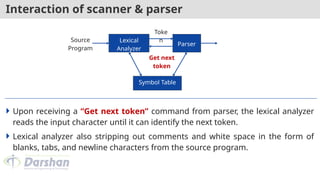
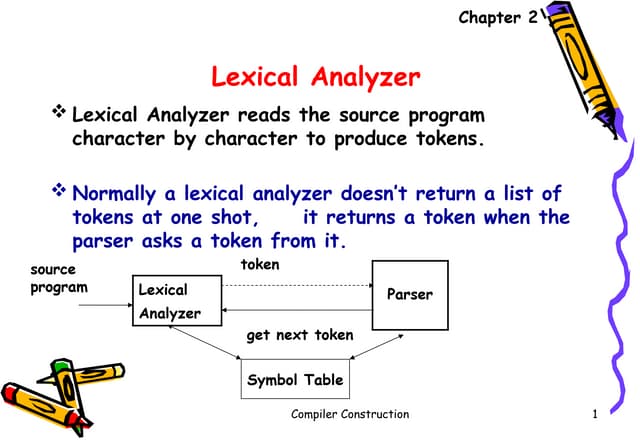
Interaction of scanner& parser
Upon receiving a “Get next token” command from parser, the lexical analyzer
reads the input character until it can identify the next token.
Lexical analyzer also stripping out comments and white space in the form of
blanks, tabs, and newline characters from the source program.
Lexical
Analyzer
Symbol Table
Parser
Toke
n
Get next
token
Source
Program
5.
Why to separatelexical analysis & parsing?
1. Simplicity in design.
2. Improves compiler efficiency.
3. Enhance compiler portability.
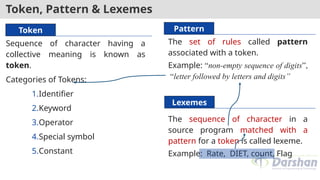
Token, Pattern &Lexemes
Sequence of character having a
collective meaning is known as
token.
Categories of Tokens:
1.Identifier
2.Keyword
3.Operator
4.Special symbol
5.Constant
The set of rules called pattern
associated with a token.
Example: “non-empty sequence of digits”,
“letter followed by letters and digits”
The sequence of character in a
source program matched with a
pattern for a token is called lexeme.
Example: Rate, DIET, count, Flag
Token Pattern
Lexemes
8.
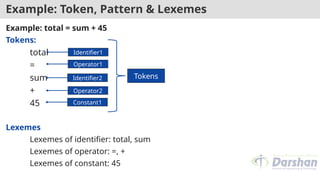
Example: Token, Pattern& Lexemes
Example: total = sum + 45
Tokens:
total
=
sum
+
45
Lexemes
Lexemes of identifier: total, sum
Lexemes of operator: =, +
Lexemes of constant: 45
Identifier1
Operator1
Identifier2
Operator2
Constant1
Tokens
Input buffering
Thereare mainly two techniques for input buffering:
1. Buffer pairs
2. Sentinels
The lexical analysis scans the input string from left to right one character at a
time.
Buffer divided into two N-character halves, where N is the number of character
on one disk block.
: : : E : : = : : Mi : * :
:
: C: * : * : 2 :
eof : : :
Buffer Pair
11.
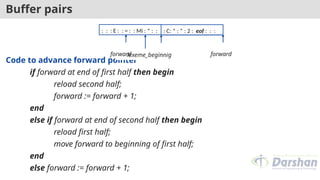
Buffer pairs
PointerLexeme Begin, marks the beginning of the current lexeme.
Pointer Forward, scans ahead until a pattern match is found.
Once the next lexeme is determined, forward is set to character at its right end.
Lexeme Begin is set to the character immediately after the lexeme just found.
If forward pointer is at the end of first buffer half then second is filled with N
input character.
If forward pointer is at the end of second buffer half then first is filled with N
input character.
: : : E : : = : : Mi : * : : : C: * : * : 2 : eof : : :
forward
lexeme_beginnig forward
: C: * : * : 2 : eof : : :
12.
Buffer pairs
Code toadvance forward pointer
if forward at end of first half then begin
reload second half;
forward := forward + 1;
end
else if forward at end of second half then begin
reload first half;
move forward to beginning of first half;
end
else forward := forward + 1;
: : : E : : = : : Mi : * : : : C: * : * : 2 : eof : : :
forward
lexeme_beginnig forward
forward
: C: * : * : 2 : eof : : :
13.
Sentinels
In bufferpairs we must check, each time we move the forward pointer that we
have not moved off one of the buffers.
Thus, for each character read, we make two tests.
We can combine the buffer-end test with the test for the current character.
We can reduce the two tests to one if we extend each buffer to hold a sentinel
character at the end.
The sentinel is a special character that cannot be part of the source program,
and a natural choice is the character EOF.
: : E : : = : : Mi : * : eof : C: * : * : 2 : eof : : eof
forward
lexeme_beginnig
14.
