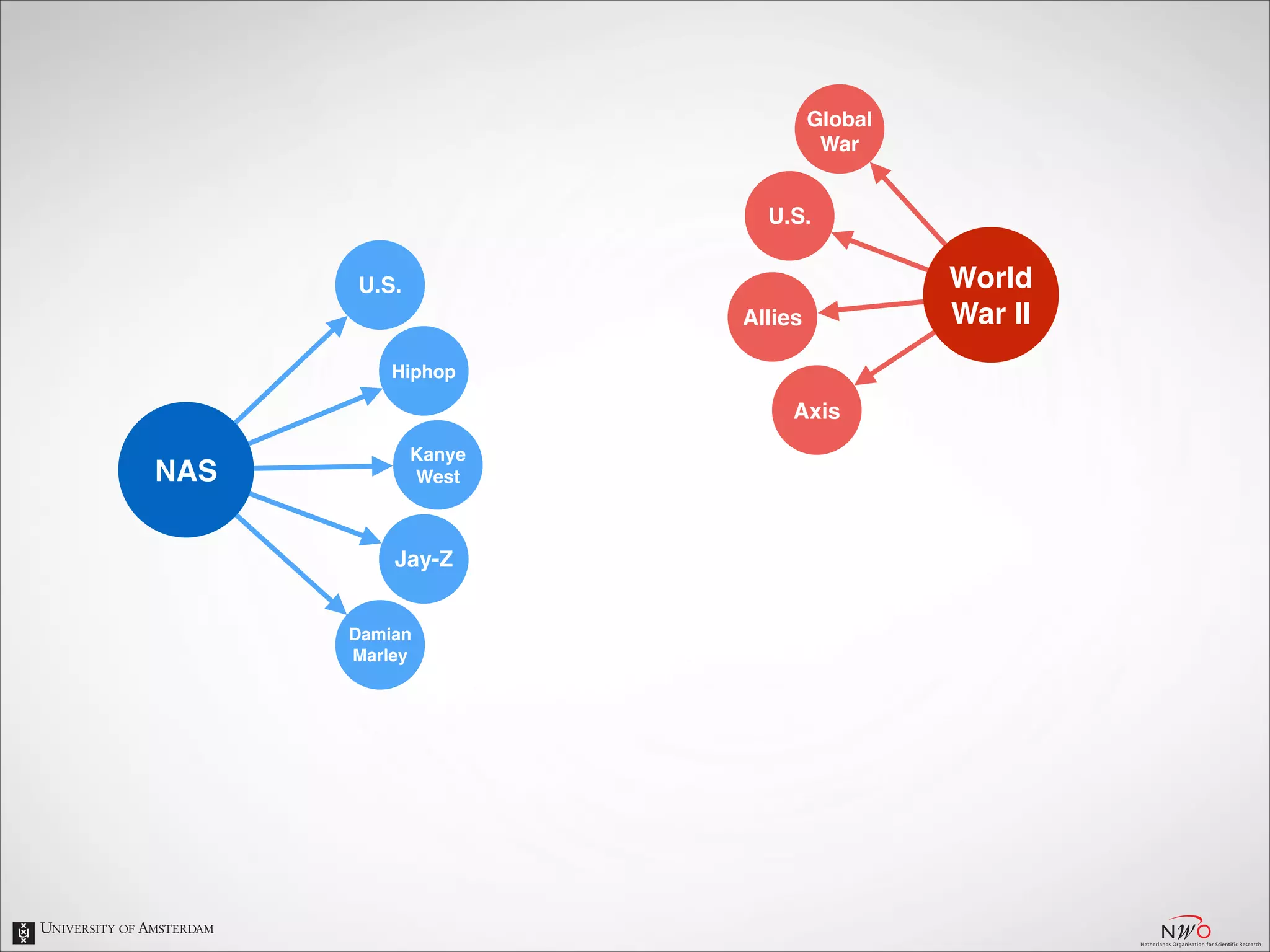
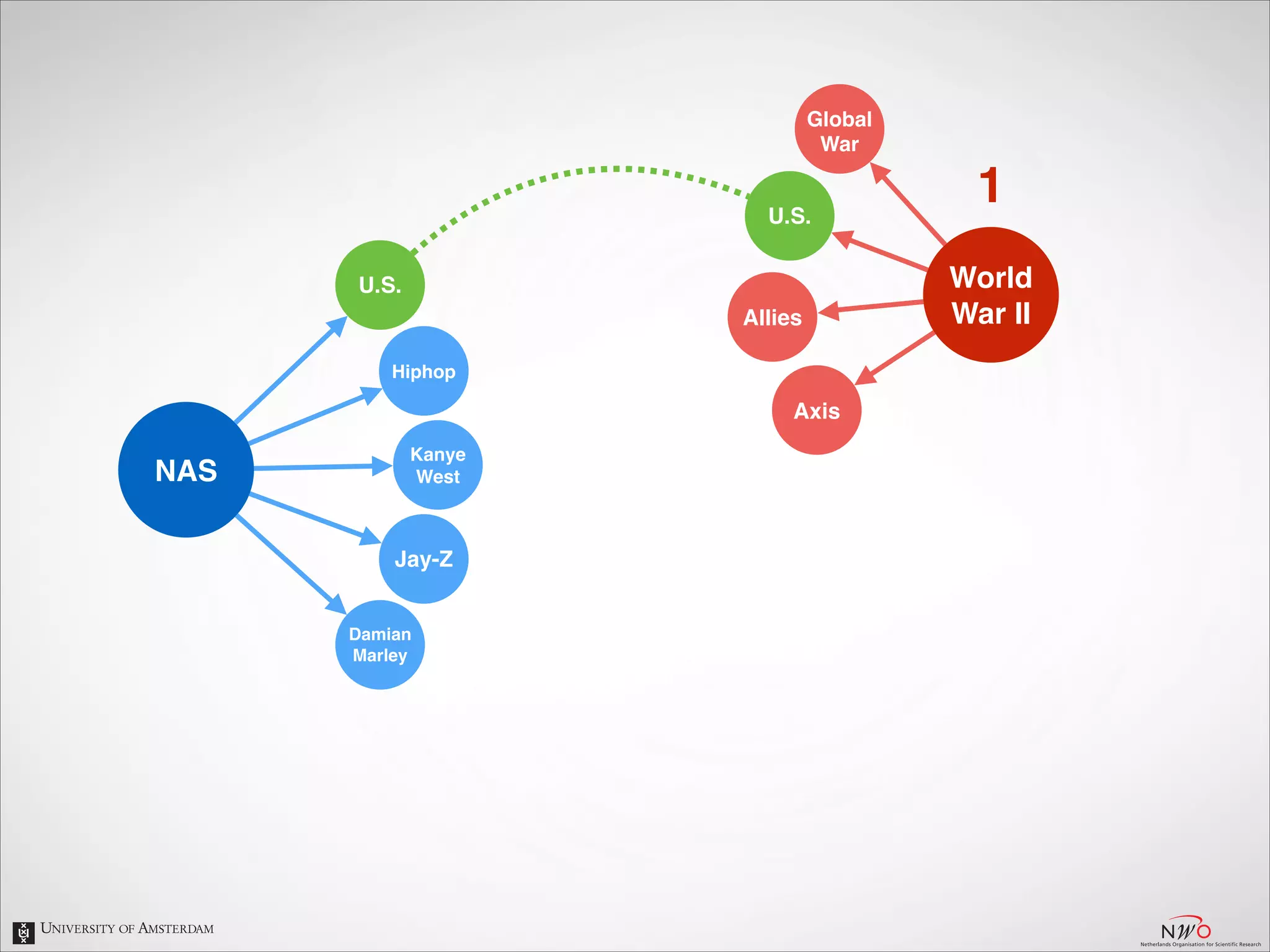
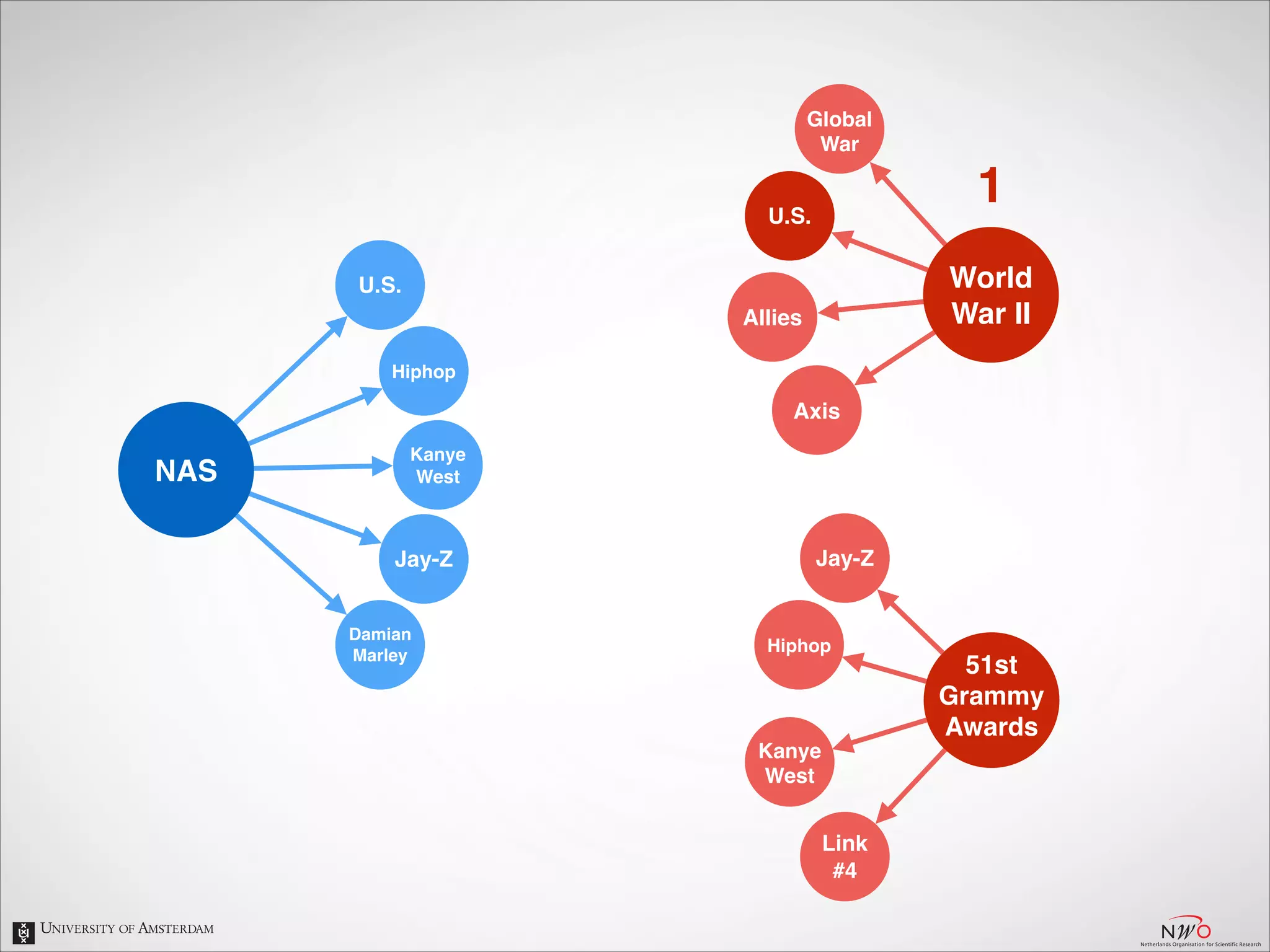
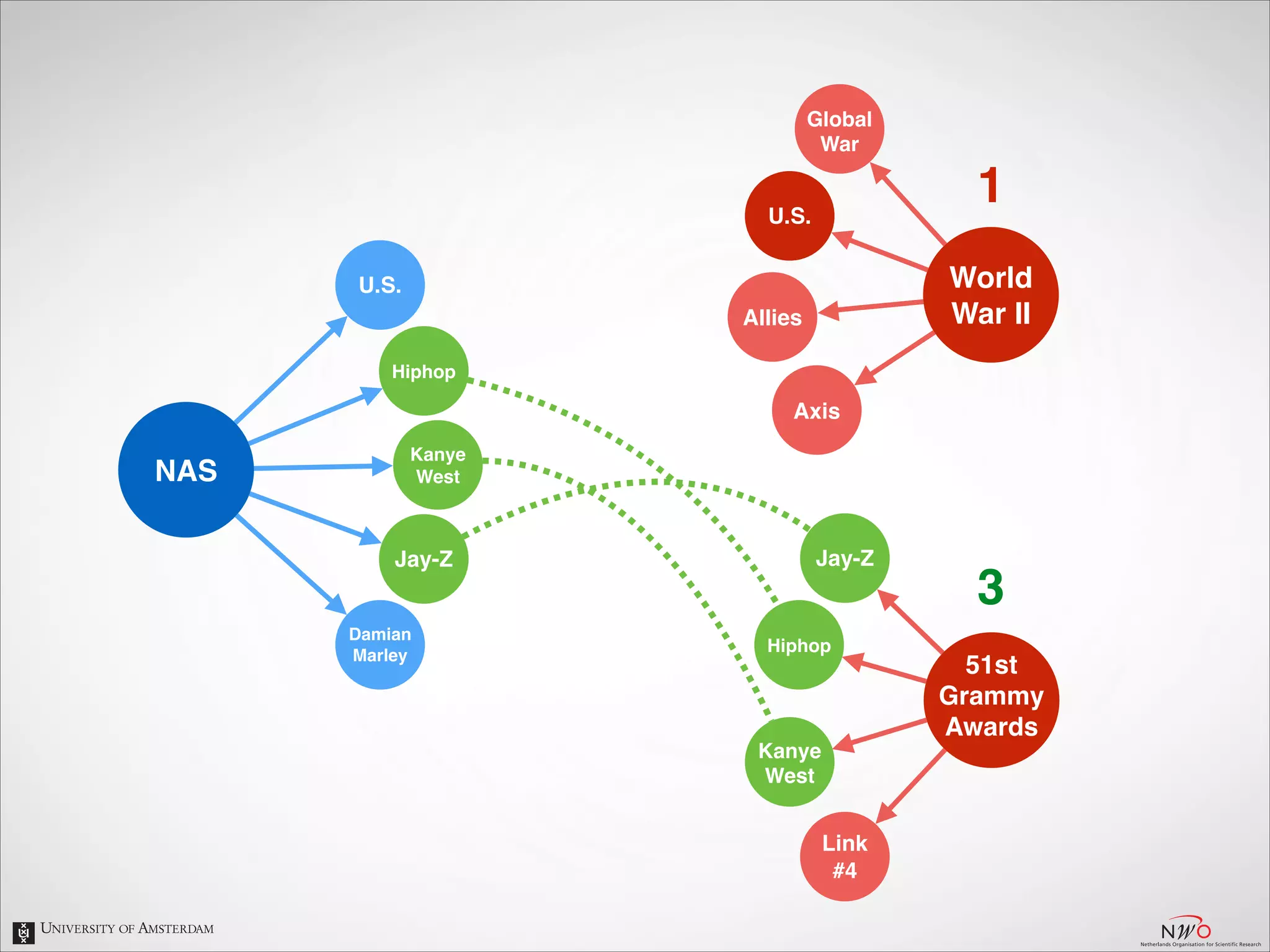


