本文讨论了基于Zookeeper的分布式选举和主库切换机制,强调了保证数据一致性的关键和监控方法。探讨了分布式系统主从库的构建,如何利用Zookeeper实现主库切换逻辑,以及面临的故障处理与超时限制。最后总结了采用虚IP和去中心化DNS的优势,旨在提高系统的可靠性与灵活性。





![相关工作
采 虚 的 式
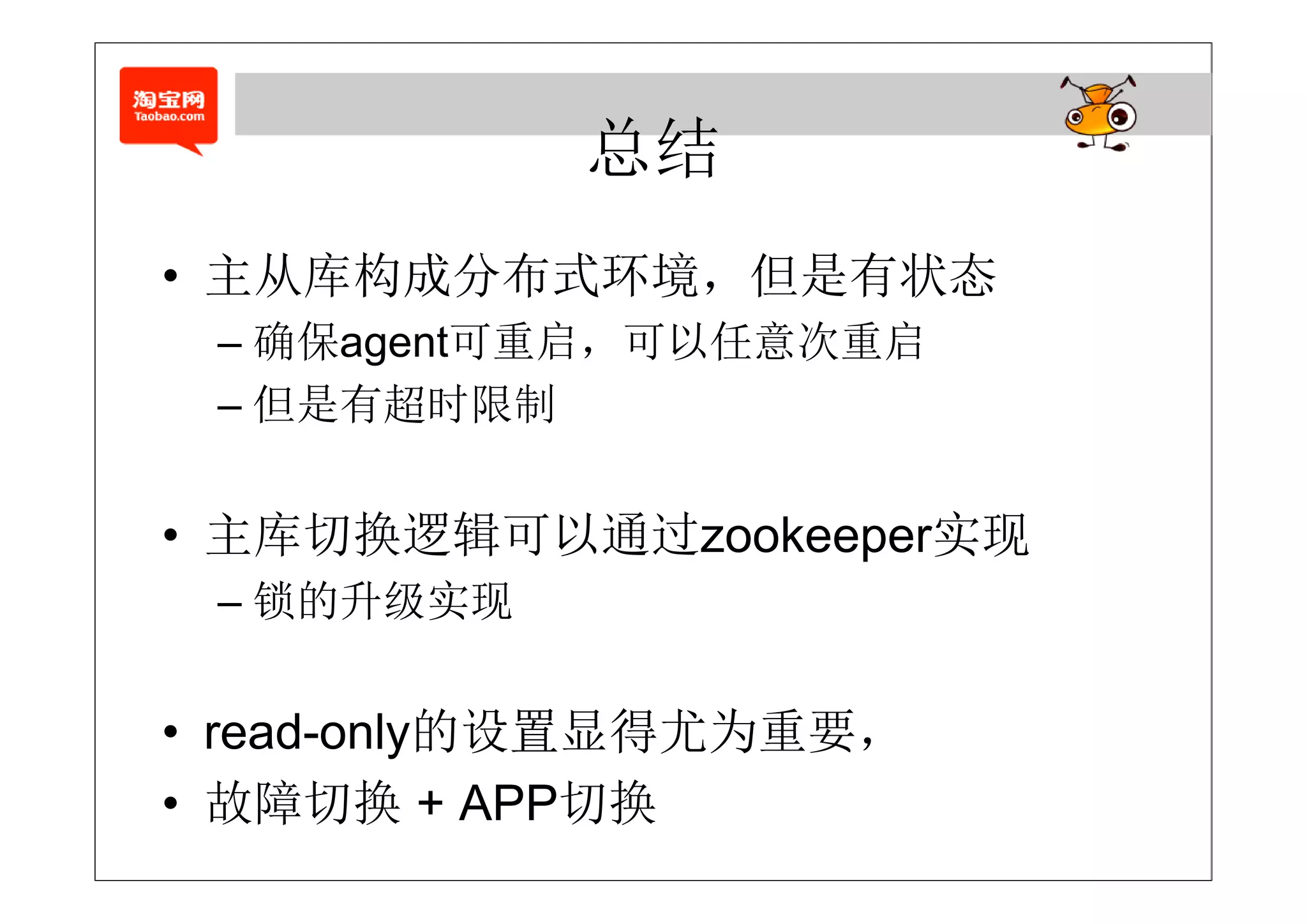
