Download to read offline












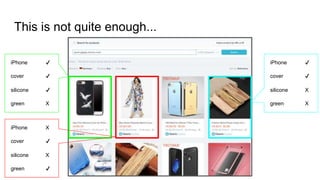
![How standard NLP workflow ( ) went wrong
● Over-Tokenization: “19mm” ⇒ [19,mm] : [NUM,PROPN]
● Wrong lemmas: “sleeved” ⇒ “sleev” but “sleeve” ⇒ “sleeve”
● PoS tag inconsistency: “nine” is NOUN, NUM and stopword(?)
Our solution
● Selective tokenization: we manually strip common punctuations and
then split by whitespace (better safe than sorry)
● Single word NLP for lemmatization and tagging (consistent)
Tokenize Spelling Stop words PoS Tagging
Lemmatization](https://image.slidesharecdn.com/catalogtitleanalysis-all-210418154036/85/Un-natural-language-processing-Catalog-NLP-12-320.jpg)

![Cleanup mechanism
Brand
list
Keep?
Brand A ✓
Brand B ✗
... Manually
From To
Mans men
Men’s men
...
Regex list
[0-9]+s*[Ss]et
...
# Match
1 3
2 <NA>
3 set
Spell ✗
Suggested
slim fit
slim-fit
slimmest
Stop
words
for
with
I
...
Phrase list
([Gg]reat|[Bb]est)s*[Pprice]
[Ff]rees*[Sh]ippingW
...
Rules?
Spell ✓
ID Keywords pieces ...
12345 men, shirt, dark, blue, casual, slimfit 3 ...
ID Title
12345 BRAND-B Mans shirt, 3set dark blue casual slimfit. Great price with free shipping!](https://image.slidesharecdn.com/catalogtitleanalysis-all-210418154036/85/Un-natural-language-processing-Catalog-NLP-15-320.jpg)










![Known issues
Fixable Probably Fixable Hard
Words in French &
Spanish: Identify with
spell check and
translate / remove
A standard approach to splitting
amalgamation (“handsfree” vs. “hands
free”)
● For splitting we can potentially use
spell suggestion (so far we cannot
guarantee 100% accuracy)
● We can curate a list and use RE to
standardize
([Oo]vers?[Ss]ize[d]? ⇒ oversized)
Better stemming / synonym / PoS libraries
Extend lexical tagging
(create or “get” lists):
● Brands
● Model names
● Phrases](https://image.slidesharecdn.com/catalogtitleanalysis-all-210418154036/85/Un-natural-language-processing-Catalog-NLP-28-320.jpg)





The document discusses the integration of natural language processing (NLP) to enhance product recommendations, search functionality, and catalog development. It highlights the challenges of categorizing products, dealing with inconsistent data, and the necessity of automating these processes while maintaining privacy and promoting a healthy marketplace. The document emphasizes the importance of data accuracy, cleaning methods, and intelligent tagging to improve user experience in product discovery.






![[DSC Europe 24] Mladen Fernezir AI search solutions for online marketplaces n...](https://cdn.slidesharecdn.com/ss_thumbnails/dsceurope24mladenferneziraisearchsolutionsforonlinemarketplacesnewexperiencesandtechnicalaspects-241126202748-9e56a11e-thumbnail.jpg?width=640&height=640&fit=bounds)




































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)