Sentinels
forward := forward+ 1;
if forward = eof then begin
if forward at end of first half then begin
reload second half;
forward := forward + 1;
end
else if forward at the second half then begin
reload first half;
move forward to beginning of first half;
end
else terminate lexical analysis;
end
: : E : : = : : Mi : * : : C: * : * : 2 : eof : : eof
lexeme_beginnig
forward
eof
forward forward
: C: * : * : 2 : eof : : eof
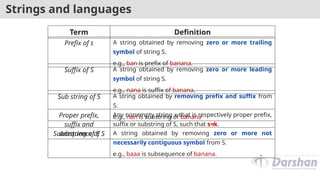
Strings and languages
TermDefinition
Prefix of s A string obtained by removing zero or more trailing
symbol of string S.
e.g., ban is prefix of banana.
Suffix of S A string obtained by removing zero or more leading
symbol of string S.
e.g., nana is suffix of banana.
Sub string of S A string obtained by removing prefix and suffix from
S.
e.g., nan is substring of banana
Proper prefix,
suffix and
substring of S
Any nonempty string x that is respectively proper prefix,
suffix or substring of S, such that s≠x.
Subsequence of S A string obtained by removing zero or more not
necessarily contiguous symbol from S.
e.g., baaa is subsequence of banana.
17.
Exercise
Write prefix,suffix, substring, proper prefix, proper suffix and subsequence of
following string:
String: Compiler
18.
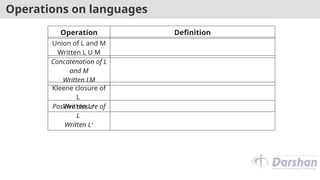
Operations on languages
OperationDefinition
Union of L and M
Written L U M
Concatenation of L
and M
Written LM
Kleene closure of
L
Written L∗
Positive closure of
L
Written L+
Regular expression
Aregular expression is a sequence of characters that define a pattern.
Notational shorthand's
1. One or more instances: +
2. Zero or more instances: *
3. Zero or one instances: ?
4. Alphabets: Σ
21.
Rules to defineregular expression
1. is a regular expression that denotes , the set containing empty string.
2. If is a symbol in then is a regular expression,
3. Suppose and are regular expression denoting the languages and . Then,
a. is a regular expression denoting
b. is a regular expression denoting
c. * is a regular expression denoting
d. is a regular expression denoting
The language denoted by regular expression is said to be a regular set.
22.
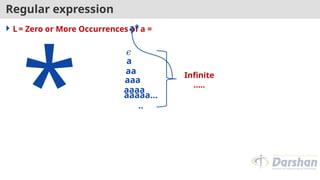
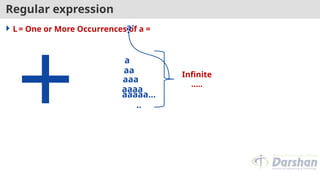
Regular expression
L=Zero or More Occurrences of a =
*
a*
a
aaa
aa
aaaa
aaaaa…
..
Infinite
…..
𝜖
23.
Regular expression
L=One or More Occurrences of a =
+
a+
a
aaa
aa
aaaa
aaaaa…
..
Infinite
…..
24.
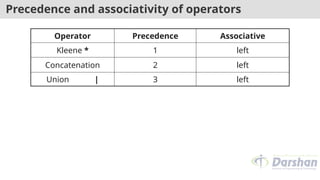
Precedence and associativityof operators
Operator Precedence Associative
Kleene * 1 left
Concatenation 2 left
Union | 3 left
25.
Regular expression examples
1.0 or 1
2. 0 or 11 or 111
3. String having zero or more a.
4. String having one or more a.
5. Regular expression over that represent all string of length 3.
6. All binary string
𝐒𝐭𝐫𝐢𝐧𝐠𝐬:𝟎 ,𝟏
𝐒𝐭𝐫𝐢𝐧𝐠𝐬:𝟎,𝟏𝟏,𝟏𝟏𝟏
𝐒𝐭𝐫𝐢𝐧𝐠𝐬:𝛜,𝐚,𝐚𝐚,𝐚𝐚𝐚,𝐚𝐚𝐚𝐚…..
𝐒𝐭𝐫𝐢𝐧𝐠𝐬:𝐚,𝐚𝐚,𝐚𝐚𝐚,𝐚𝐚𝐚𝐚…..
𝐒𝐭𝐫𝐢𝐧𝐠𝐬:𝐚𝐛𝐜,𝐛𝐜𝐚,𝐛𝐛𝐛,𝐜𝐚𝐛,𝐚𝐛𝐚….
𝐒𝐭𝐫𝐢𝐧𝐠𝐬:𝟎,𝟏𝟏,𝟏𝟎𝟏,𝟏𝟎𝟏𝟎𝟏,𝟏𝟏𝟏𝟏…
𝐑.𝐄.=𝟎|𝟏𝟏|𝟏𝟏𝟏
𝐑 .𝐄.=𝟎∨𝟏
𝐑 .𝐄.=𝐚∗
𝐑 .𝐄.=𝐚+¿
𝐑.𝐄.=(𝐚|𝐛|𝐜)(𝐚|𝐛|𝐜)(𝐚|𝐛|𝐜)
+
26.
