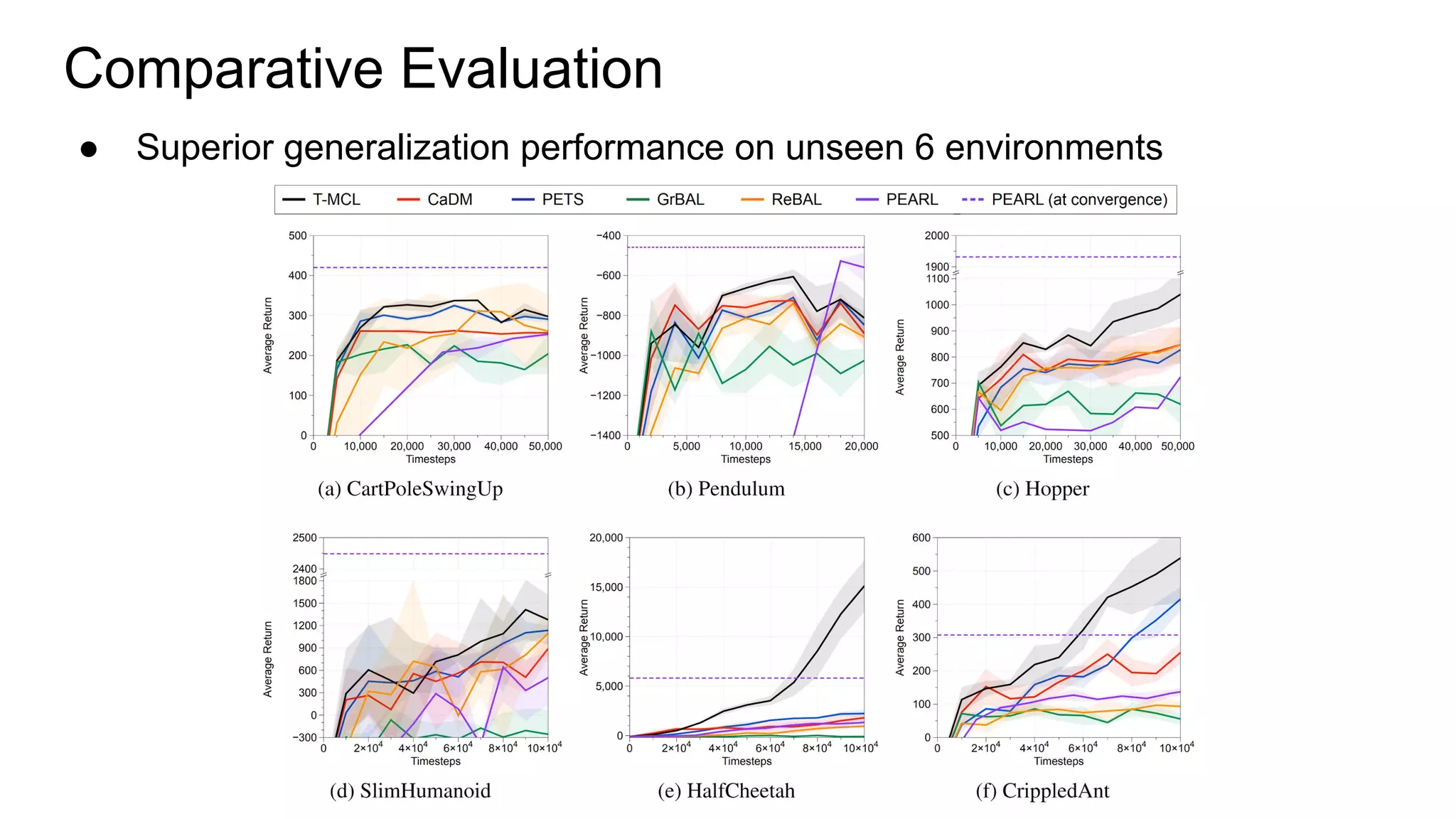
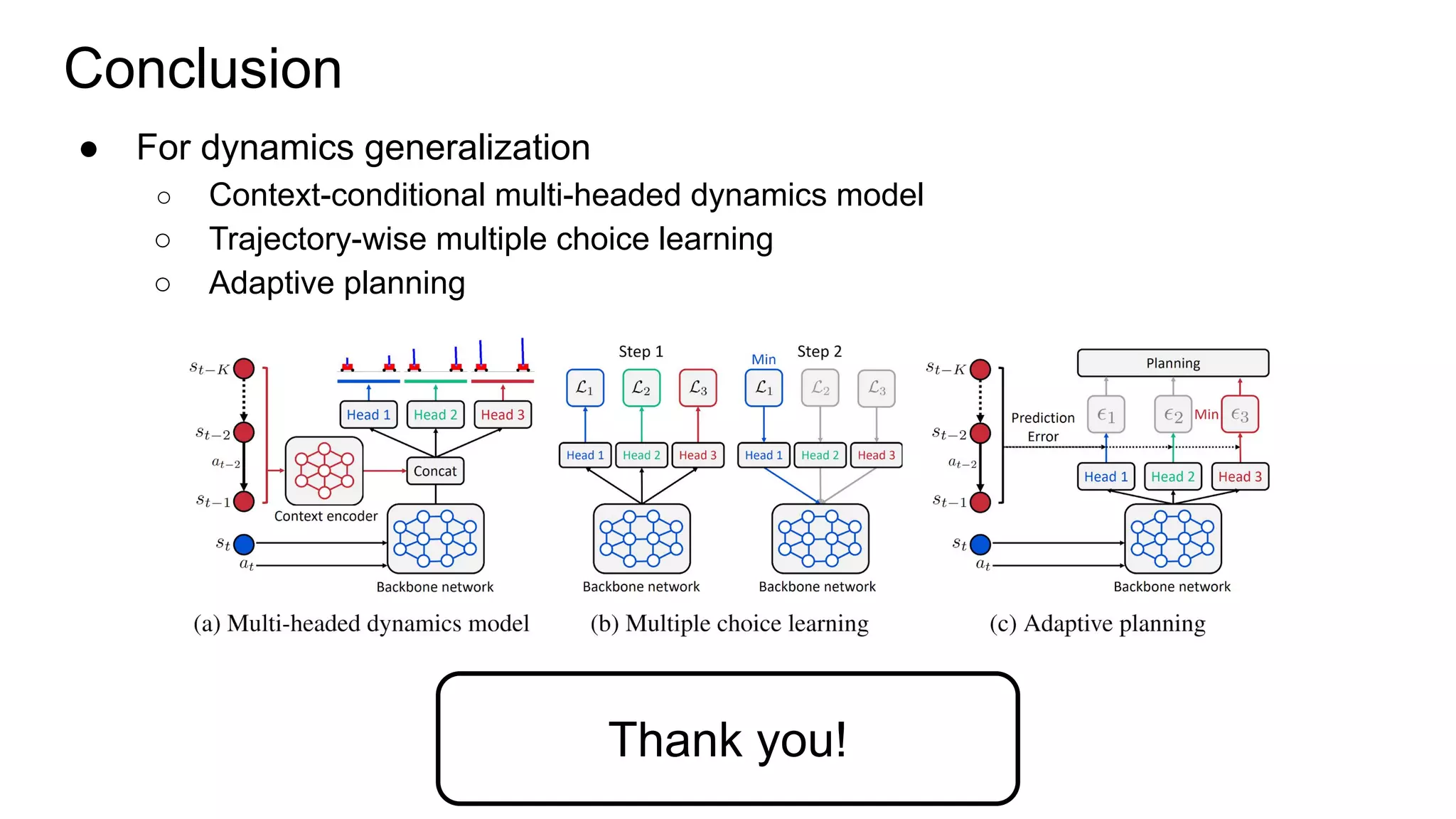
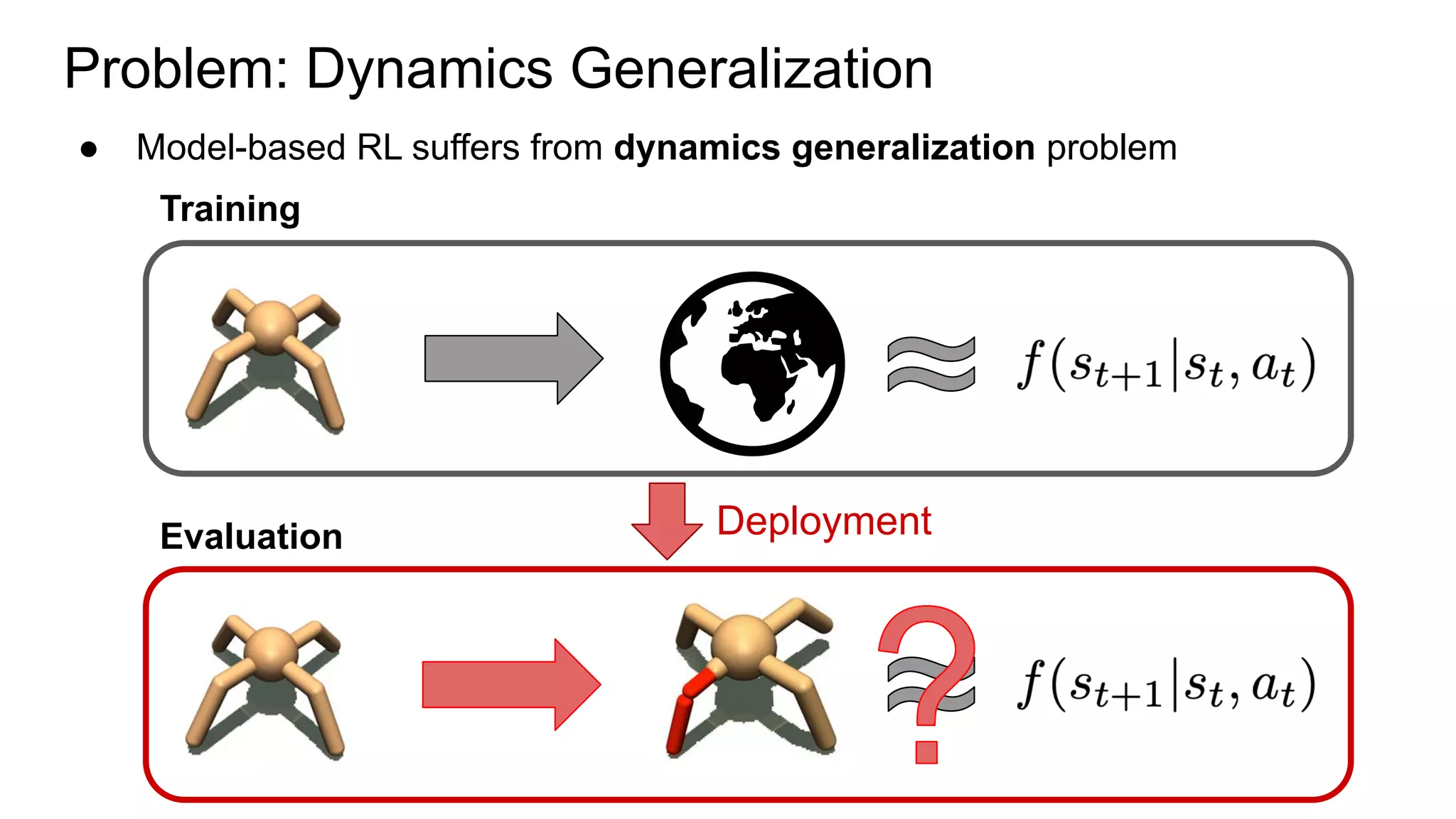
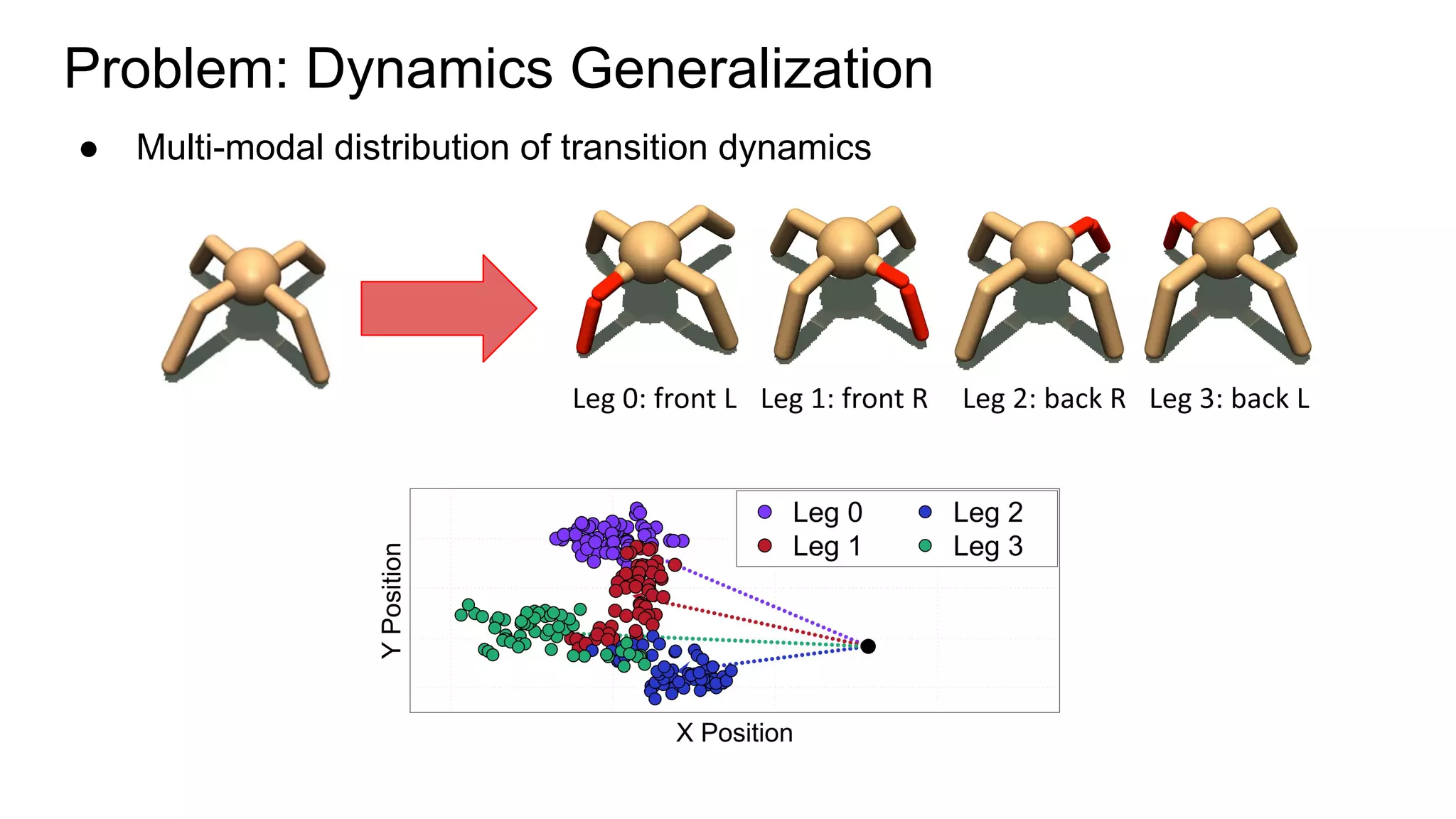
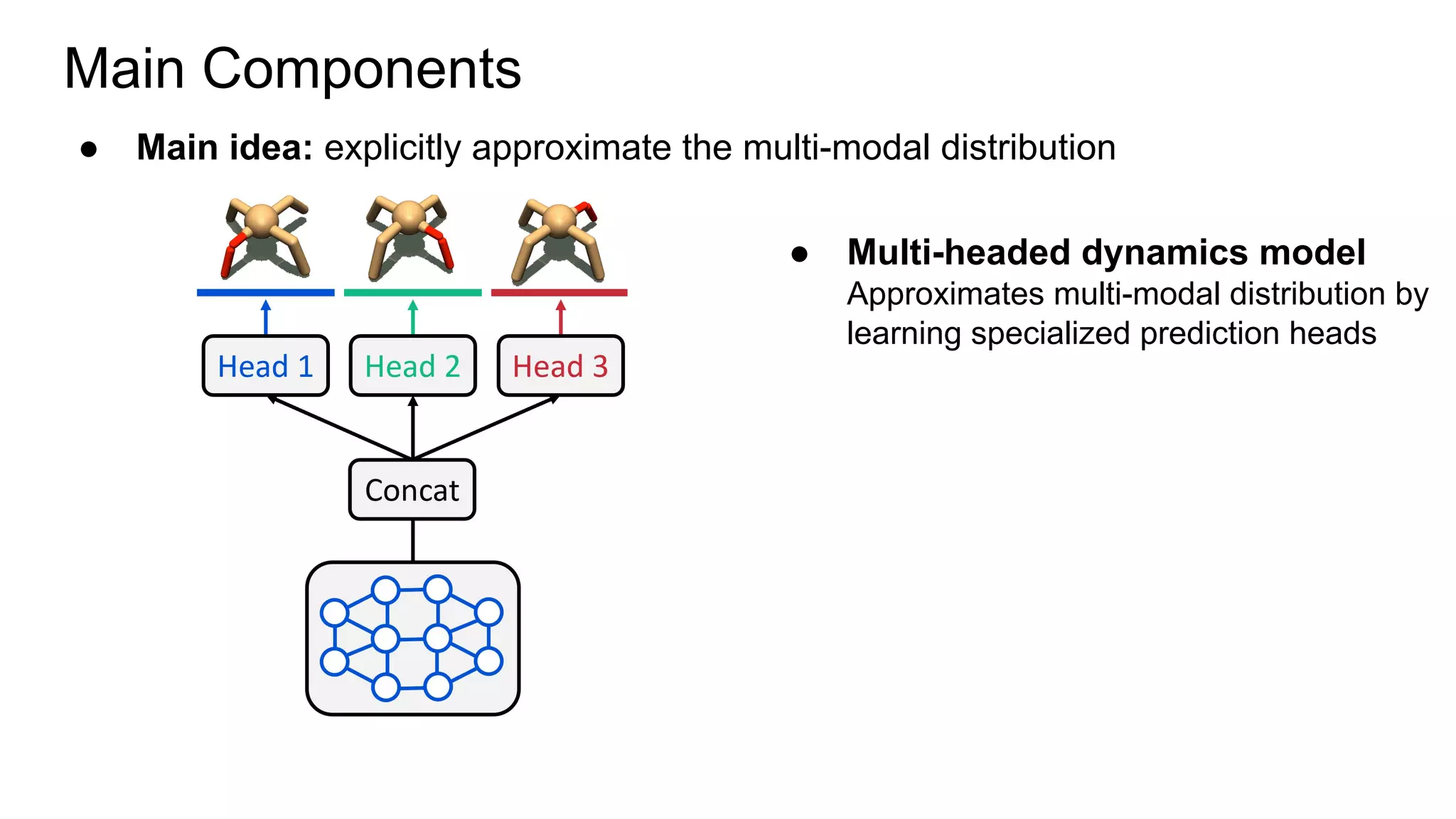
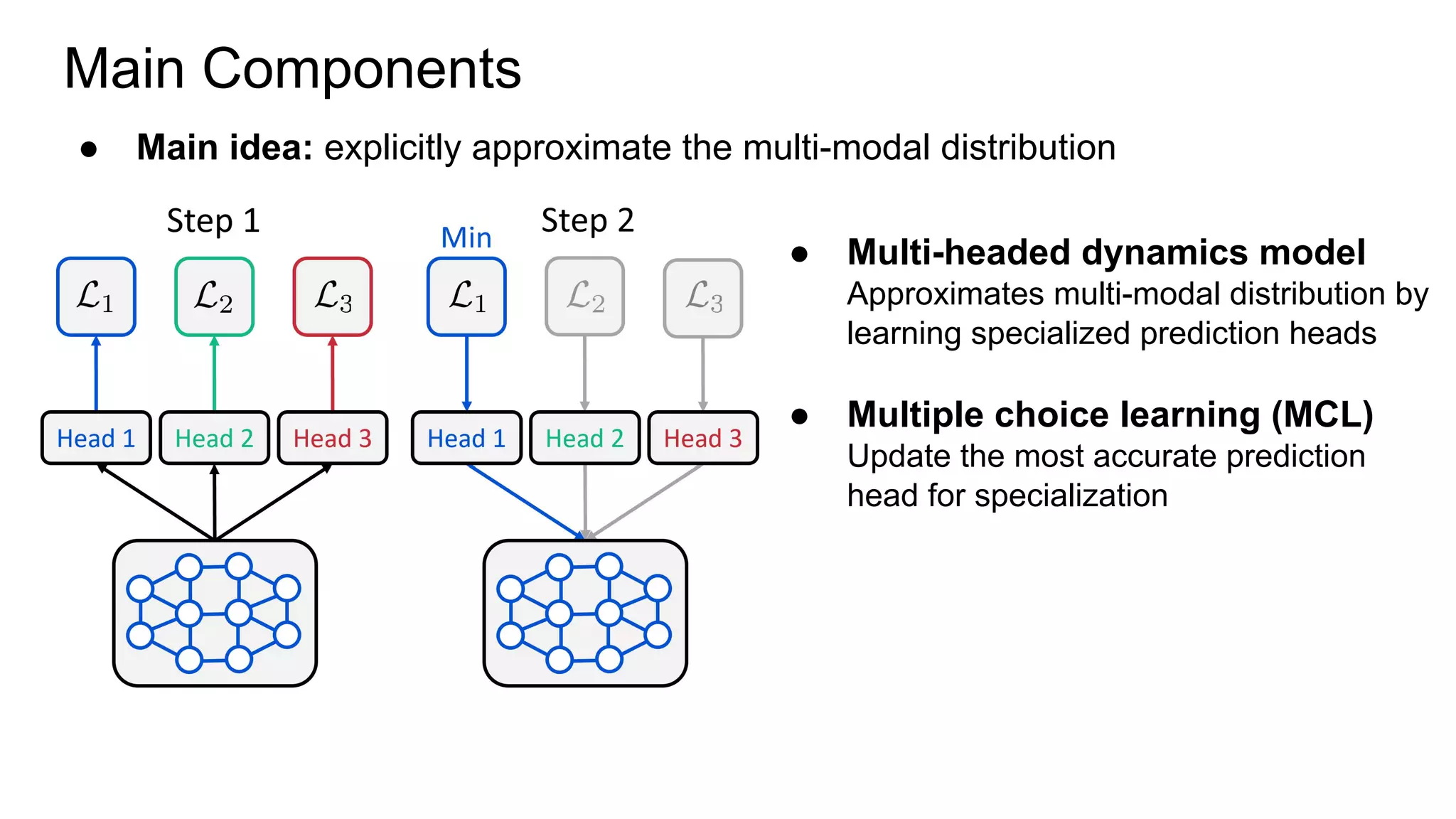
