Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Kyota Yasuda
PPTX, PDF
12,346 views
Tensorflowで言語識別をやってみた
12/11、TensorFlowの勉強会で発表した資料
Engineering
◦
Read more
7
Save
Share
Embed
Embed presentation
Download
Downloaded 22 times
1
/ 13
2
/ 13
3
/ 13
4
/ 13
5
/ 13
6
/ 13
7
/ 13
8
/ 13
9
/ 13
10
/ 13
11
/ 13
12
/ 13
13
/ 13
More Related Content
PDF
TensorFlowをざっくりLTしてみた
by
Mitsuki Ogasahara
PDF
思いついたアルゴリズムを TensorFlow で実装してみた話
by
Shuhei Fujiwara
PDF
内省するTensorFlow
by
Yoshiyuki Kakihara
PDF
TensorFlowで遊んでみよう!
by
Kei Hirata
PDF
TensorFlowで逆強化学習
by
Mitsuhisa Ohta
PDF
TensorFlow 入門
by
Takenori Nakagawa
PDF
Chainerのテスト環境とDockerでのCUDAの利用
by
Yuya Unno
PDF
ピーFIの研究開発現場
by
Yuya Unno
TensorFlowをざっくりLTしてみた
by
Mitsuki Ogasahara
思いついたアルゴリズムを TensorFlow で実装してみた話
by
Shuhei Fujiwara
内省するTensorFlow
by
Yoshiyuki Kakihara
TensorFlowで遊んでみよう!
by
Kei Hirata
TensorFlowで逆強化学習
by
Mitsuhisa Ohta
TensorFlow 入門
by
Takenori Nakagawa
Chainerのテスト環境とDockerでのCUDAの利用
by
Yuya Unno
ピーFIの研究開発現場
by
Yuya Unno
What's hot
PDF
最先端NLP勉強会 “Learning Language Games through Interaction” Sida I. Wang, Percy L...
by
Yuya Unno
PDF
子供の言語獲得と機械の言語獲得
by
Yuya Unno
PDF
NIP2015読み会「End-To-End Memory Networks」
by
Yuya Unno
PPTX
Emnlp読み会資料
by
Jiro Nishitoba
PDF
tmu_science_cafe02
by
Tomoyuki Kajiwara
PDF
言語と知識の深層学習@認知科学会サマースクール
by
Yuya Unno
PDF
20150702文章読解支援のための日本語の語彙平易化システム
by
Tomoyuki Kajiwara
PDF
文章読解支援のための語彙平易化@第1回NLP東京Dの会
by
Tomoyuki Kajiwara
PDF
ゼロから始める自然言語処理 【FIT2016チュートリアル】
by
Yuki Arase
PDF
Tensor flow勉強会 (ayashiminagaranotensorflow)
by
tak9029
PDF
Facebookの人工知能アルゴリズム「memory networks」について調べてみた
by
株式会社メタップスホールディングス
PDF
joint_seminar
by
Tomoyuki Kajiwara
PPTX
AI入門「第1回:AIの歴史とTensorFlow」
by
fukuoka.ex
PDF
日本語の語彙平易化システムおよび評価セットの構築
by
Tomoyuki Kajiwara
PDF
2016tf study5
by
Shin Asakawa
PPTX
ニューラルチューリングマシン入門
by
naoto moriyama
PDF
開発者からみたTensor flow
by
Hideo Kinami
PDF
【FIT2016チュートリアル】ここから始める情報処理 ~音声編~ by 東工大・篠崎先生
by
Toshihiko Yamasaki
PPTX
Deep forest
by
naoto moriyama
最先端NLP勉強会 “Learning Language Games through Interaction” Sida I. Wang, Percy L...
by
Yuya Unno
子供の言語獲得と機械の言語獲得
by
Yuya Unno
NIP2015読み会「End-To-End Memory Networks」
by
Yuya Unno
Emnlp読み会資料
by
Jiro Nishitoba
tmu_science_cafe02
by
Tomoyuki Kajiwara
言語と知識の深層学習@認知科学会サマースクール
by
Yuya Unno
20150702文章読解支援のための日本語の語彙平易化システム
by
Tomoyuki Kajiwara
文章読解支援のための語彙平易化@第1回NLP東京Dの会
by
Tomoyuki Kajiwara
ゼロから始める自然言語処理 【FIT2016チュートリアル】
by
Yuki Arase
Tensor flow勉強会 (ayashiminagaranotensorflow)
by
tak9029
Facebookの人工知能アルゴリズム「memory networks」について調べてみた
by
株式会社メタップスホールディングス
joint_seminar
by
Tomoyuki Kajiwara
AI入門「第1回:AIの歴史とTensorFlow」
by
fukuoka.ex
日本語の語彙平易化システムおよび評価セットの構築
by
Tomoyuki Kajiwara
2016tf study5
by
Shin Asakawa
ニューラルチューリングマシン入門
by
naoto moriyama
開発者からみたTensor flow
by
Hideo Kinami
【FIT2016チュートリアル】ここから始める情報処理 ~音声編~ by 東工大・篠崎先生
by
Toshihiko Yamasaki
Deep forest
by
naoto moriyama
Tensorflowで言語識別をやってみた
1.
TensorFlowで言語識別を やってみた 2015/12/11@TensorFlow研究会 株式会社ビズリーチ 安田京太
2.
自己紹介 安田京太(@dasoran) ・株式会社ビズリーチ所属 ・新卒で今年の春に入社して現在インフラ担当 ・機械学習は(ほぼ)趣味ですこし
3.
やったこと ・英語、フランス語、スペイン語の文章を食わせて言語を当てさせる ・MNIST以外の簡単な学習タスクで挙動を確認したかった ・word単位で入力するのではなく、文字単位で入力した ・シンプルだと思ったのに見かけることがない ・それくらいの構造頑張って学習してほしい
4.
入力データ This is a
pen. ↓ 文字コード化 [0x54, 0x68, 0x69, 0x73, 0x20, 0x69, 0x73,0x20, 0x61, 0x20, 0x70, 0x65, 0x6e, 0x2e] ・400文字で文章を切って入力
5.
TensorFlow部分のコード x = tf.placeholder(tf.float32,
[None, n_input_node]) W = tf.Variable(tf.zeros([n_input_node, 3])) b = tf.Variable(tf.zeros([3])) y = tf.nn.softmax(tf.matmul(x, W) + b) y_ = tf.placeholder(tf.float32, [None, 3]) cross_entropy = -tf.reduce_sum(y_*tf.log(y)) train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy) init = tf.initialize_all_variables() correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float")) sess = tf.Session() sess.run(init) for i in range(100): perm = np.random.permutation(n_train) for i in range(0, n_train, batchsize): x_batch = np.asarray(x_train[perm[i:i + batchsize]]) y_batch = np.asarray(y_train[perm[i:i + batchsize]]) sess.run(train_step, feed_dict={x: x_batch, y_: y_batch}) print sess.run(accuracy, feed_dict={x: x_test, y_: y_test})
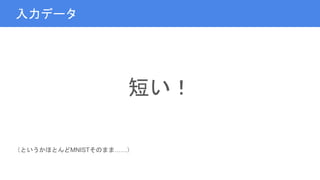
6.
入力データ 短い! (というかほとんどMNISTそのまま……)
7.
初心者的TensorFlowの勘所 ・定義してから実行する ・外部から値を入れたい変数をplaceholderで定義する ・placeholderで定義した値にsess.run(関数, feed_dict={値})で代入実行する
8.
初心者的TensorFlowの勘所 「y = 5x
+ 3」を計算してみる x = tf.placeholder(tf.float32, [None, 1]) y = 5 * x + 3 init = tf.initialize_all_variables() sess = tf.Session() sess.run(init) print sess.run(y, feed_dict={x: [[10], [3]]})
9.
話を戻して
10.
言語認識の結果 正答率:0.416 ほとんど識別できてない やはりword単位でないとだめなのか・・・
11.
文字だけでなんとかする努力 ・入力文字を数値ではなく256次元の1,0のベクトルにしてみた T ↓ 文字コード化 [0x54] ↓ ベクトル化 [0,
0, 0, …, 0, 0, 1, 0, 0, ….0]
12.
努力の結果 正答率:0.843 学習してると言えるくらいになった! データが分散していないと学習がうまくできない事があるらしい。
13.
まとめ ・TensorFlowは簡単! ・学習タスクは入力データの形式が大事
Download





