


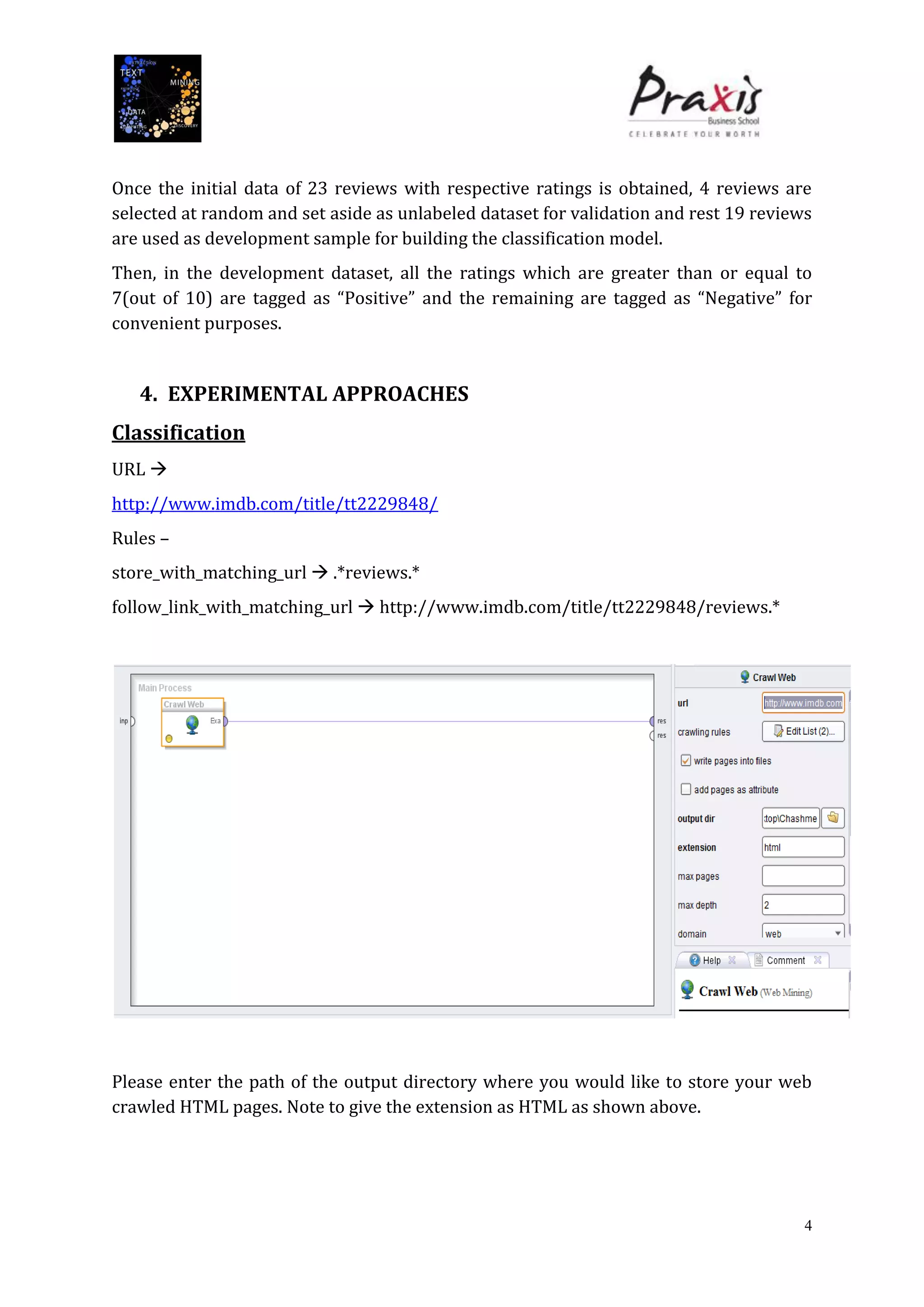
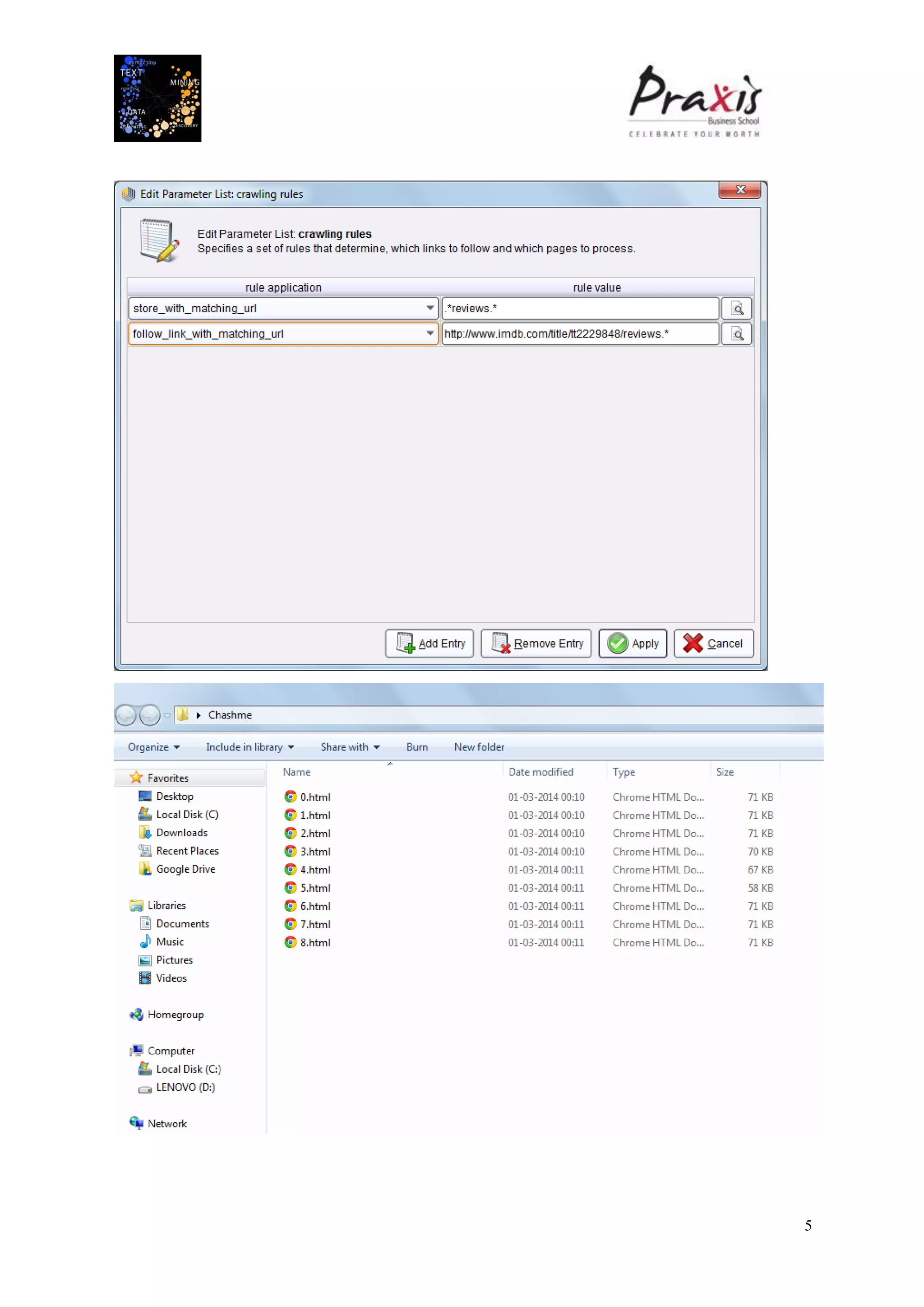
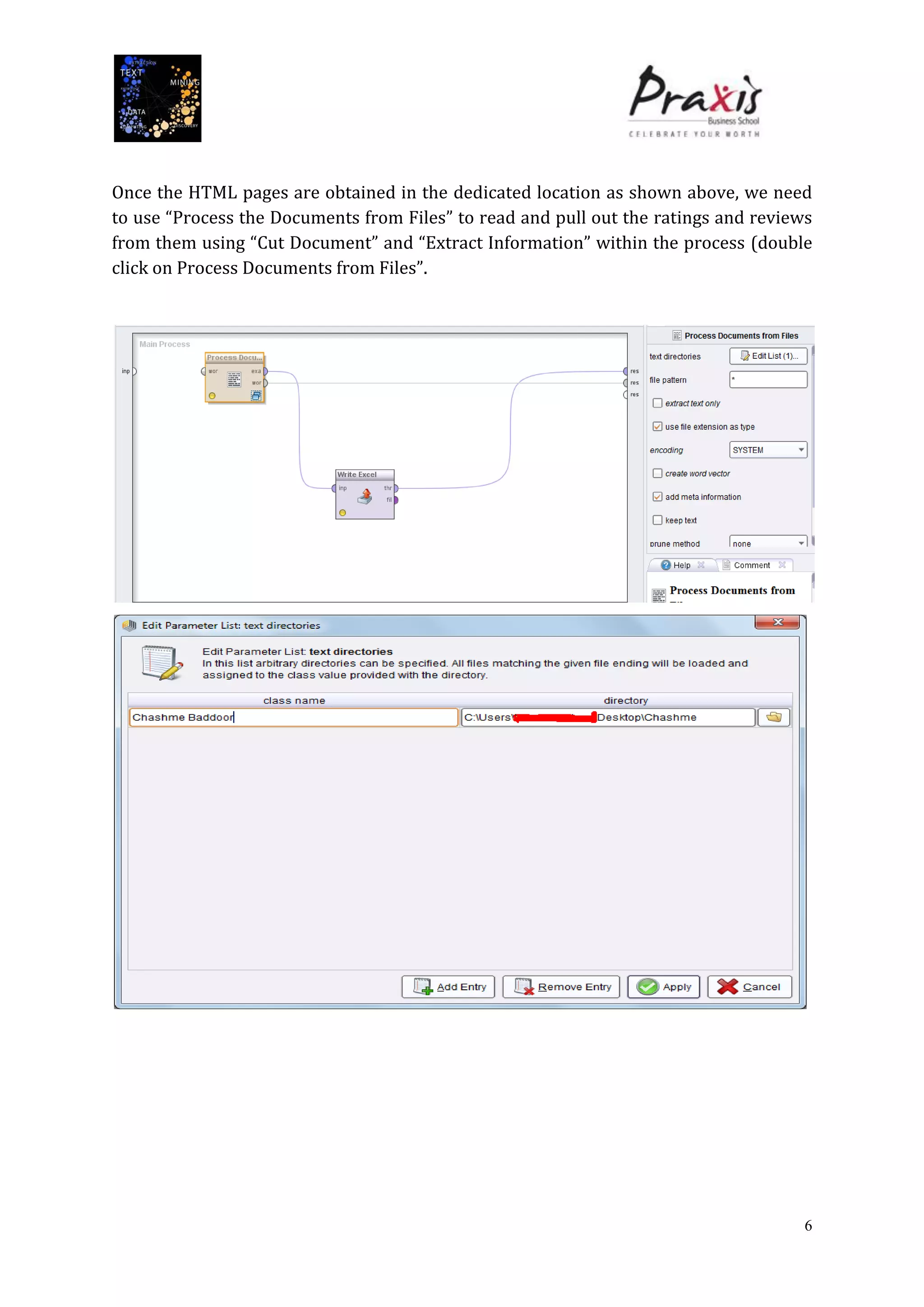
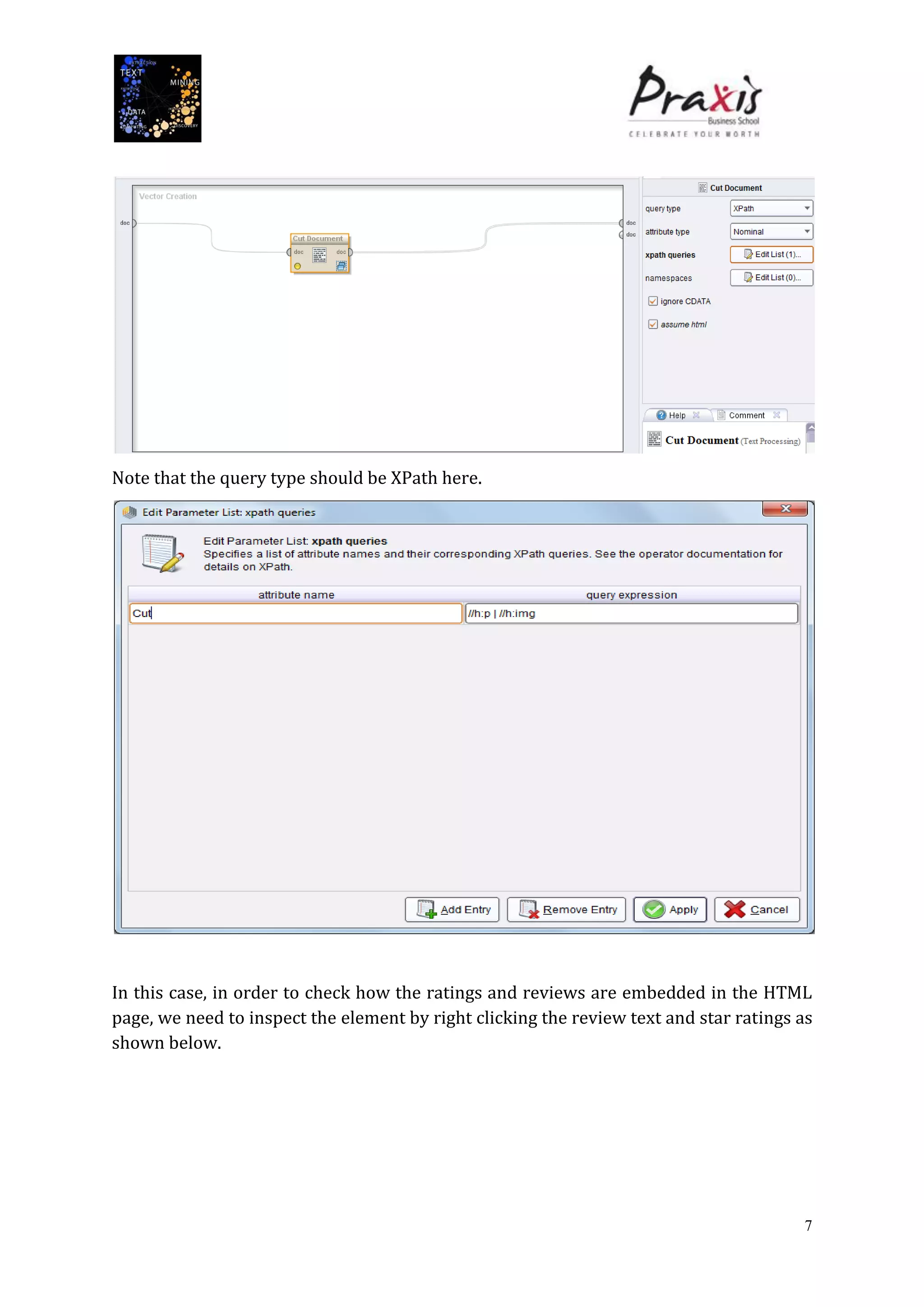
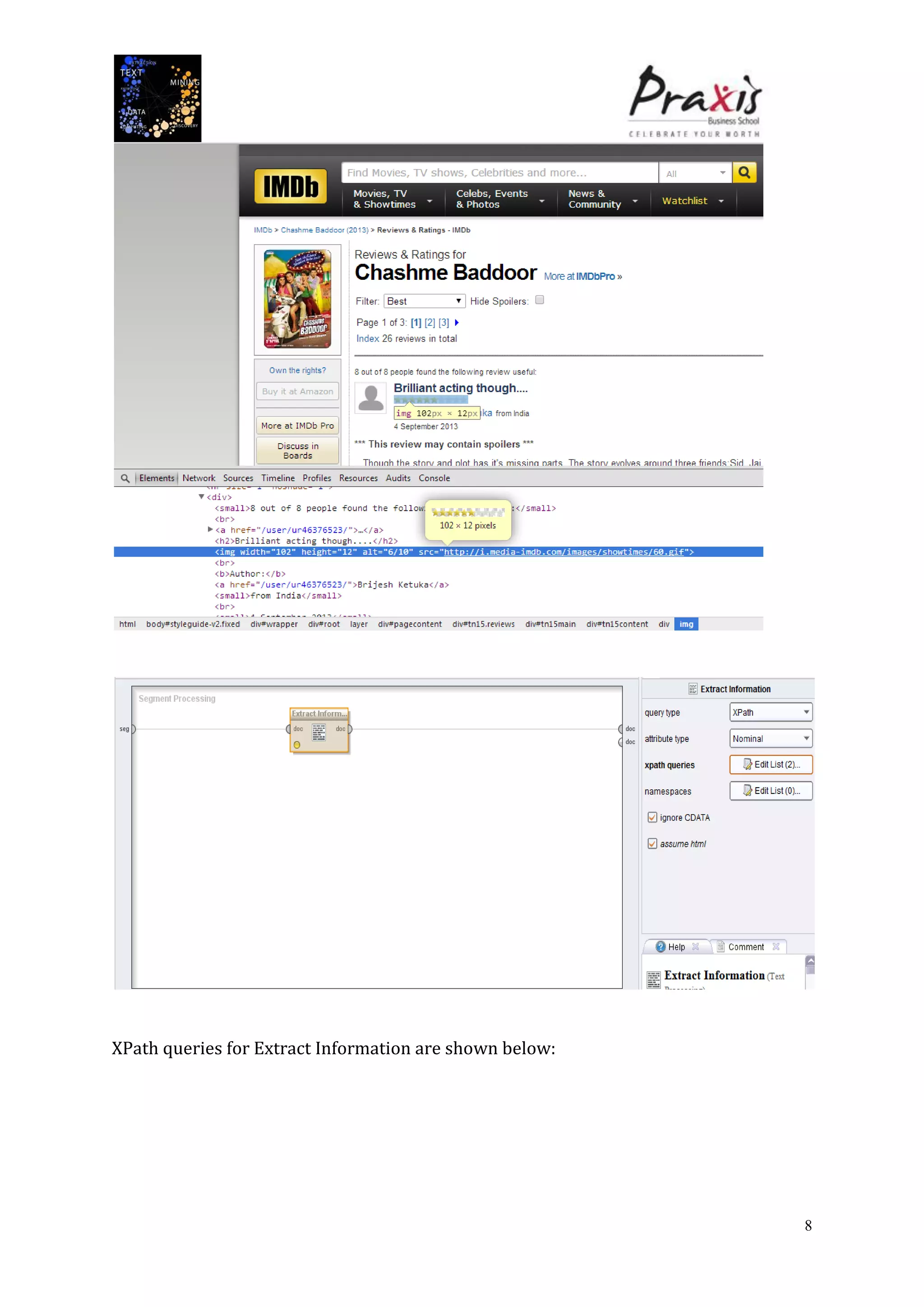
