This document provides an overview of support vector machines (SVM). It explains that SVM is a supervised machine learning algorithm used for classification and regression. It works by finding the optimal separating hyperplane that maximizes the margin between different classes of data points. The document discusses key SVM concepts like slack variables, kernels, hyperparameters like C and gamma, and how the kernel trick allows SVMs to fit non-linear decision boundaries.
AI / ML
MachineLearning
Using Computer algorithms to
uncover insights, determine
relationships , and make prediction
about future trends.
Artificial Intelligence
Enabling computer systems to perform
tasks that ordinarily requires human
intelligence.
We use machine learning methods to create AI systems.
4.
Machine Learning Paradigms
•Unsupervised Learning
• Find structure in data. (Clusters, Density, Patterns)
• Supervised Learning
• Find mapping between features to labels
5.
Support Vector Machine
•Supervised machine learning Algorithm.
• Can be used for Classification/Regression.
• Works well with small datasets
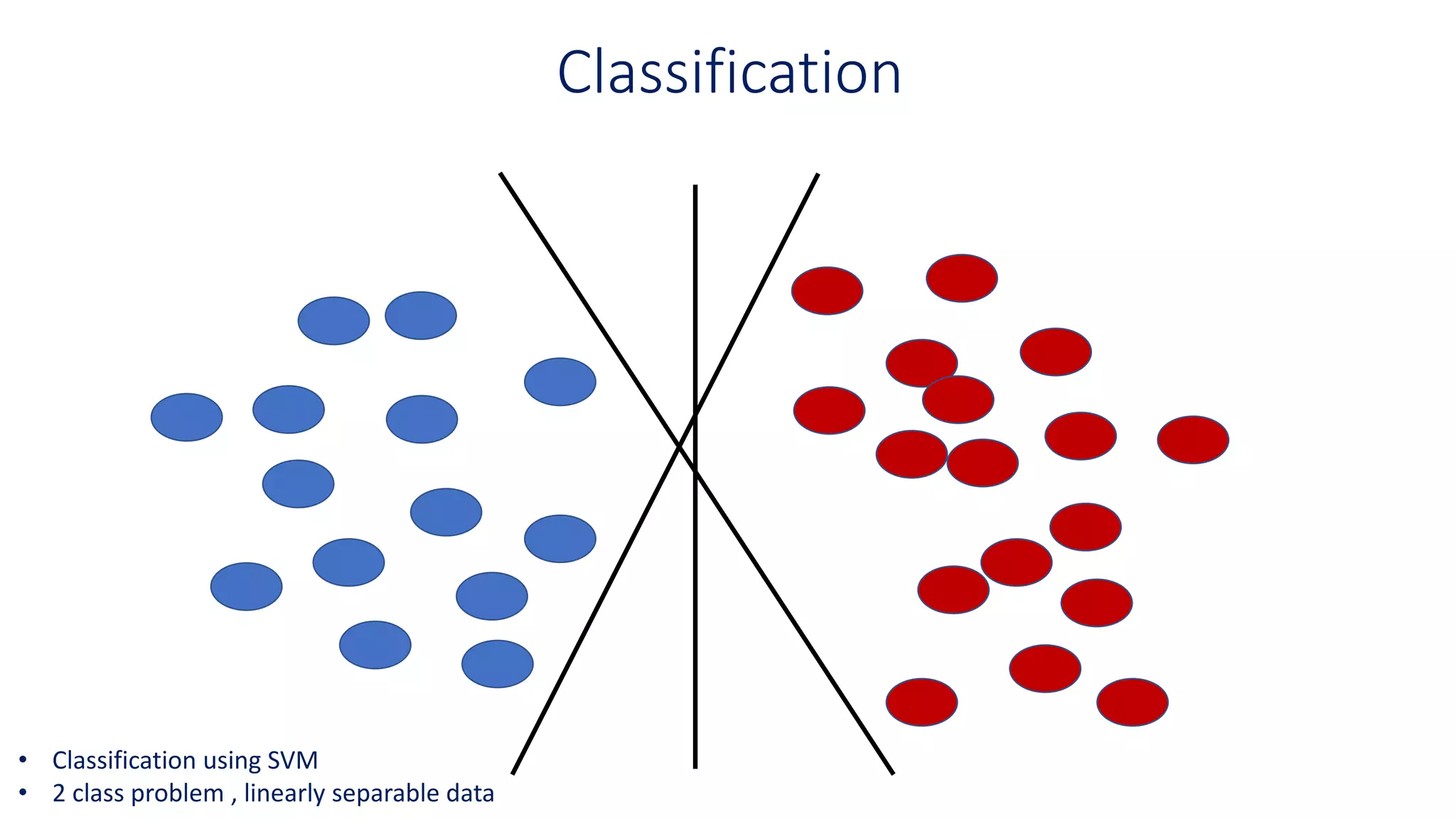
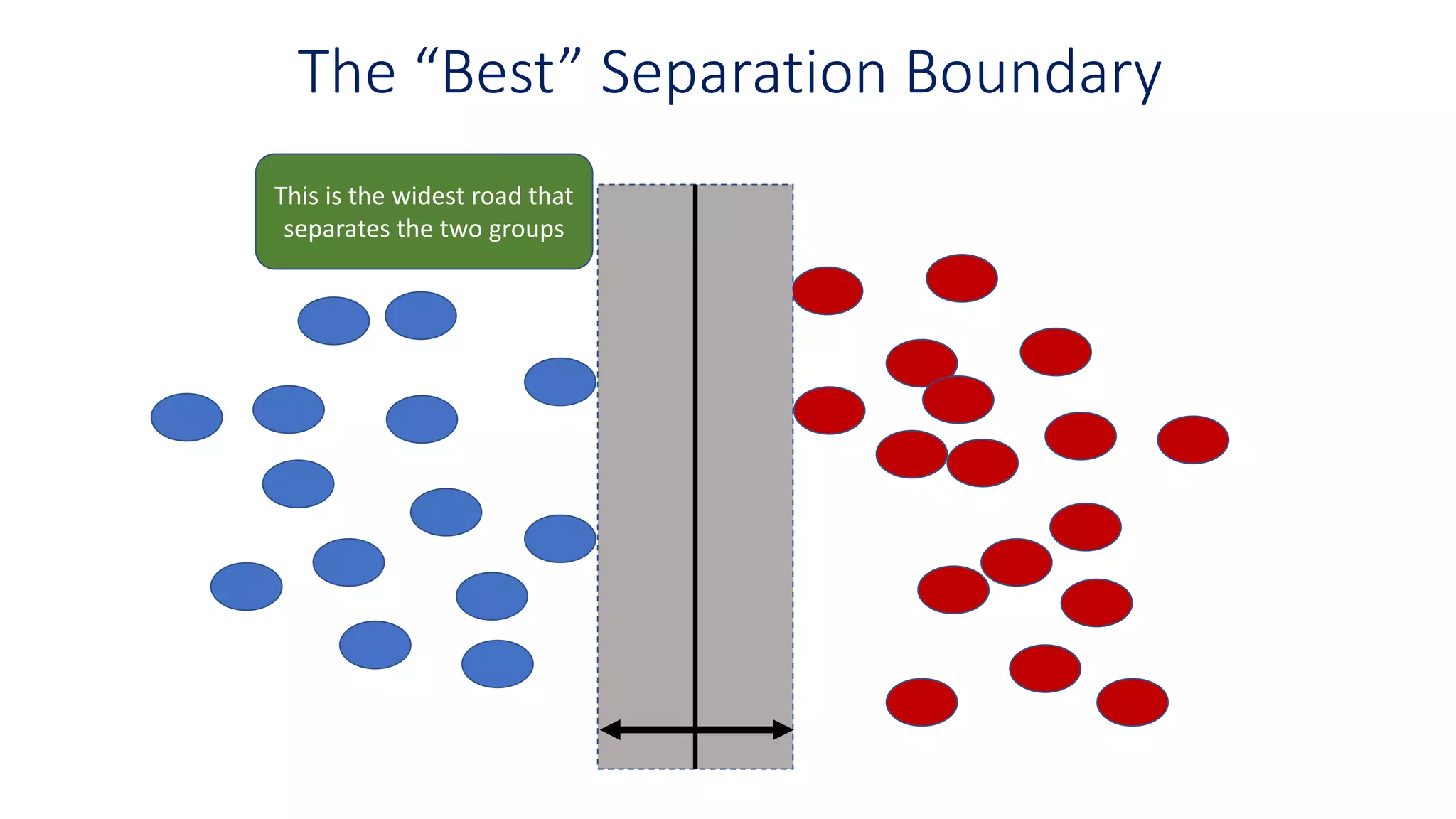
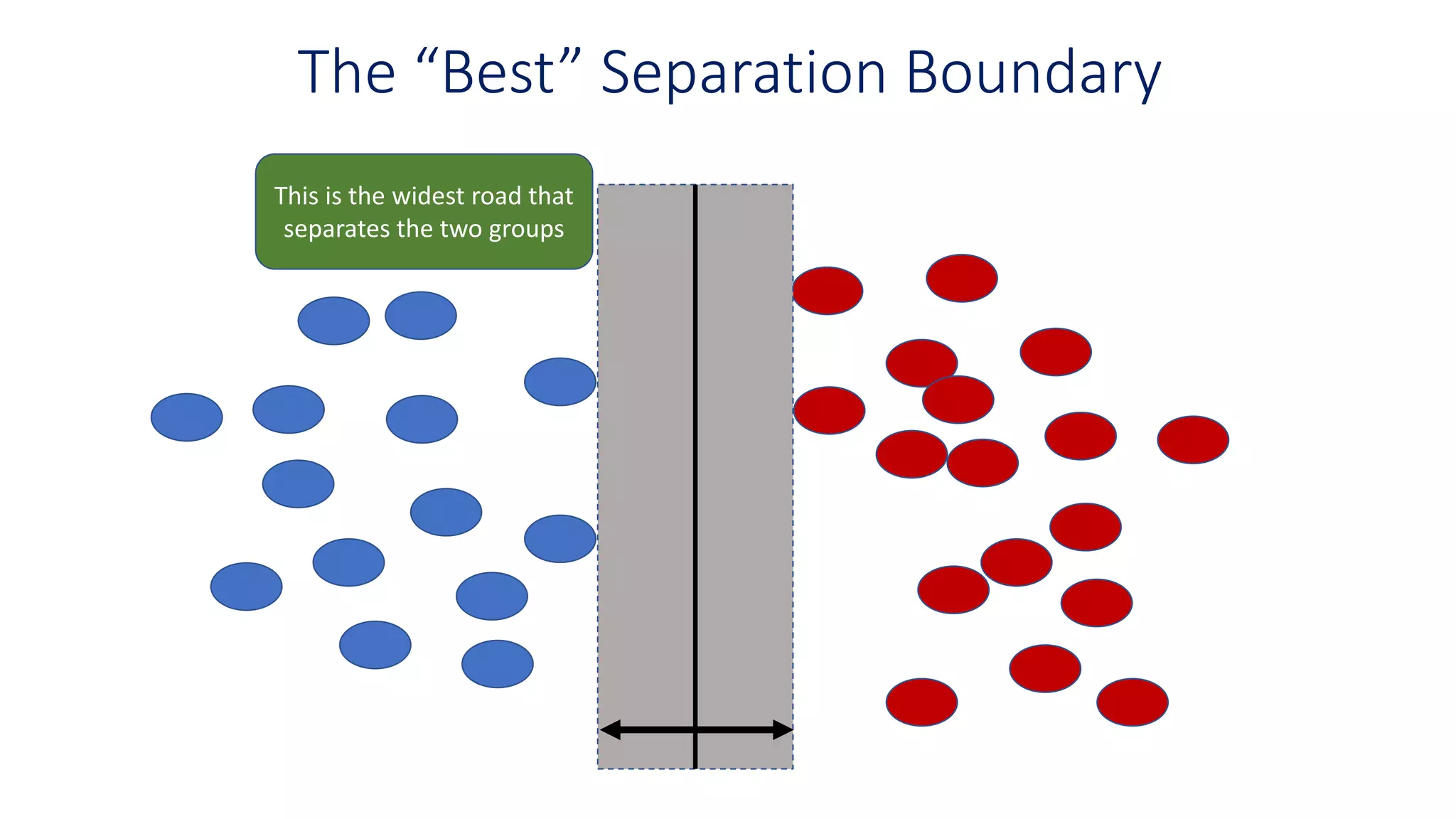
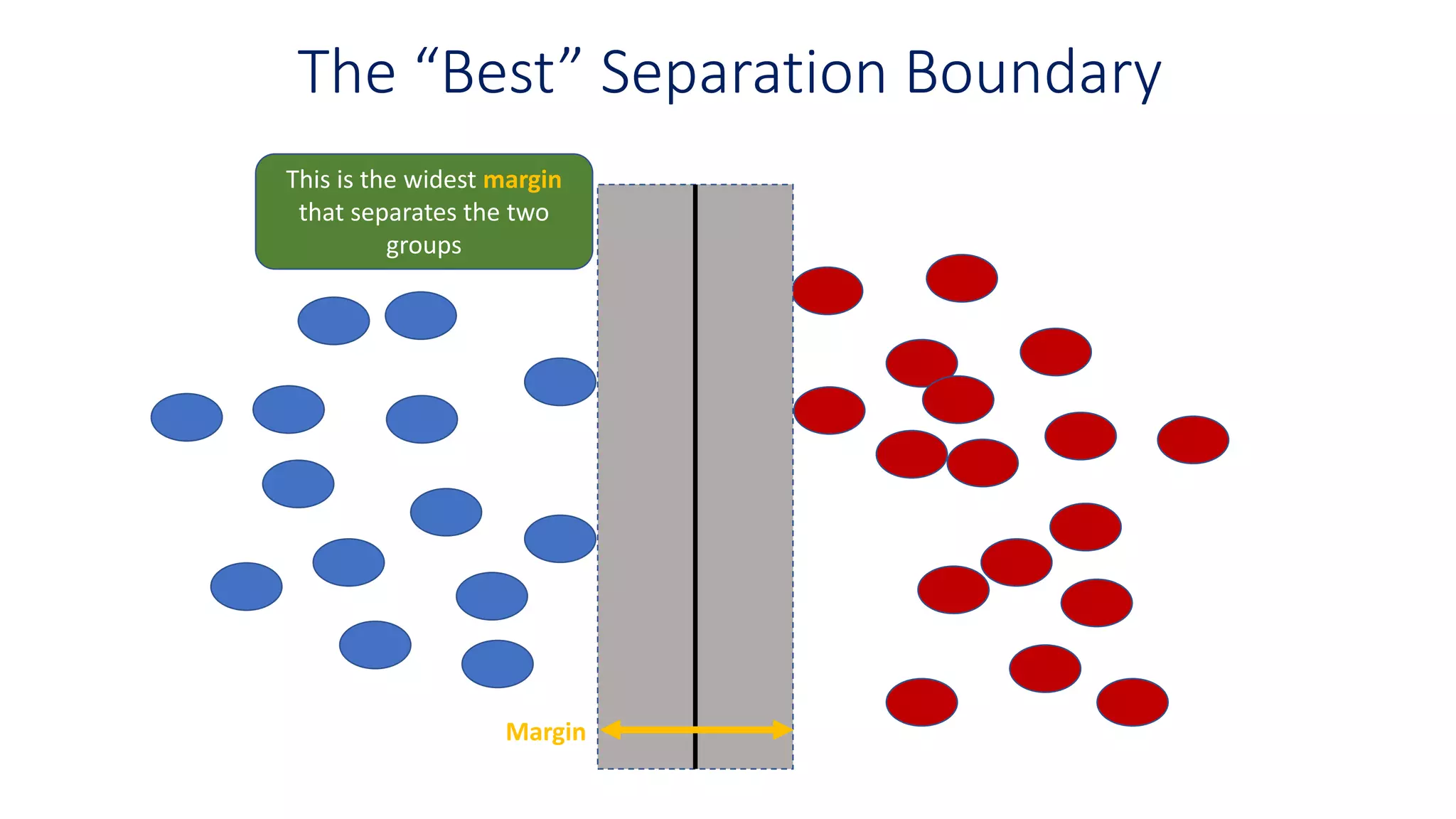
The “Best” SeparationBoundary
This is the widest margin
that separates the two
groups
Margin
12.