![入力データ
This is a pen.
↓ 文字コード化
[0x54, 0x68, 0x69, 0x73, 0x20, 0x69, 0x73,0x20, 0x61, 0x20, 0x70, 0x65, 0x6e, 0x2e]
・400文字で文章を切って入力](https://image.slidesharecdn.com/whcuper3tu6kghlhkk2f-signature-a35f4e8364a814ed8e355366c11fac0941bc4107f20658d85ec0fb402e725d1a-poli-151211112053/85/Tensorflow-4-320.jpg)
![TensorFlow部分のコード
x = tf.placeholder(tf.float32, [None, n_input_node])
W = tf.Variable(tf.zeros([n_input_node, 3]))
b = tf.Variable(tf.zeros([3]))
y = tf.nn.softmax(tf.matmul(x, W) + b)
y_ = tf.placeholder(tf.float32, [None, 3])
cross_entropy = -tf.reduce_sum(y_*tf.log(y))
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)
init = tf.initialize_all_variables()
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
sess = tf.Session()
sess.run(init)
for i in range(100):
perm = np.random.permutation(n_train)
for i in range(0, n_train, batchsize):
x_batch = np.asarray(x_train[perm[i:i + batchsize]])
y_batch = np.asarray(y_train[perm[i:i + batchsize]])
sess.run(train_step, feed_dict={x: x_batch, y_: y_batch})
print sess.run(accuracy, feed_dict={x: x_test, y_: y_test})](https://image.slidesharecdn.com/whcuper3tu6kghlhkk2f-signature-a35f4e8364a814ed8e355366c11fac0941bc4107f20658d85ec0fb402e725d1a-poli-151211112053/85/Tensorflow-5-320.jpg)

![初心者的TensorFlowの勘所
「y = 5x + 3」を計算してみる
x = tf.placeholder(tf.float32, [None, 1])
y = 5 * x + 3
init = tf.initialize_all_variables()
sess = tf.Session()
sess.run(init)
print sess.run(y, feed_dict={x: [[10], [3]]})](https://image.slidesharecdn.com/whcuper3tu6kghlhkk2f-signature-a35f4e8364a814ed8e355366c11fac0941bc4107f20658d85ec0fb402e725d1a-poli-151211112053/85/Tensorflow-8-320.jpg)

![文字だけでなんとかする努力
・入力文字を数値ではなく256次元の1,0のベクトルにしてみた
T
↓ 文字コード化
[0x54]
↓ ベクトル化
[0, 0, 0, …, 0, 0, 1, 0, 0, ….0]](https://image.slidesharecdn.com/whcuper3tu6kghlhkk2f-signature-a35f4e8364a814ed8e355366c11fac0941bc4107f20658d85ec0fb402e725d1a-poli-151211112053/85/Tensorflow-11-320.jpg)




