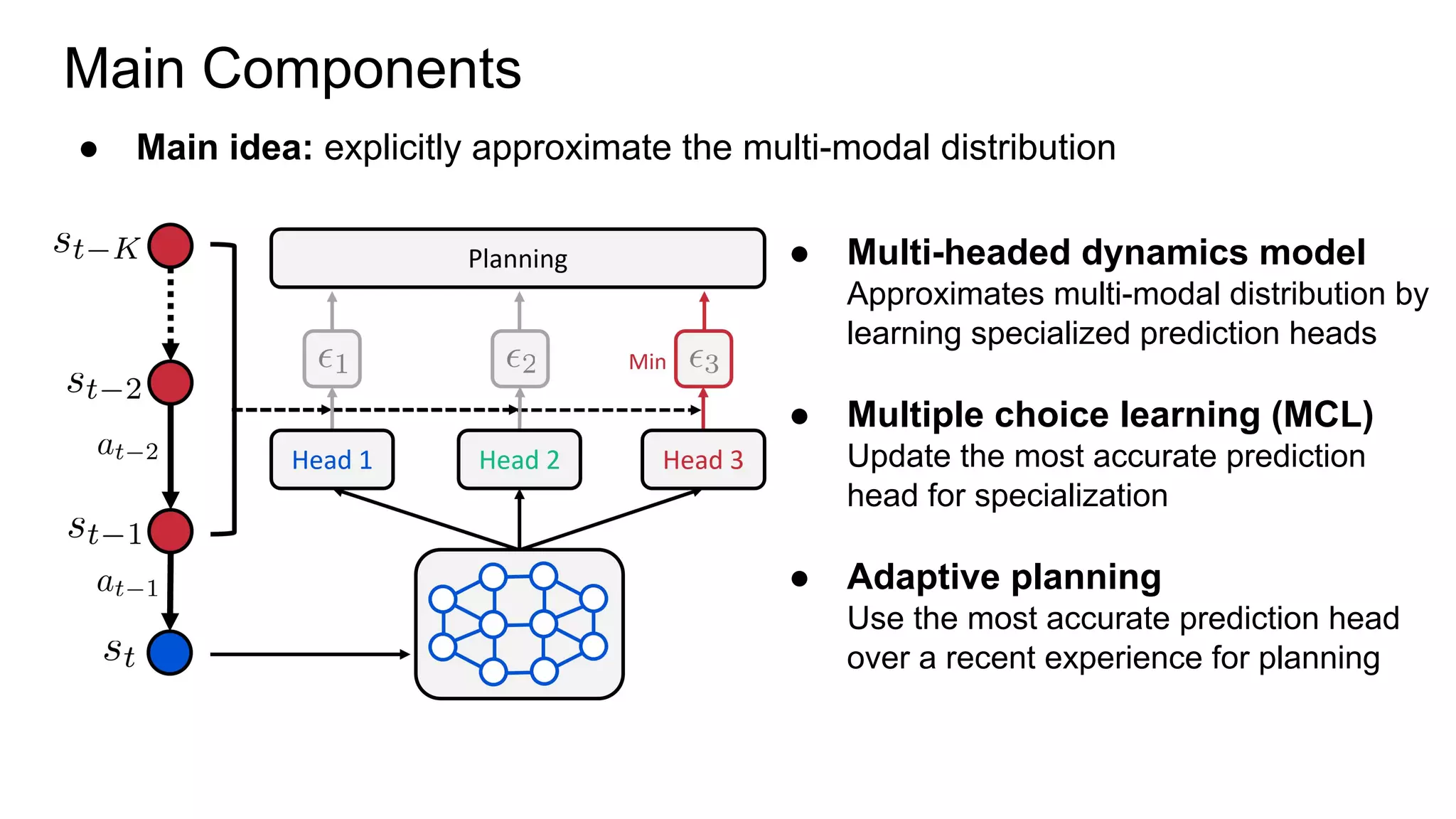
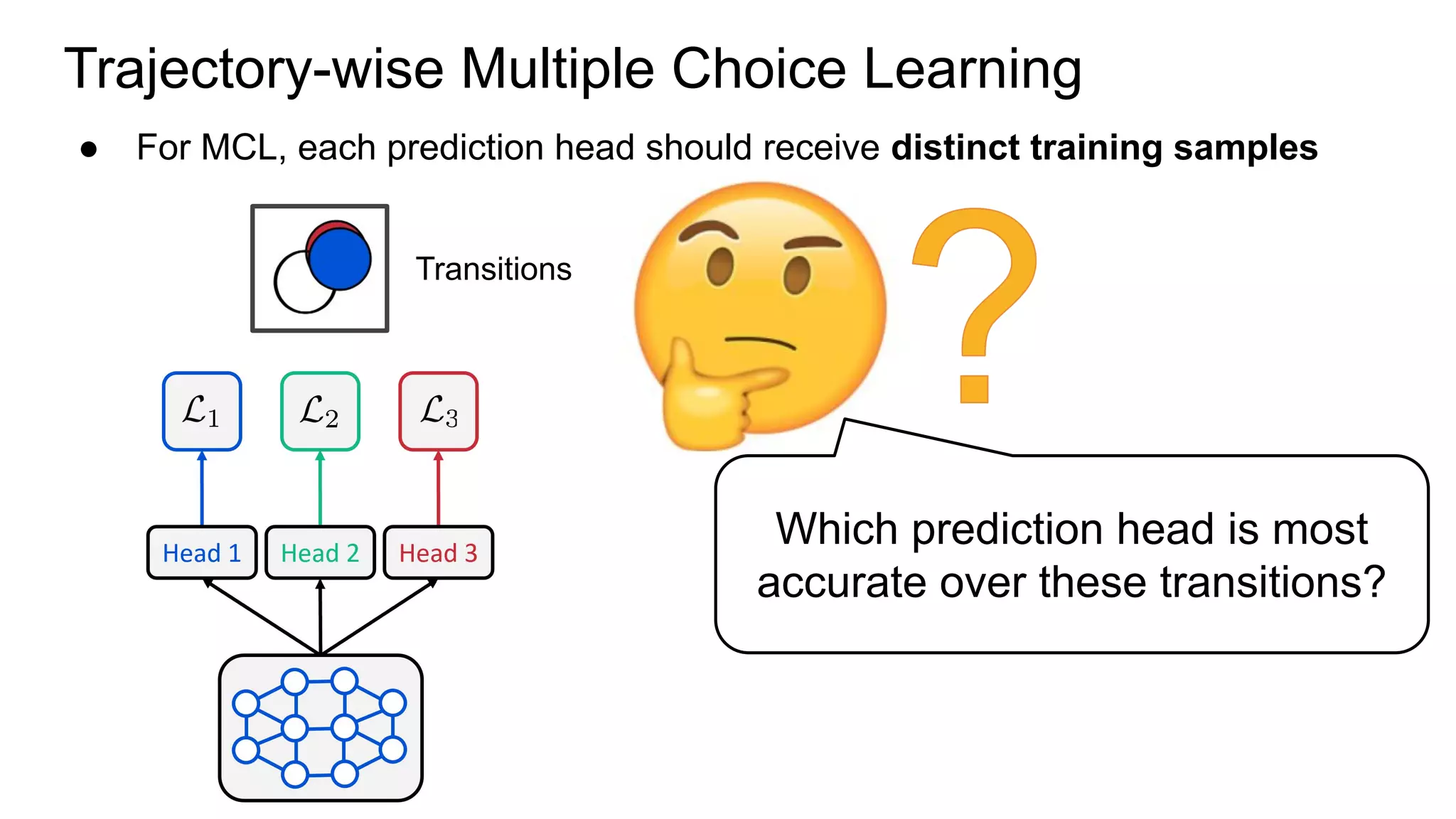
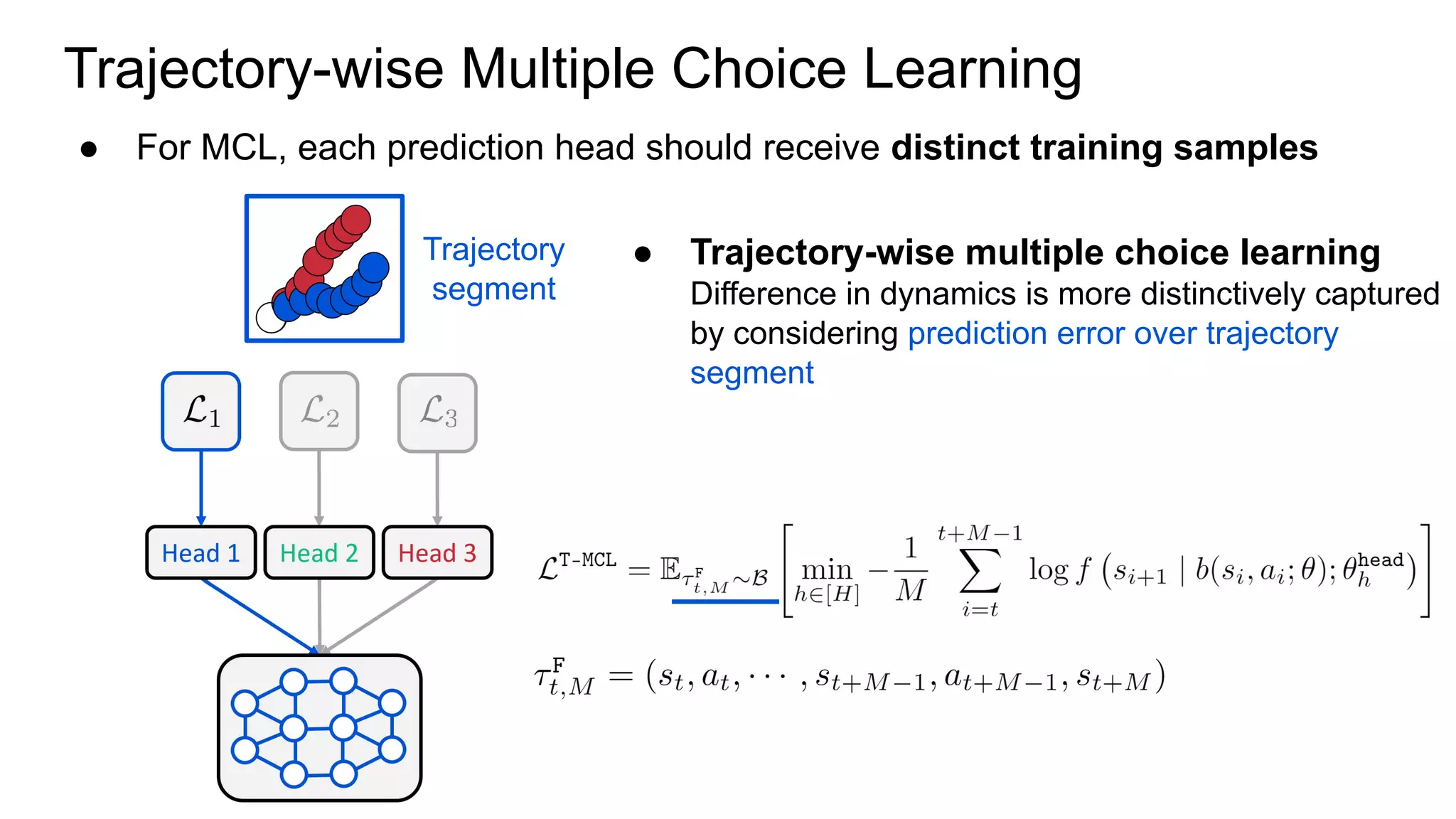
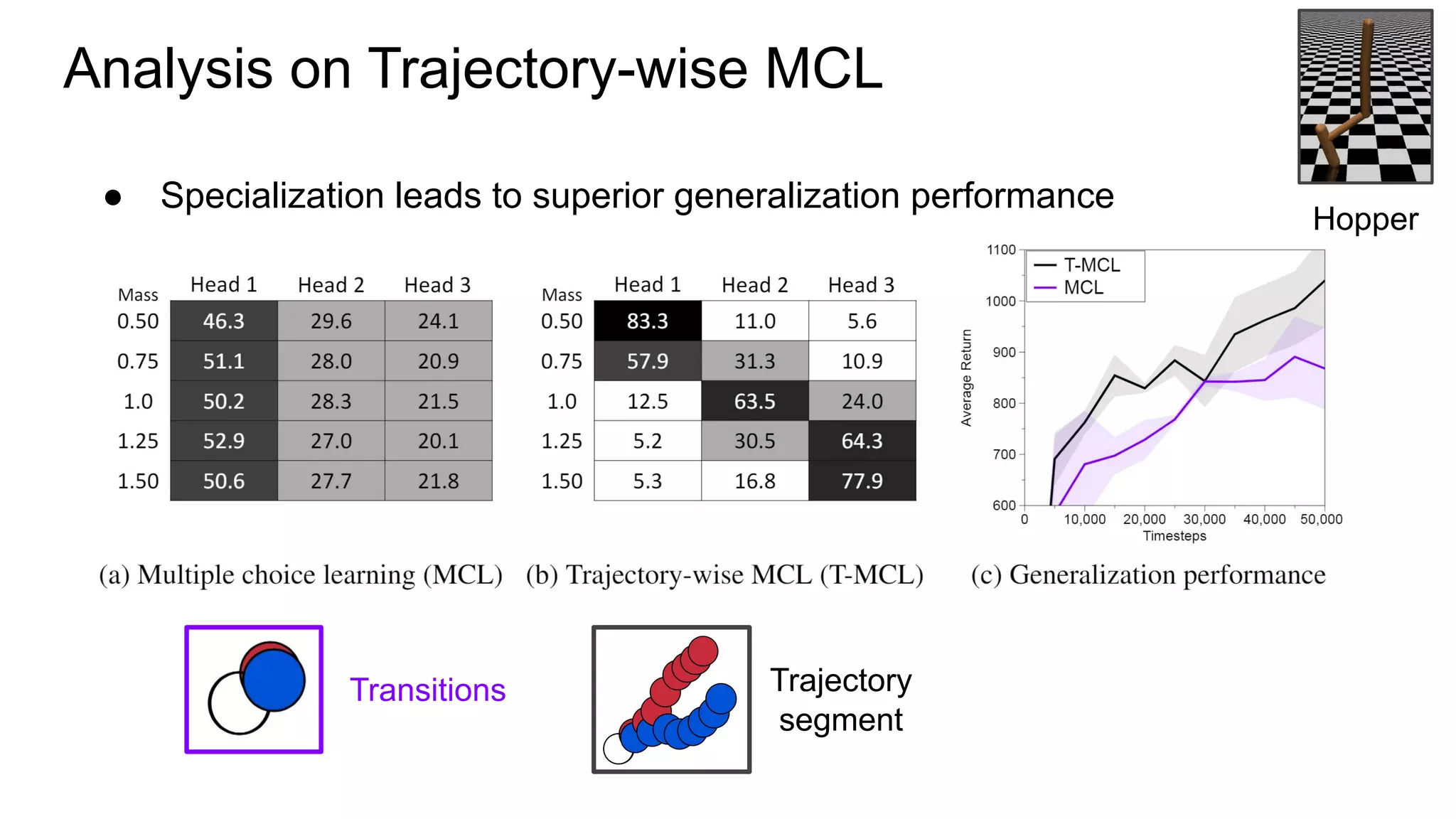
This document proposes a method called Trajectory-wise Multiple Choice Learning (MCL) to improve generalization