
Recommended
More Related Content
Similar to Survival report of 76 breast cancer patients under three different treatments
Similar to Survival report of 76 breast cancer patients under three different treatments (20)
Recently uploaded
Recently uploaded (20)
Survival report of 76 breast cancer patients under three different treatments
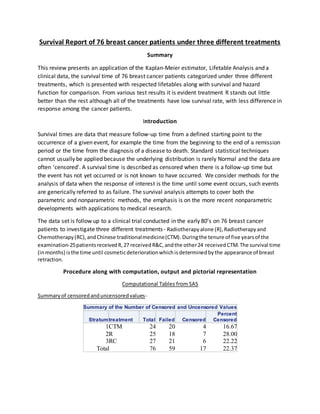
- 1. Survival Report of 76 breast cancer patients under three different treatments Summary This review presents an application of the Kaplan-Meier estimator, Lifetable Analysis and a clinical data, the survival time of 76 breast cancer patients categorized under three different treatments, which is presented with respected lifetables along with survival and hazard function for comparison. From various test results it is evident treatment R stands out little better than the rest although all of the treatments have low survival rate, with less difference in response among the cancer patients. Introduction Survival times are data that measure follow-up time from a defined starting point to the occurrence of a given event, for example the time from the beginning to the end of a remission period or the time from the diagnosis of a disease to death. Standard statistical techniques cannot usually be applied because the underlying distribution is rarely Normal and the data are often 'censored'. A survival time is described as censored when there is a follow-up time but the event has not yet occurred or is not known to have occurred. We consider methods for the analysis of data when the response of interest is the time until some event occurs, such events are generically referred to as failure. The survival analysis attempts to cover both the parametric and nonparametric methods, the emphasis is on the more recent nonparametric developments with applications to medical research. The data set is follow up to a clinical trial conducted in the early 80’s on 76 breast cancer patients to investigate three different treatments- Radiotherapyalone (R),Radiotherapyand Chemotherapy(RC),andChinese traditionalmedicine(CTM). Duringthe tenure of five yearsof the examination-25patientsreceivedR,27 receivedR&C,andthe other24 receivedCTM.The survival time (inmonths) isthe time until cosmeticdeteriorationwhichisdeterminedbythe appearance of breast retraction. Procedure along with computation, output and pictorial representation Computational Tables from SAS Summaryof censoredanduncensoredvalues- Summary of the Number of Censored and Uncensored Values Stratumtreatment Total Failed Censored Percent Censored 1CTM 24 20 4 16.67 2R 25 18 7 28.00 3RC 27 21 6 22.22 Total 76 59 17 22.37