Regular expression examples
7.0 or more occurrence of either a or b or both
8. 1 or more occurrence of either a or b or both
9. Binary no. ends with 0
10.Binary no. ends with 1
11.Binary no. starts and ends with 1
12.String starts and ends with same character
𝑺𝒕𝒓𝒊𝒏𝒈𝒔:𝝐,𝒂,𝒂𝒂,𝒂𝒃𝒂𝒃,𝒃𝒂𝒃…
𝑺𝒕𝒓𝒊𝒏𝒈𝒔:𝒂,𝒂𝒂,𝒂𝒃𝒂𝒃,𝒃𝒂𝒃,𝒃𝒃𝒃𝒂𝒂𝒂…
𝑺𝒕𝒓𝒊𝒏𝒈𝒔:𝟎,𝟏𝟎,𝟏𝟎𝟎,𝟏𝟎𝟏𝟎,𝟏𝟏𝟏𝟏𝟎…
𝑺𝒕𝒓𝒊𝒏𝒈𝒔:𝟏,𝟏𝟎𝟏,𝟏𝟎𝟎𝟏,𝟏𝟎𝟏𝟎𝟏,…
𝑺𝒕𝒓𝒊𝒏𝒈𝒔:𝟏𝟏,𝟏𝟎𝟏,𝟏𝟎𝟎𝟏,𝟏𝟎𝟏𝟎𝟏,…
𝑺𝒕𝒓𝒊𝒏𝒈𝒔:𝟎𝟎,𝟏𝟎𝟏,𝒂𝒃𝒂,𝒃𝒂𝒂𝒃…
𝑹. 𝑬.=(𝒂∨𝒃)∗
+
𝑹.𝑬.=(𝟎∨𝟏)∗𝟏
*
27.
Regular expression examples
13.Allstring of a and b starting with a
14.String of 0 and 1 ends with 00
15.String ends with abb
16.String starts with 1 and ends with 0
17.All binary string with at least 3 characters and 3rd
character should be zero
18.Language which consist of exactly two b’s over the set
… *
… 𝑹.𝑬.=(𝟎∨𝟏)∗𝟎𝟎
… 𝑹.𝑬.=(𝒂∨𝒃)∗𝒂𝒃𝒃
… 𝑹.𝑬.=𝟏(𝟎∨𝟏)∗𝟎
… 𝑹.𝑬.=(𝟎|𝟏)(𝟎|𝟏)𝟎(𝟎∨𝟏)∗
… 𝑹.𝑬.=𝒂∗𝒃𝒂∗𝒃𝒂∗
28.
Regular expression examples
19.Thelanguage with such that 3rd
character from right end of the string is
always a.
20.Any no. of followed by any no. of followed by any no. of
21.String should contain at least three
22.String should contain exactly two
23.Length of string should be at least 1 and at most 3
24.No. of zero should be multiple of 3
… 𝑹.𝑬.=(𝒂∨𝒃)∗𝒂(𝒂∨𝒃)(𝒂∨𝒃)
… 𝑹.𝑬.=𝒂∗𝒃∗𝒄∗
…. 𝑹.𝑬.=(𝟎∨𝟏)∗
𝟏(𝟎∨𝟏)∗
𝟏(𝟎∨𝟏)∗
𝟏(𝟎∨𝟏)∗
…. 𝑹. 𝑬 .=𝟎∗
𝟏𝟎∗
𝟏𝟎∗
…. 𝑹.𝑬.=(𝟎∨𝟏)|(𝟎∨𝟏)(𝟎∨𝟏)|(𝟎∨𝟏)(𝟎∨𝟏)(𝟎∨𝟏)
…. 𝑹.𝑬.=(𝟏∗
𝟎𝟏∗
𝟎𝟏∗
𝟎𝟏∗
)∗
29.
Regular expression examples
24.Thelanguage with where should be multiple of 3
25.Even no. of 0
26.String should have odd length
27.String should have even length
28.String start with 0 and has odd length
30.String start with 1 and has even length
31.All string begins or ends with 00 or 11
𝑺𝒕𝒓𝒊𝒏𝒈𝒔:𝒂𝒂𝒂,𝒃𝒂𝒂𝒂,𝒃𝒂𝒄𝒂𝒃𝒂,𝒂𝒂𝒂𝒂𝒂𝒂.. 𝑹.𝑬.=((𝒃∨𝒄)∗
𝒂(𝒃∨𝒄)∗
𝒂(𝒃∨𝒄)∗
𝒂(𝒃∨𝒄)∗
)
∗
…. 𝑹. 𝑬 .=(𝟏∗
𝟎𝟏∗
𝟎𝟏∗
)∗
…. 𝑹. 𝑬.=(𝟎∨𝟏)((𝟎|𝟏)(𝟎∨𝟏))
∗
…. 𝑹. 𝑬 .=((𝟎|𝟏)(𝟎∨𝟏))
∗
…. 𝑹. 𝑬 .=(𝟎)((𝟎|𝟏)(𝟎∨𝟏))
∗
…. 𝑹.𝑬.=𝟏(𝟎∨𝟏)((𝟎|𝟏)(𝟎∨𝟏))
∗
𝑺𝒕𝒓𝒊𝒏𝒈𝒔:𝟎𝟎𝟏𝟎𝟏,𝟏𝟎𝟏𝟎𝟎,𝟏𝟏𝟎,𝟎𝟏𝟎𝟏𝟏… 𝑹.𝑬.=(𝟎𝟎∨𝟏𝟏)(𝟎∨𝟏)∗∨(𝟎|𝟏)∗(𝟎𝟎∨𝟏𝟏)
30.