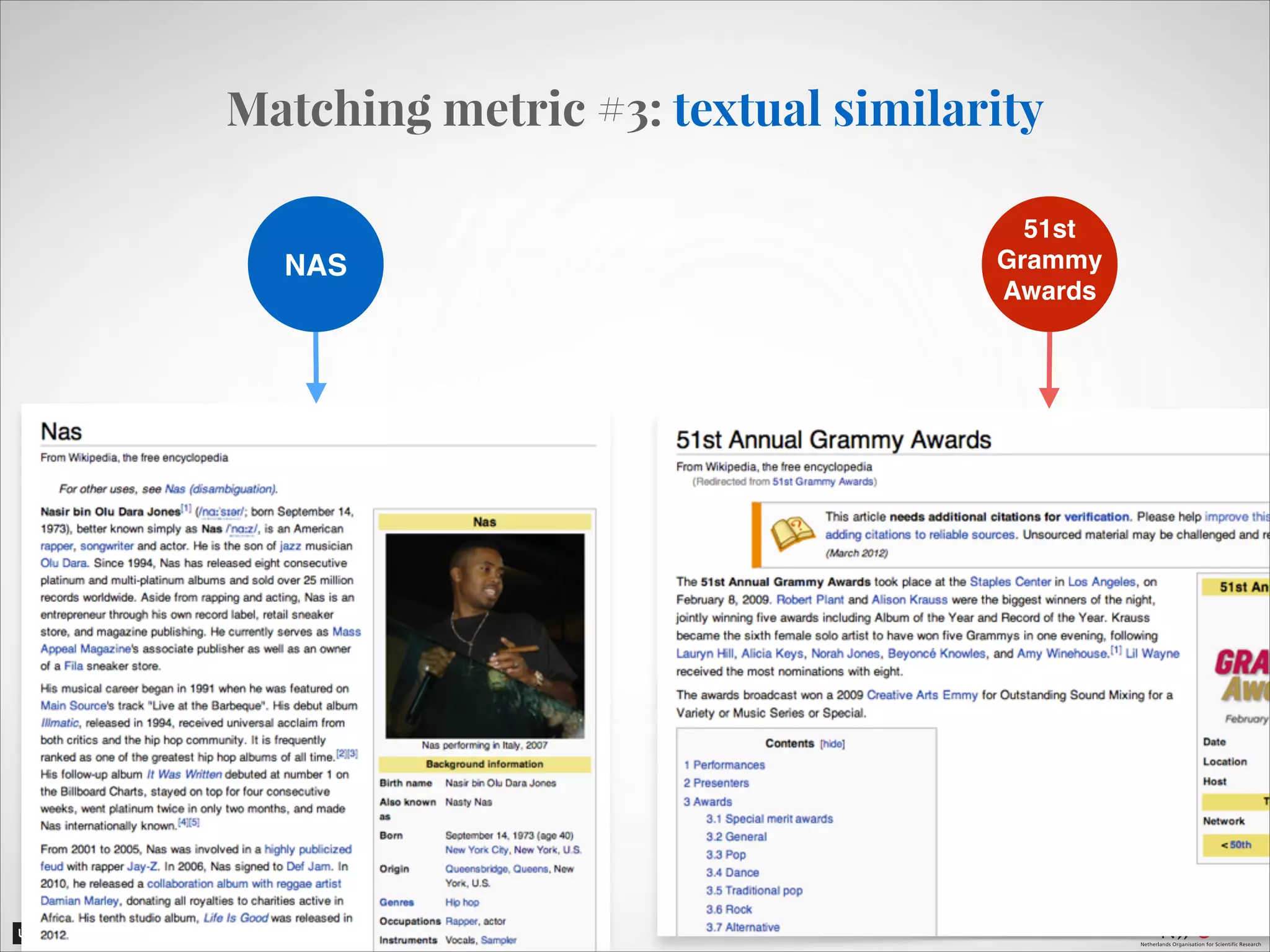
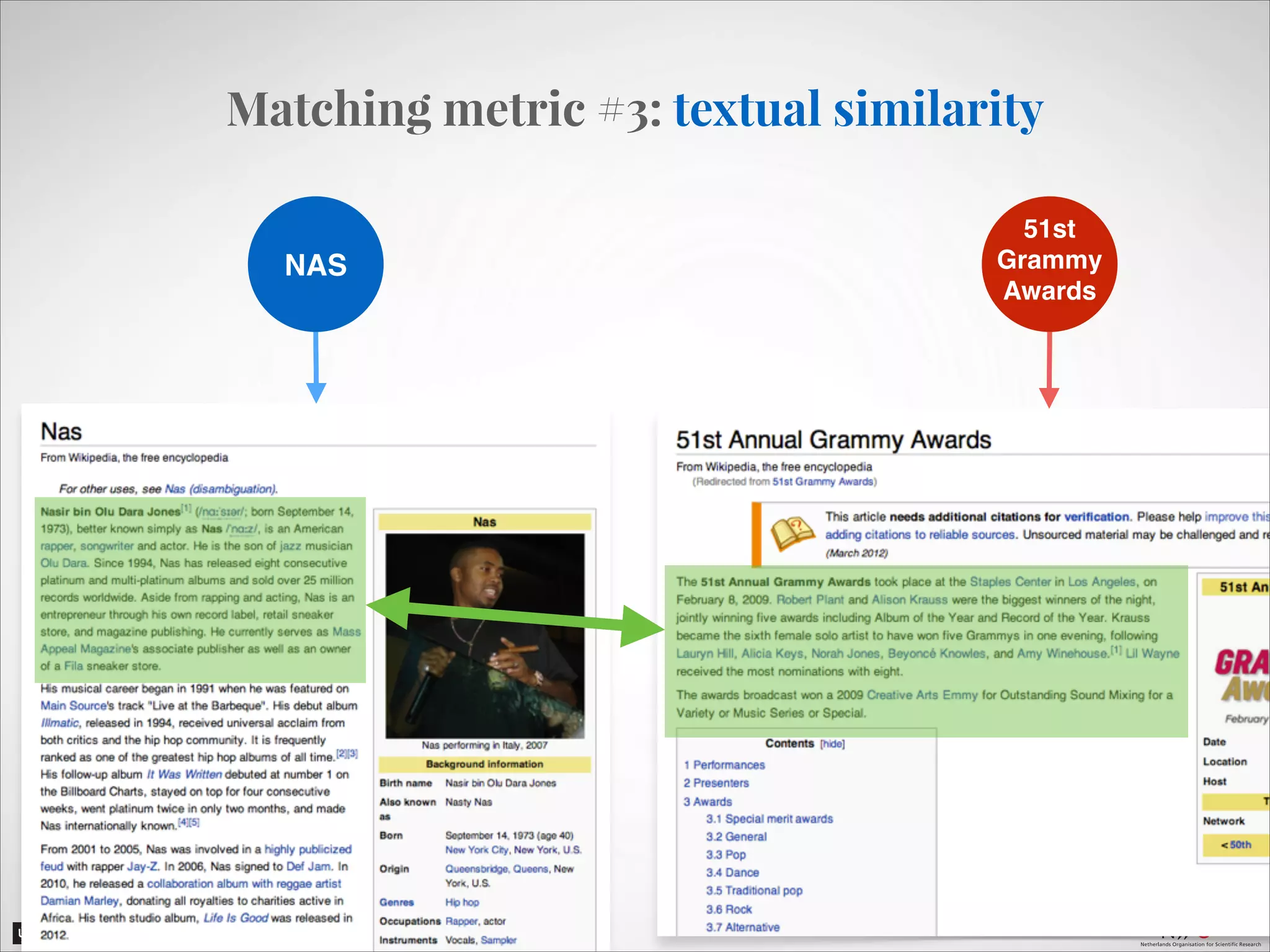


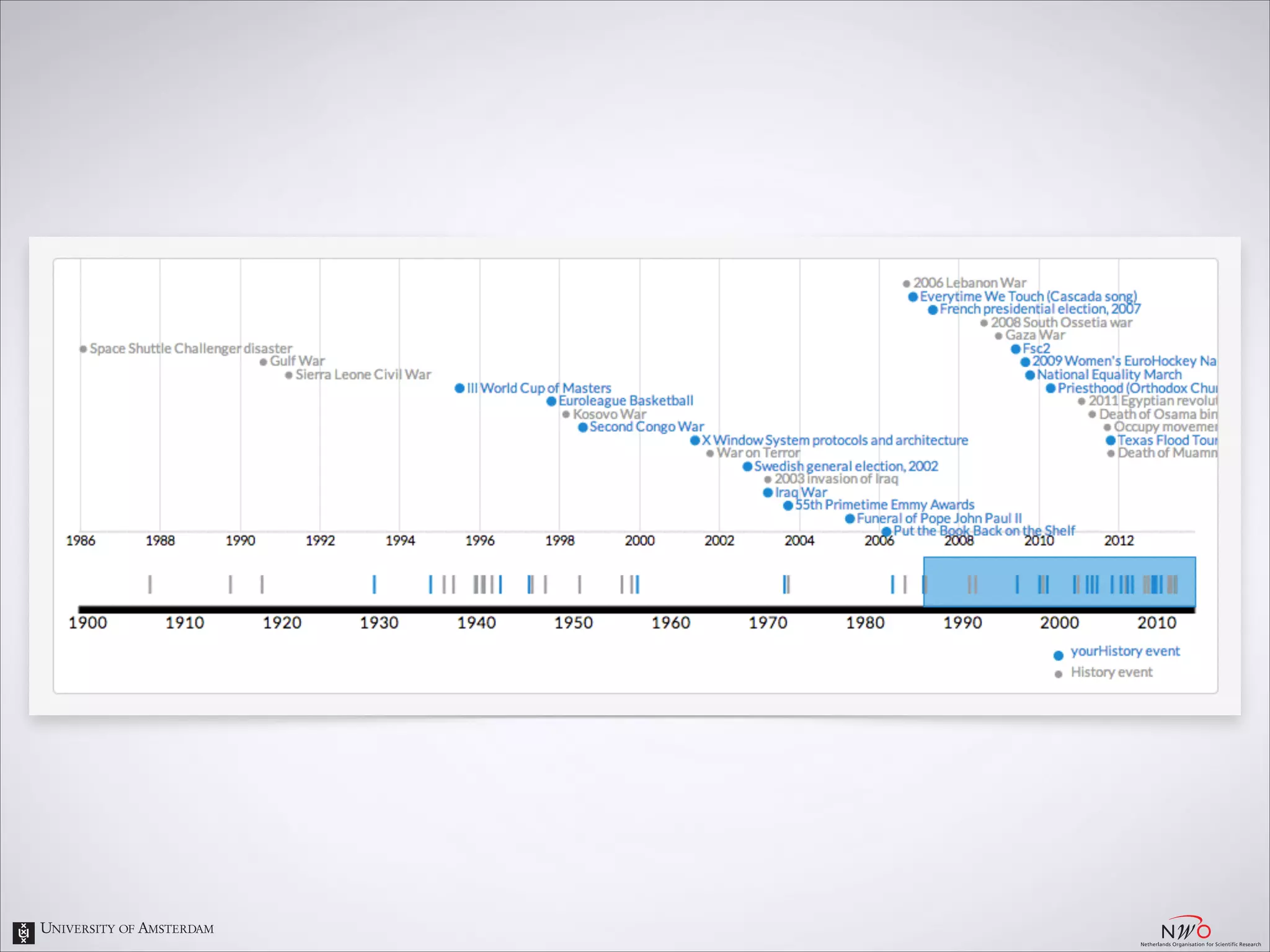
