Downloaded 13 times









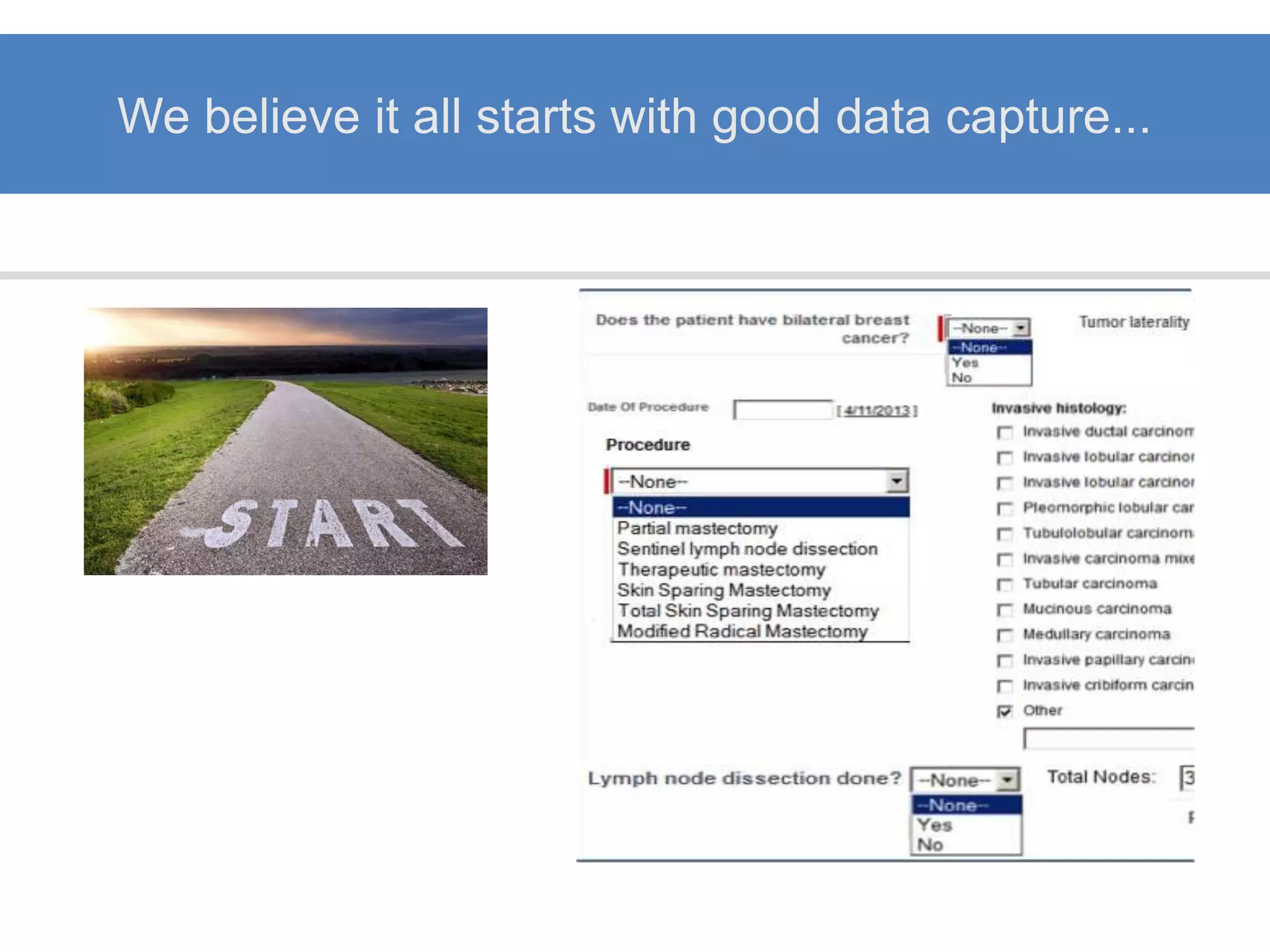

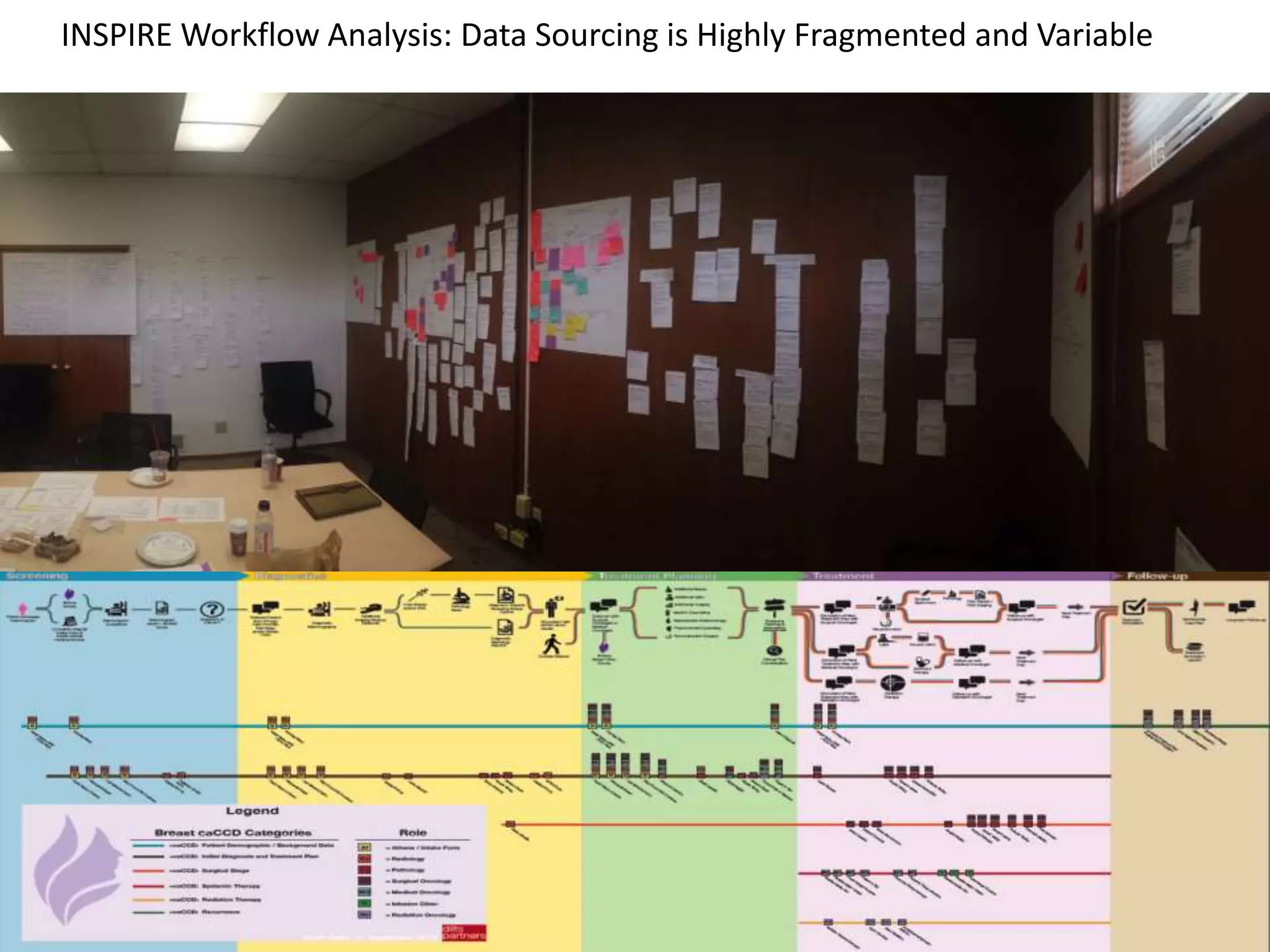

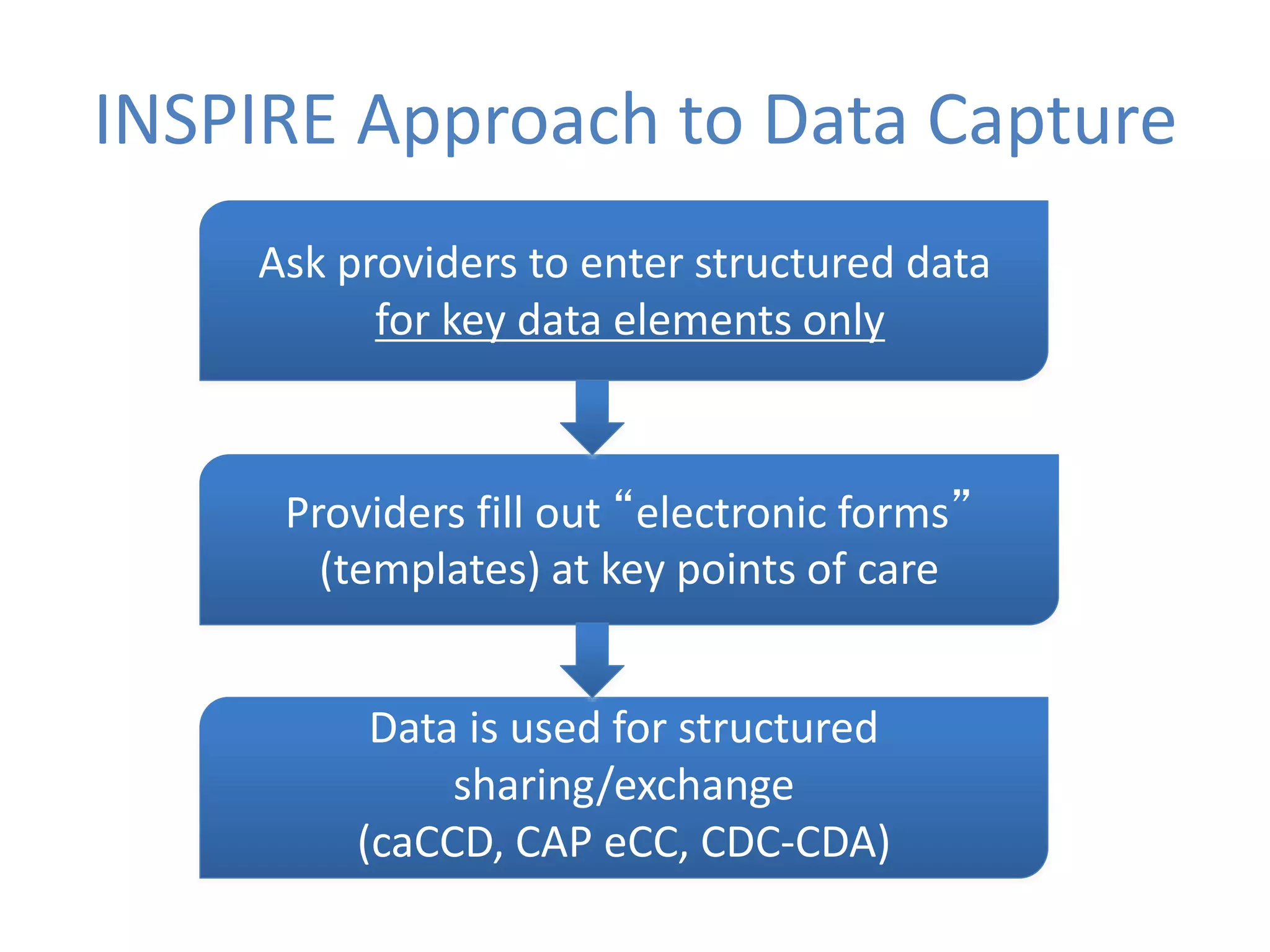