• Master采用虚IP的方式
– 前提:备库与主库在同一网段
前提:备库与主库在同 网段
– 阿里云的云聊PHPWind [1]
– 腾讯的CDB[2]
• DB对外的接口是DNS
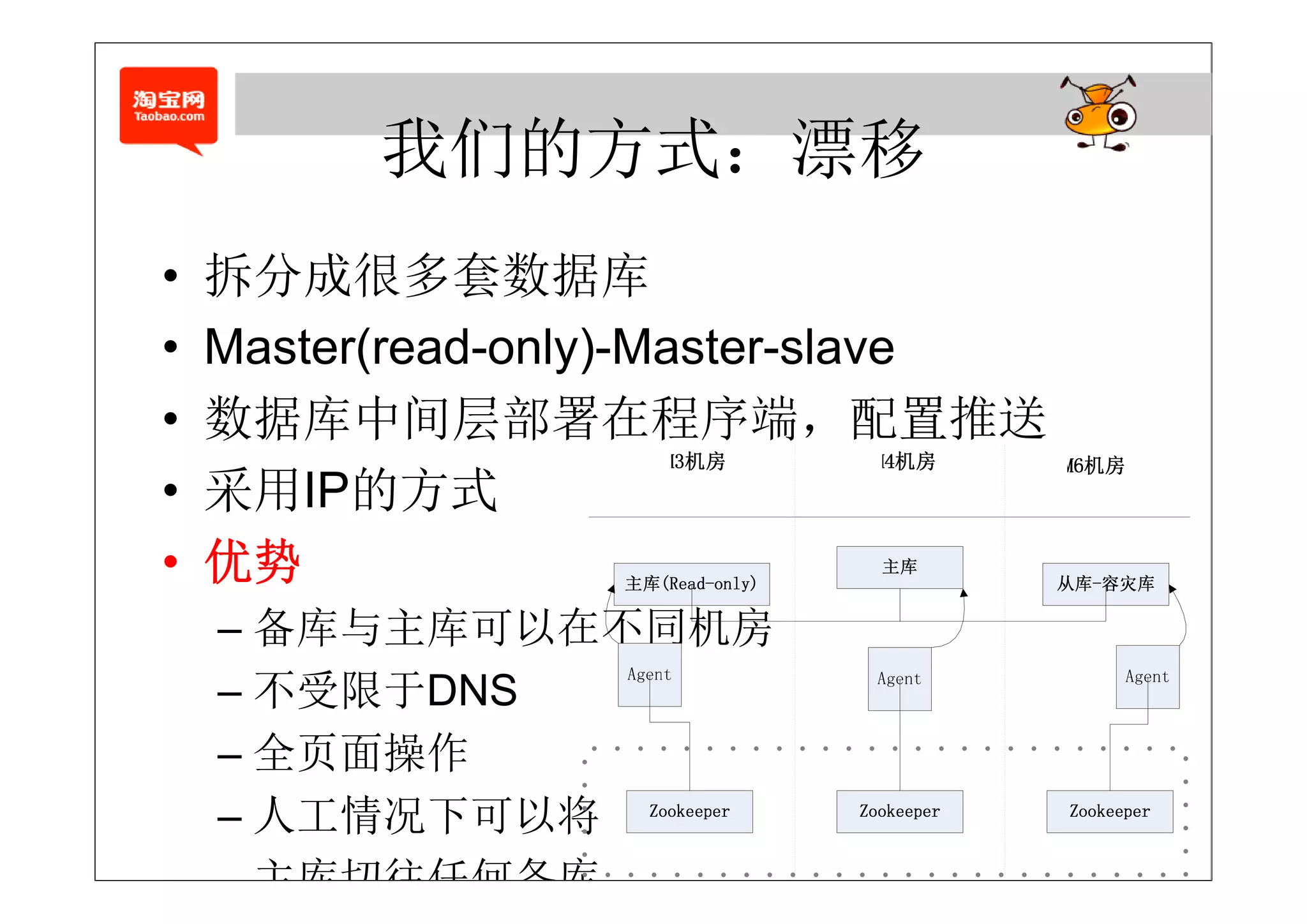
– 优势:备库与主库可以在不同机房
– 阿里云在考虑的自动切换
– 缺点:受限于DNS,若DNS故障,服务不可用
