













![{
"@id": "/recipes/",
"@type": "Collection",
"member": [ ... ],
...
"operation": {
"@type": "AddAction",
"method": "POST",
"expects": "Recipe"
}
}
{
"@id": "Recipe",
"@type": "Class",
"supportedProperty": {
"property": "name",
"required": true
}
}](https://image.slidesharecdn.com/theweb3-140505041048-phpapp01/75/The-Web-3-0-is-just-around-the-corner-Be-prepared-24-2048.jpg)
![{
"@id": "/users/markus/recipes/",
"@type": "Collection",
"member": [ ... ],
...
"operation": {
"@type": "AddAction",
"method": "POST",
"expects": "Recipe"
}
}
{
"@id": "Recipe",
"@type": "Class",
"supportedProperty": {
"property": "name",
"required": true
}
}](https://image.slidesharecdn.com/theweb3-140505041048-phpapp01/75/The-Web-3-0-is-just-around-the-corner-Be-prepared-25-2048.jpg)
![{
"@id": "/users/markus/recipes/",
"@type": "Collection",
"member": [ ... ],
...
}
{
"@type": "AddAction",
"method": "POST",
"expects": "Recipe"
}](https://image.slidesharecdn.com/theweb3-140505041048-phpapp01/75/The-Web-3-0-is-just-around-the-corner-Be-prepared-26-2048.jpg)
![{
"@id": "RecipeCollection",
"@type": "Class",