Regular expression examples
31.Languageof all string containing both 11 and 00 as substring
32.String ending with 1 and not contain 00
33.Language of C identifier
𝑺𝒕𝒓𝒊𝒏𝒈𝒔:𝟎𝟎𝟏𝟏,𝟏𝟏𝟎𝟎,𝟏𝟎𝟎𝟏𝟏𝟎,𝟎𝟏𝟎𝟎𝟏𝟏…
𝑺𝒕𝒓𝒊𝒏𝒈𝒔:𝟎𝟏𝟏,𝟏𝟏𝟎𝟏,𝟏𝟎𝟏𝟏…. 𝑹. 𝑬 .=(𝟏|𝟎𝟏)+¿
𝑹. 𝑬 .=(¿+𝑳)(¿+𝑳+𝑫)∗
𝑺𝒕𝒓𝒊𝒏𝒈𝒔:𝒂𝒓𝒆𝒂,𝒊,𝒓𝒆𝒅𝒊𝒐𝒖𝒔,𝒈𝒓𝒂𝒅𝒆𝟏….
𝒘𝒉𝒆𝒓𝒆𝑳𝒊𝒔𝑳𝒆𝒕𝒕𝒆𝒓∧𝐃𝐢𝐬𝐝𝐢𝐠𝐢𝐭
31.
Regular definition
Aregular definition gives names to certain regular expressions and uses those
names in other regular expressions.
Regular definition is a sequence of definitions of the form:
……
Where is a distinct name & is a regular expression.
Example: Regular definition for identifier
letter A|B|C|………..|Z|a|b|………..|z
digit 0|1|…….|9|
id letter (letter | digit)*
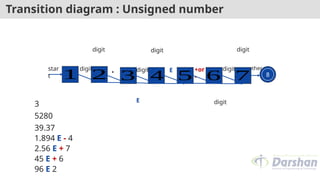
Transition diagram :Unsigned number
1 2 8
other
digit
3 4 5 6 7
digit
digit
digit
+or
-
digit
digit
E
.
star
t
E digit
3
5280
39.37
1.894 E - 4
2.56 E + 7
45 E + 6
96 E 2
Hard coding andautomatic generation lexical
analyzers
Lexical analysis is about identifying the pattern from the input.
To recognize the pattern, transition diagram is constructed.
It is known as hard coding lexical analyzer.
Example: to represent identifier in ‘C’, the first character must be letter and
other characters are either letter or digits.
To recognize this pattern, hard coding lexical analyzer will work with a transition
diagram.
The automatic generation lexical analyzer takes special notation as input.
For example, lex compiler tool will take regular expression as input and finds
out the pattern matching to that regular expression.
2 3
Start
Letter or
digit
Letter
1
Finite Automata
FiniteAutomata are recognizers.
FA simply say “Yes” or “No” about each possible input string.
Finite Automata is a mathematical model consist of:
1. Set of states
2. Set of input symbol
3. A transition function move
4. Initial state
5. Final states or accepting states
41.
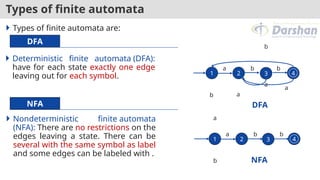
Types of finiteautomata
Types of finite automata are:
Nondeterministic finite automata
(NFA): There are no restrictions on the
edges leaving a state. There can be
several with the same symbol as label
and some edges can be labeled with .
1 2 3 4
a b b
a
b
1 2 3 4
a b b
a
a
a
b
DFA
NFA
b
Deterministic finite automata (DFA):
have for each state exactly one edge
leaving out for each symbol.