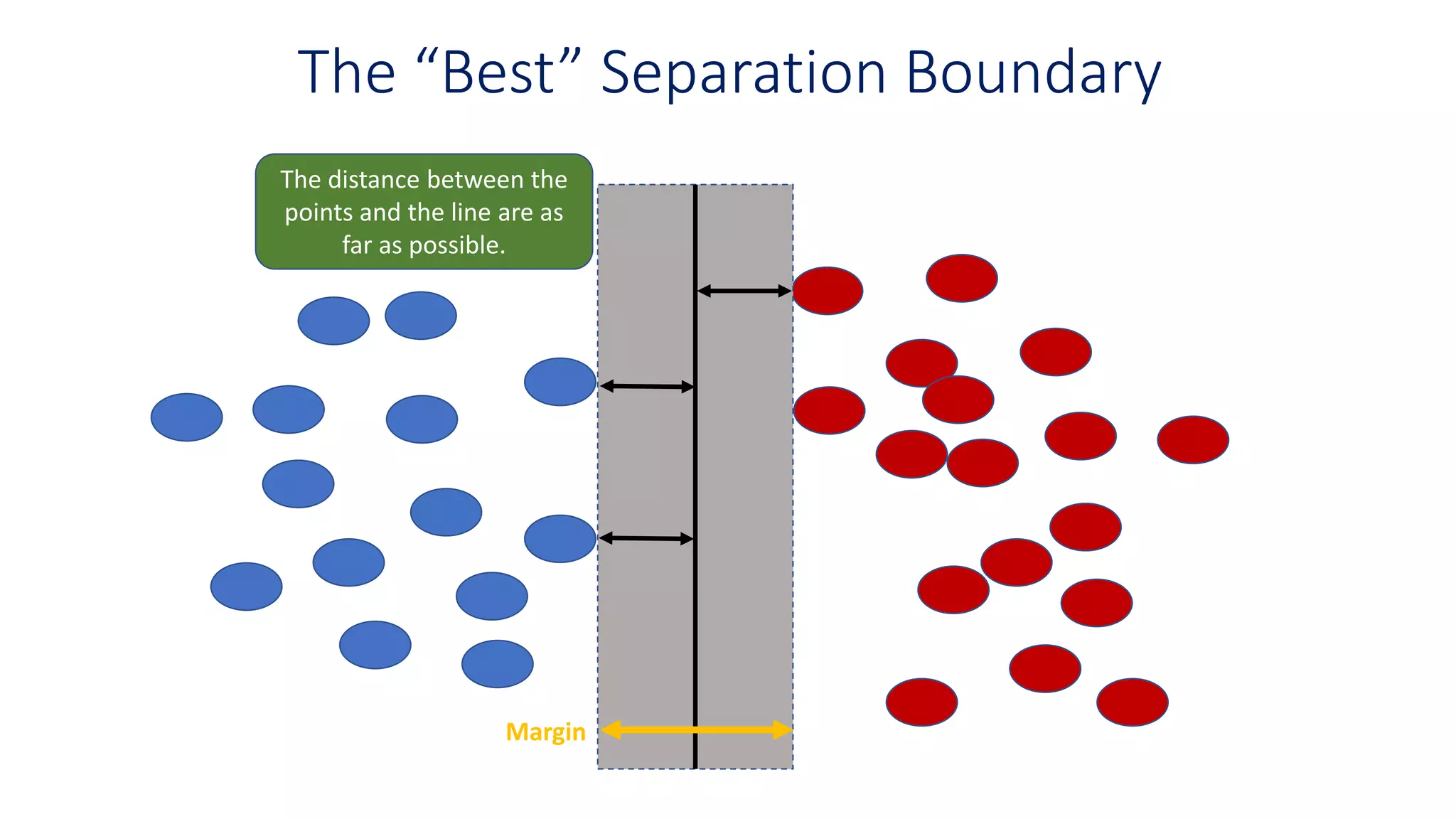
The “Best” SeparationBoundary
The distance between the
points and the line are as
far as possible.
