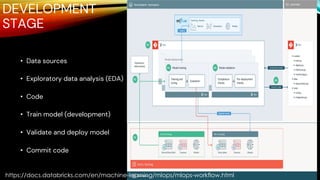
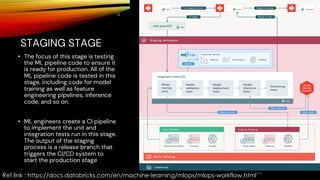
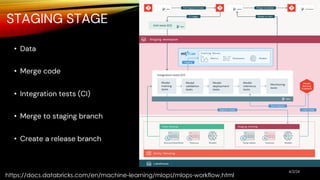
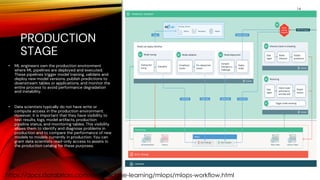
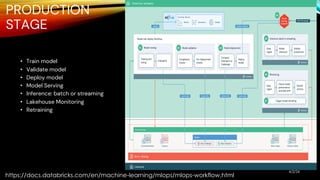
The document outlines MLOps as a methodology integrating processes for managing machine learning code, data, and models, emphasizing the creation of separate environments for each development stage (development, staging, production). It recommends using tools such as git for version control, delta tables for data storage, and MLflow for tracking model development. The MLOps workflow includes stages of experimentation, testing, and deployment, with a focus on maintaining a robust pipeline and governance.