Download as PDF, PPTX

![“Since it is their [Funding Agencies] mission to
promote research, many funding agencies
support open access. [...] Thus the question
arises whether the money invested in open
access is on a par with its research impact.”
Johannes Fournier (German Research Foundation)
Berlin6, 13 May 2008, Session 7 - Pondering on Research Impact and Cost Effectiveness
http://oa.mpg.de/berlin6/index8a92.html?page_id=75
maurice.vanderfeesten 2](https://image.slidesharecdn.com/sure2-statistics-dashboard-mockup2-110606044630-phpapp02/75/SURE2-Statistics-dashboard-mockup-2-2048.jpg)

![The question of how to measure the
effectiveness of such a publishing model [Open
Access] was simple, according to Liebrand – by
usage levels.
Wim Liebrand, chief executive of SURFfoundation
Research Information, January 2011, Issue 51, page 17
maurice.vanderfeesten 4](https://image.slidesharecdn.com/sure2-statistics-dashboard-mockup2-110606044630-phpapp02/75/SURE2-Statistics-dashboard-mockup-4-2048.jpg)







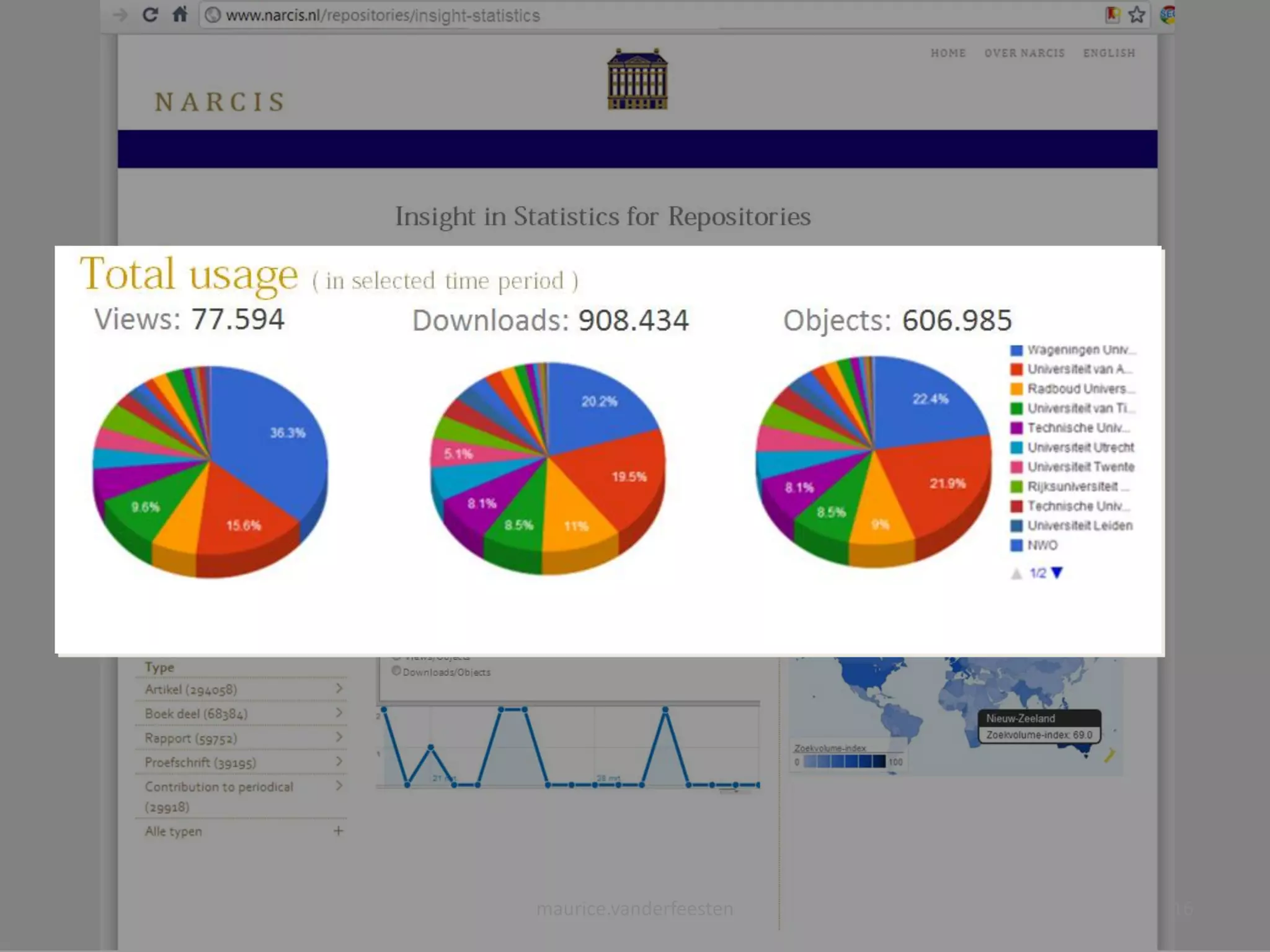
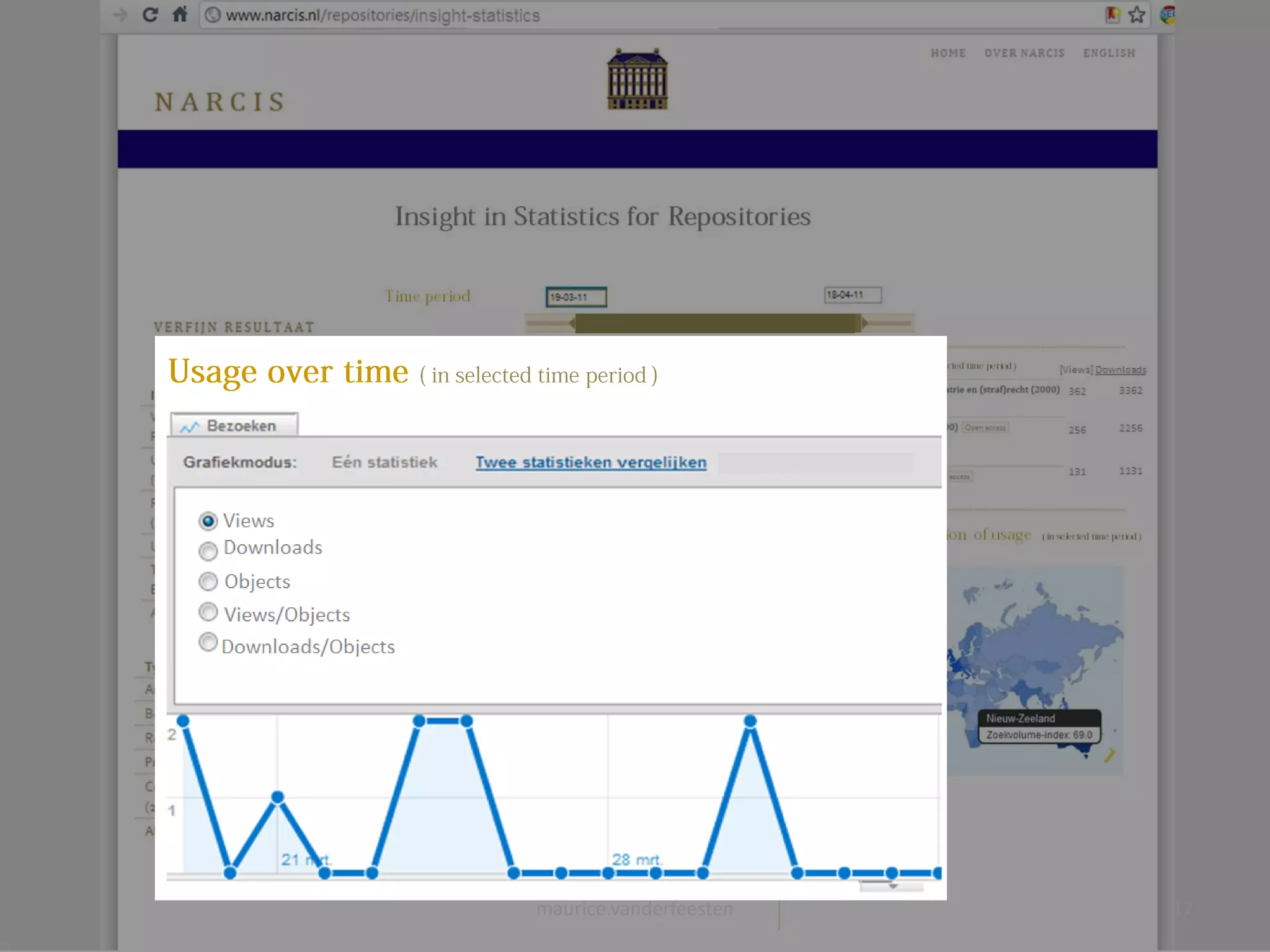
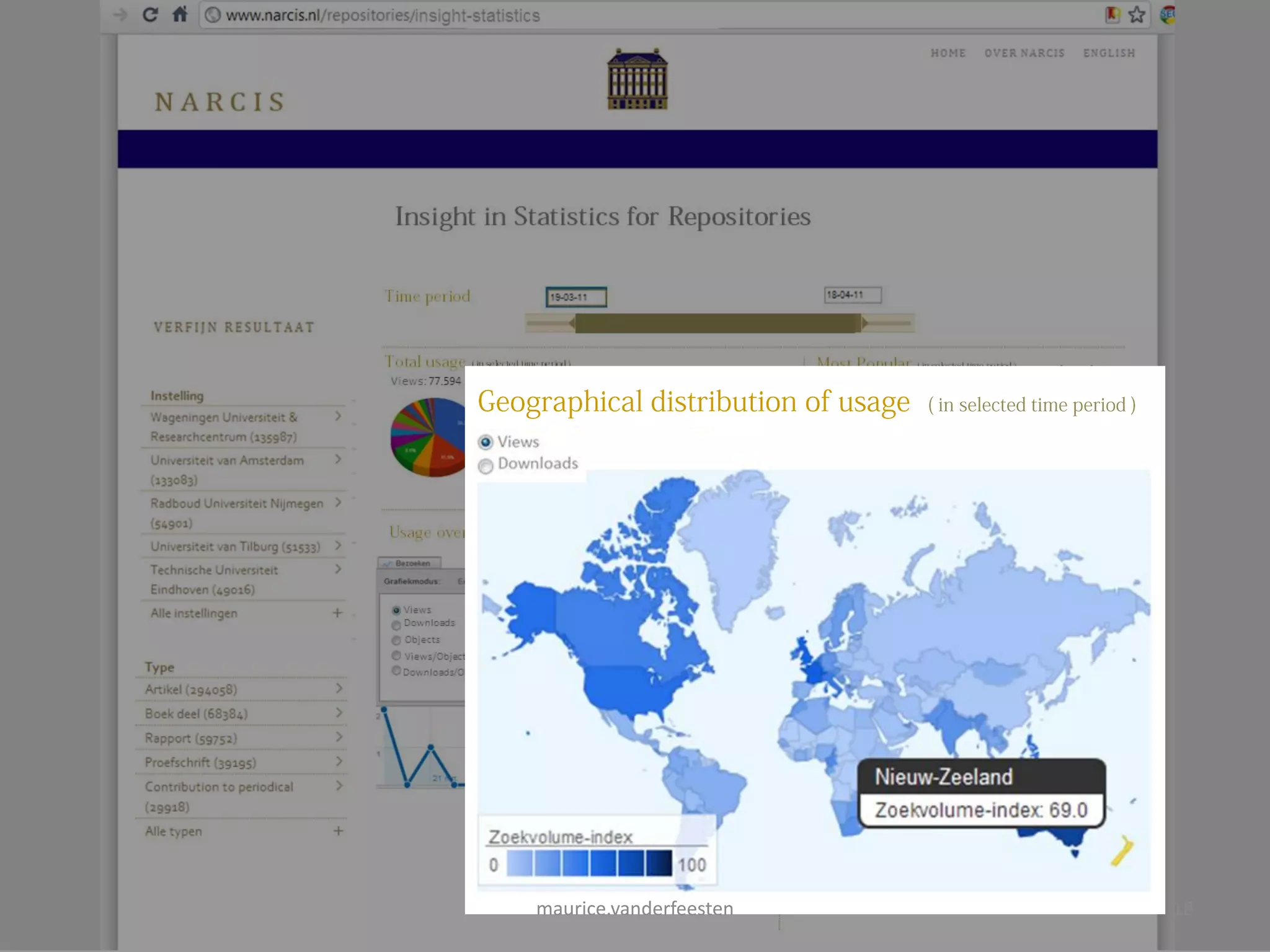
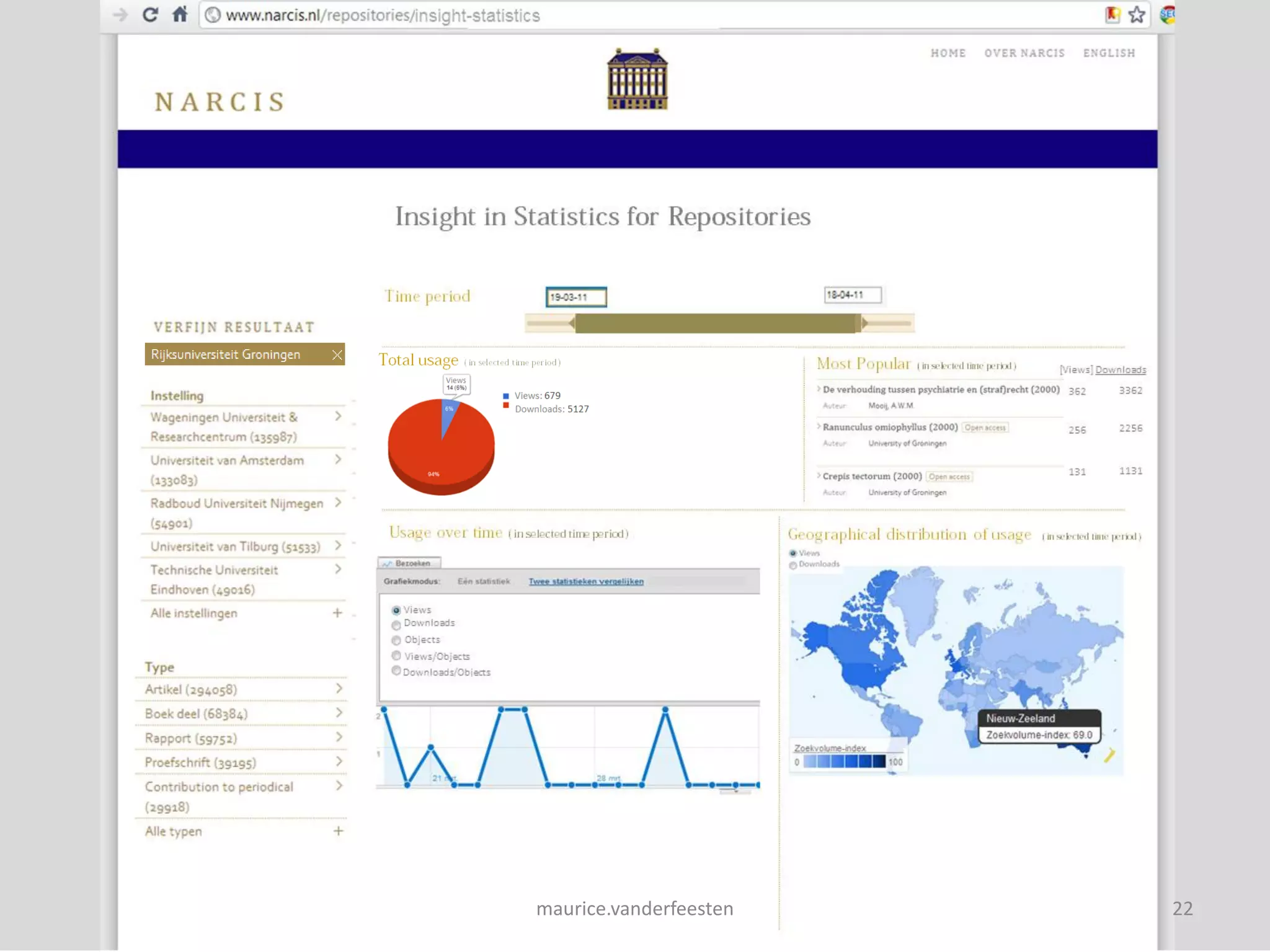