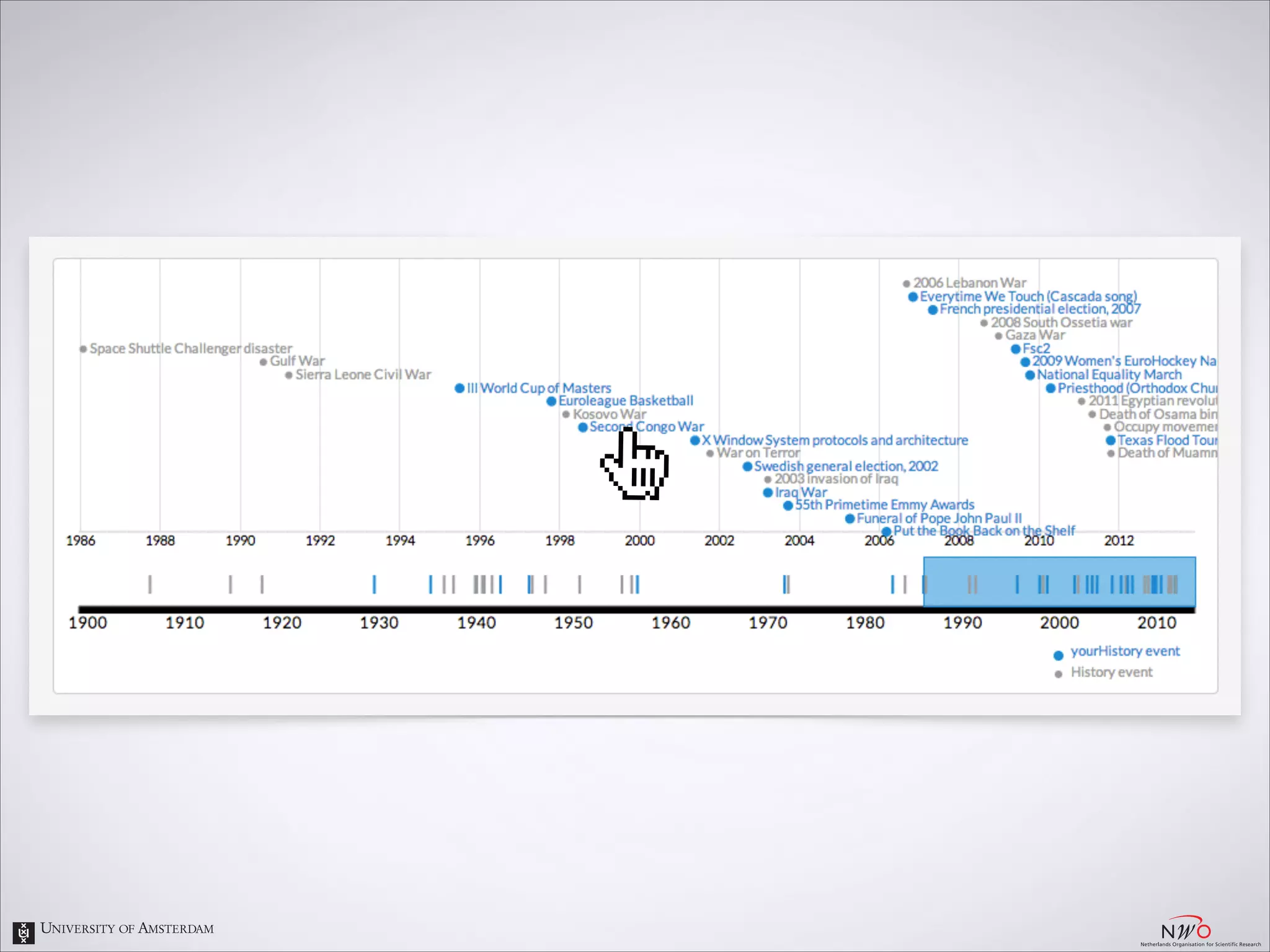


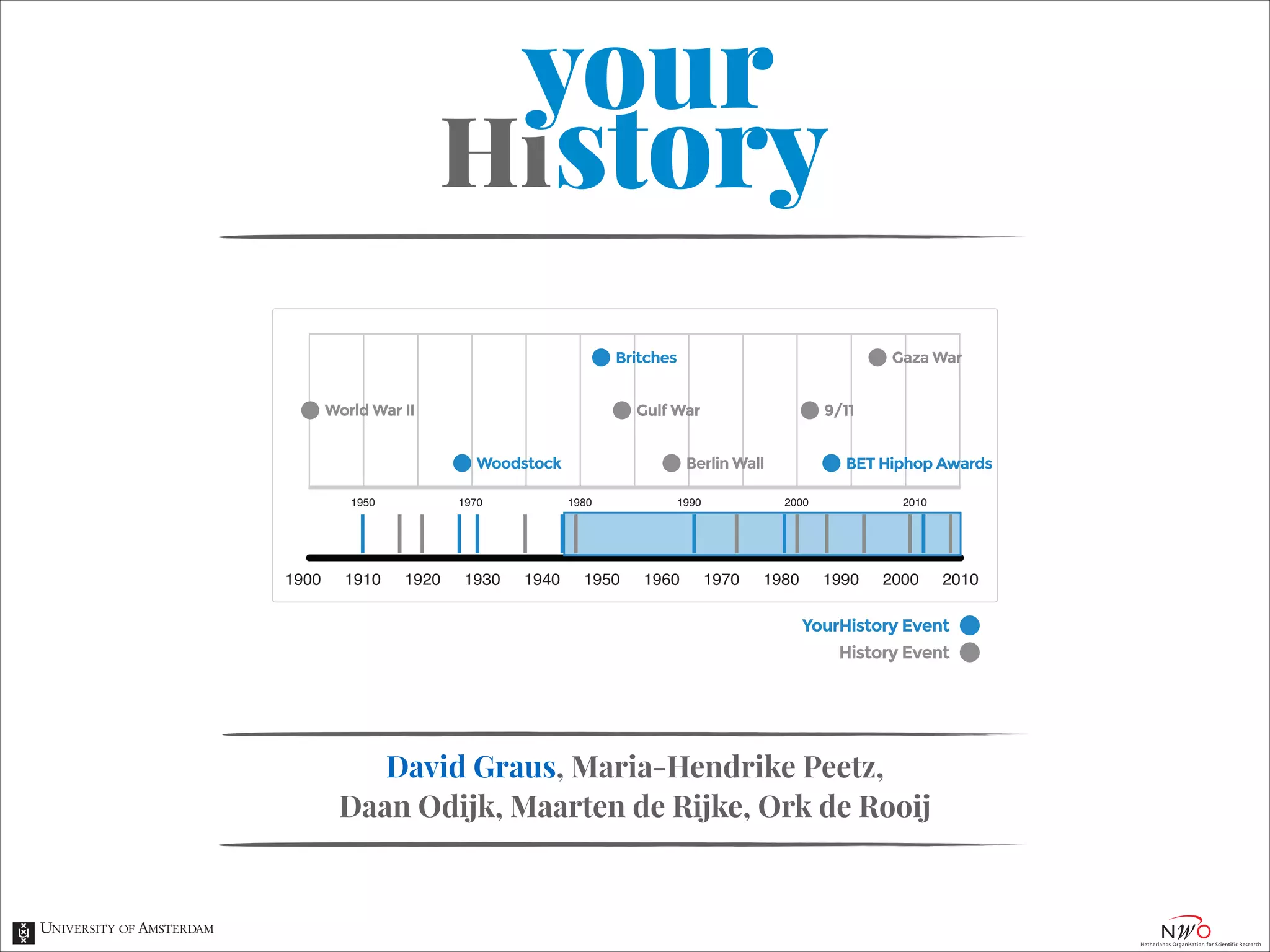
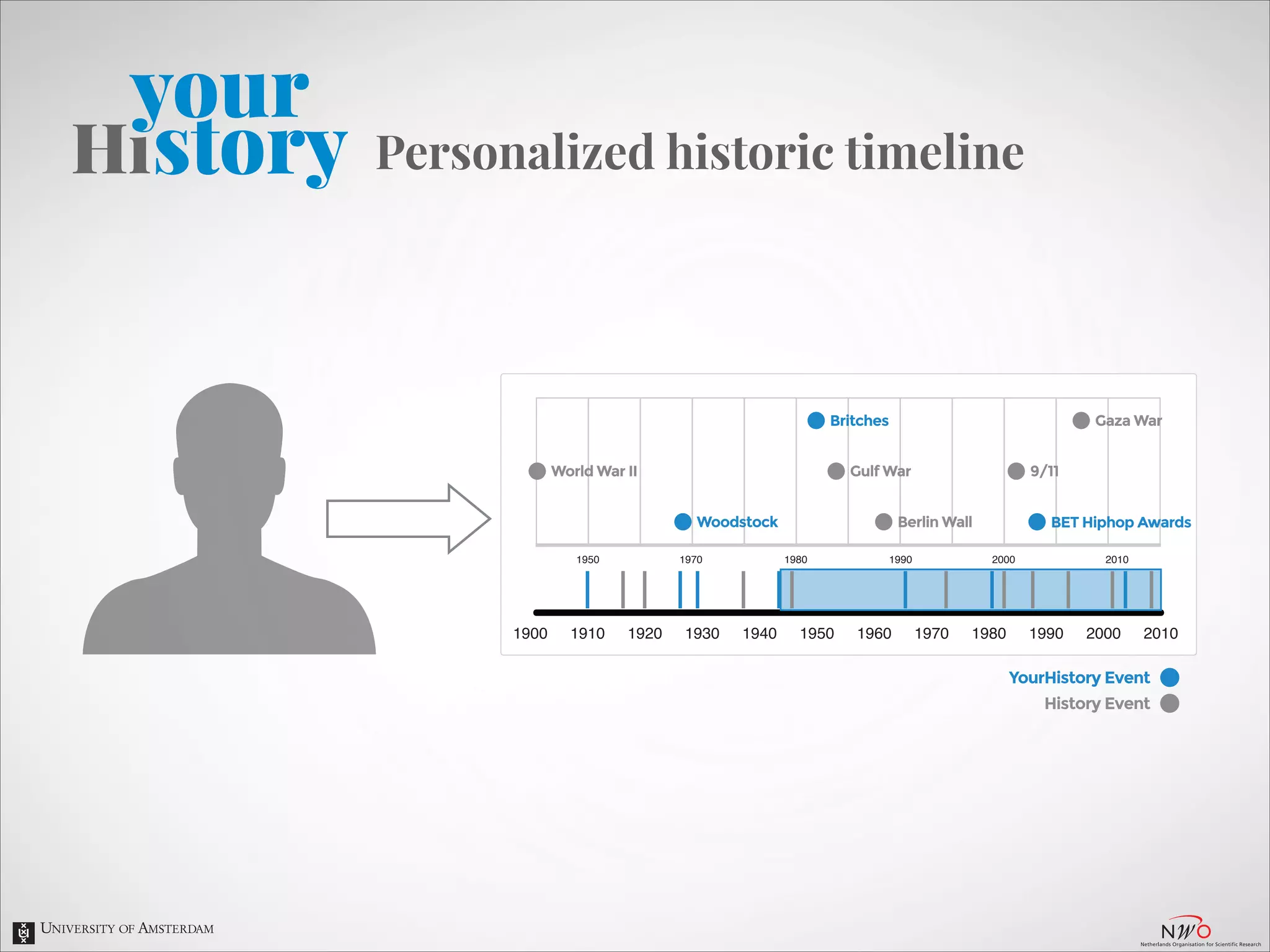
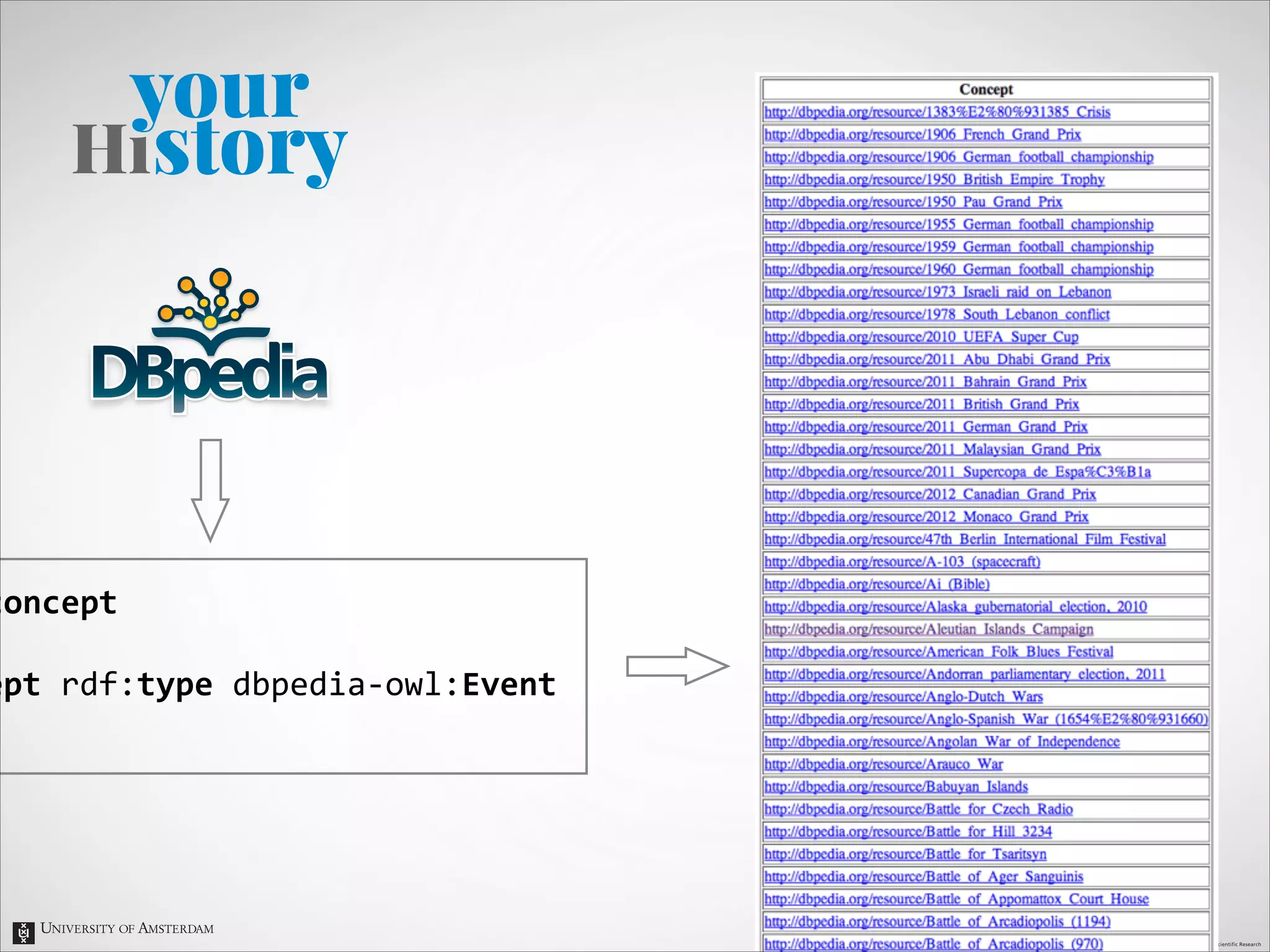