– [1] http://app.phpwind.com/
– [2] http://wiki.opensns.qq.com/wiki/CDB](https://image.slidesharecdn.com/v2-0-110829020717-phpapp02/75/MySQL-6-2048.jpg)
![分布式系统常用方法
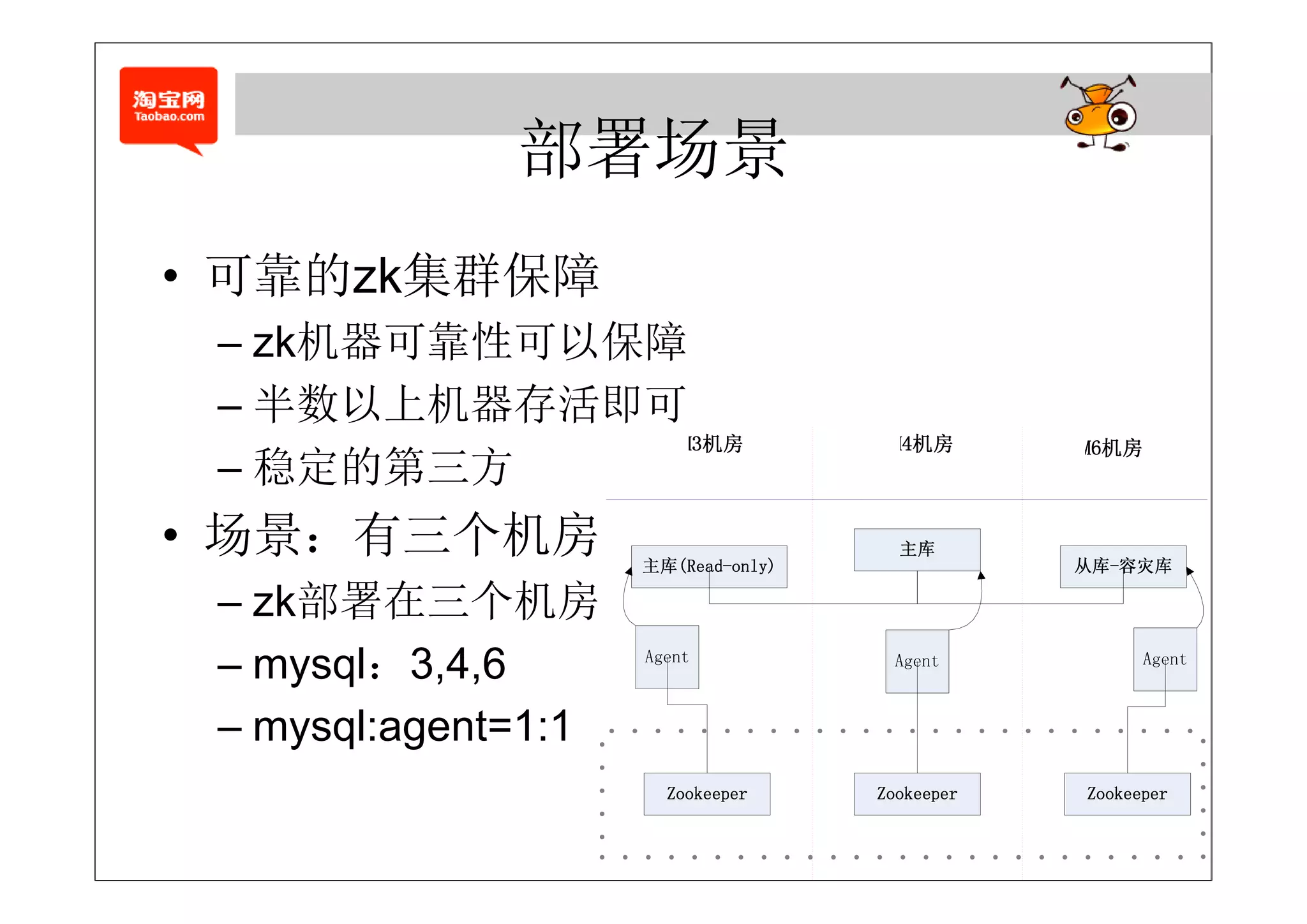