- 2. The above table shows the summary of all the censored and uncensored values obtained from the given data set. 1.Kaplan –Meier Estimate SAS procedure- For each case in the sample, we define three variables, Time, Status and Treatment. Let Time denote the survival time (exact or censored), Status be a dummy variable with Status=0 if Time is censored and 1 otherwise and Treat be a variable with Treat = R if the patient received Radiotherapy alone, RC if the patient receive Radiotherapy and Chemotherapy and CTM if the patient received Chinese traditional medicine. The SAS code for procedure LIFETEST can be used to test the above null hypothesis. We should simply add a STRATA statement after the Time statement. We computed and plotted the PLS estimates of S(t) at every time for the R,RC and CTM groups. Hence using proc lifetest we acquire the following result. We also include the Survival distribution function but later on different section. SAS output- The following tables are the SAS output of Product Limit (PL) survival estimates under the three treatment groups CTM, R and RC. (a) CTM- Product-Limit Survival Estimates Time SurvivalFailure Survival Standard Error Number Failed Number Left 0.0000 1.0000 0 0 0 24 10.0000 0.95830.0417 0.0408 1 23 13.0000 0.91670.0833 0.0564 2 22 14.0000 0.87500.1250 0.0675 3 21 16.0000 0.83330.1667 0.0761 4 20 16.0000* . . . 4 19 18.0000 0.78950.2105 0.0838 5 18 20.0000 0.74560.2544 0.0899 6 17 21.0000 0.70180.2982 0.0947 7 16 27.0000 0.65790.3421 0.0984 8 15 28.0000 . . . 9 14 28.0000 0.57020.4298 0.1030 10 13 28.0000* . . . 10 12 32.0000 0.52270.4773 0.1048 11 11
- 3. 33.0000 . . . 12 10 33.0000 0.42760.5724 0.1051 13 9 34.0000 0.38010.6199 0.1036 14 8 39.0000* . . . 14 7 41.0000 0.32580.6742 0.1020 15 6 46.0000 0.27150.7285 0.0984 16 5 51.0000 0.21720.7828 0.0925 17 4 52.0000 0.16290.8371 0.0838 18 3 53.0000 0.10860.8914 0.0713 19 2 55.0000* . . . 19 1 57.0000 01.0000 . 20 0 Summary Statistics for Time Variable Time Quartile Estimates Percent Point Estimate 95% Confidence Interval Transform [Lower Upper) 75 51.0000LOGLOG 33.000057.0000 50 33.0000LOGLOG 21.000046.0000 25 20.0000LOGLOG 10.000028.0000 Mean Standard Error 34.0943 3.2433 (b) R- Product-Limit Survival Estimates Time SurvivalFailure Survival Standard Error Number Failed Number Left 0.0000 1.0000 0 0 0 25 16.0000 0.96000.0400 0.0392 1 24 17.0000* . . . 1 23 18.0000 0.91830.0817 0.0554 2 22 20.0000 0.87650.1235 0.0668 3 21 24.0000 0.83480.1652 0.0755 4 20 25.0000 0.79300.2070 0.0825 5 19 27.0000 . . . 6 18 27.0000 0.70960.2904 0.0925 7 17 29.0000 0.66780.3322 0.0961 8 16 33.0000 0.62610.3739 0.0987 9 15 35.0000 0.58430.4157 0.1006 10 14 36.0000 0.54260.4574 0.1017 11 13 39.0000* . . . 11 12 41.0000 0.49740.5026 0.1028 12 11 44.0000* . . . 12 10
- 4. 45.0000 0.44770.5523 0.1038 13 9 50.0000 0.39790.6021 0.1035 14 8 52.0000 0.34820.6518 0.1018 15 7 52.0000* . . . 15 6 56.0000 . . . 16 5 56.0000 0.23210.7679 0.0954 17 4 58.0000* . . . 17 3 59.0000 0.15470.8453 0.0896 18 2 60.0000* . . . 18 1 60.0000* . . . 18 0 Summary Statistics for Time Variable Time Quartile Estimates Percent Point Estimate 95% Confidence Interval Transform [Lower Upper) 75 56.0000LOGLOG 45.0000 . 50 41.0000LOGLOG 27.000056.0000 25 27.0000LOGLOG 16.000036.0000 Mean Standard Error 41.4362 3.1849 (c) RC- Product-Limit Survival Estimates Time SurvivalFailure Survival Standard Error Number Failed Number Left 0.0000 1.0000 0 0 0 27 9.0000 0.96300.0370 0.0363 1 26 11.0000 0.92590.0741 0.0504 2 25 17.0000 . . . 3 24 17.0000 0.85190.1481 0.0684 4 23 19.0000 0.81480.1852 0.0748 5 22 21.0000 0.77780.2222 0.0800 6 21 24.0000 0.74070.2593 0.0843 7 20 25.0000 0.70370.2963 0.0879 8 19 27.0000 0.66670.3333 0.0907 9 18 28.0000 0.62960.3704 0.0929 10 17 28.0000* . . . 10 16 29.0000 0.59030.4097 0.0951 11 15 29.0000* . . . 11 14 30.0000 0.54810.4519 0.0972 12 13