"subClassOf": "Collection",
"supportedOperation": {
"@type": "AddAction",
"method": "POST",
"expects": "Recipe"
}
}
{
"@id": "/users/markus/recipes/",
"@type": "RecipeCollection",
"member": [ ... ],
...
}
{
"@type": "AddAction",
"method": "POST",
"expects": "Recipe"
}](https://image.slidesharecdn.com/theweb3-140505041048-phpapp01/75/The-Web-3-0-is-just-around-the-corner-Be-prepared-27-2048.jpg)

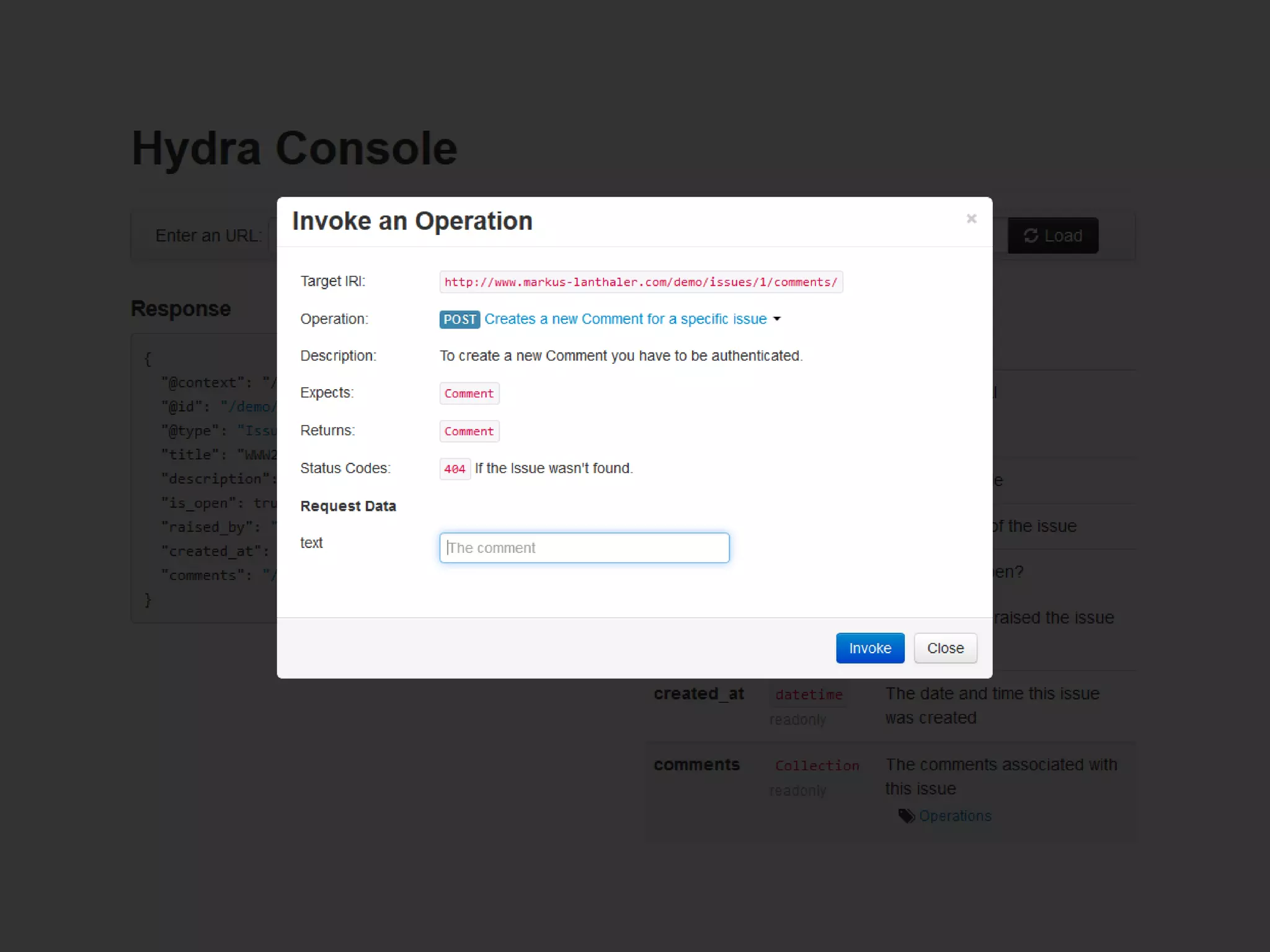




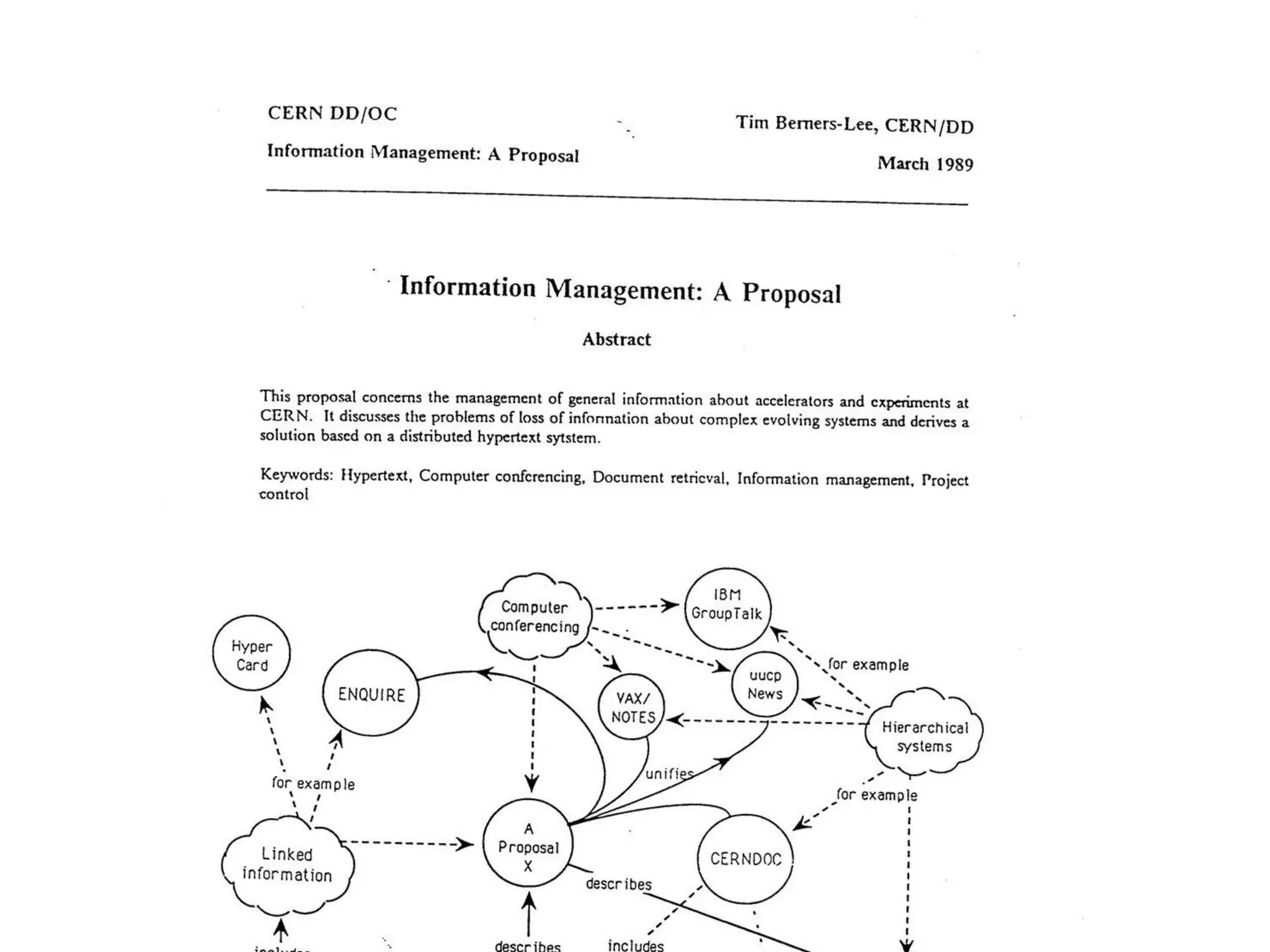
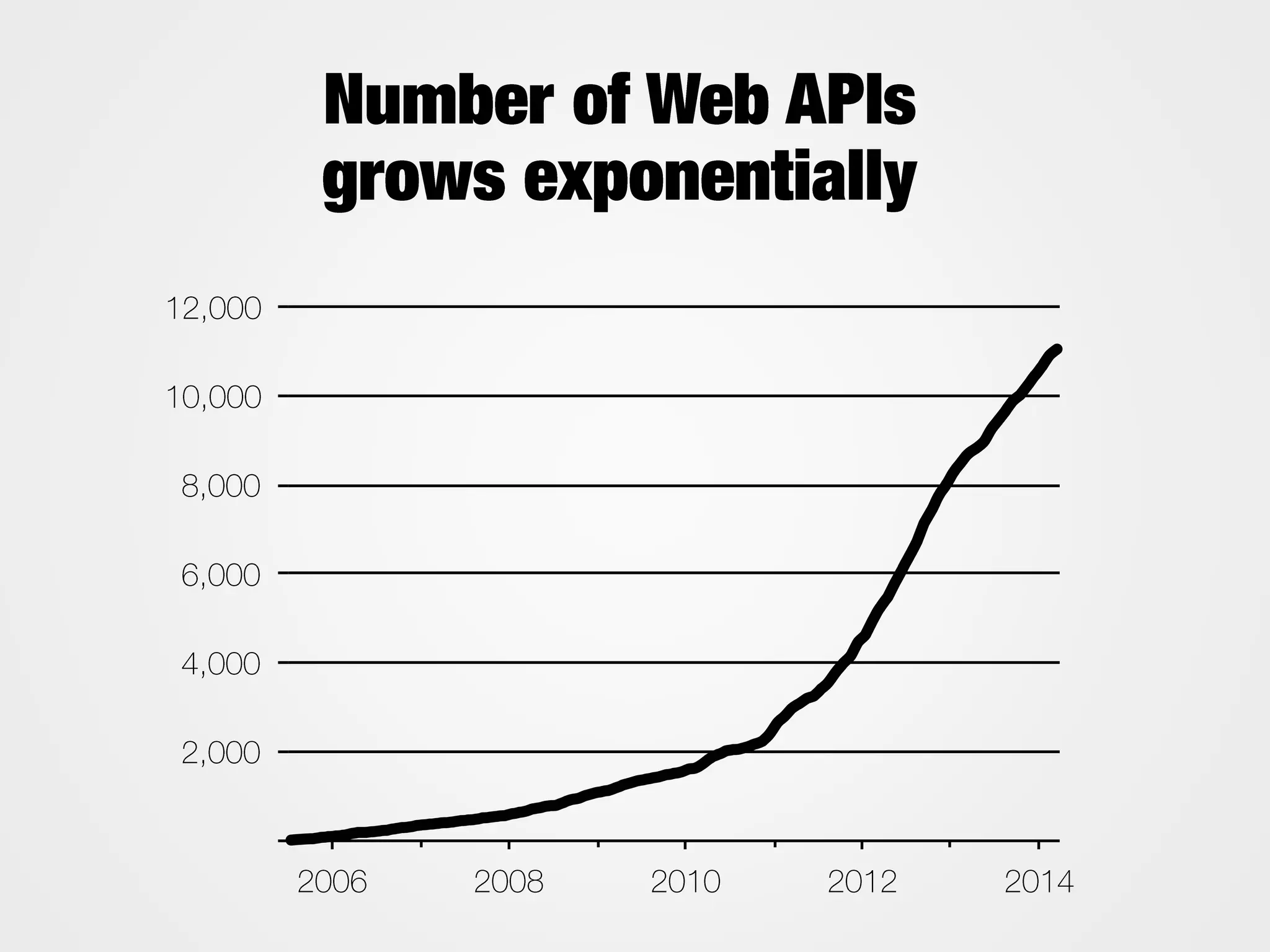
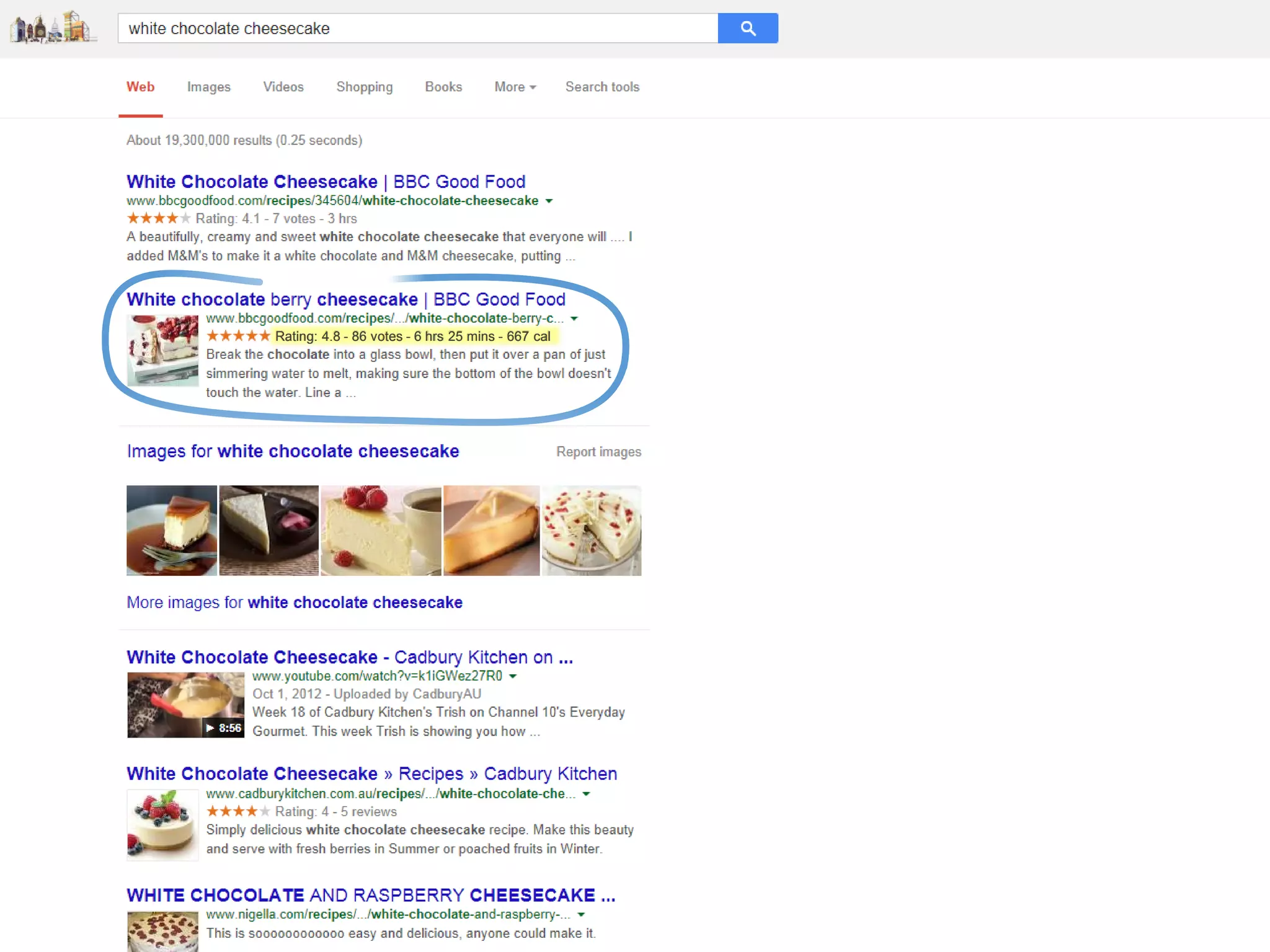