DFA
NFA
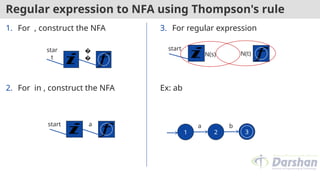
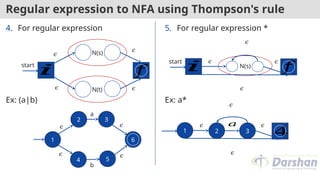
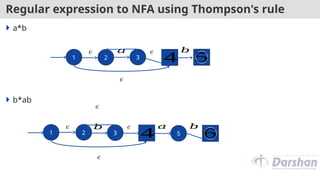
Regular expression toNFA using Thompson's rule
1. For , construct the NFA
2. For in , construct the NFA
𝑖 𝑓
�
�
star
t
𝑖 𝑓
a
start
3. For regular expression
Ex: ab
𝑖 𝑓
start
N(s) N(t)
1 2 3
a b
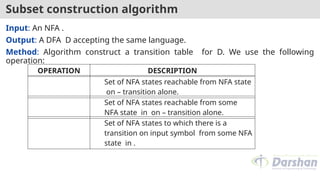
Subset construction algorithm
Input:An NFA .
Output: A DFA D accepting the same language.
Method: Algorithm construct a transition table for D. We use the following
operation:
OPERATION DESCRIPTION
Set of NFA states reachable from NFA state
on – transition alone.
Set of NFA states reachable from some
NFA state in on – transition alone.
Set of NFA states to which there is a
transition on input symbol from some NFA
state in .
49.
Subset construction algorithm
initiallybe the only state in and it is unmarked;
while there is unmarked states T in do begin
mark ;
for each input symbol do begin
if is not in then
add as unmarked state to
end
end
50.
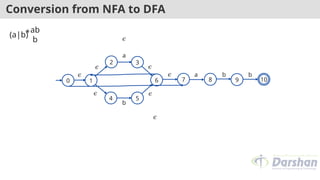
Conversion from NFAto DFA
1
(a|b)
*ab
b
2
5
3
4
6 7 8 9
0 10
𝜖
a
b
𝜖 a b b
𝜖
𝜖 𝜖
𝜖
𝜖
𝜖
51.
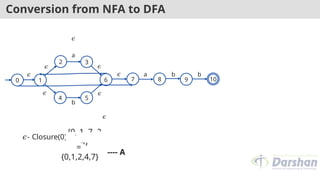
Conversion from NFAto DFA
1
2
5
3
4
6 7 8 9
0
𝜖
a
b
𝜖 a b b
𝜖
𝜖 𝜖
𝜖
𝜖
𝜖
10
{0, 1, 7, 2,
4}
---- A
𝜖- Closure(0)=
=
{0,1,2,4,7}
52.
Conversion from NFAto DFA
1
2
5
3
4
6 7 8 9
0
𝜖
a
b
𝜖 a b b
𝜖
𝜖 𝜖
𝜖
𝜖
𝜖
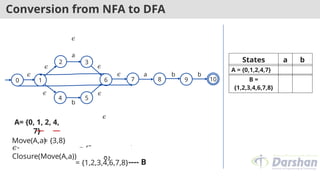
A= {0, 1, 2, 4,
7}
Move(A,a)
= {3,8}
𝜖-
Closure(Move(A,a))
= {3, 6, 7, 1, 2, 4,
8}
---- B
= {1,2,3,4,6,7,8}
10
States a b
A = {0,1,2,4,7} B
B =
{1,2,3,4,6,7,8}
53.
Conversion from NFAto DFA
1
2
5
3
4
6 7 8
0
𝜖
a
b
𝜖 a b b
𝜖
𝜖 𝜖
𝜖
𝜖
𝜖
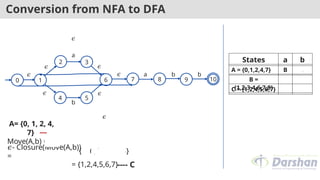
A= {0, 1, 2, 4,
7}
Move(A,b) =
{5}
𝜖- Closure(Move(A,b))
=
{5, 6, 7, 1, 2, 4}
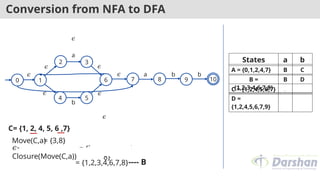
---- C
= {1,2,4,5,6,7}
10
9
States a b
A = {0,1,2,4,7} B C
B =
{1,2,3,4,6,7,8}
C = {1,2,4,5,6,7}
54.
Conversion from NFAto DFA
1
2
5
3
4
6 7 8
0
𝜖
a
b
𝜖 a b
𝜖
𝜖 𝜖
𝜖
𝜖
𝜖
B = {1, 2, 3, 4, 6, 7, 8}
Move(B,a)
= {3,8}
𝜖-
Closure(Move(B,a))
= {3, 6, 7, 1, 2, 4,
8}
---- B
= {1,2,3,4,6,7,8}
b
10
9
States a b
A = {0,1,2,4,7} B C
B =
{1,2,3,4,6,7,8}
B
C = {1,2,4,5,6,7}
55.