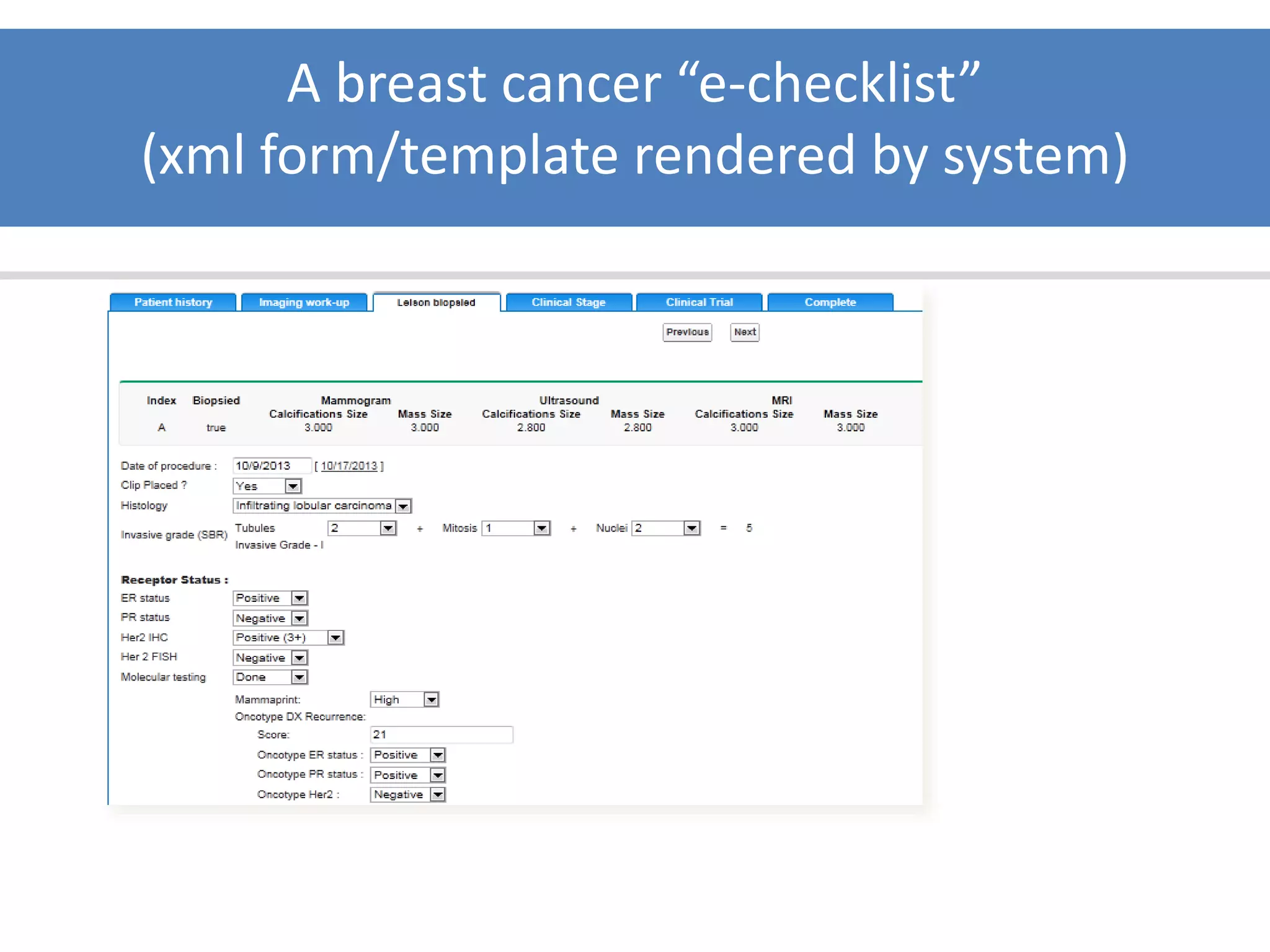

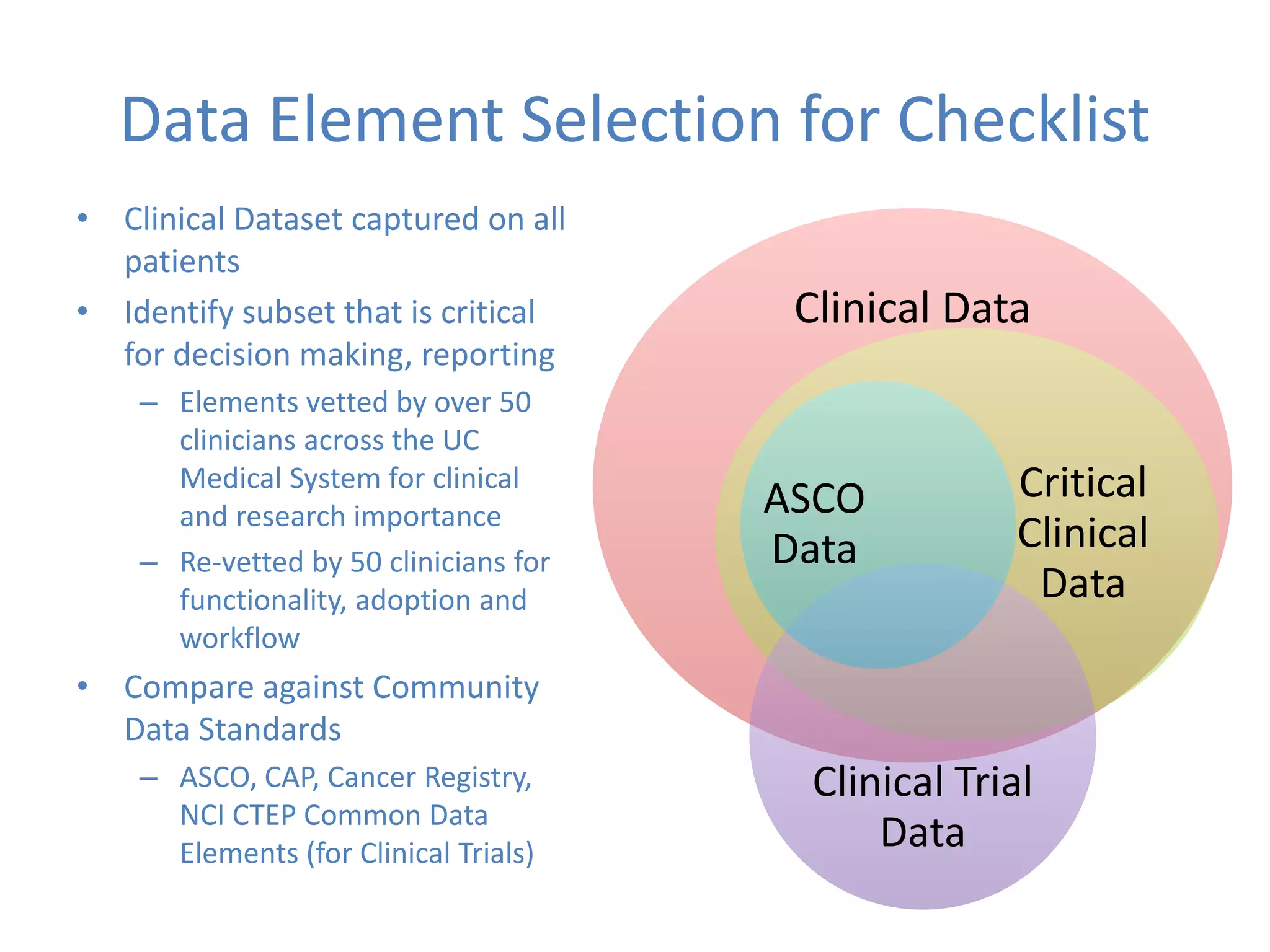
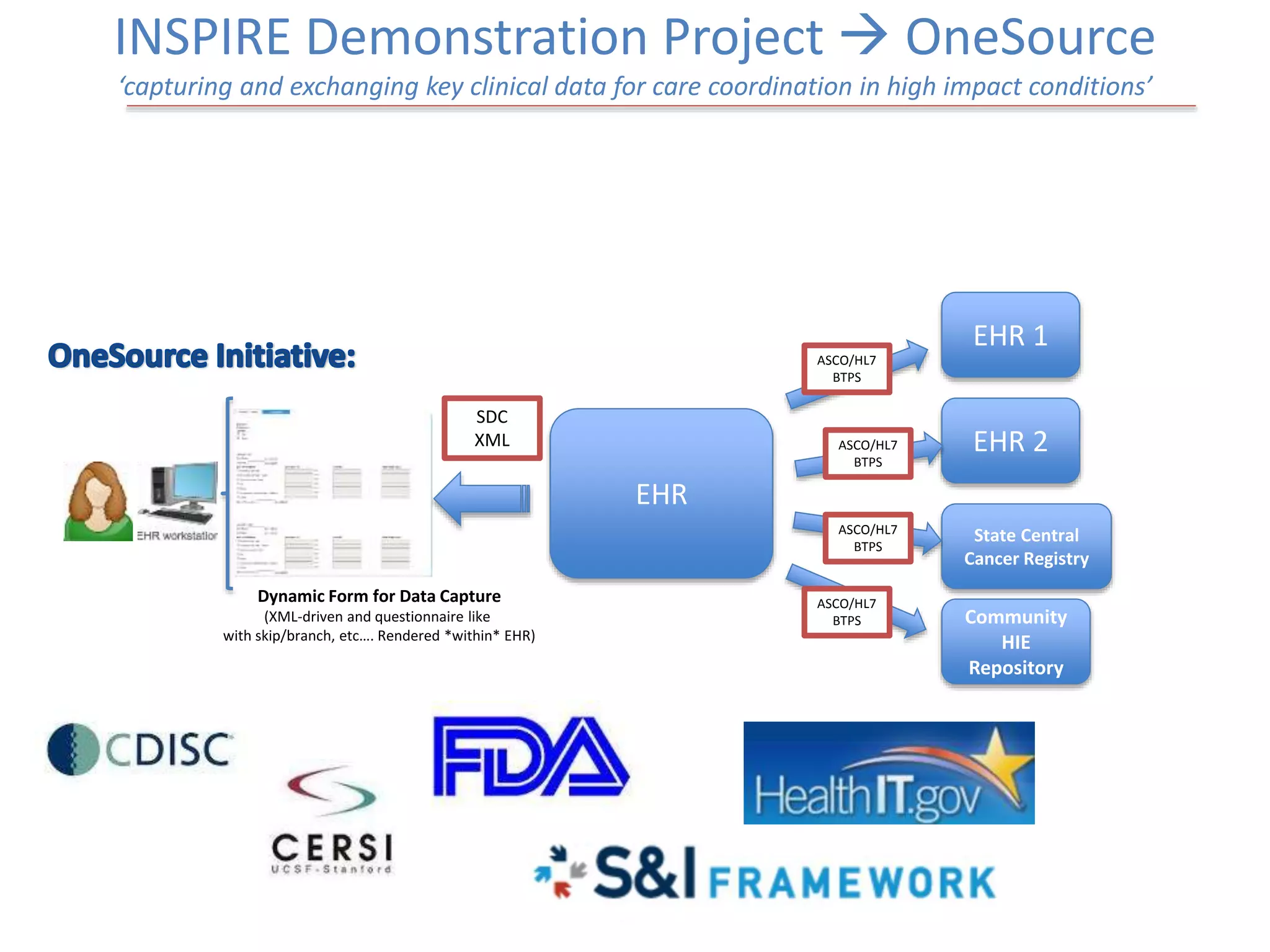
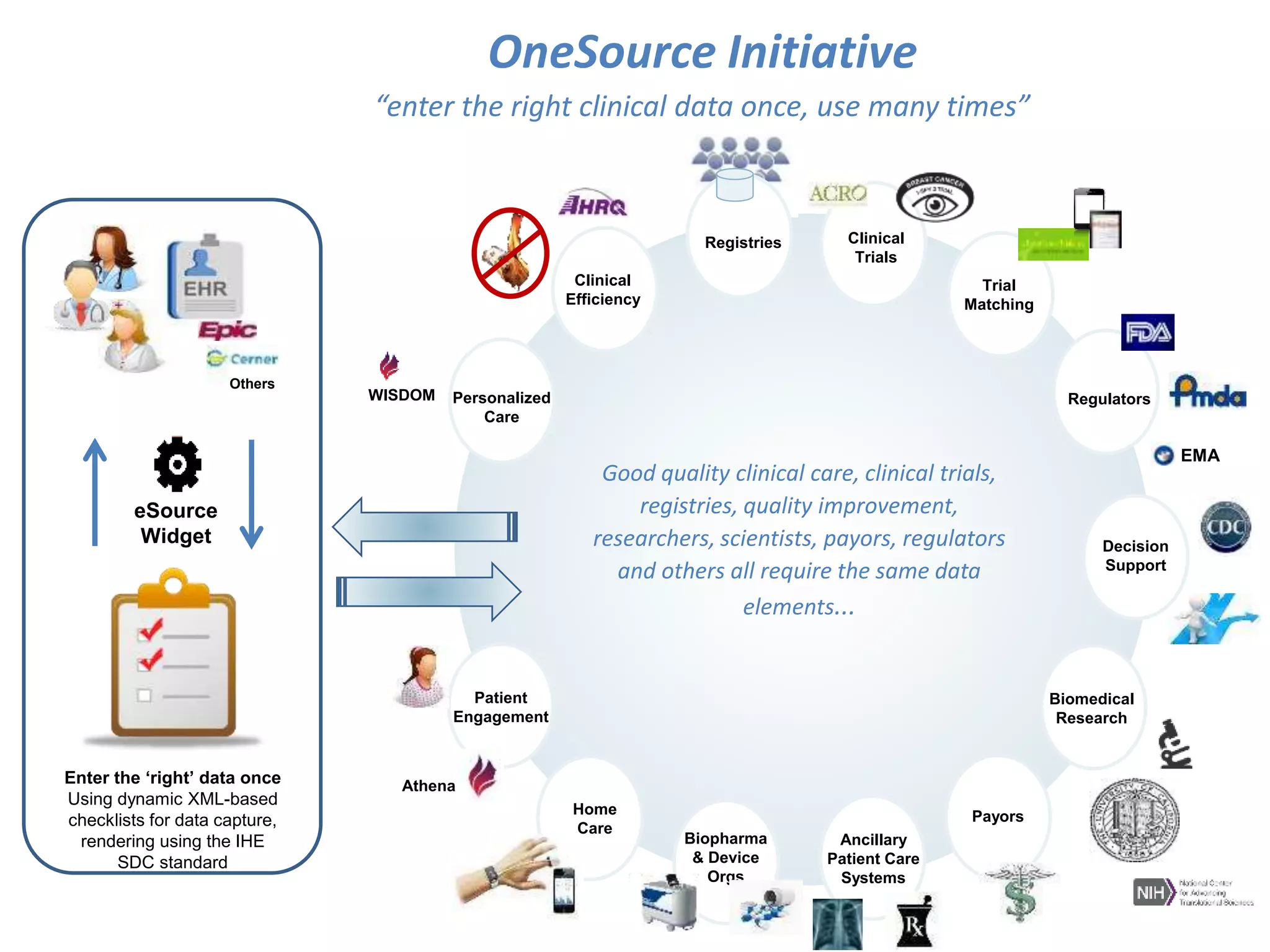