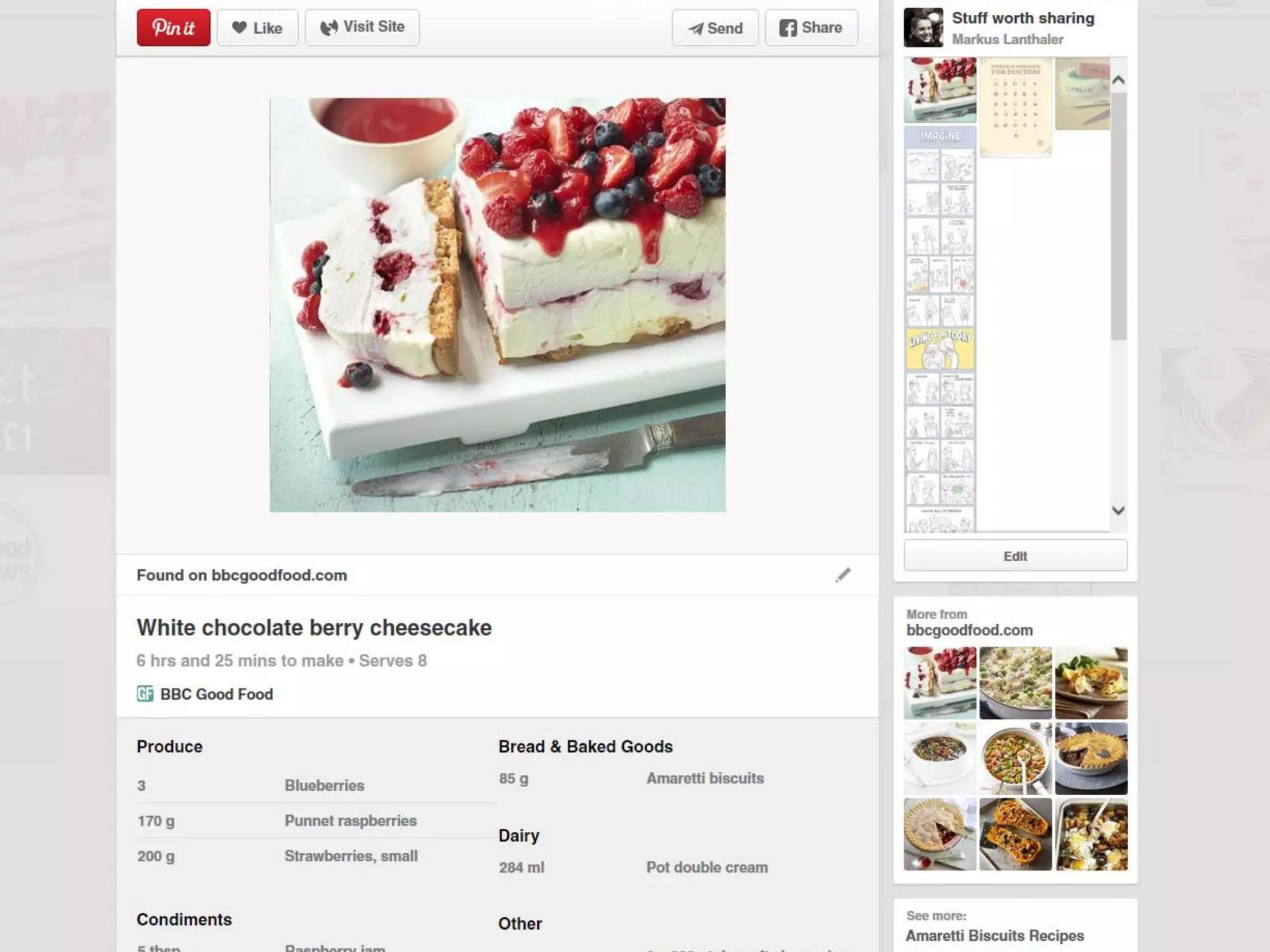
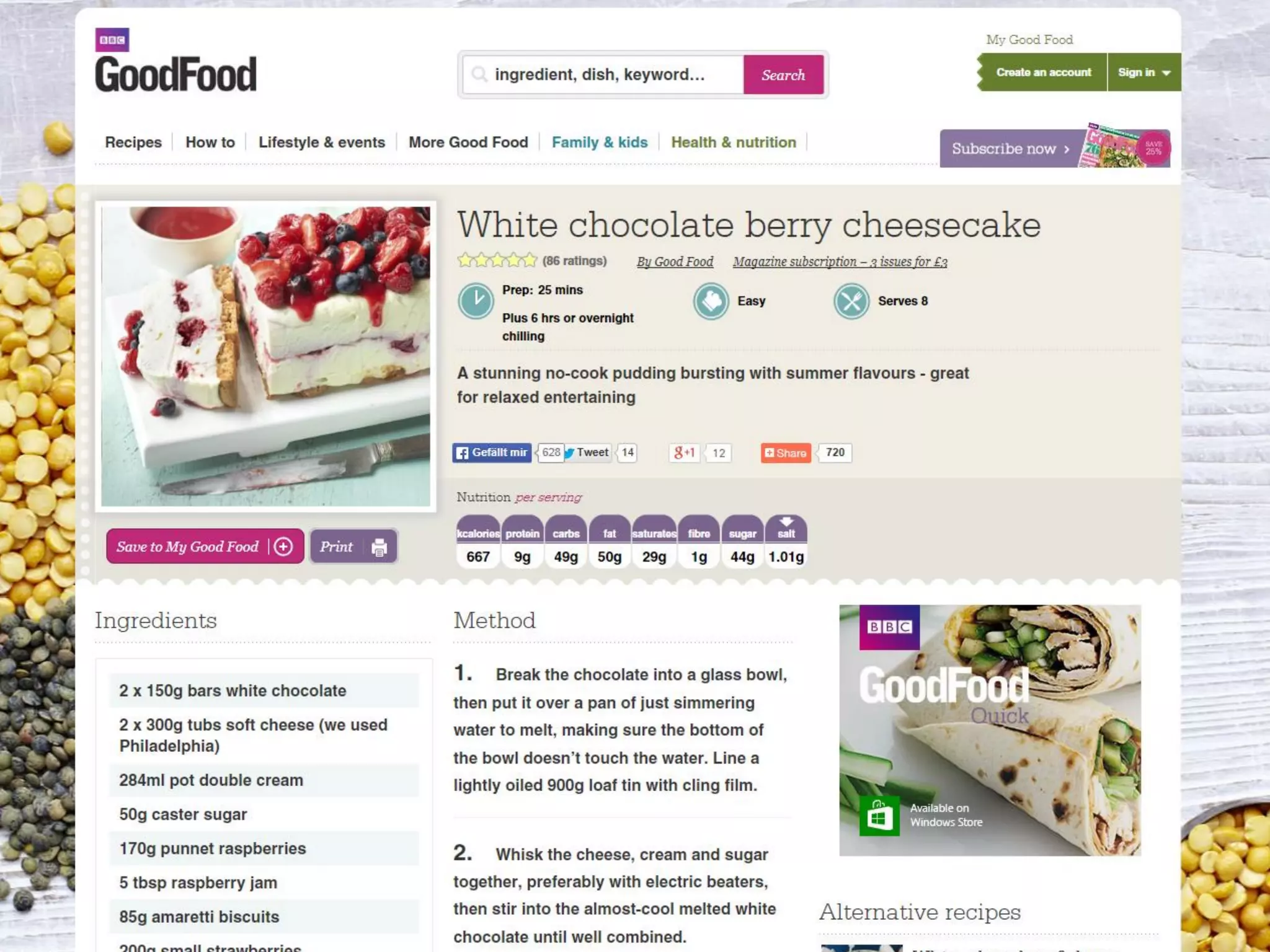
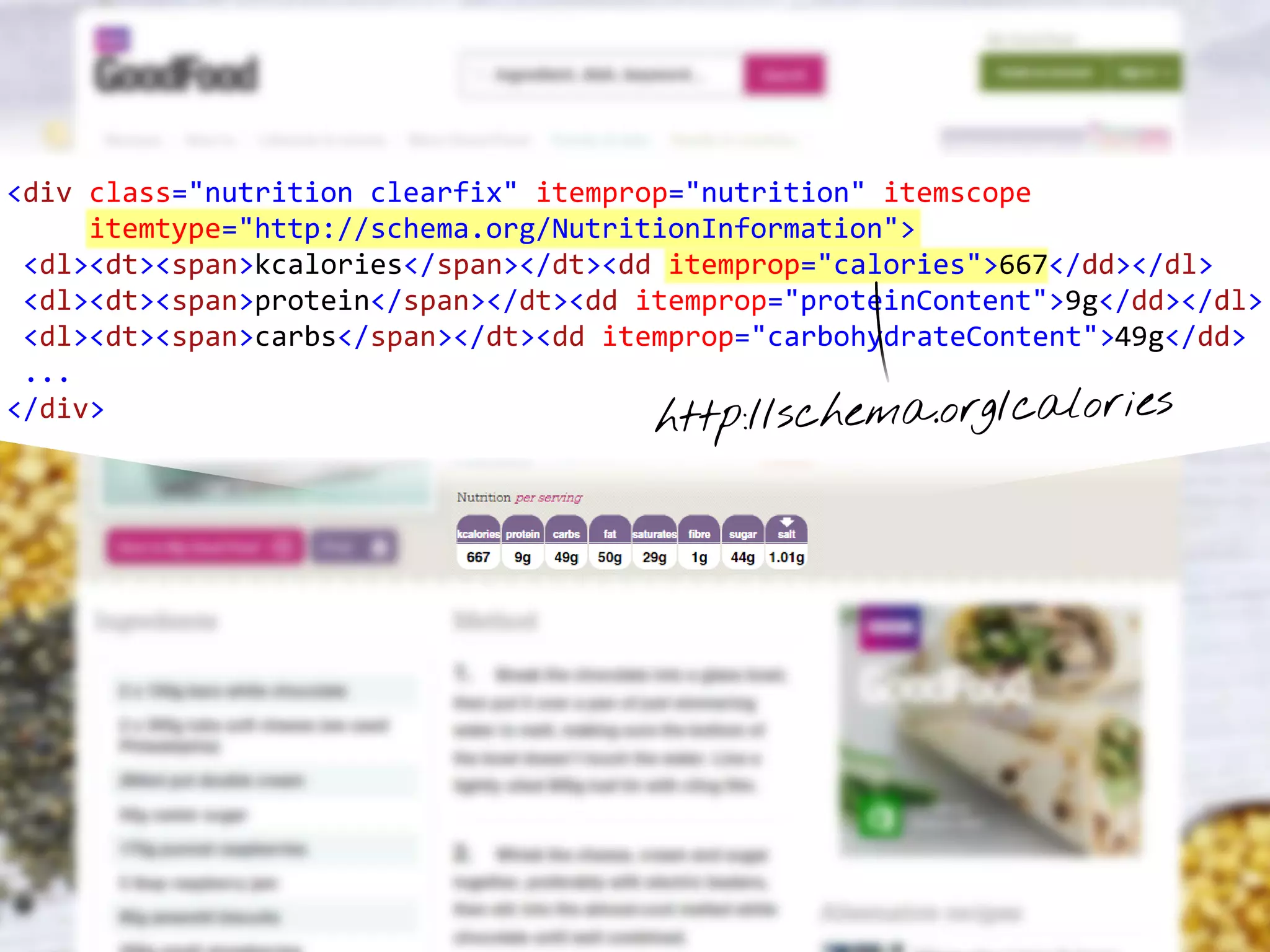
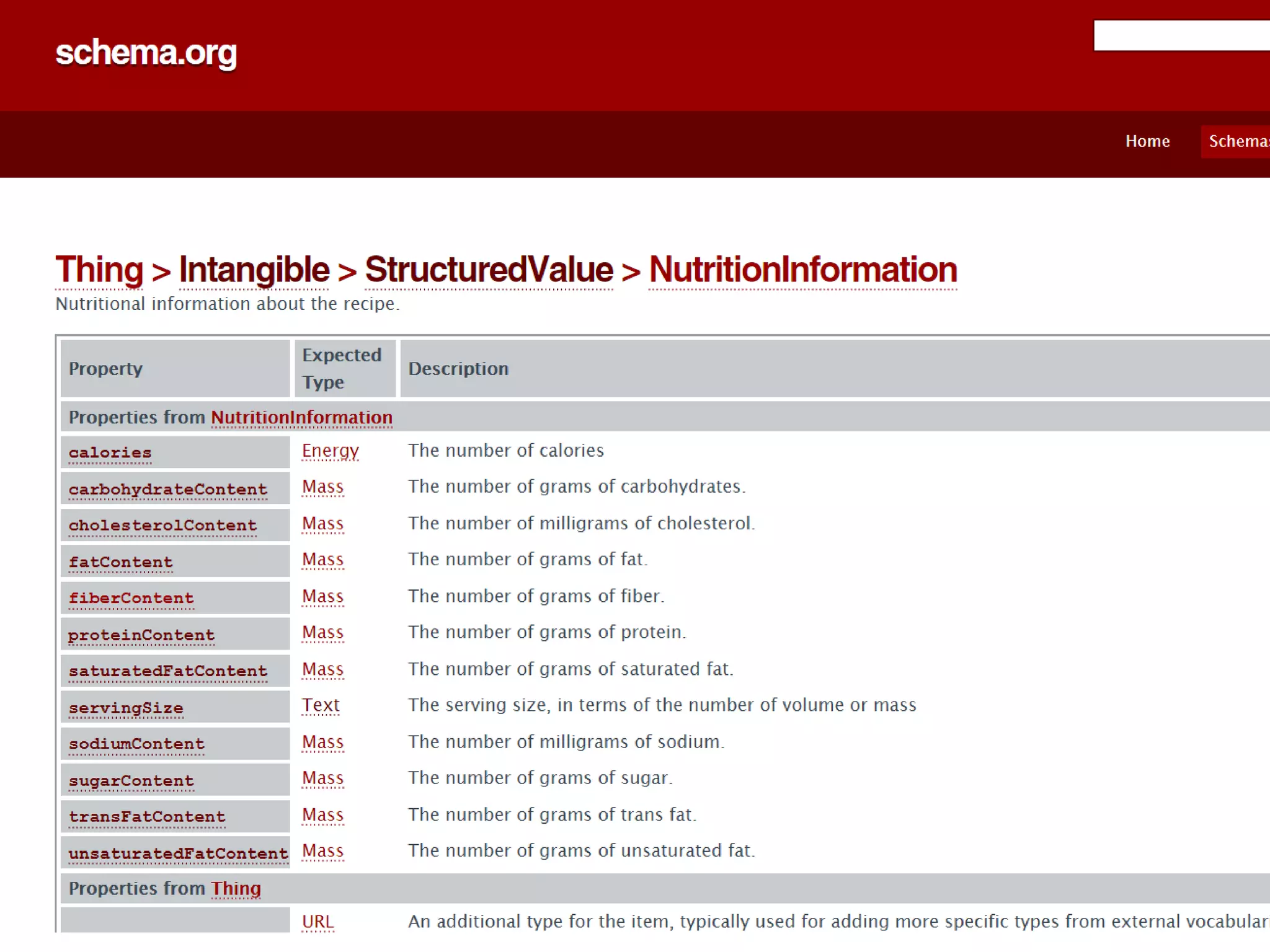
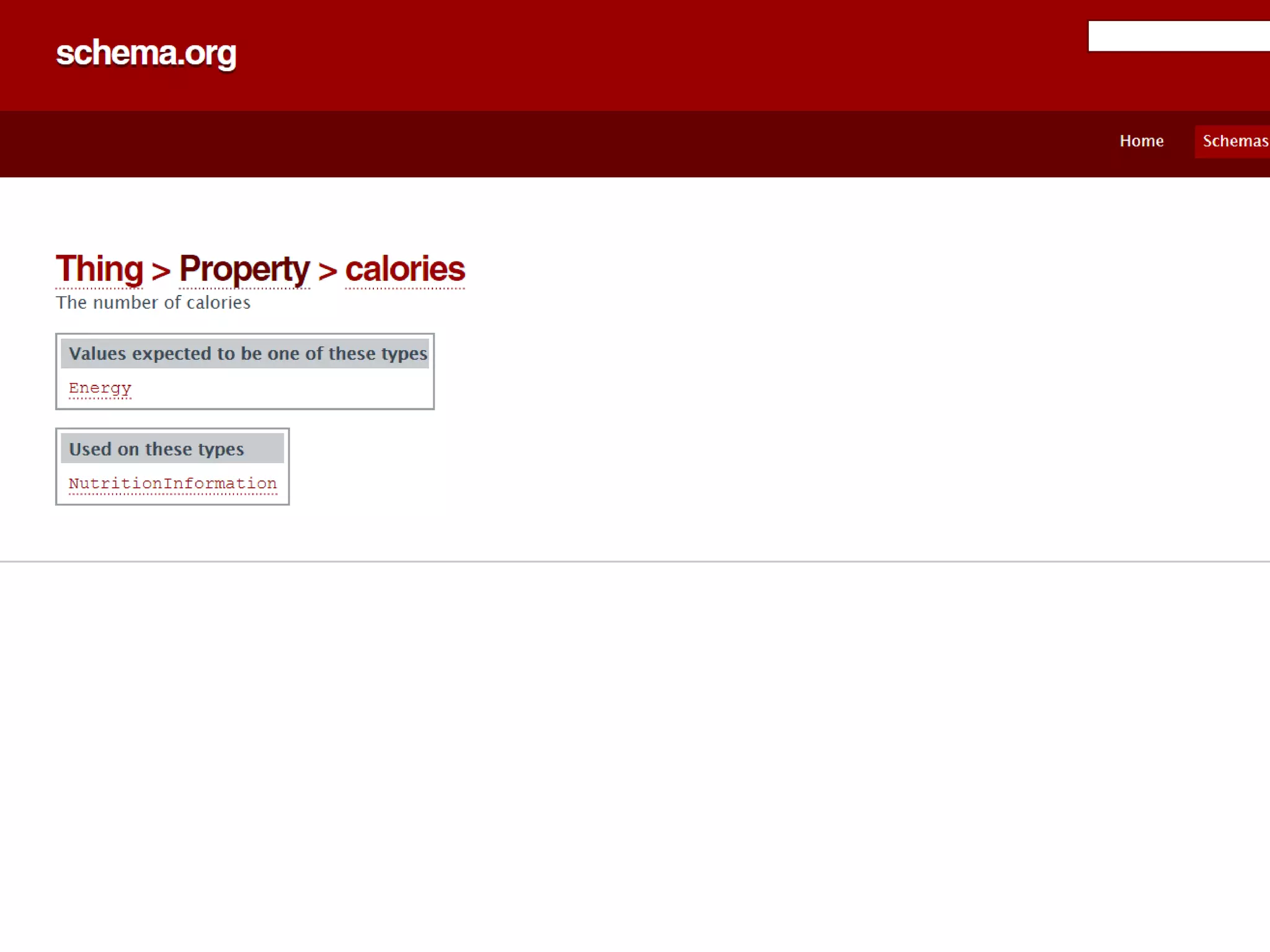
This document contains nutrition information for a food item containing 667 calories, 9g of protein and 49g of carbohydrates. It also includes JSON snippets defining schema.org contexts, types, classes and collections for representing recipes and collections of recipes.

























