Conversion from NFAto DFA
1
2
5
3
4
6 7 8
0
𝜖
a
b
𝜖 a b
𝜖
𝜖 𝜖
𝜖
𝜖
𝜖
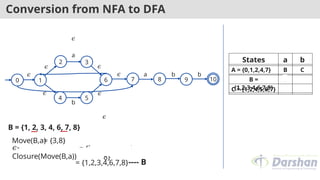
B= {1, 2, 3, 4, 6, 7,
8}
Move(B,b)
= {5,9}
𝜖-
Closure(Move(B,b))
= {5, 6, 7, 1, 2, 4,
9} ----
D
= {1,2,4,5,6,7,9}
b
10
9
States a b
A = {0,1,2,4,7} B C
B =
{1,2,3,4,6,7,8}
B D
C = {1,2,4,5,6,7}
D =
{1,2,4,5,6,7,9}
56.
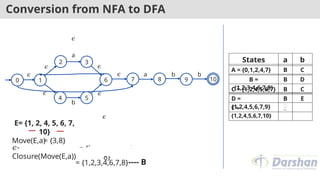
Conversion from NFAto DFA
1
2
5
3
4
6 7 8
0
𝜖
a
b
𝜖 a b
𝜖
𝜖 𝜖
𝜖
𝜖
𝜖
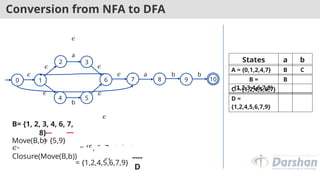
Move(C,a)
= {3,8}
𝜖-
Closure(Move(C,a))
= {3, 6, 7, 1, 2, 4,
8}
---- B
= {1,2,3,4,6,7,8}
C= {1, 2, 4, 5, 6 ,7}
b
10
9
States a b
A = {0,1,2,4,7} B C
B =
{1,2,3,4,6,7,8}
B D
C = {1,2,4,5,6,7} B
D =
{1,2,4,5,6,7,9}
57.
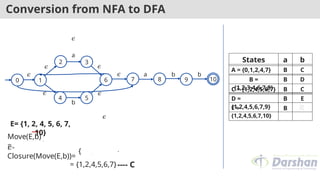
Conversion from NFAto DFA
1
2
5
3
4
6 7 8
0
𝜖
a
b
𝜖 a b b
𝜖
𝜖 𝜖
𝜖
𝜖
𝜖
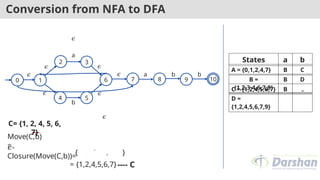
Move(C,b)
=
{5}
𝜖-
Closure(Move(C,b))={5, 6, 7, 1, 2, 4}
---- C
= {1,2,4,5,6,7}
C= {1, 2, 4, 5, 6,
7}
10
9
States a b
A = {0,1,2,4,7} B C
B =
{1,2,3,4,6,7,8}
B D
C = {1,2,4,5,6,7} B C
D =
{1,2,4,5,6,7,9}
58.
Conversion from NFAto DFA
1
2
5
3
4
6 7 8
0
𝜖
a
b
𝜖 a b b
𝜖
𝜖 𝜖
𝜖
𝜖
𝜖
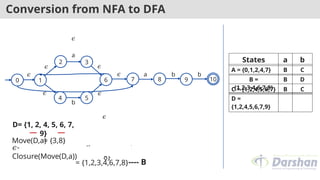
Move(D,a)
= {3,8}
𝜖-
Closure(Move(D,a))
= {3, 6, 7, 1, 2, 4,
8}
---- B
= {1,2,3,4,6,7,8}
D= {1, 2, 4, 5, 6, 7,
9}
10
9
States a b
A = {0,1,2,4,7} B C
B =
{1,2,3,4,6,7,8}
B D
C = {1,2,4,5,6,7} B C
D =
{1,2,4,5,6,7,9}
B
59.
Conversion from NFAto DFA
1
2
5
3
4
6 7 8
0
𝜖
a
b
𝜖 a b b
𝜖
𝜖 𝜖
𝜖
𝜖
𝜖
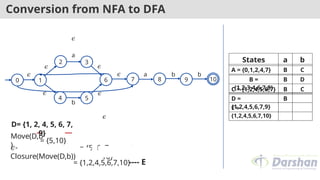
Move(D,b
)
= {5,10}
𝜖-
Closure(Move(D,b))
= {5, 6, 7, 1, 2, 4,
10}
---- E
= {1,2,4,5,6,7,10}
D= {1, 2, 4, 5, 6, 7,
9}
10
9
States a b
A = {0,1,2,4,7} B C
B =
{1,2,3,4,6,7,8}
B D
C = {1,2,4,5,6,7} B C
D =
{1,2,4,5,6,7,9}
B E
E =
{1,2,4,5,6,7,10}
60.