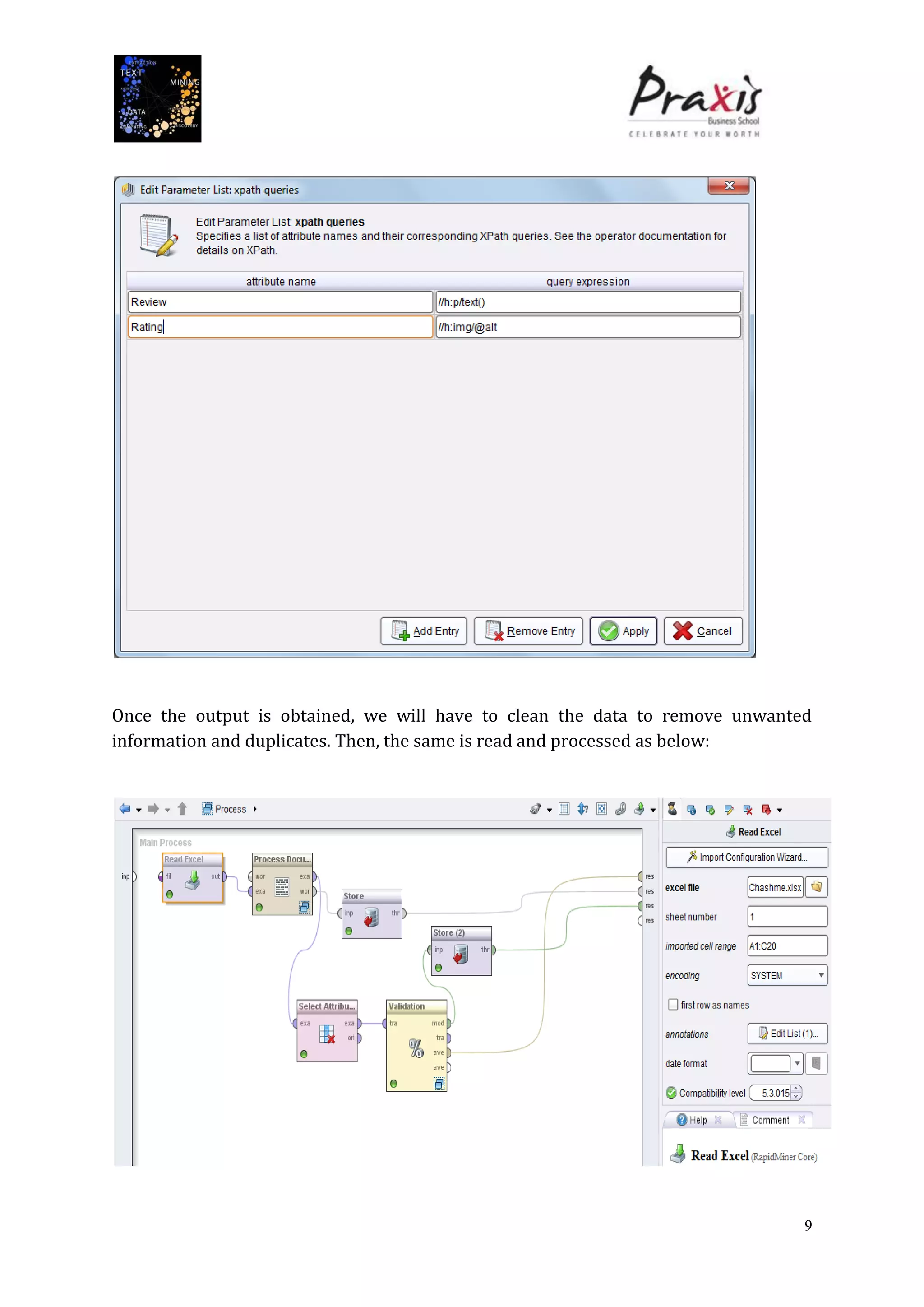
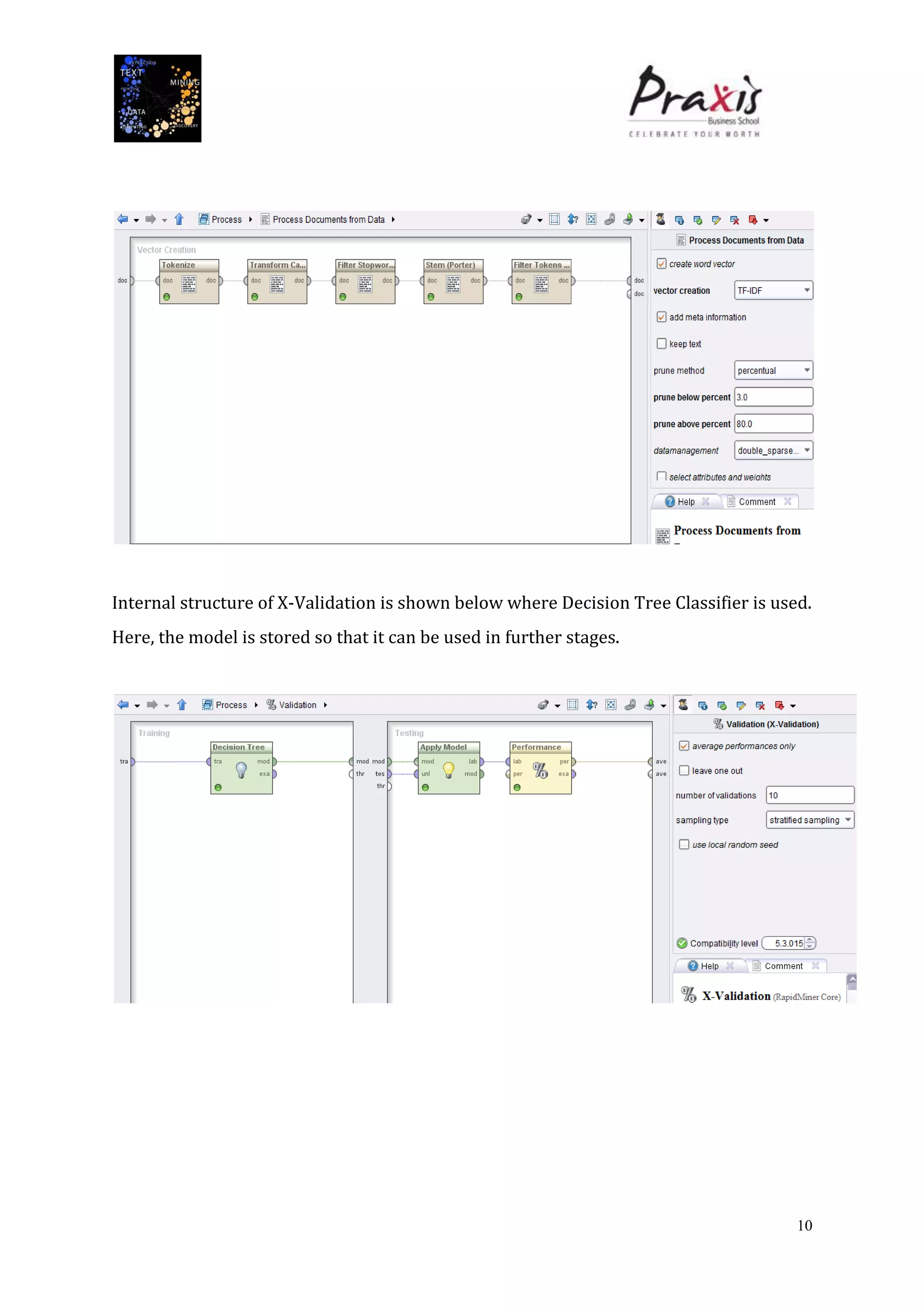
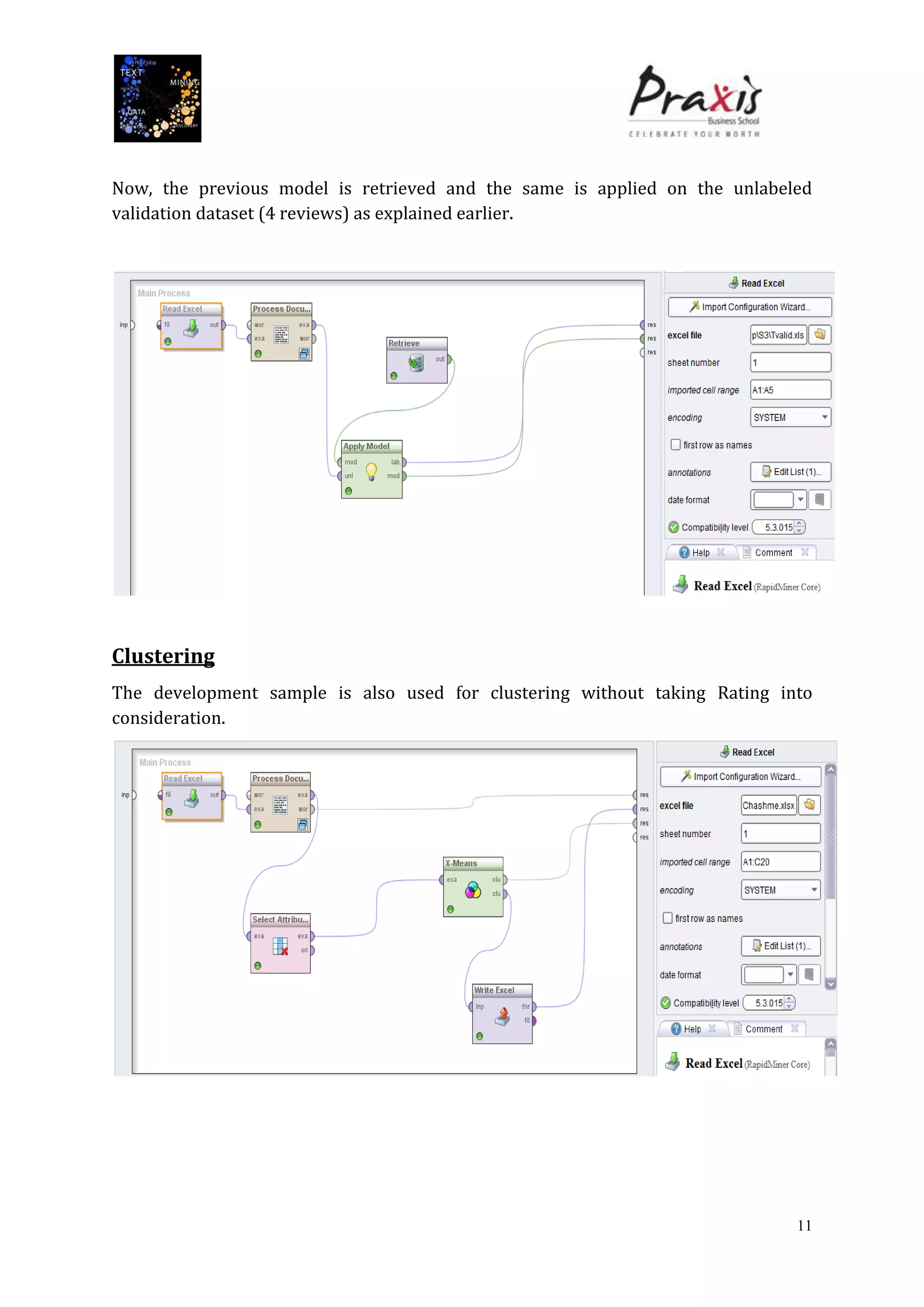
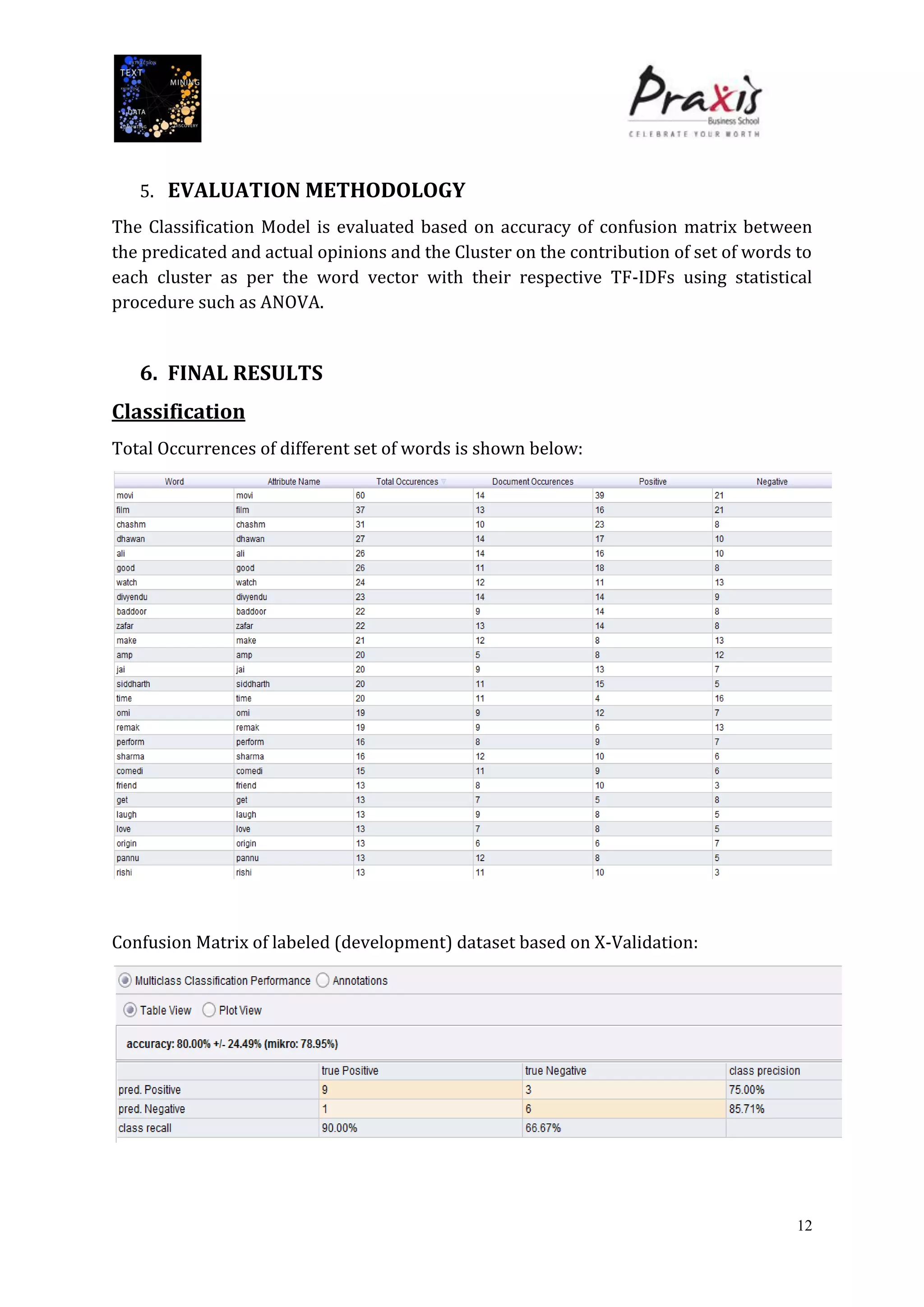
