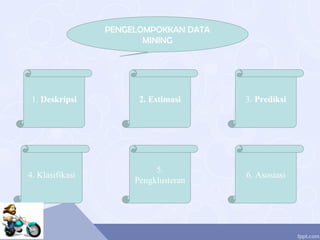
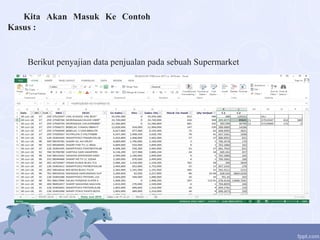
Dokumen tersebut membahas implementasi aljabar linear dalam teknologi data mining. Secara khusus membahas beberapa metode pengelompokan data mining seperti deskripsi, estimasi, prediksi, klasifikasi, pengkusteran, dan asosiasi. Metode pengkusteran seperti k-means dan mixture modelling dijelaskan secara singkat. Contoh kasus penjualan di supermarket diberikan untuk memperjelas pembahasan.