Margin
13.
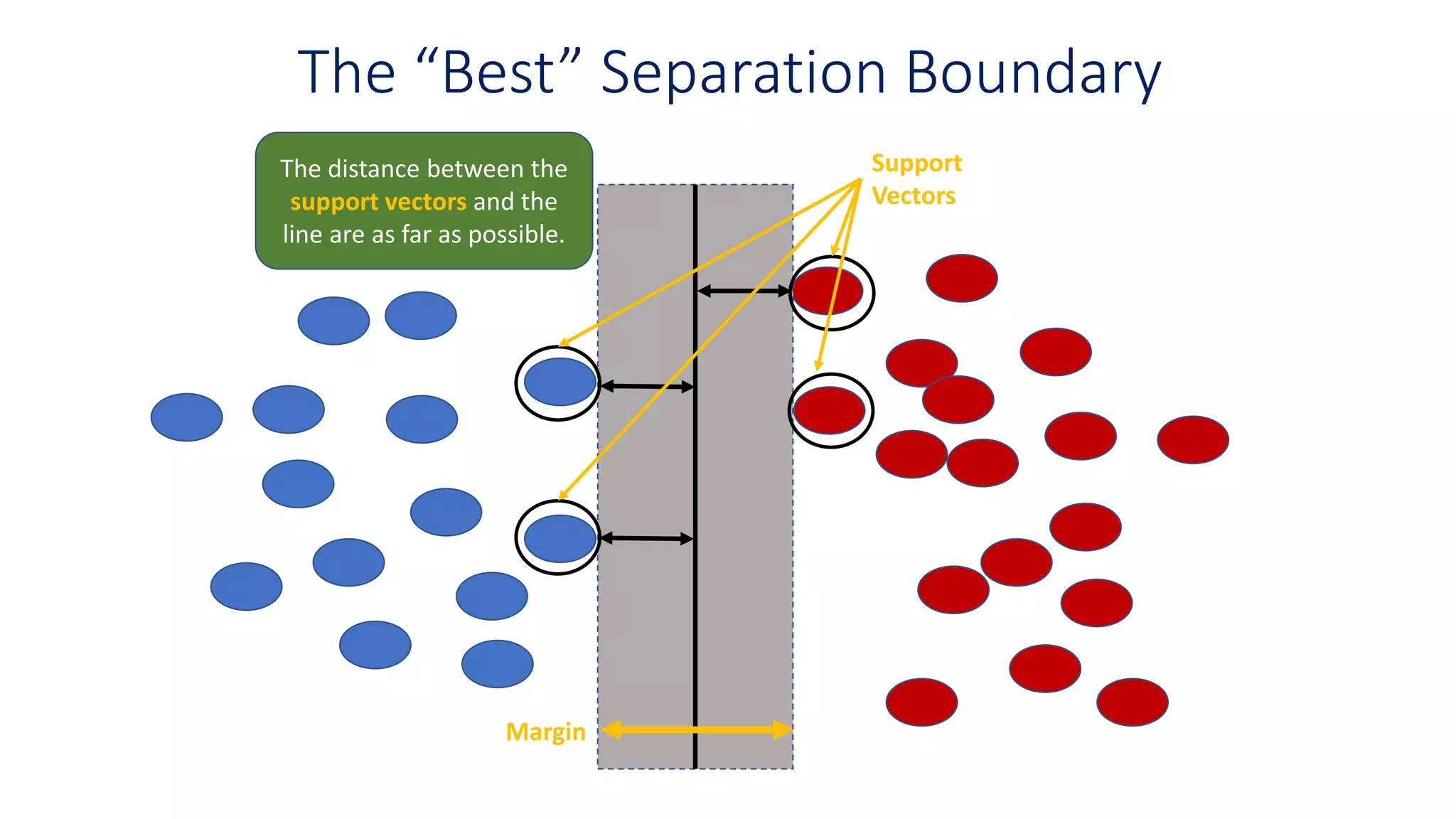
The “Best” SeparationBoundary
The distance between the
support vectors and the
line are as far as possible.