- 5. 33.0000 0.50600.4940 0.0984 13 12 37.0000 0.46380.5362 0.0989 14 11 39.0000 0.42160.5784 0.0985 15 10 40.0000* . . . 15 9 44.0000 0.37480.6252 0.0980 16 8 46.0000* . . . 16 7 47.0000* . . . 16 6 51.0000 0.31230.6877 0.0996 17 5 52.0000 0.24990.7501 0.0973 18 4 54.0000 0.18740.8126 0.0909 19 3 56.0000 0.12490.8751 0.0792 20 2 58.0000 0.06250.9375 0.0593 21 1 60.0000* . . . 21 0 Summary Statistics for Time Variable Time Quartile Estimates Percent Point Estimate 95% Confidence Interval Transform [Lower Upper) 75 52.0000LOGLOG 39.000058.0000 50 37.0000LOGLOG 25.000052.0000 25 24.0000LOGLOG 11.000029.0000 Mean Standard Error 36.9469 3.2011 2.Life-table Analysis SAS Procedure-The SAS procedure for the life-table analysis remains the same but here under proc lifetest we define the intervals under which we are creating the life-table. SAS output- The following tables are the SAS output of life-table analysis under the three treatment groups CTM,R and RC. (a) CTM-
- 6. Life Table Survival Estimates Interval Num ber Faile d Numb er Censo red Effect ive Samp le Size Conditi onal Probabi lity of Failure Conditi onal Probabi lity Standar d Error Survi val Fail ure Survi val Stand ard Error Media n Resid ual Lifeti me Media n Stand ard Error Evaluated at the Midpoint of the Interval [Low er, Upp er) PDF PDF Stand ard Error Hazar d Hazar d Stand ard Error 0 5 0 0 24.0 0 0 1.000 0 0 0 31.75 02 2.704 6 0 . 0 . 5 10 0 0 24.0 0 0 1.000 0 0 0 26.75 02 2.704 6 0 . 0 . 10 15 3 0 24.0 0.1250 0.0675 1.000 0 0 0 21.75 02 2.704 6 0.02 50 0.013 5 0.026 667 0.015 362 15 20 2 1 20.5 0.0976 0.0655 0.875 0 0.12 50 0.067 5 18.40 64 2.560 6 0.01 71 0.011 5 0.020 513 0.014 486 20 25 2 0 18.0 0.1111 0.0741 0.789 6 0.21 04 0.083 7 14.53 75 2.466 0 0.01 75 0.011 8 0.023 529 0.016 609 25 30 3 1 15.5 0.1935 0.1004 0.701 9 0.29 81 0.094 6 17.45 00 8.267 7 0.02 72 0.014 6 0.042 857 0.024 601 30 35 4 0 12.0 0.3333 0.1361 0.566 0 0.43 40 0.103 8 18.75 00 7.577 7 0.03 77 0.016 9 0.08 0.039 192 35 40 0 1 7.5 0 0 0.377 4 0.62 26 0.103 6 17.50 00 2.130 0 0 . 0 . 40 45 1 0 7.0 0.1429 0.1323 0.377 4 0.62 26 0.103 6 12.50 00 2.204 8 0.01 08 0.010 4 0.030 769 0.030 678 45 50 1 0 6.0 0.1667 0.1521 0.323 5 0.67 65 0.101 8 8.333 3 2.041 2 0.01 08 0.010 4 0.036 364 0.036 213 50 55 3 0 5.0 0.6000 0.2191 0.269 5 0.73 05 0.098 1 4.166 7 1.863 4 0.03 23 0.016 7 0.171 429 0.089 424 55 60 1 1 1.5 0.6667 0.3849 0.107 8 0.89 22 0.070 9 3.750 0 3.061 9 0.01 44 0.012 6 0.2 0.173 205 60 . 0 0 0.0 0 0 0.035 9 0.96 41 0.047 8 . . . . . . (b) R-