半机 存
• Paxos:一半机器存活即可
• 实践中,常用master + lease来提高效率
• 分布式系统协调服务
– Chubby (Google: Bigtable, MapReduce)
– Zookeeper (Yahoo!: hbase, hadoop子项目)
• [1] The Chubby lock service for loosely-coupled distributed systems (google论文)
• [ ] p
[2] http://nosql-wiki.org/wiki/bin/view/Main/ThePartTimeParliament
q g
• [3] http://hadoop.apache.org/zookeeper
• [4] PaxosLease: PaxosLease: Diskless Paxos for Leases](https://image.slidesharecdn.com/v2-0-110829020717-phpapp02/75/MySQL-7-2048.jpg)




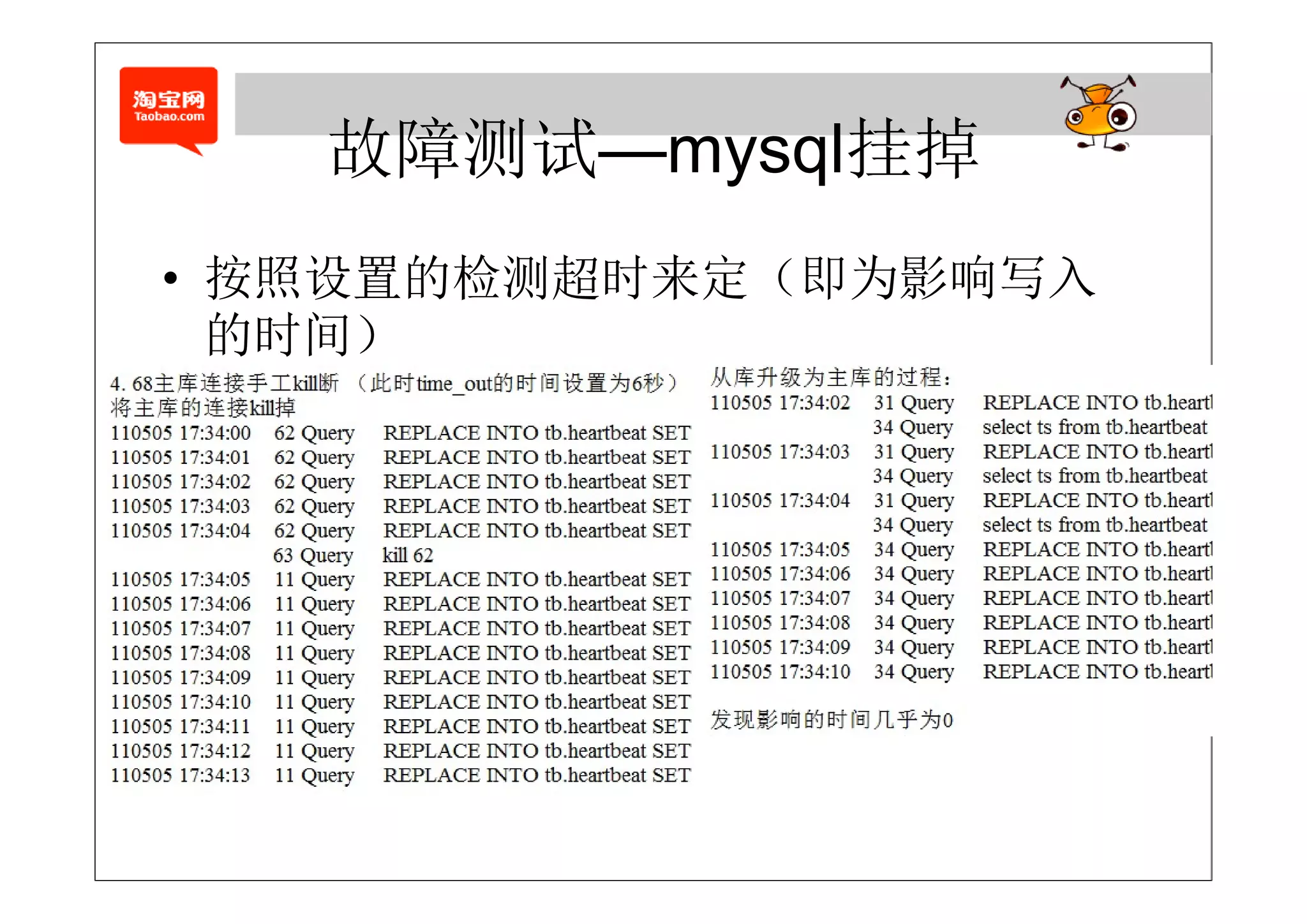

![故障测试—agent的自动重启
故障测试 agent的自动重启
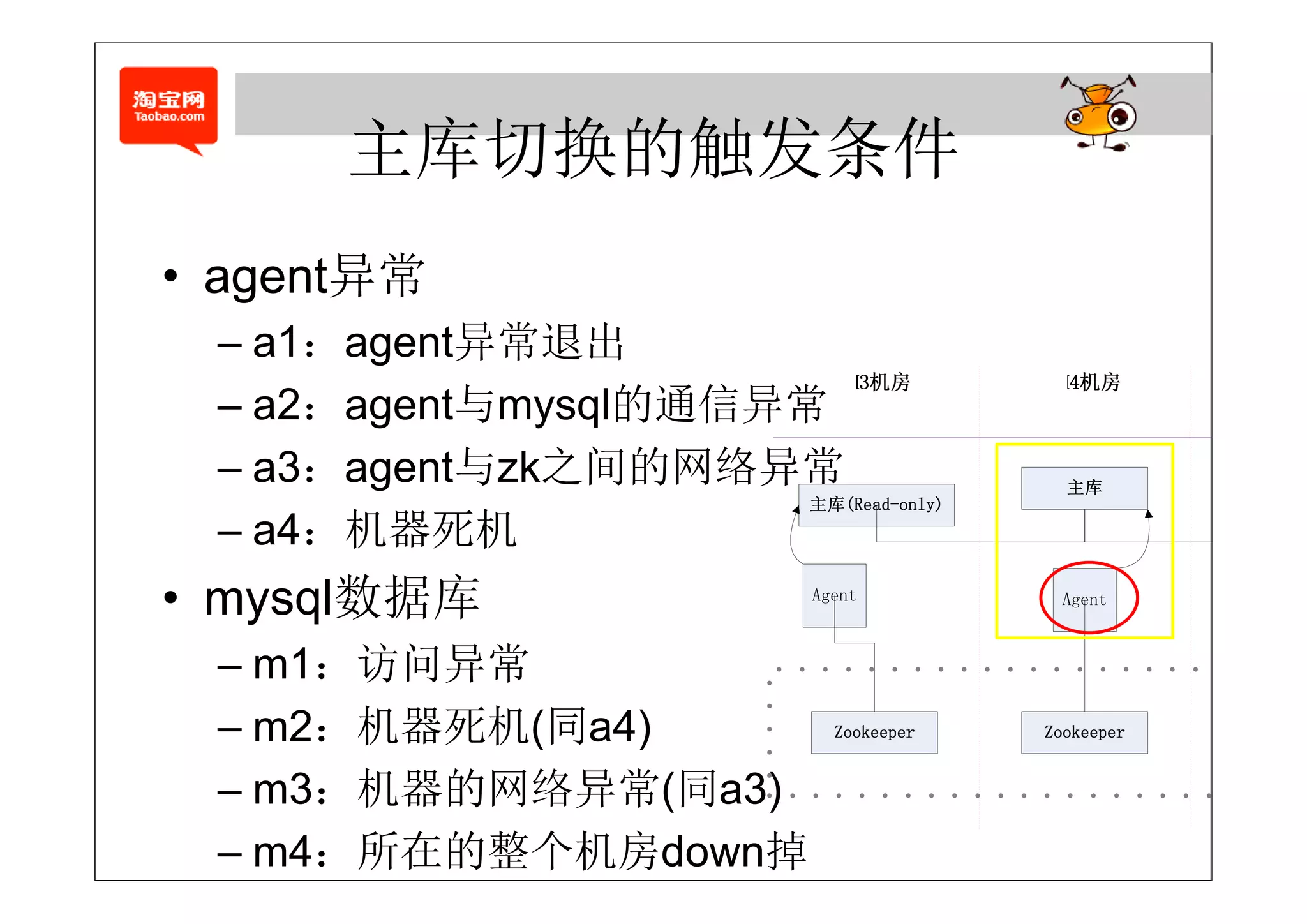