Margin
Support
Vectors
14.
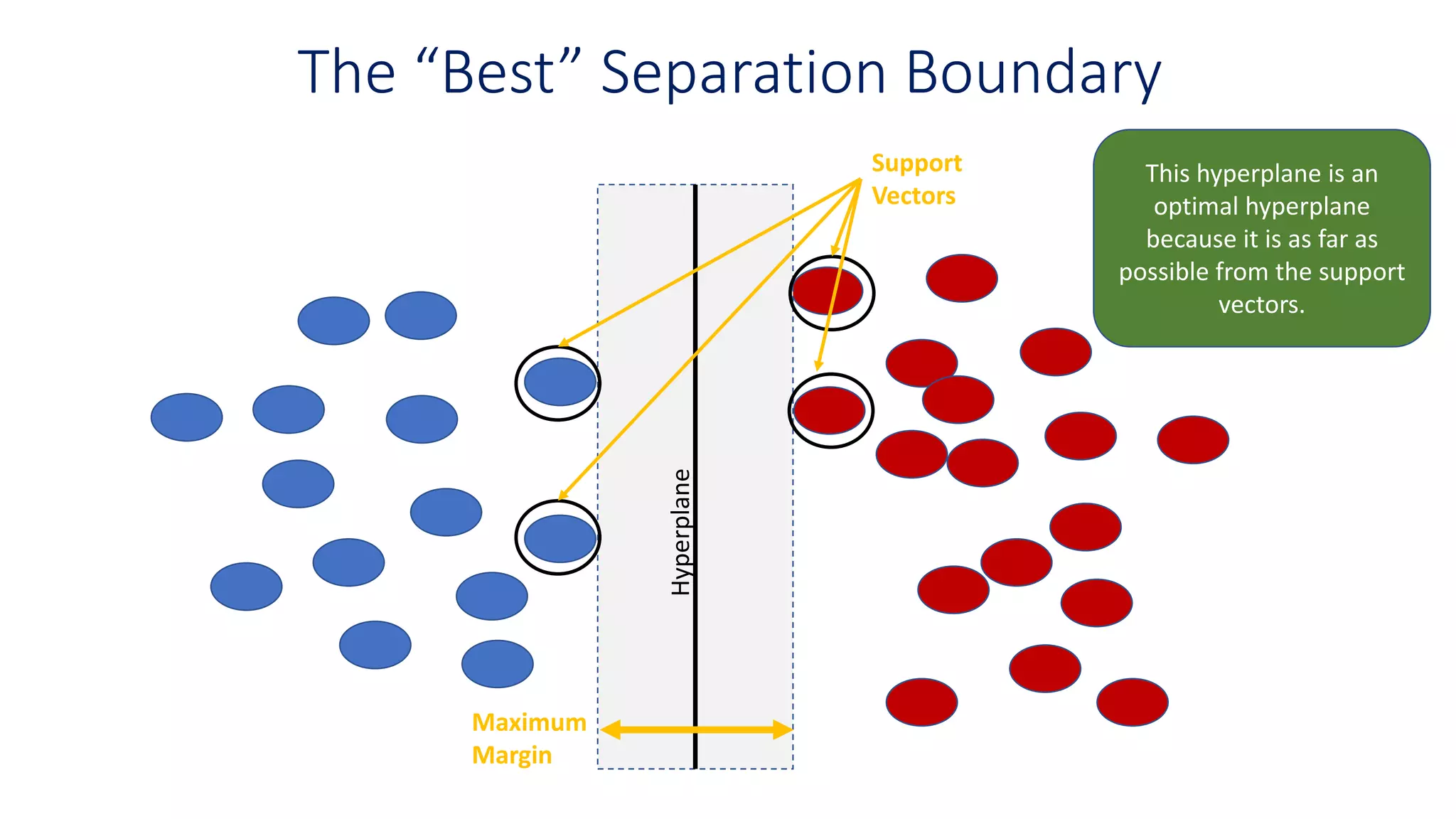
The “Best” SeparationBoundary
This hyperplane is an
optimal hyperplane
because it is as far as
possible from the support
vectors.