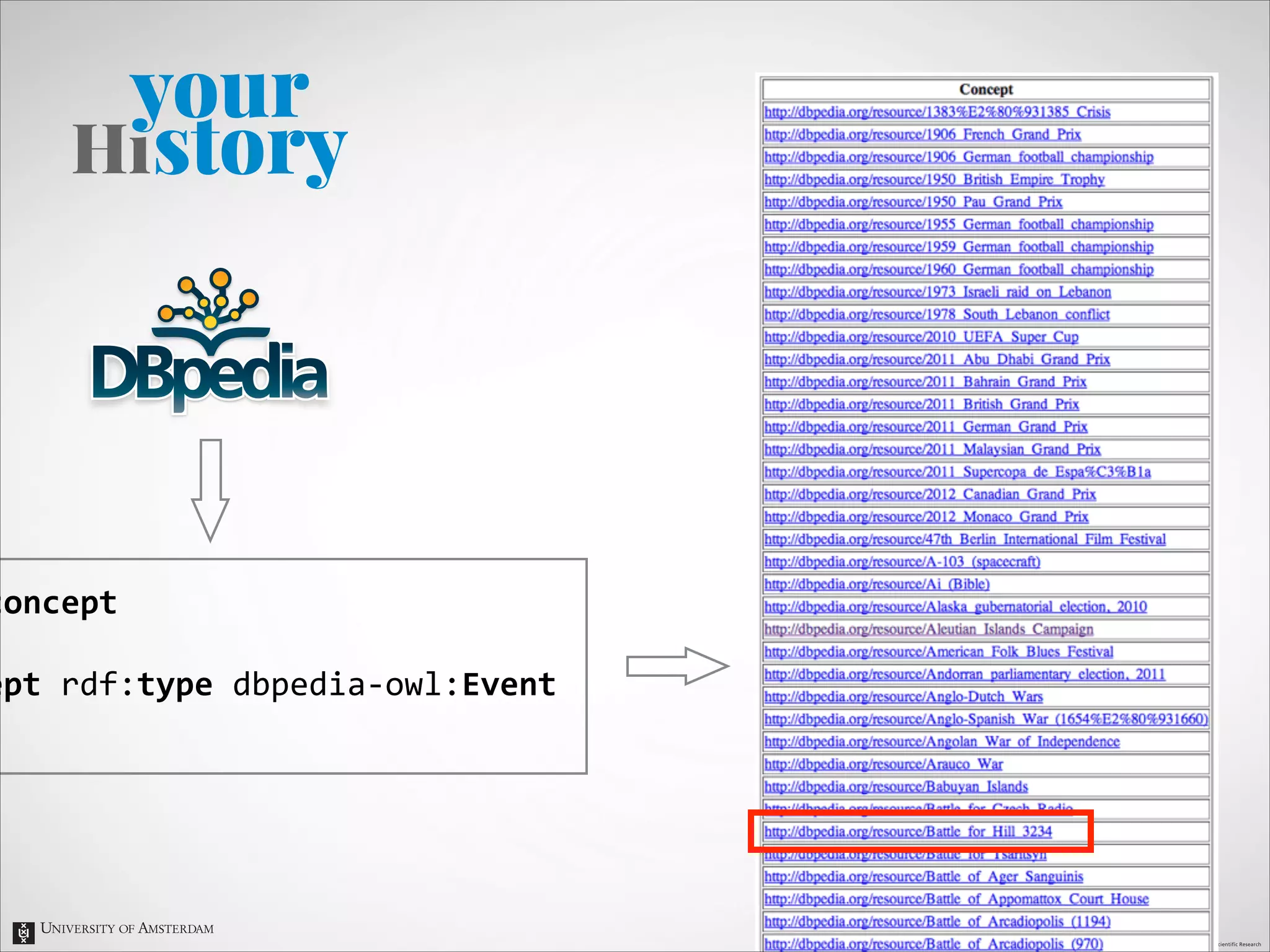
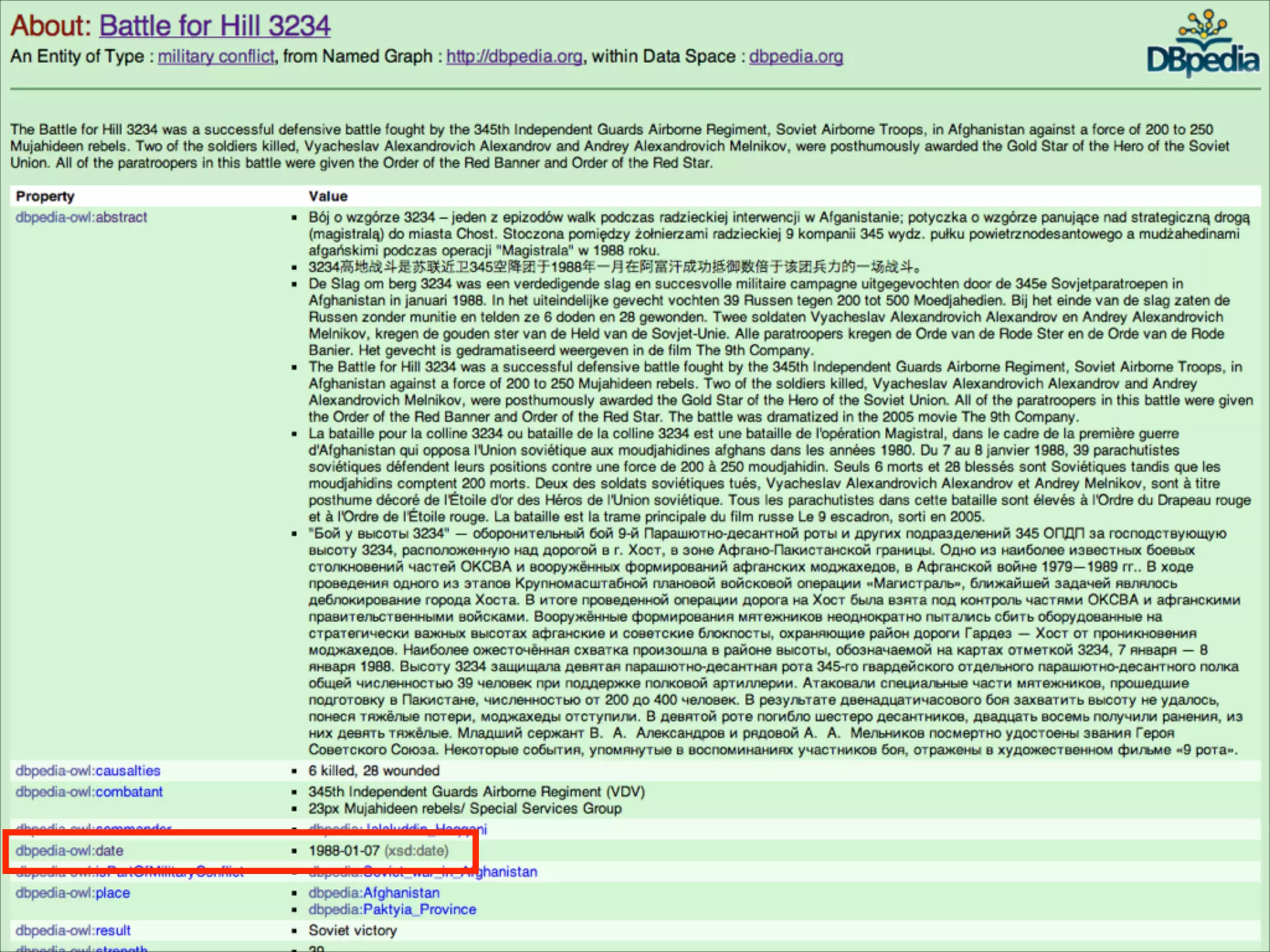
The document describes an entity linking approach to generate a personalized timeline of historic events for a user. It involves 4 main parts: (1) fetching candidate historic events from DBpedia, (2) generating a user profile based on information extracted from the user's Facebook profile, (3) matching the candidate events to the user's interests in their profile, and (4) scoring and ranking the events to produce the final personalized timeline. The approach uses entity linking techniques to associate mentions of entities in the user's profile with the corresponding entries in a knowledge base, in order to identify the user's interests.








