- 7. Life Table Survival Estimates Interval Num ber Faile d Numb er Censo red Effect ive Samp le Size Conditi onal Probab ility of Failure Conditi onal Probab ility Standa rd Error Survi val Fail ure Survi val Stand ard Error Medi an Resid ual Lifeti me Media n Stand ard Error Evaluated at the Midpoint of the Interval [Low er, Upp er) PDF PDF Stand ard Error Hazar d Hazar d Stand ard Error 0 5 0 0 25.0 0 0 1.000 0 0 0 44.23 88 10.65 22 0 . 0 . 5 10 0 0 25.0 0 0 1.000 0 0 0 39.23 88 10.65 22 0 . 0 . 10 15 0 0 25.0 0 0 1.000 0 0 0 34.23 88 10.65 22 0 . 0 . 15 20 2 1 24.5 0.0816 0.0553 1.000 0 0 0 29.23 88 10.76 04 0.01 63 0.011 1 0.017 021 0.012 025 20 25 2 0 22.0 0.0909 0.0613 0.918 4 0.08 16 0.055 3 28.41 59 9.931 8 0.01 67 0.011 3 0.019 048 0.013 453 25 30 4 0 20.0 0.2000 0.0894 0.834 9 0.16 51 0.075 5 26.25 18 4.471 7 0.03 34 0.015 2 0.044 444 0.022 085 30 35 1 0 16.0 0.0625 0.0605 0.667 9 0.33 21 0.096 0 25.14 18 2.256 2 0.00 835 0.008 17 0.012 903 0.012 897 35 40 2 1 14.5 0.1379 0.0906 0.626 2 0.37 38 0.098 7 20.70 59 2.221 9 0.01 73 0.011 7 0.029 63 0.020 894 40 45 1 1 11.5 0.0870 0.0831 0.539 8 0.46 02 0.102 2 16.87 29 2.150 8 0.00 939 0.009 14 0.018 182 0.018 163 45 50 1 0 10.0 0.1000 0.0949 0.492 9 0.50 71 0.103 6 12.50 71 2.105 9 0.00 986 0.009 58 0.021 053 0.021 023 50 55 2 1 8.5 0.2353 0.1455 0.443 6 0.55 64 0.104 3 8.173 1 2.055 8 0.02 09 0.013 8 0.053 333 0.037 376 55 60 3 1 5.5 0.5455 0.2123 0.339 2 0.66 08 0.102 6 4.583 3 1.954 3 0.03 70 0.018 2 0.15 0.080 283 60 . 0 2 1.0 0 0 0.154 2 0.84 58 0.085 8 . . . . . . (b) RC-
- 8. Life Table Survival Estimates Interval Num ber Faile d Numb er Censo red Effect ive Samp le Size Conditi onal Probab ility of Failure Conditi onal Probab ility Standa rd Error Survi val Fail ure Survi val Stand ard Error Medi an Resid ual Lifeti me Media n Stand ard Error Evaluated at the Midpoint of the Interval [Low er, Upp er) PDF PDF Stand ard Error Hazar d Hazar d Stand ard Error 0 5 0 0 27.0 0 0 1.000 0 0 0 35.07 50 5.759 1 0 . 0 . 5 10 1 0 27.0 0.0370 0.0363 1.000 0 0 0 30.07 50 5.759 1 0.00 741 0.007 27 0.007 547 0.007 546 10 15 1 0 26.0 0.0385 0.0377 0.963 0 0.03 70 0.036 3 26.18 33 5.651 4 0.00 741 0.007 27 0.007 843 0.007 842 15 20 3 0 25.0 0.1200 0.0650 0.925 9 0.07 41 0.050 4 22.29 17 5.541 7 0.02 22 0.012 1 0.025 532 0.014 711 20 25 2 0 22.0 0.0909 0.0613 0.814 8 0.18 52 0.074 8 21.17 17 9.877 2 0.01 48 0.010 1 0.019 048 0.013 453 25 30 4 2 19.0 0.2105 0.0935 0.740 7 0.25 93 0.084 3 25.09 02 2.273 5 0.03 12 0.014 3 0.047 059 0.023 366 30 35 2 0 14.0 0.1429 0.0935 0.584 8 0.41 52 0.096 1 22.17 65 2.090 9 0.01 67 0.011 3 0.030 769 0.021 693 35 40 2 0 12.0 0.1667 0.1076 0.501 3 0.49 87 0.098 9 18.29 41 1.935 8 0.01 67 0.011 3 0.036 364 0.025 607 40 45 1 1 9.5 0.1053 0.0996 0.417 7 0.58 23 0.098 5 14.41 18 1.813 1 0.00 879 0.008 57 0.022 222 0.022 188 45 50 0 2 7.0 0 0 0.373 7 0.62 63 0.097 4 10.00 00 1.889 8 0 . 0 . 50 55 3 0 6.0 0.5000 0.2041 0.373 7 0.62 63 0.097 4 5.000 0 2.041 2 0.03 74 0.018 1 0.133 333 0.072 577 55 60 2 0 3.0 0.6667 0.2722 0.186 9 0.81 31 0.090 5 3.750 0 2.165 1 0.02 49 0.015 8 0.2 0.122 474 60 . 0 1 0.5 0 0 0.062 3 0.93 77 0.059 1 . . . . . . Goodness of Fit test In thissectionwe will performthe goodnessof fittestunder the differentdistributionandwe will select the appropriate distributionaccordingtothe AICvalue (the lowerthe better). Conclusion-Fromthe tablesof the SASoutputwe will selectLogNormal distributionasourmodel for fittingthe data.
