Download as PDF, PPTX





















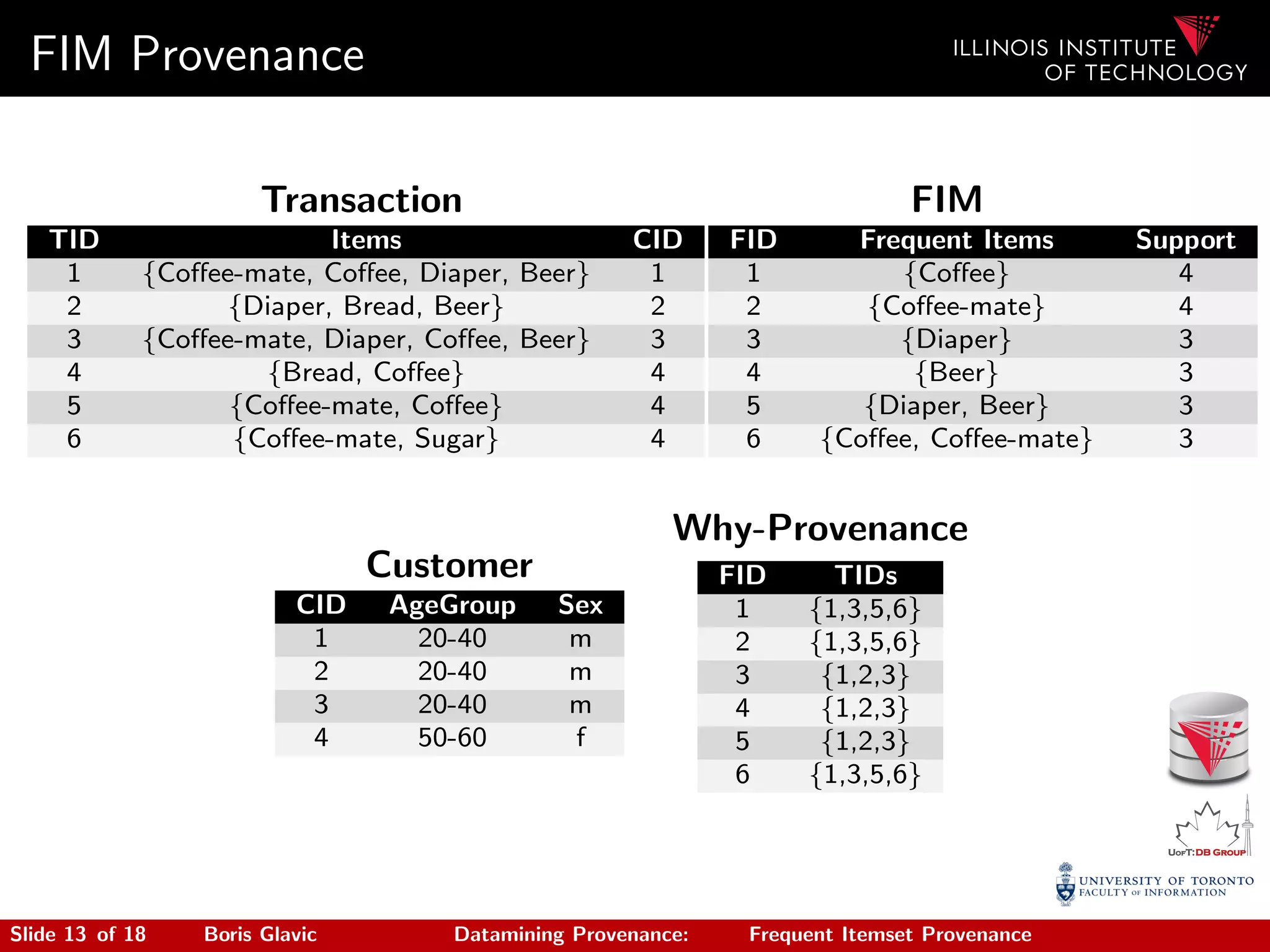














The document discusses the importance of provenance in data mining, emphasizing its role in understanding how data inputs influence mining results. It highlights challenges like reducing provenance size and managing context to improve interpretability of mining algorithms through case studies on frequent itemset mining and multidimensional scaling. The findings suggest that data mining can significantly benefit from an integrated approach to provenance that helps in contextualizing and tracing results back to their input origins.
































