的 某种 度代表 库的
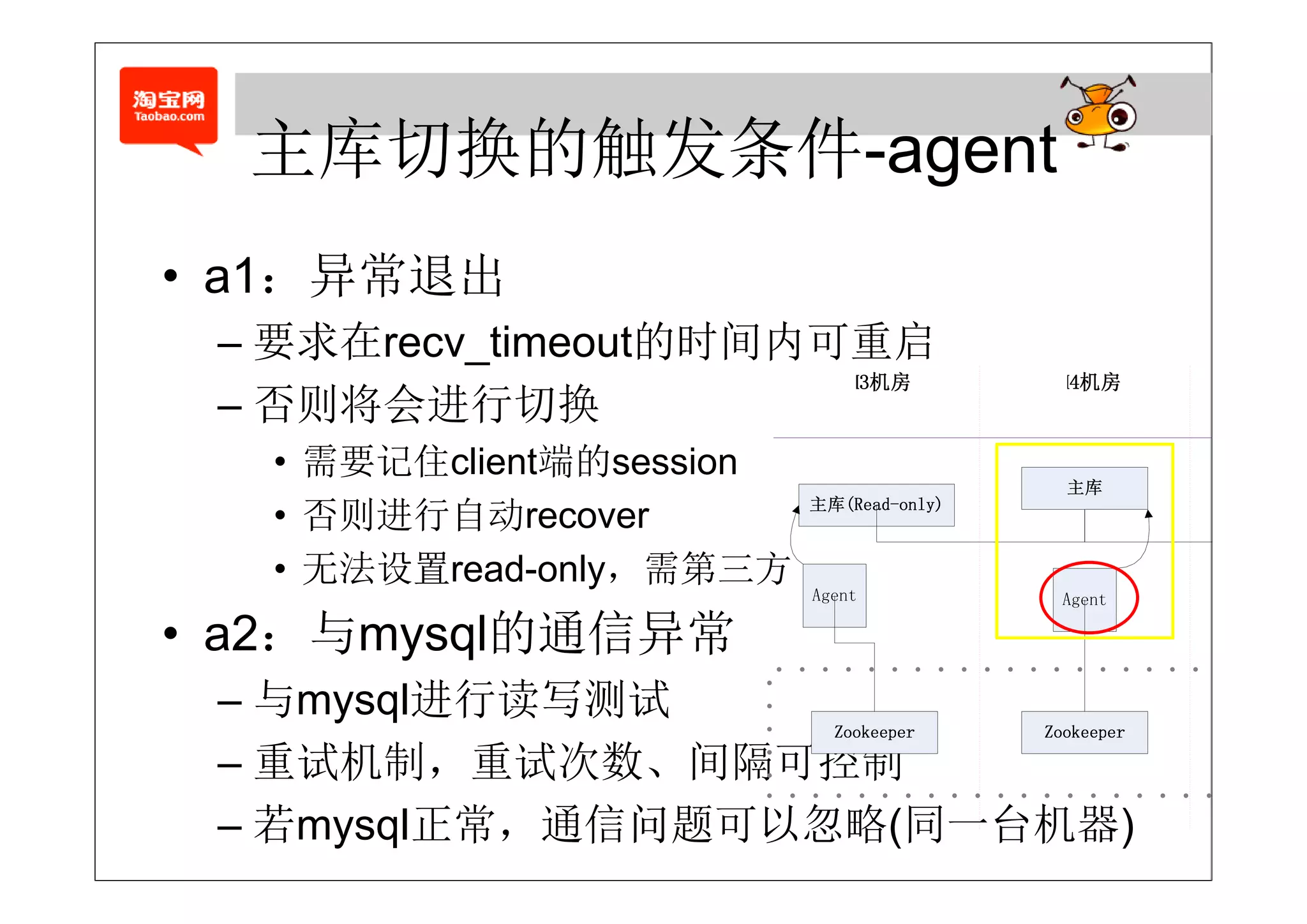
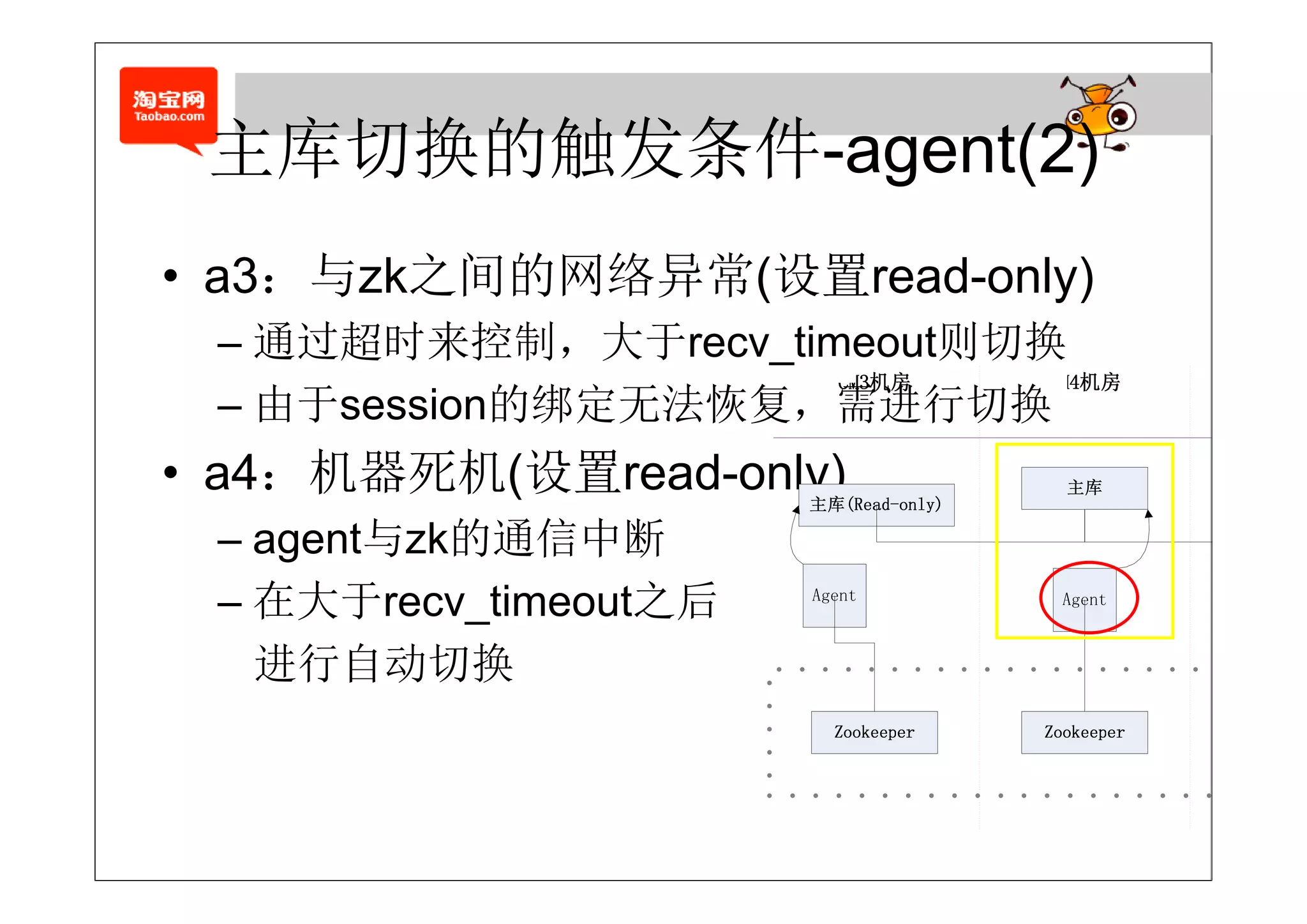
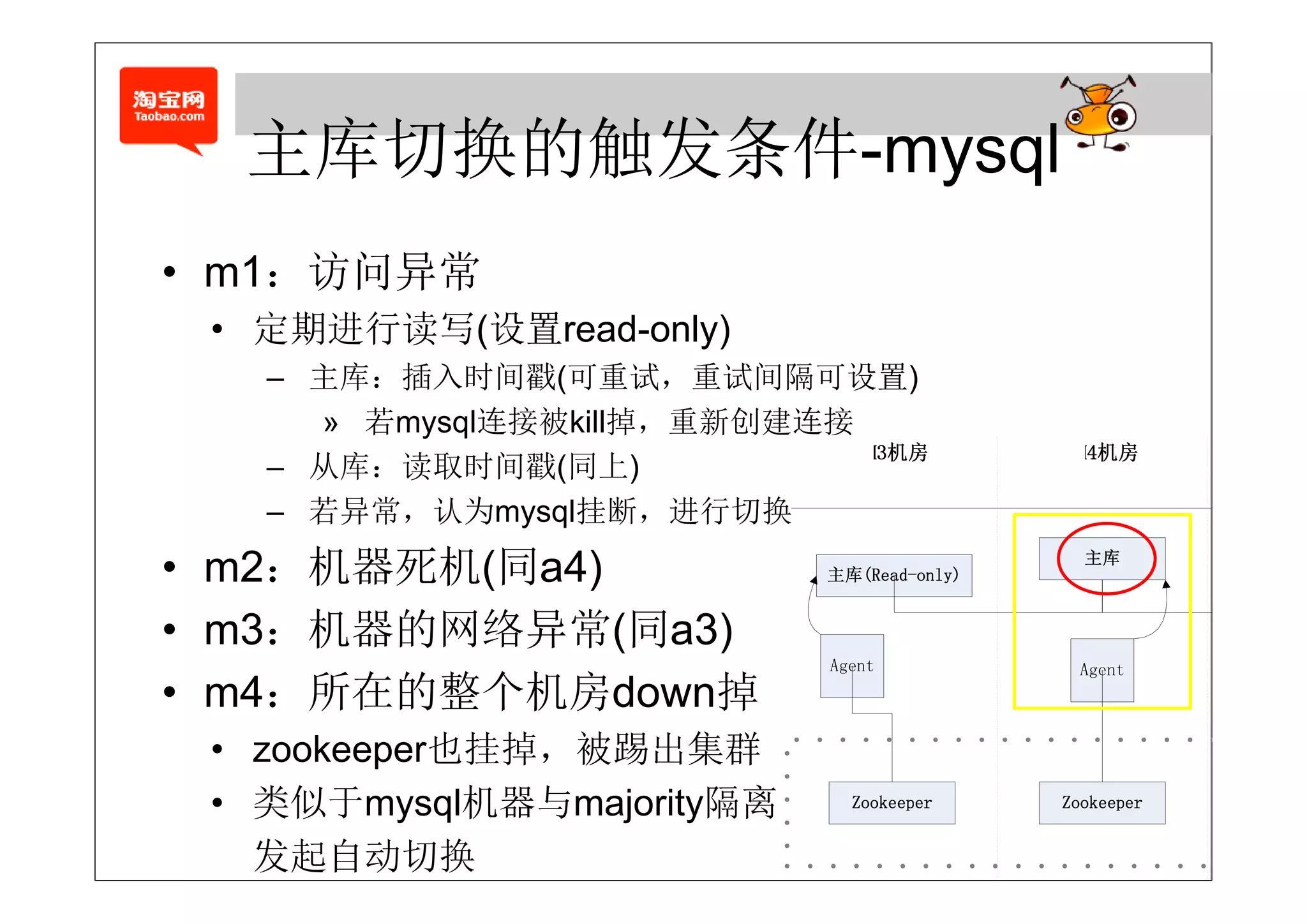
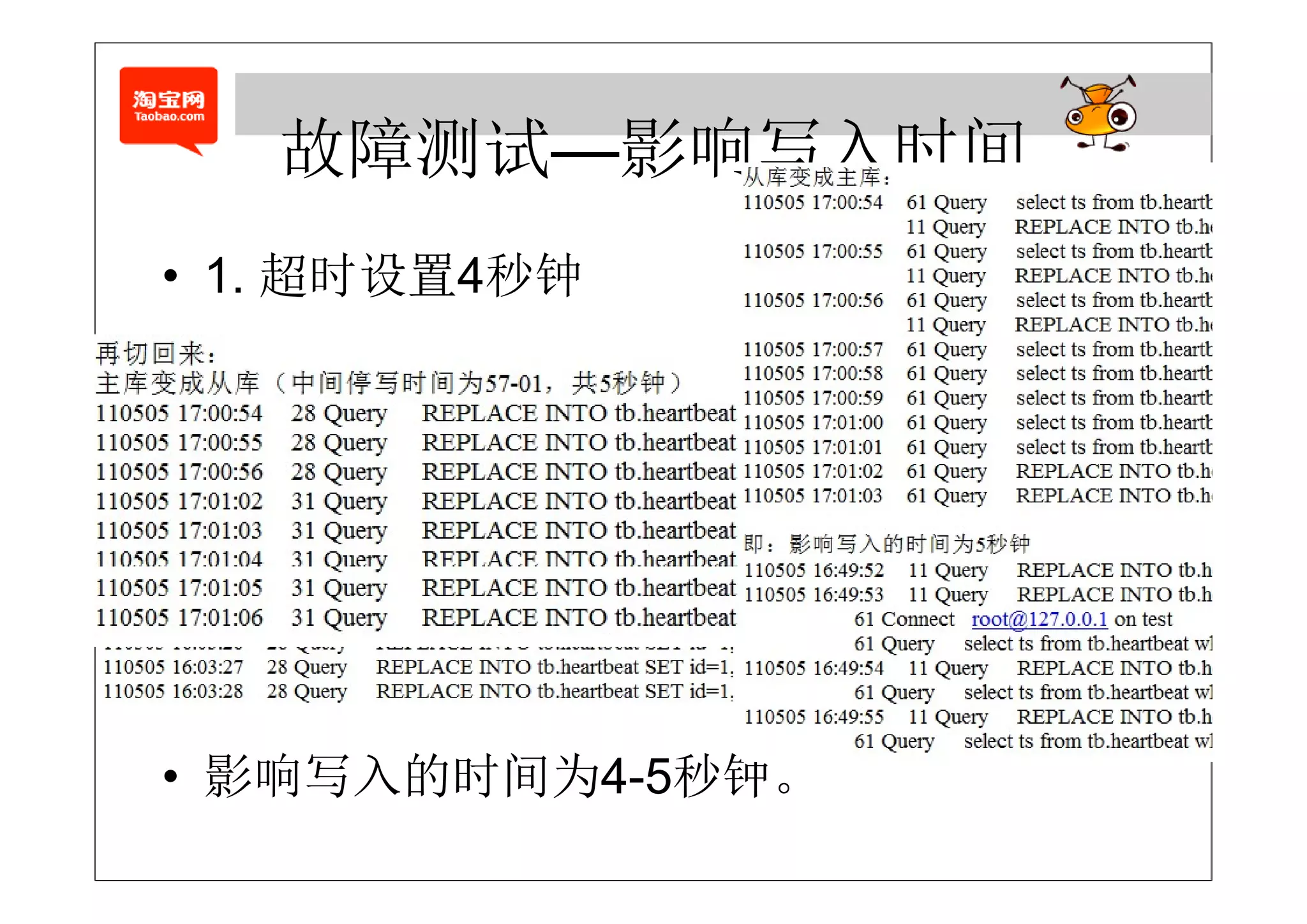
• agent的退出某种程度代表了主库的退出
– 1. 自动重启agent (需要将sess o 保持到本地)
自动重启age (需要将session保持到本地)
– [REF: hadoop the definitive guide chapter 13]](https://image.slidesharecdn.com/v2-0-110829020717-phpapp02/75/MySQL-21-2048.jpg)