Conversion from NFAto DFA
1
2
5
3
4
6 7 8
0
𝜖
a
b
𝜖 a b b
𝜖
𝜖 𝜖
𝜖
𝜖
𝜖
Move(E,a)
= {3,8}
𝜖-
Closure(Move(E,a))
= {3, 6, 7, 1, 2, 4,
8}
---- B
= {1,2,3,4,6,7,8}
E= {1, 2, 4, 5, 6, 7,
10}
10
9
States a b
A = {0,1,2,4,7} B C
B =
{1,2,3,4,6,7,8}
B D
C = {1,2,4,5,6,7} B C
D =
{1,2,4,5,6,7,9}
B E
E =
{1,2,4,5,6,7,10}
B
61.
Conversion from NFAto DFA
1
2
5
3
4
6 7 8
0
𝜖
a
b
𝜖 a b b
𝜖
𝜖 𝜖
𝜖
𝜖
𝜖
Move(E,b)
=
{5}
𝜖-
Closure(Move(E,b))=
{5,6,7,1,2,4}
---- C
= {1,2,4,5,6,7}
States a b
A = {0,1,2,4,7} B C
B =
{1,2,3,4,6,7,8}
B D
C = {1,2,4,5,6,7} B C
E= {1, 2, 4, 5, 6, 7,
10}
D =
{1,2,4,5,6,7,9}
B E
E =
{1,2,4,5,6,7,10}
B C
10
9
62.
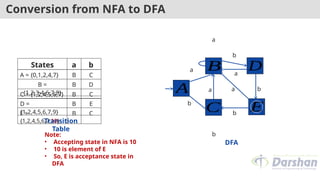
Conversion from NFAto DFA
A
B
C
a
b
a
b
a
D
E
b
a
b
b
a
Transition
Table
DFA
Note:
• Accepting state in NFA is 10
• 10 is element of E
• So, E is acceptance state in
DFA
States a b
A = {0,1,2,4,7} B C
B =
{1,2,3,4,6,7,8}
B D
C = {1,2,4,5,6,7} B C
D =
{1,2,4,5,6,7,9}
B E
E =
{1,2,4,5,6,7,10}
B C
63.
Exercise
Convert followingregular expression to DFA using subset construction method:
1. (a+b)*a(a+b)
2. (a+b)*ab*a
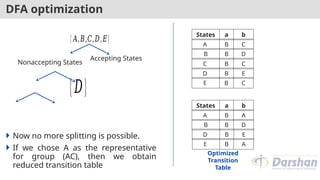
DFA optimization
1. Constructan initial partition of the set of states with two groups: the
accepting states and the non-accepting states .
2. Apply the repartition procedure to to construct a new partition .
3. If , let and continue with step (4). Otherwise, repeat step (2) with .
for each group of do begin
partition into subgroups such that two states and
of are in the same subgroup if and only if for all
input symbols , states and have transitions on
to states in the same group of .
replace in by the set of all subgroups formed.
end
66.
DFA optimization
4. Chooseone state in each group of the partition as the representative for that
group. The representatives will be the states of . Let s be a representative
state, and suppose on input a there is a transition of from to . Let be the
representative of s group. Then has a transition from to on . Let the start
state of be the representative of the group containing start state of , and let
the accepting states of be the representatives that are in .
5. If has a dead state , then remove from . Also remove any state not reachable
from the start state.
67.
DFA optimization
Nowno more splitting is possible.
If we chose A as the representative
for group (AC), then we obtain
reduced transition table
A B C
B B D
C B C
D B E
E B C
States a b
{𝐴,𝐵,𝐶,𝐷,𝐸}
Nonaccepting States
Accepting States
{𝐷}
A B A
B B D
D B E
E B A
States a b
Optimized
Transition
Table
Rules to computenullable, firstpos, lastpos
nullable(n)
The subtree at node generates languages including the empty string.
firstpos(n)
The set of positions that can match the first symbol of a string generated by the
subtree at node
lastpos(n)
The set of positions that can match the last symbol of a string generated be the
subtree at node
followpos(i)
The set of positions that can follow position in the tree.
70.
Rules to computenullable, firstpos, lastpos
Node n nullable(n) firstpos(n) lastpos(n)
A leaf labeled
by
true
A leaf with
position
false
nullable(c1)
or
nullable(c2)
firstpos(c1)
firstpos(c2)
lastpos(c1)
lastpos(c2)
nullable(c1)
and
nullable(c2)
if (nullable(c1))
thenfirstpos(c1)
firstpos(c2)
else firstpos(c1)
if (nullable(c2))
then
lastpos(c1)
lastpos(c2)
else lastpos(c2)
true firstpos(c1) lastpos(c1)
¿
n
c1 c2
n
∗
n
.
c1 c2
c1
71.
Rules to computefollowpos
1. If n is concatenation node with left child c1 and right child c2 and i is a
position in lastpos(c1), then all position in firstpos(c2) are in followpos(i)
2. If n is * node and i is position in lastpos(n), then all position in firstpos(n) are
in followpos(i)
72.
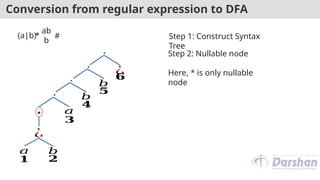
Conversion from regularexpression to DFA
𝑎 𝑏
¿
∗
.