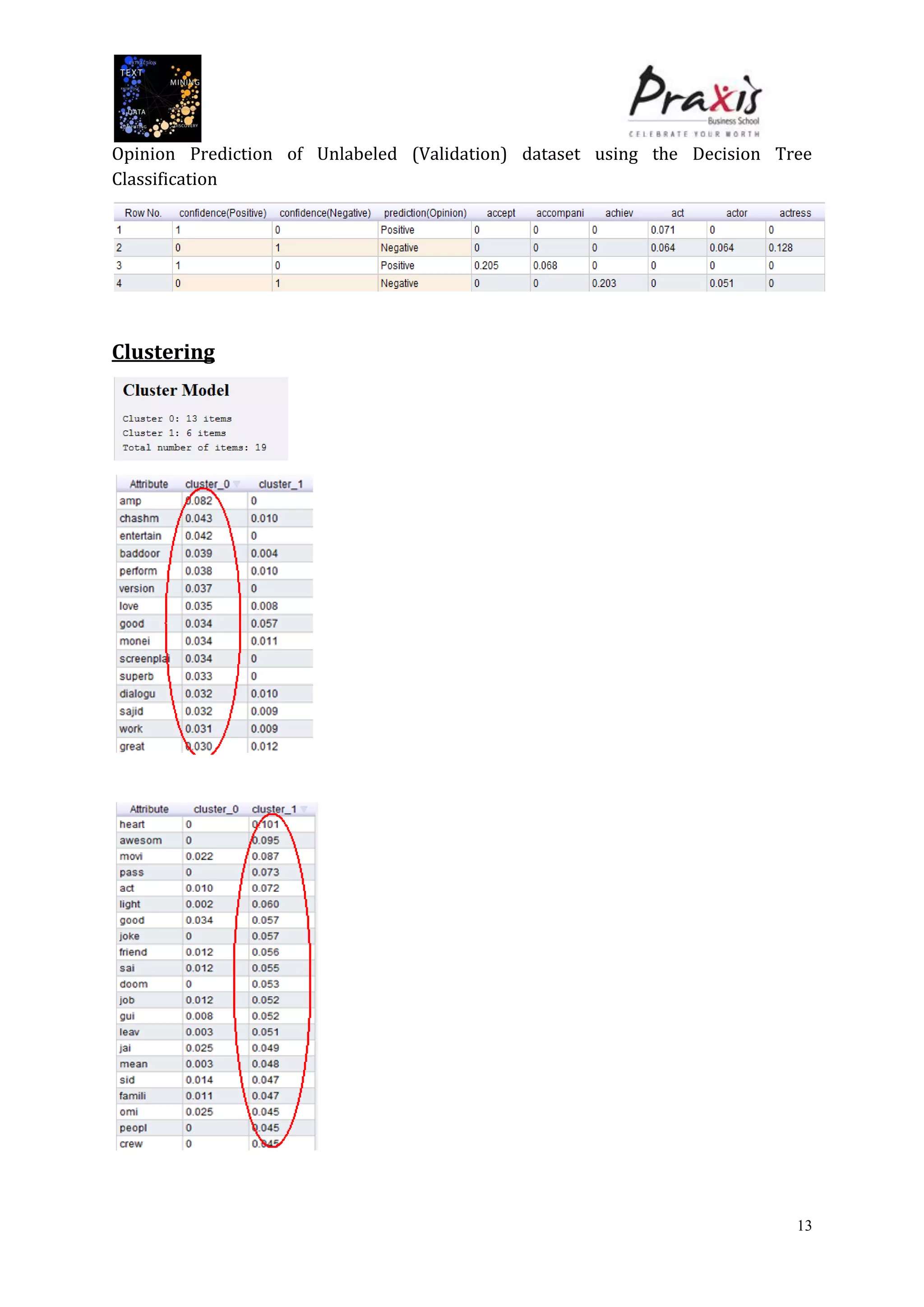


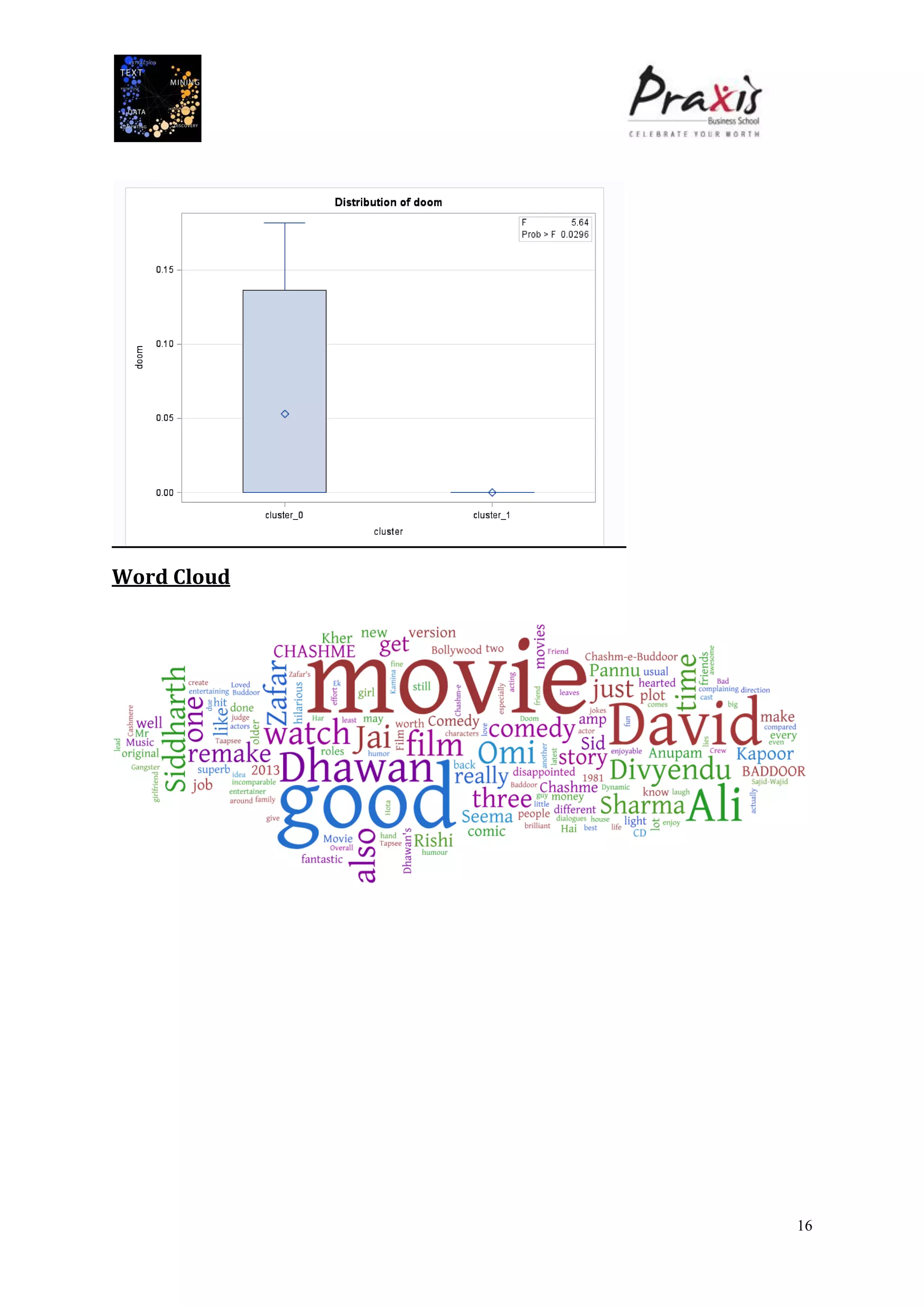

The document summarizes a project that performed text mining on reviews of the Bollywood movie "Chashme Baddoor" to classify reviews as positive or negative and cluster reviews into groups. Key steps included collecting 23 reviews from IMDb, building a decision tree classification model to predict review sentiment, applying the model to unlabeled reviews, and clustering reviews without ratings. The clusters revealed insights about the movie's plot, acting, music, and areas for improvement. Text mining provided useful audience feedback to consider for future films.










































































![[DSC Europe 25] Dragan Vucic - Building the Learning Organization - How AI Tr...](https://cdn.slidesharecdn.com/ss_thumbnails/8brigo2sbu6qur6gxrra-7-251205085715-6ae07d24-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Boris Perkovic - Lost in performance.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/uq5hrp7vsuahqkxzifux-1-251204082258-fd2ee09d-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)