- 9. Detailsof the SASoutputare giveninthe followingmanner- SAS Output- Exponential Distribution- Fit Statistics -2 Log Likelihood 175.956 AIC (smaller is better) 177.956 AICC (smaller is better)178.010 BIC (smaller is better) 180.287 Analysis of Maximum Likelihood Parameter Estimates Parameter DF Estimate Standard Error95% Confidence LimitsChi-Square Pr > ChiSq Intercept 1 3.4570 0.1089 3.2436 3.6704 1007.79 <.0001 Scale 0 1.0000 0.0000 1.0000 1.0000 Weibull Scale 1 31.7213 3.4543 25.6246 39.2684 Weibull Shape 0 1.0000 0.0000 1.0000 1.0000 Weibull distribution- Fit Statistics -2 Log Likelihood 154.835 AIC (smaller is better) 158.835 AICC (smaller is better)159.000 BIC (smaller is better) 163.497 Analysis of Maximum Likelihood Parameter Estimates Parameter DF Estimate Standard Error95% Confidence LimitsChi-Square Pr > ChiSq Intercept 1 3.4570 0.0853 3.2899 3.6241 1643.79 <.0001 Scale 1 0.4830 0.0615 0.3763 0.6199 Weibull Scale 1 31.7213 2.7047 26.8394 37.4912 Weibull Shape 1 2.0703 0.2636 1.6131 2.6573
- 10. Log Normal Distribution- Fit Statistics -2 Log Likelihood 128.013 AIC (smaller is better) 132.013 AICC (smaller is better)132.177 BIC (smaller is better) 136.674 Analysis of Maximum Likelihood Parameter Estimates ParameterDF Estimate Standard Error95% Confidence LimitsChi-Square Pr > ChiSq Intercept 1 3.4570 0.0578 3.3436 3.5703 3573.43 <.0001 Scale 1 0.4830 0.0381 0.4138 0.5637 Log logisticDistribution- Fit Statistics -2 Log Likelihood 139.573 AIC (smaller is better) 143.573 AICC (smaller is better)143.737 BIC (smaller is better) 148.234 Analysis of Maximum Likelihood Parameter Estimates ParameterDF Estimate Standard Error95% Confidence LimitsChi-Square Pr > ChiSq Intercept 1 3.4570 0.0969 3.2671 3.6469 1272.89 <.0001 Scale 1 0.4830 0.1005 0.3212 0.7263 Gamma Distribution- Fit Statistics -2 Log Likelihood 154.835 AIC (smaller is better) 160.835 AICC (smaller is better)161.169 BIC (smaller is better) 167.827
- 11. Analysis of Maximum Likelihood Parameter Estimates ParameterDF Estimate Standard Error95% Confidence LimitsChi-Square Pr > ChiSq Intercept 1 3.4570 0.0853 3.2899 3.6241 1643.79 <.0001 Scale 1 0.4830 0.0615 0.3763 0.6199 Shape 0 1.0000 0.0000 1.0000 1.0000 Interpretation-The AICvale of Lognormal distributionis132.013 whichisthe smallestamongstthe otherdistributions,hence Lognormal distributionisthe appropriate model forfittingthe givendataset. Pictorial Representation Survival function- Most real life survival curves are not portrayed as smooth curves as in this example. Instead, they are usually shown as staircase curves with a "step" down each time there is a death. This is because a real-world survival curve represents the actual experience of a particular group of people. At the moment of each death, the proportion of survivor’s decreases and the proportion of survivors does not change at any other time. Thus the curve steps down at each death and is flat in between deaths which leads to the classic staircase appearance. While a staircase does represent the actual experience of the group whose survival is portrayed in the curve, it does not mean that the risk of an individual patient occurs in discrete steps at specific times as shown in these curves. With staircase curves, as the group of patients is larger, the step down caused by each death is smaller. If the times of the deaths are plotted accurately, then we can see that as the size of the group increases the staircase will become closer and closer to the ideal of a smooth curve
- 12. Interpretation- The curves may compare results from different treatments as in the above graph. If one curve is continuously "above" the other, as with these curves, the conclusion is that the treatment associated with the higher curve was more effective for these patients. There are many ways the two curves could compare. They might be very close to each other indicating there was no difference between the treatments. If a dangerously toxic treatment resulted in more long term survivors than a less dangerous treatment, the curve for the riskier treatment might be lower than the other curve due to early treatment deaths, but end up further off the deck in the end. Now from the above graph it is quite clear that the graph of R(radiotherapy) is above the rest stating that it might be the superior treatment compared to RC and CTMtreatments. Although for all of the treatments the survival graph is getting closer to zero in long run indicating low survival rate for all, which is quite obvious since we are dealing with a fatal disease like breast cancer. Often it may be unclear whether two curves are really different or whether it is reasonable to assume the difference between them may be just due to chance. There are tests of significance
- 13. for survival curves, such as the log rank test, and we will often see a "p value" given with comparative survival curves to indicate whether the difference is statistically significant. This is explained in the next section Hazard Function- The nonparametric hazard plot enables one to examine the hazard function without any distribution assumption. This plot may indicate which parametric distribution would be appropriate for modeling your data should you decide to use parametric estimation methods. One can interpret the nonparametric hazard plot the same way as one would interpret the parametric hazard plot. The major difference is that the nonparametric hazard plot is a step function whereas the parametric hazard plot is a smoothed function.