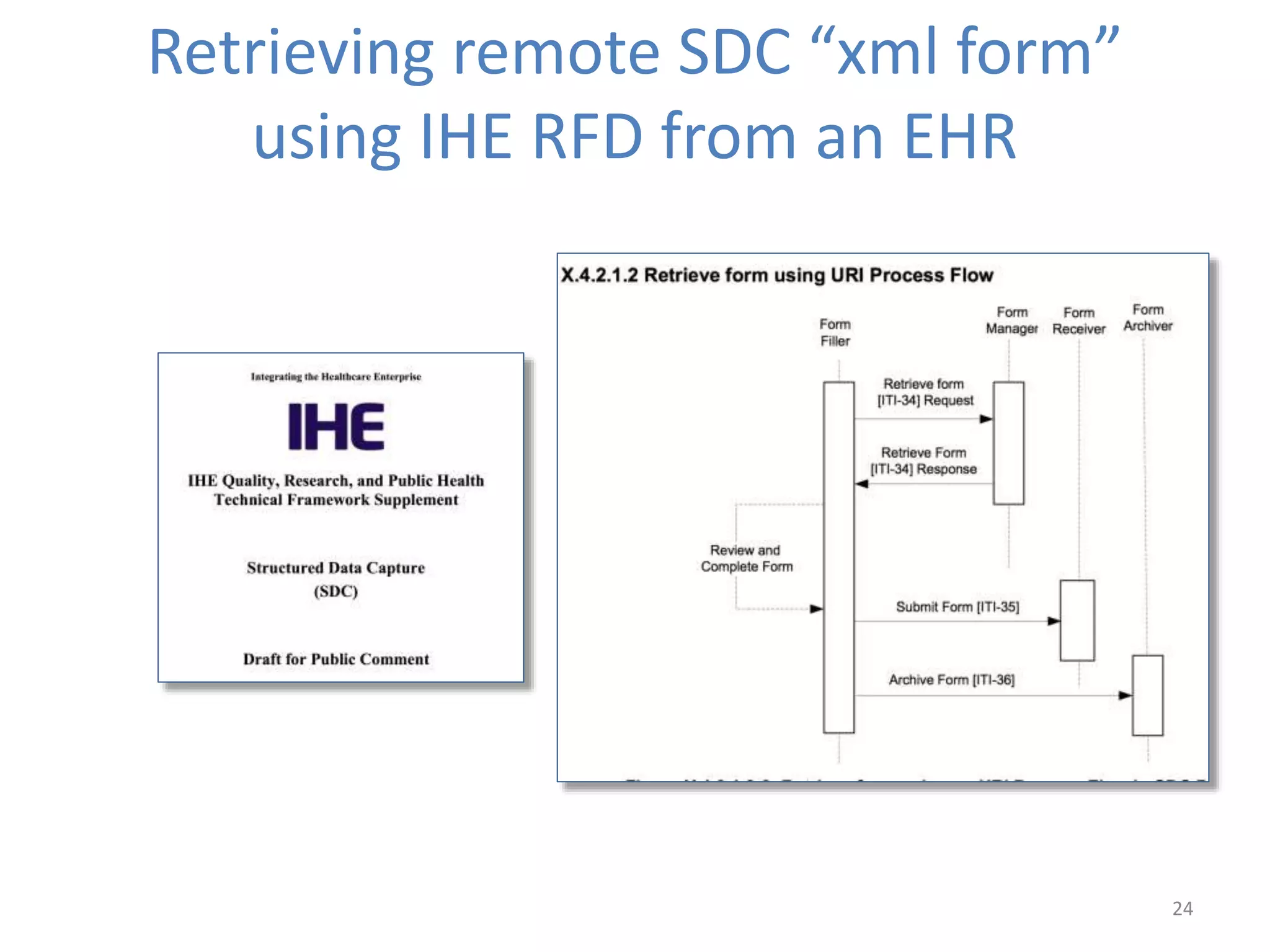
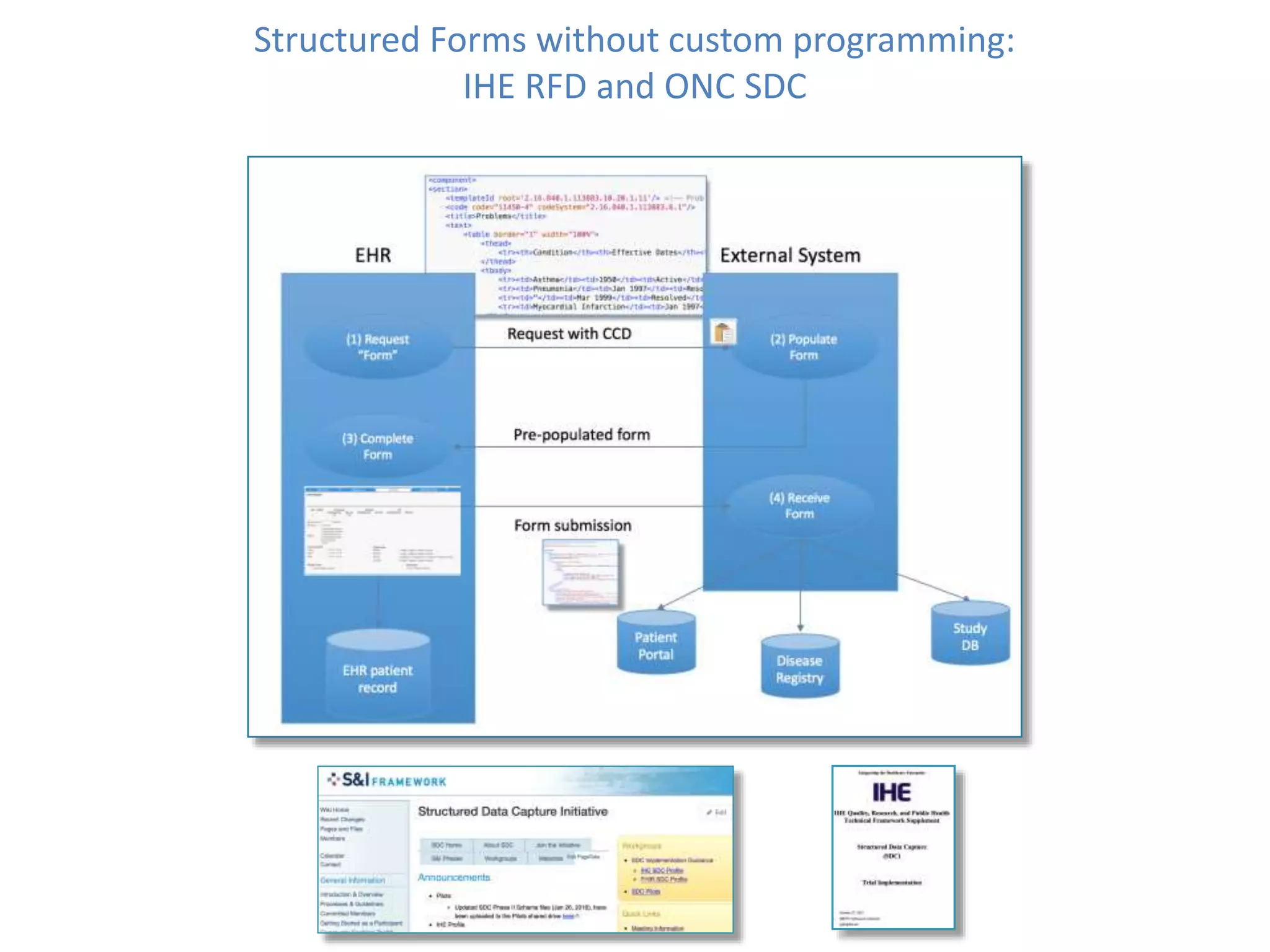











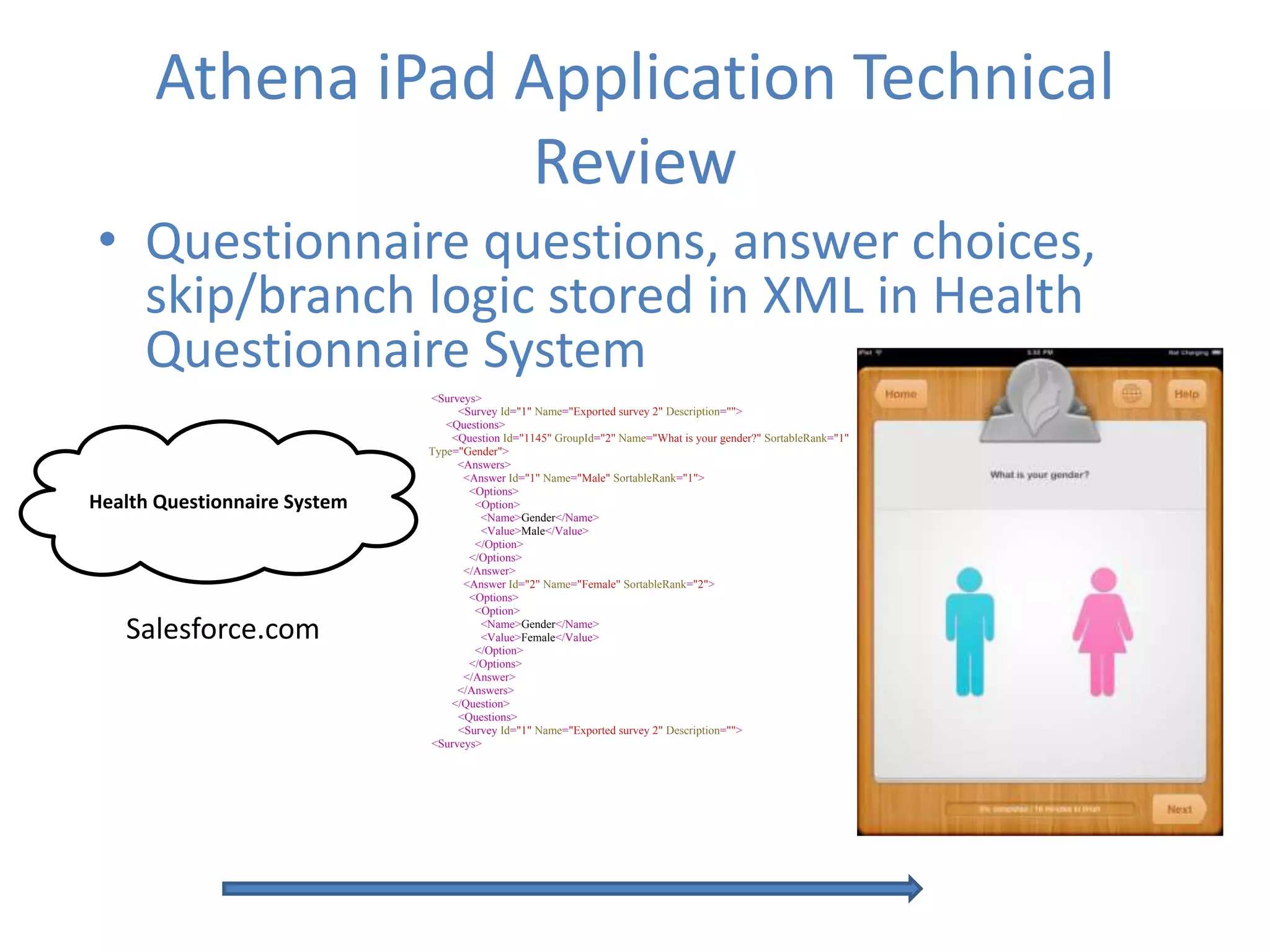

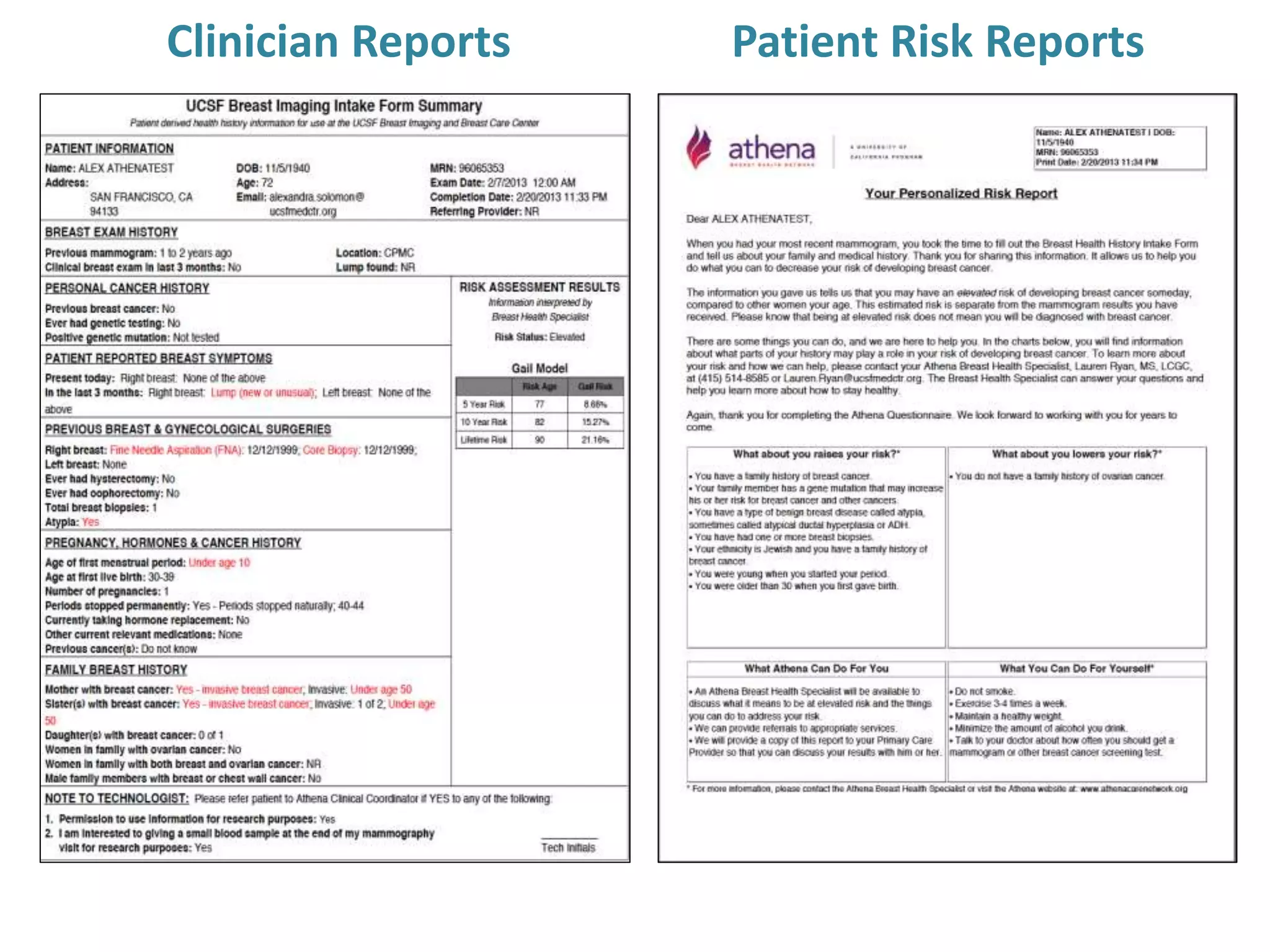