in model-based reinforcement learning. The method uses a multi-headed dynamics model to approximate the multi-modal distribution of transition dynamics. Trajectory-wise MCL updates the prediction head that is most accurate over an entire trajectory segment, allowing each head to specialize. An adaptive planning method then uses the most accurate head based on recent experience. Evaluation shows the approach achieves superior generalization to new environments compared to baseline methods.

![Context-conditional Multi-headed Dynamics Model
● We also introduce context encoder for online adaptation to unseen environments
● Context encoder g captures
contextual information from past
experience
● See [Lee’20] for more information
[Lee’20] Lee, Kimin, Younggyo Seo, Seunghyun Lee, Honglak Lee, Jinwoo Shin. "Context-aware Dynamics Model for Generalization in Model-Based Reinforcement Learning." In
ICML. 2020.](https://image.slidesharecdn.com/slides-201027191436/75/Trajectory-wise-Multiple-Choice-Learning-for-Dynamics-Generalization-in-Reinforcement-Learning-9-2048.jpg)
![Analysis on Adaptive Planning
● Qualitative analysis
○ Manually assign prediction heads specialized for [mass: 2.5] to [mass: 1.0]
[Mass: 1.0]
with prediction heads
specialized for [Mass: 2.5]
[Mass: 2.5]
with prediction heads
specialized for [Mass: 2.5]
Agent acts as if it has a heavyweight body!](https://image.slidesharecdn.com/slides-201027191436/75/Trajectory-wise-Multiple-Choice-Learning-for-Dynamics-Generalization-in-Reinforcement-Learning-11-2048.jpg)