- 14. Interpretation- From the above graph it is quite evident that the hazard plot of the cancer patients getting the treatment of CTM and RC are increasing than the cancer patients receiving the R treatment. Hence the breast cancer patients receiving the CTM and RC treatment do not respond that well compared to that of the treatment R, stating treatment R is much better. Test of Homogeneity data table from SAS Let us consider the following tests- H0: the treatments (or characteristics) being compared are all the same vs H1: Not H0.
- 15. Using proc lifetest we get the following SAS output for homogeneity test- Rank Statistics treatment Log-RankWilcoxon CTM 5.0743 200.00 R -6.1580 -243.00 RC 1.0837 43.00 Covariance Matrix for the Log-Rank Statistics treatment CTM R RC CTM 10.5217 -5.5701 -4.9516 R -5.570113.3057 -7.7357 RC -4.9516 -7.735712.6873 Covariance Matrix for the Wilcoxon Statistics treatment CTM R RC CTM 26460.0-13342.1-13118.0 R -13342.1 29660.3-16318.2 RC -13118.0-16318.2 29436.2 Test of Equality over Strata Test Chi-Square DF Pr > Chi-Square Log-Rank 3.6109 2 0.1644 Wilcoxon 2.3929 2 0.3023 -2Log(LR) 1.1913 2 0.5512 Interpretation-The ranktestsforhomogeneityindicate asignificantdifference betweenthe treatments (p=0.1644 forthe log-ranktestandp=0.3023 for the Wilcoxontest). The corresponding chi-square p-value of Log-rank test being 0.1644, hence at α-.05 level of significance we accept the null hypothesis H0, stating that there is no significant difference in the difference of the treatments. The p-value corresponding to the chi-square value of Wilcoxon test also supports our argument. Conclusion When not every patient responds to a treatment, as is nearly always the case in cancer therapy, each trial will accrue some patients who will be responders, and others who, unfortunately, will not be responders. By random chance, some of these trials will happen to get more responders and thus show a higher response rate than others. If the trials are small enough and there are enough trials, probably a few of these identical trials will get a much higher response rate than the others.
- 16. From the statistical homogeneity table we can conclude that the three treatments are not much of any difference for the test subject of 76 breast cancer patients. But from the survival graph one may argue that treatment R stands out to be little better compared to the rest. Moreover from the hazard plot, the hazard curve of both of the treatments CTMand RC are highly increasing compared to that of the treatment R, supporting our argument. So with the given small data set we can conclude that although all of the treatments for the breast cancer patients hold significantly no difference and with low survival rate, but treatment R might edge out to be little bit better than the rest. Recommendation If there is a high response rate in a small trial and we conduct one more small trial of the same treatment and also get a high response rate this is evidence that the true response rate really is relatively high - because the chances of randomly getting a much higher response rate than the true response rate in any one small trial is small - getting such results twice in a row is not likely. If the trials are larger, the chance of getting misleading results in the first place is smaller. So we can conclude that on a long run, that is if we collect more sample clinical data we might get a clearer picture as which treatment is best or whether they have any significantly different impact or not.