𝟏 𝟐
𝑎
.
.
.
𝑏
𝑏
¿
(a|b)*
ab
b
𝟒
𝟑
𝟓
𝟔
#
Step 2: Nullable node
Here, * is only nullable
node
Step 1: Construct Syntax
Tree
73.
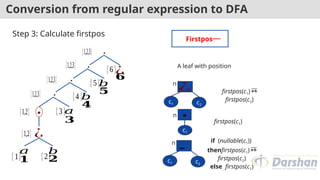
Conversion from regularexpression to DFA
𝑎 𝑏
¿
∗
.
{1} {2}
{1,2}
{1,2} 𝑎
{3}
{1,2,3}
.
{4 }
{1,2,3}
.
{5}
{1,2,3}
.
{6}
{1,2,3}
𝑏
𝑏
¿
Step 3: Calculate firstpos
Firstpos
A leaf with position
¿
n
c1 c2
firstpos(c1)
firstpos(c2)
∗
n
c1
firstpos(c1)
.
n
c1 c2
𝟏 𝟐
𝟒
𝟑
𝟓
𝟔
if (nullable(c1))
thenfirstpos(c1)
firstpos(c2)
else firstpos(c1)
74.
Conversion from regularexpression to DFA
𝑎 𝑏
¿
∗
.
{1} {1} {2} {2}
{1,2} {1,2}
{1,2} {1,2} 𝑎
{3} {3}
{1,2,3} {3}
.
{4 } {4 }
{1,2,3} {4 }
.
{5} {5}
{1,2,3} {5}
.
{6} {6}
{1,2,3} {6}
𝑏
𝑏
¿
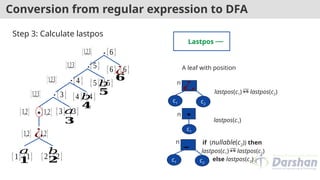
Step 3: Calculate lastpos
𝟏 𝟐
𝟒
𝟑
𝟓
𝟔
Lastpos
A leaf with position
¿
n
c1 c2
if (nullable(c2)) then
lastpos(c1) lastpos(c2)
else lastpos(c2)
∗
n
c1
lastpos(c1)
.
n
c1 c2
lastpos(c1) lastpos(c2)
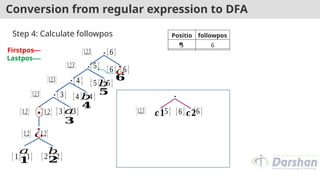
Conversion from regularexpression to DFA
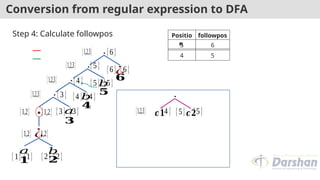
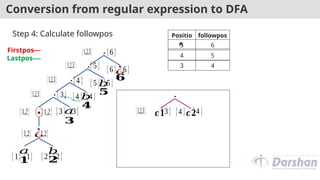
Initial state = of root = {1,2,3} ----- A
State A
δ( (1,2,3),a) = followpos(1) U followpos(3)
=(1,2,3) U (4) = {1,2,3,4} ----- B
δ( (1,2,3),b) = followpos(2)
=(1,2,3) ----- A
Positio
n
followpos
5 6
4 5
3 4
2 1,2,3
1 1,2,3
States a b
A={1,2,3} B A
B={1,2,3,4}
81.
Conversion from regularexpression to DFA
State B
δ( (1,2,3,4),a) = followpos(1) U followpos(3)
=(1,2,3) U (4) = {1,2,3,4} ----- B
δ( (1,2,3,4),b) = followpos(2) U followpos(4)
=(1,2,3) U (5) = {1,2,3,5} ----- C
State C
δ( (1,2,3,5),a) = followpos(1) U followpos(3)
=(1,2,3) U (4) = {1,2,3,4} ----- B
δ( (1,2,3,5),b) = followpos(2) U followpos(5)
=(1,2,3) U (6) = {1,2,3,6} ----- D
Positio
n
followpos
5 6
4 5
3 4
2 1,2,3
1 1,2,3
States a b
A={1,2,3} B A
B={1,2,3,4} B C
C={1,2,3,5} B D
D={1,2,3,6
}
82.
Conversion from regularexpression to DFA
State D
δ( (1,2,3,6),a) = followpos(1) U followpos(3)
=(1,2,3) U (4) = {1,2,3,4} ----- B
δ( (1,2,3,6),b) = followpos(2)
=(1,2,3) ----- A
Positio
n
followpos
5 6
4 5
3 4
2 1,2,3
1 1,2,3
States a b
A={1,2,3} B A
B={1,2,3,4} B C
C={1,2,3,5} B D
D={1,2,3,6
}
B A
A B C D
a b b
b
a
a
b
a
DFA
83.
Conversion from regularexpression to DFA
Construct DFA for following regular expression:
1. (c | d)*c#