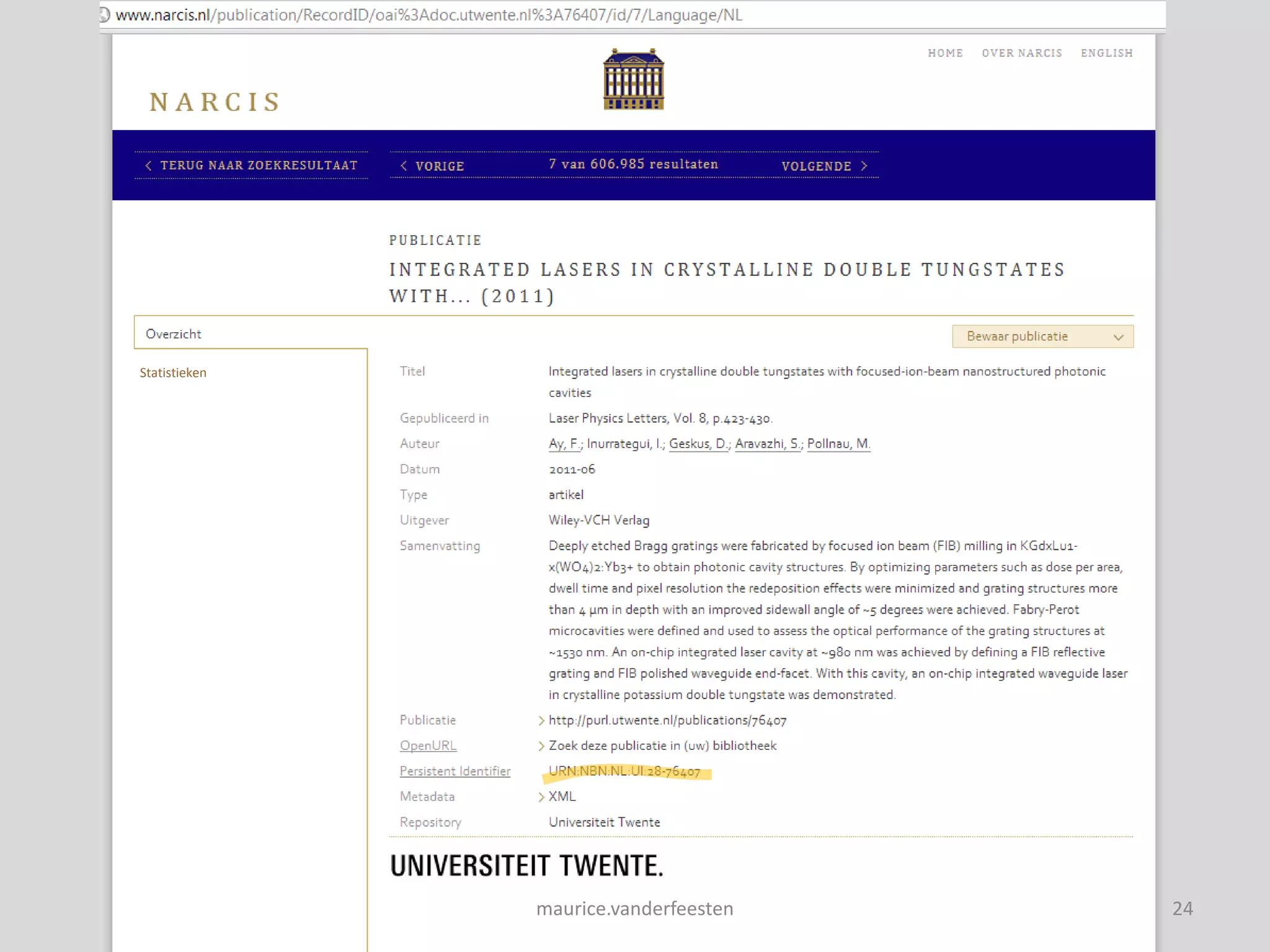
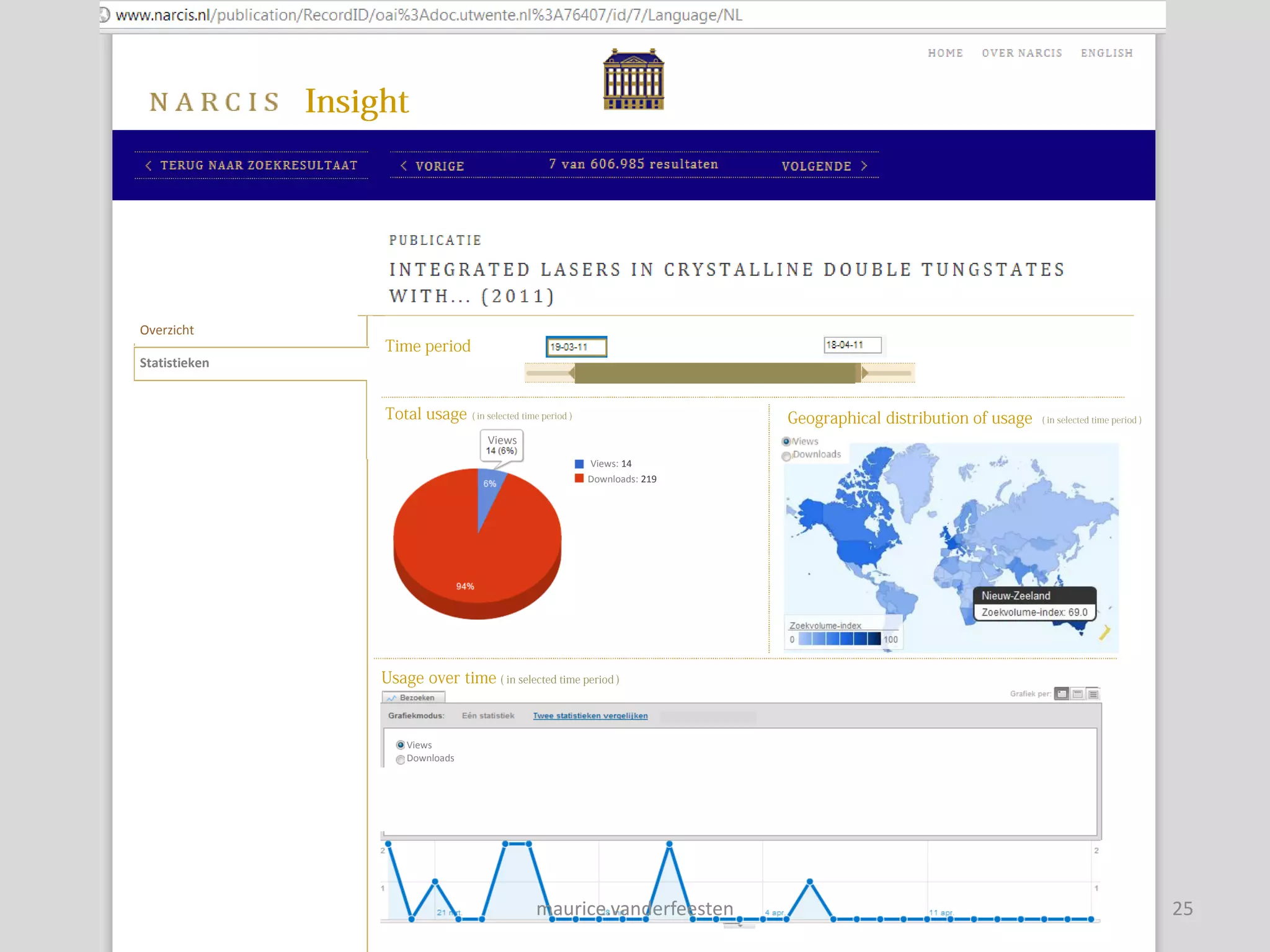
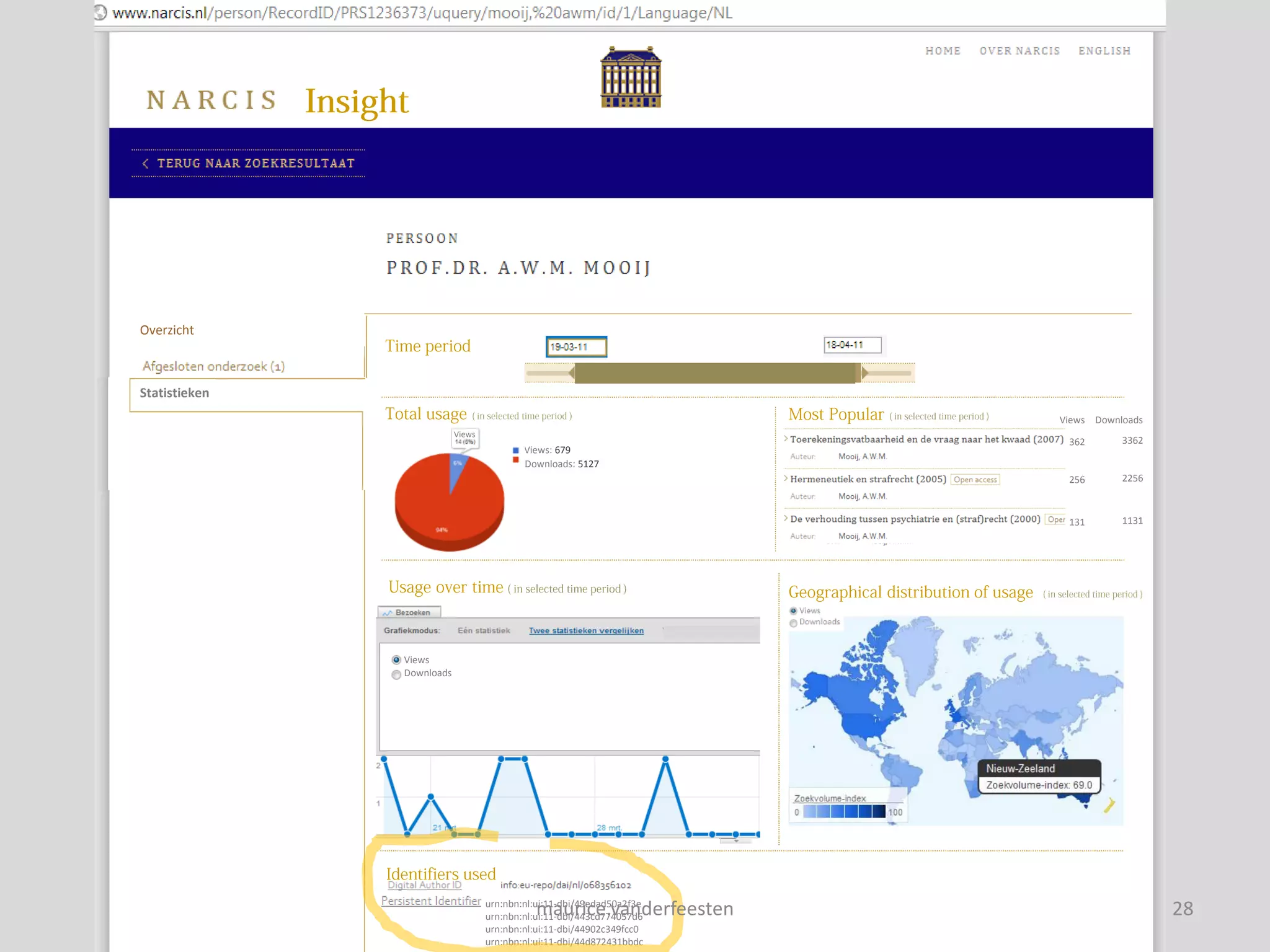
![insight-statistics
[Views] Downloads
Views: 77.594 Downloads: 908.434 Objects: 606.985
362 3362
256 2256
131 1131
Views
Downloads
Objects
Views/Objects
Downloads/Objects