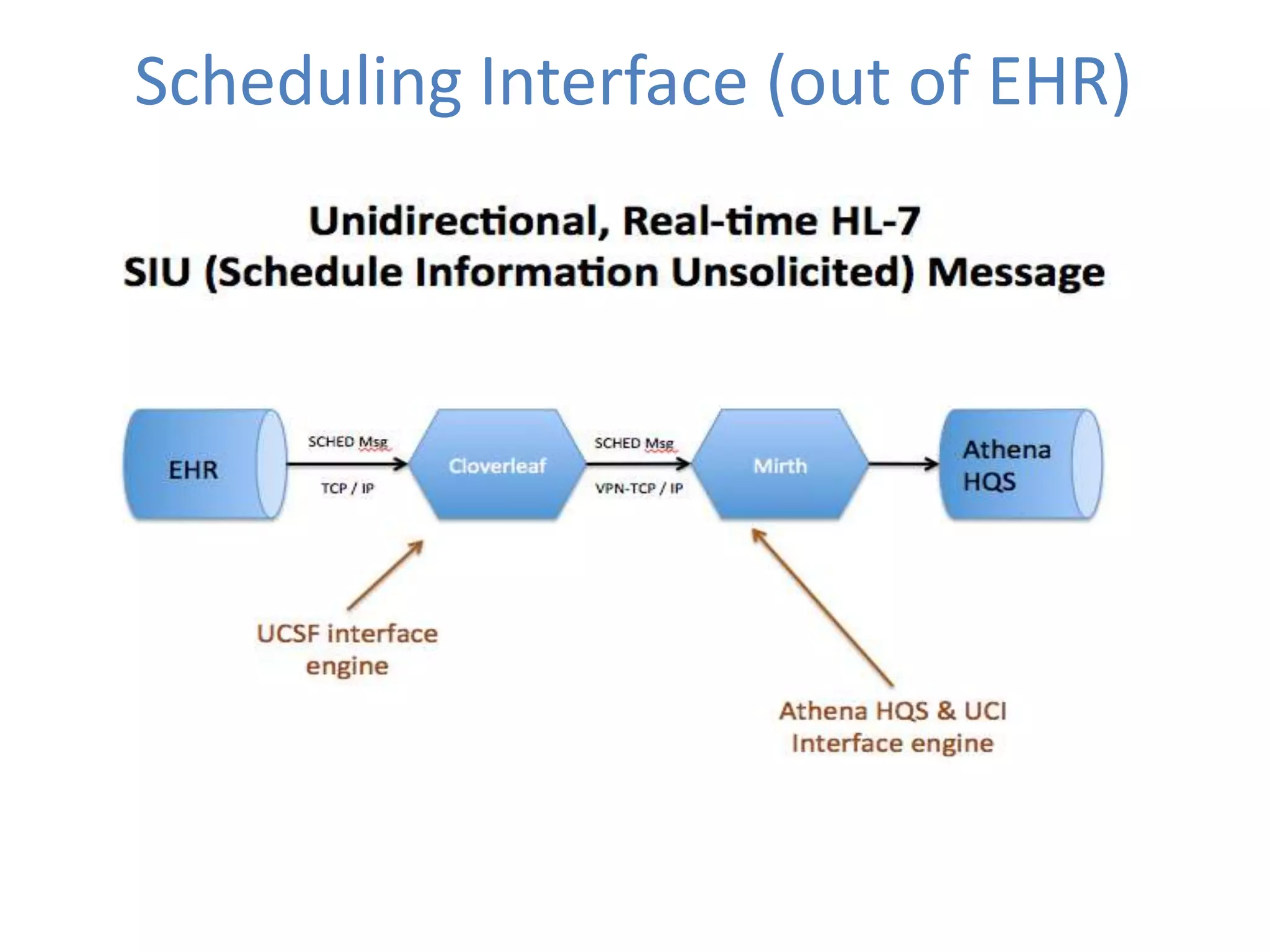
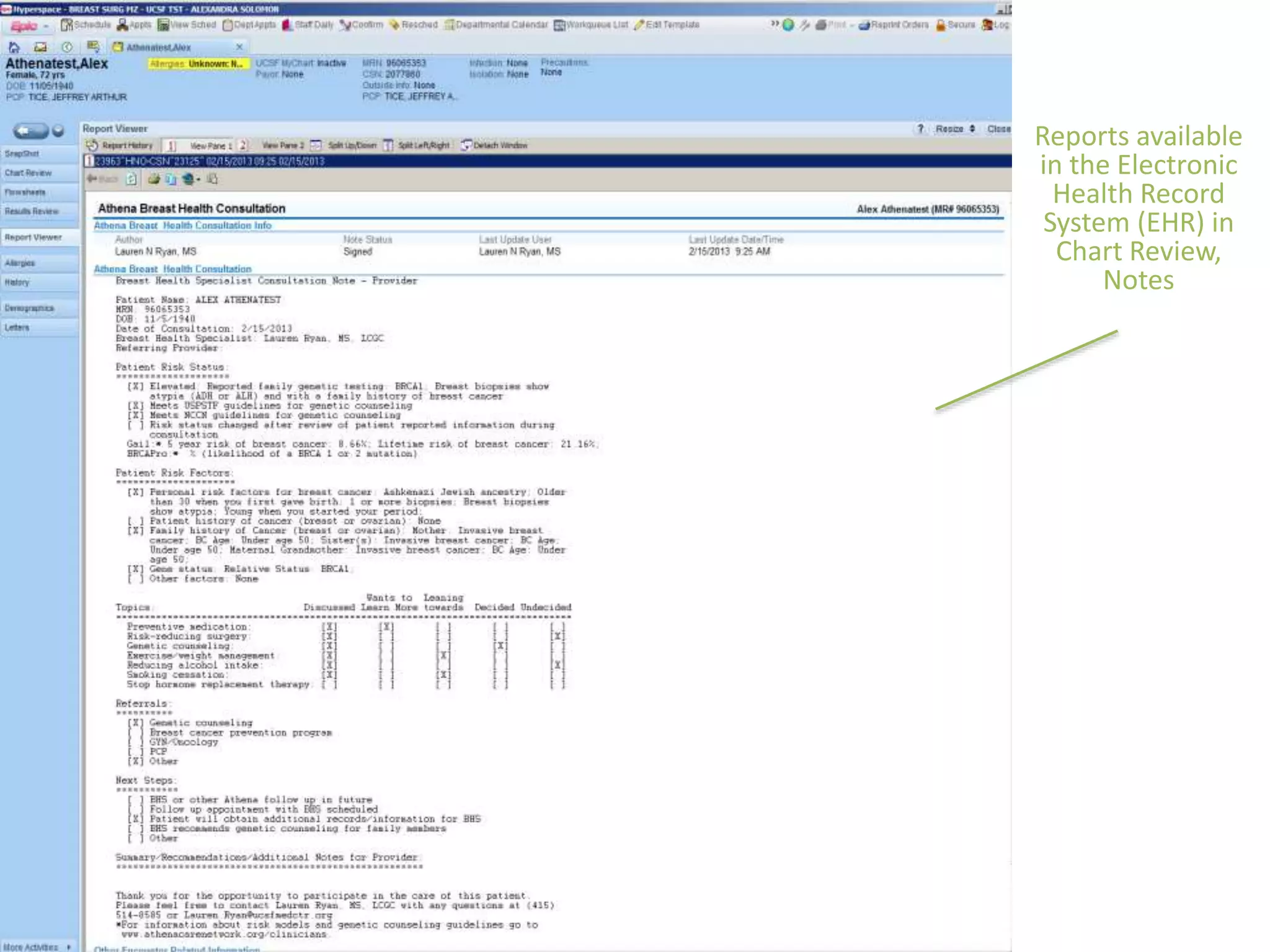
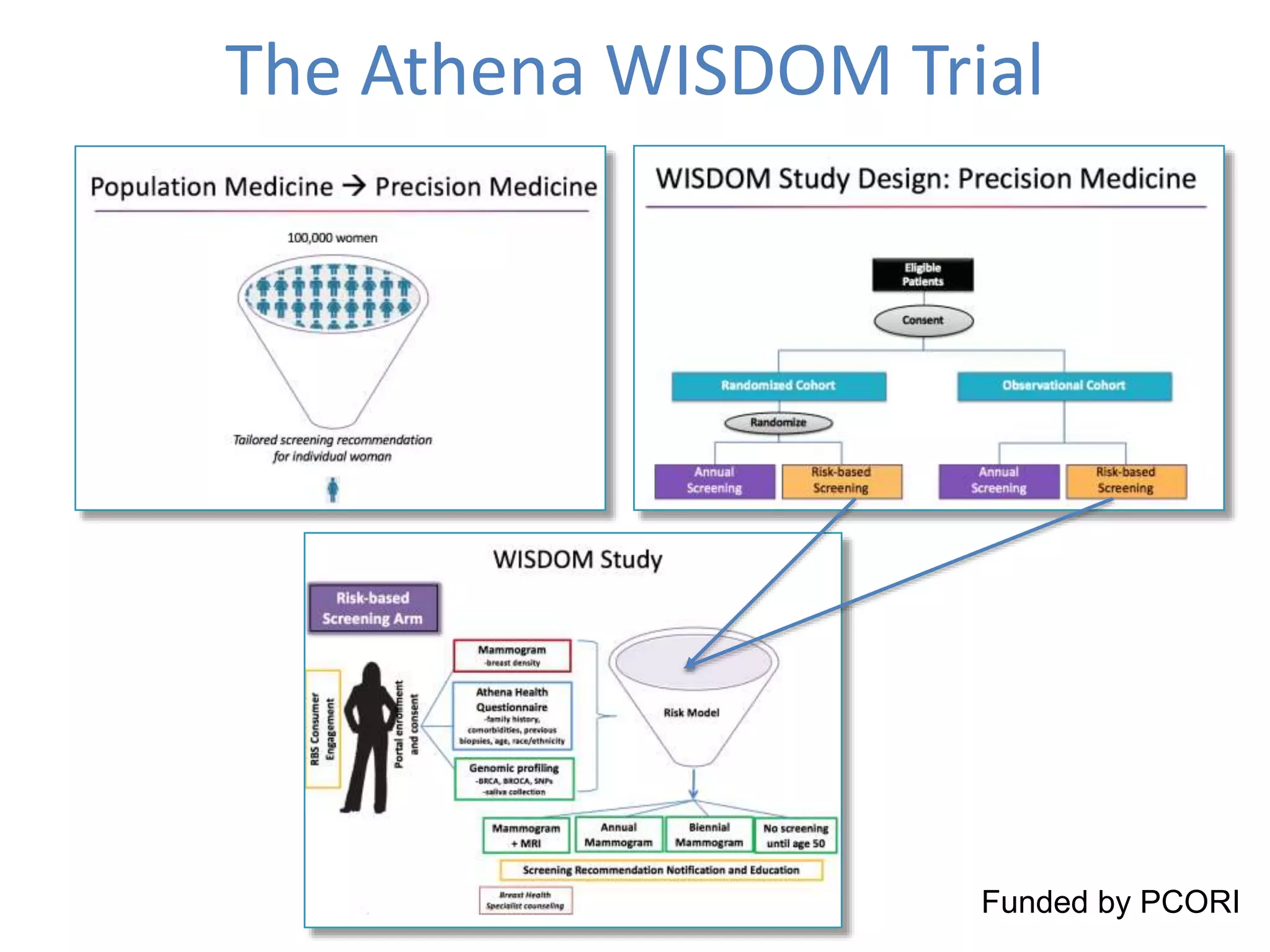
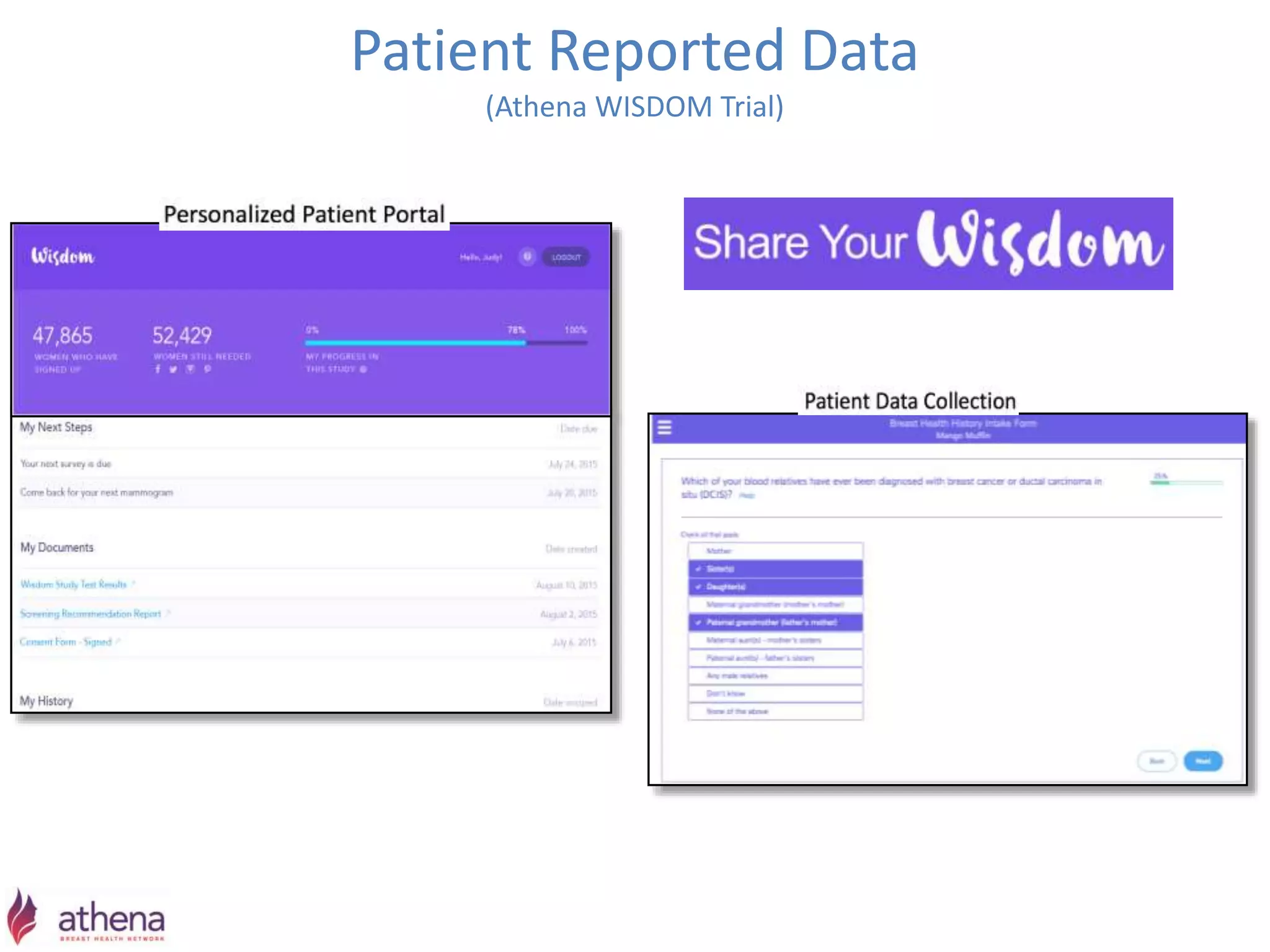



The Onesource Initiative aims to improve structured sourcing of key clinical data for personalized care, addressing challenges in data capture and documentation within electronic health records (EHRs). It advocates for a transformation in clinical documentation through the use of dynamic XML-based checklists to enhance data quality, streamline information retrieval, and support clinical decision-making. Inspired by trials demonstrating fragmented data workflows, the initiative emphasizes the importance of structured sharing for efficient care coordination and engaging patients in data reporting.


















































































