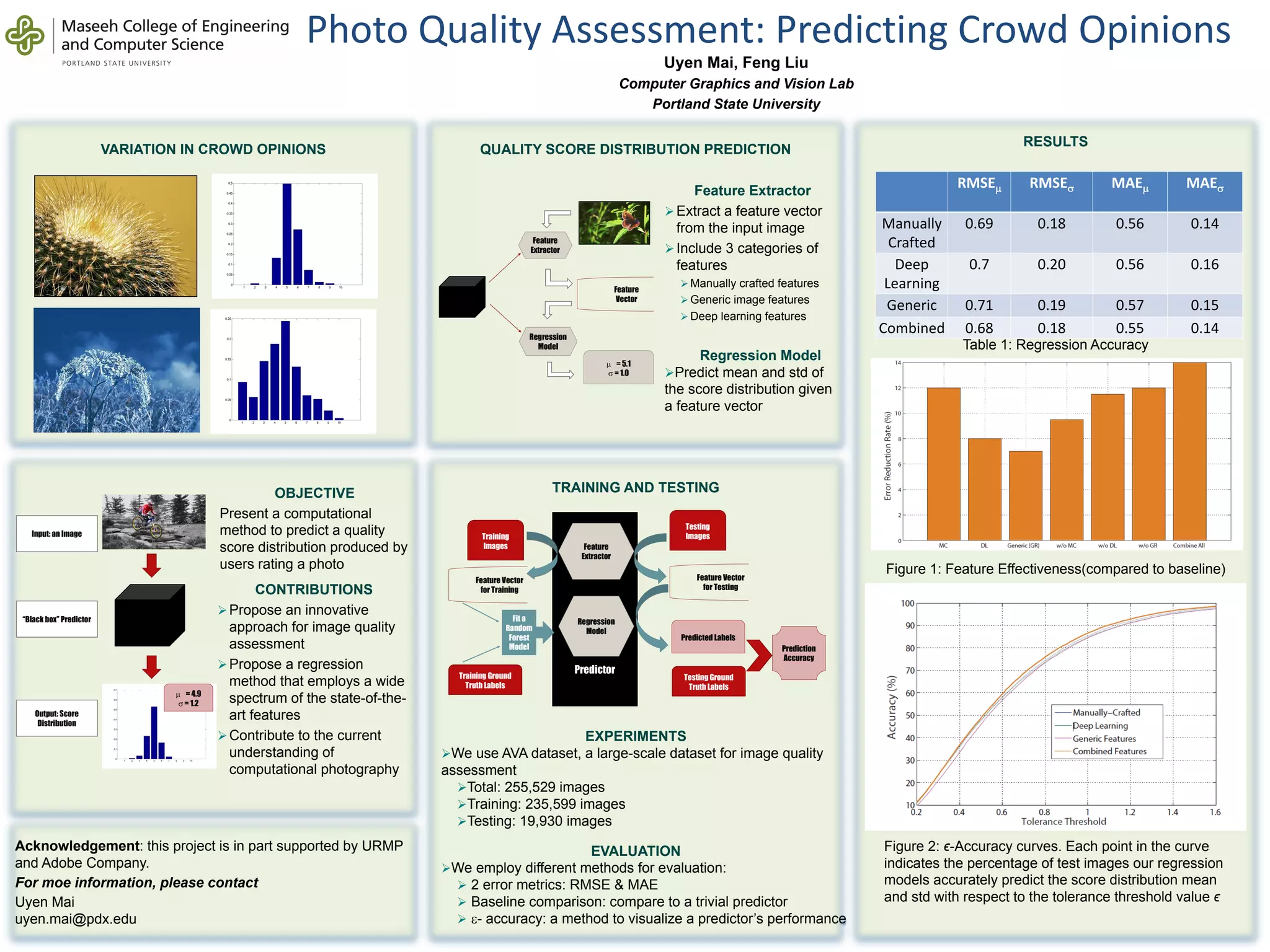
The document describes experiments conducted to predict crowd opinions on photo quality using a computational method. It summarizes:
1) The experiments used the AVA dataset containing over 255,000 images for training and testing, with 235,599 images for training and 19,930 for testing.
2) Photo quality prediction performance was evaluated using RMSE, MAE, and ε-accuracy metrics and by comparing to a trivial predictor baseline.
3) The proposed method extracts manually crafted, generic, and deep learning features from images to predict the mean and standard deviation of a quality score distribution using regression models like random forests.