maurice.vanderfeesten 14](https://image.slidesharecdn.com/sure2-statistics-dashboard-mockup2-110606044630-phpapp02/75/SURE2-Statistics-dashboard-mockup-14-2048.jpg)
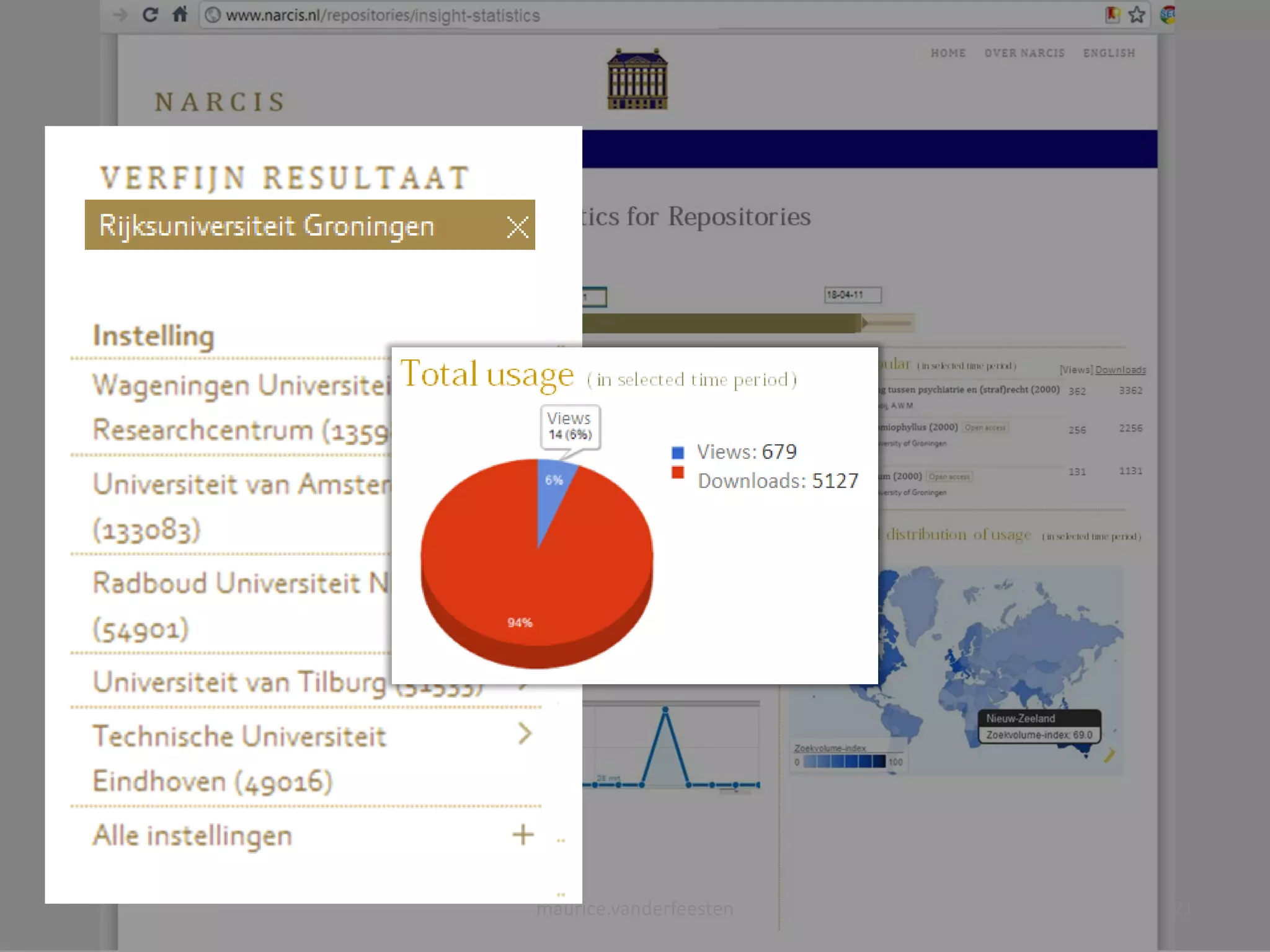
![[Views] Downloads
maurice.vanderfeesten 19](https://image.slidesharecdn.com/sure2-statistics-dashboard-mockup2-110606044630-phpapp02/75/SURE2-Statistics-dashboard-mockup-19-2048.jpg)








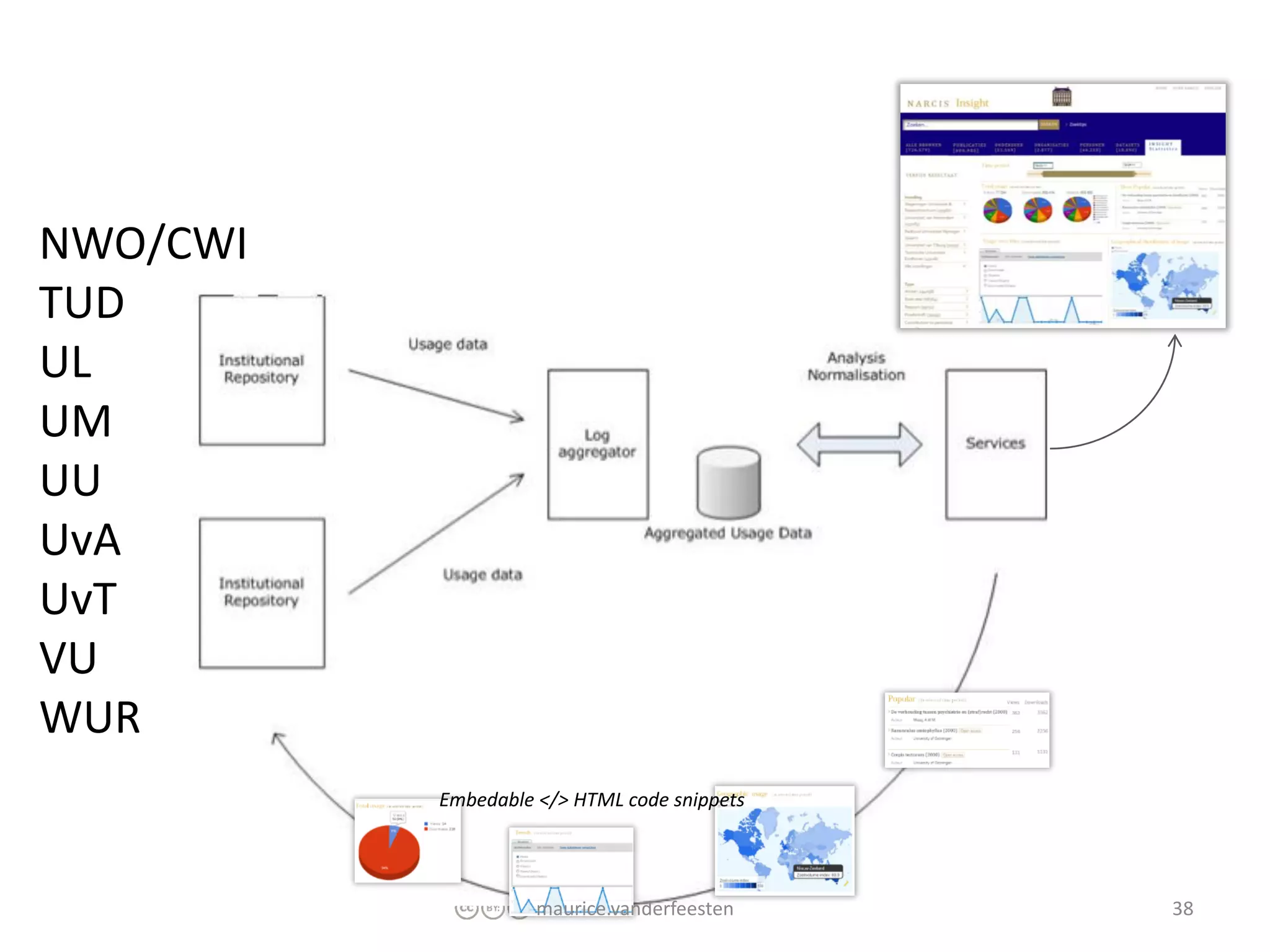
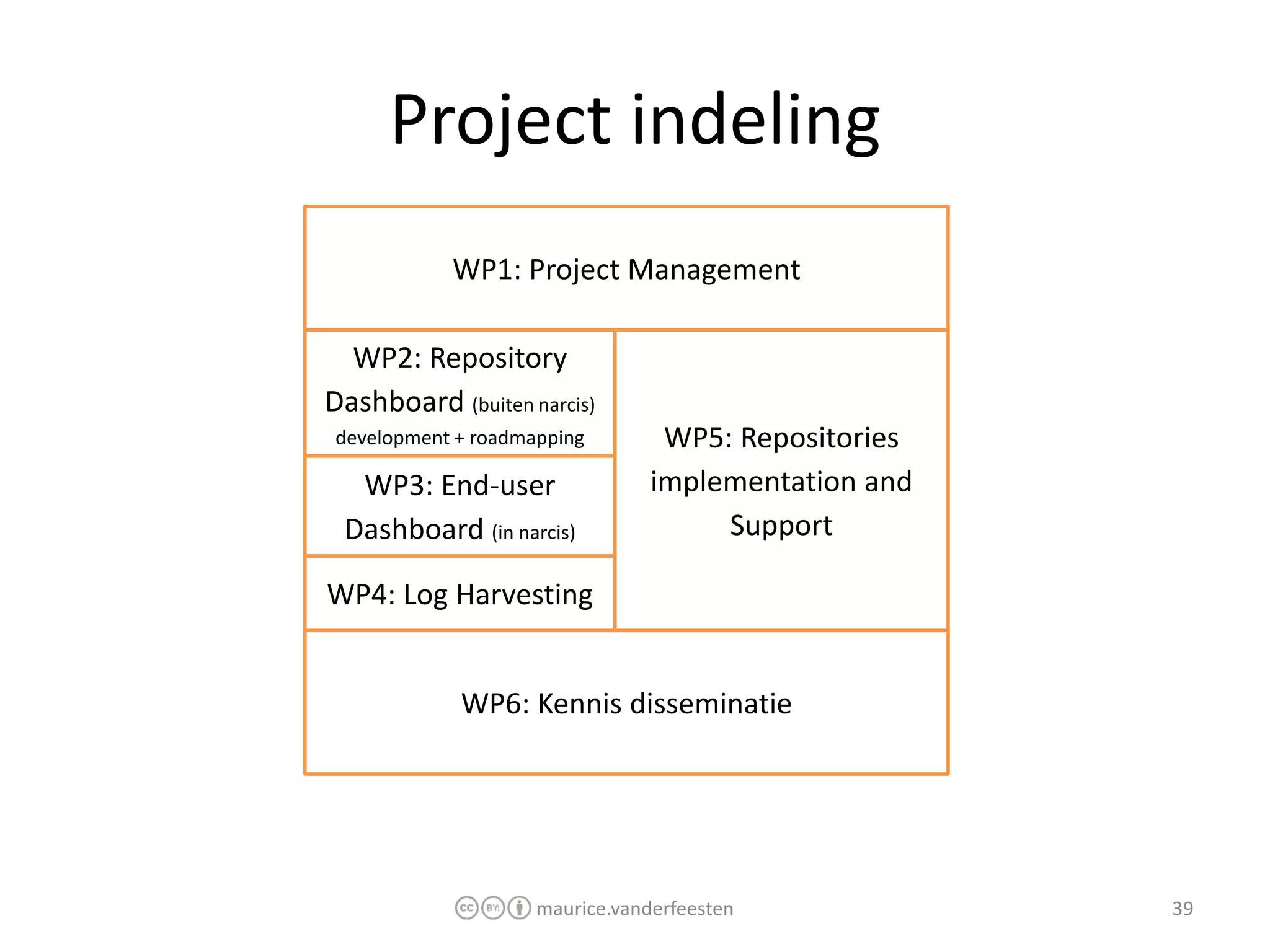

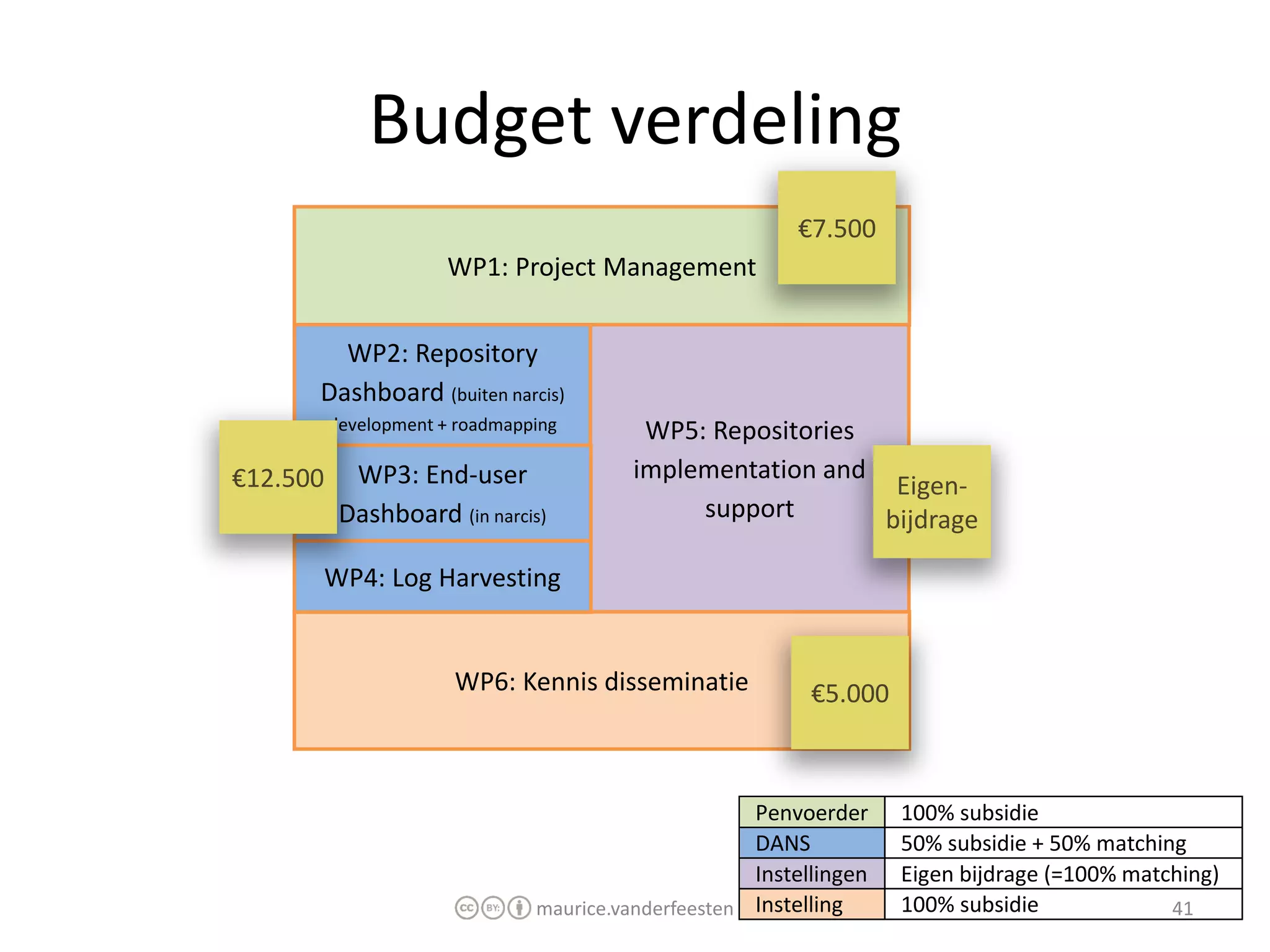



€7.500 WP2: €15.000 WP3: €15.000 WP4: €15.000 WP5: €30.000 WP6: €7.500 Totaal: €90.000 Financiering: SURFfoundation Looptijd: 1 jaar Start: 1 oktober 2011 Eind: 1 oktober 2012 maurice.vanderfeesten 41 Planning 2011 Q3: Projectvoorstel, budget goedkeuring Q4: WP2,3,4 ontwikkeling 2012



































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)