Maximum
Margin
Support
Vectors
Hyperplane
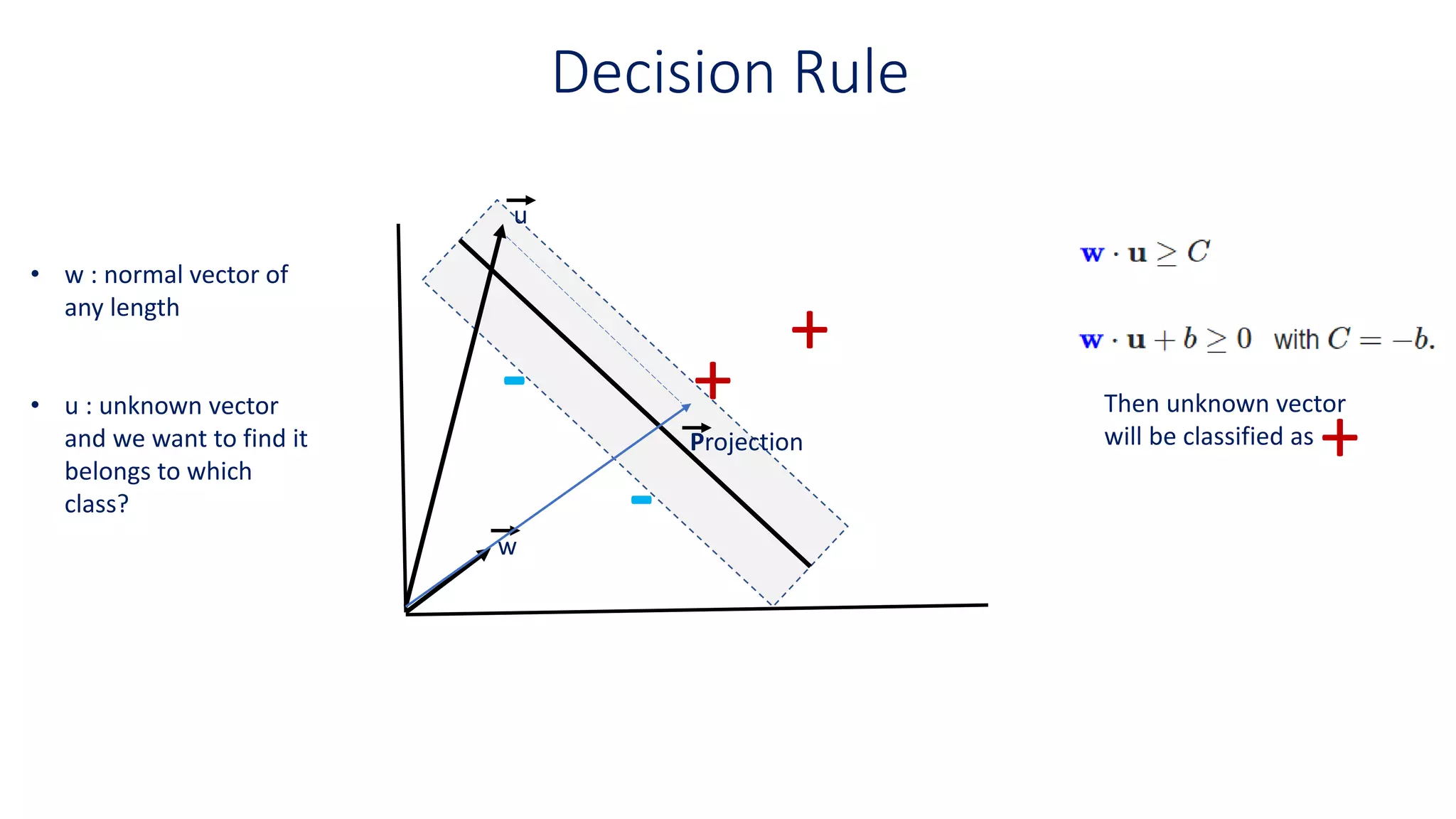
Decision Rule
+
+
-
-w
u
Projection
• w: normal vector of
any length
• u : unknown vector
and we want to find it
belongs to which
class?
Then unknown vector
will be classified as
+
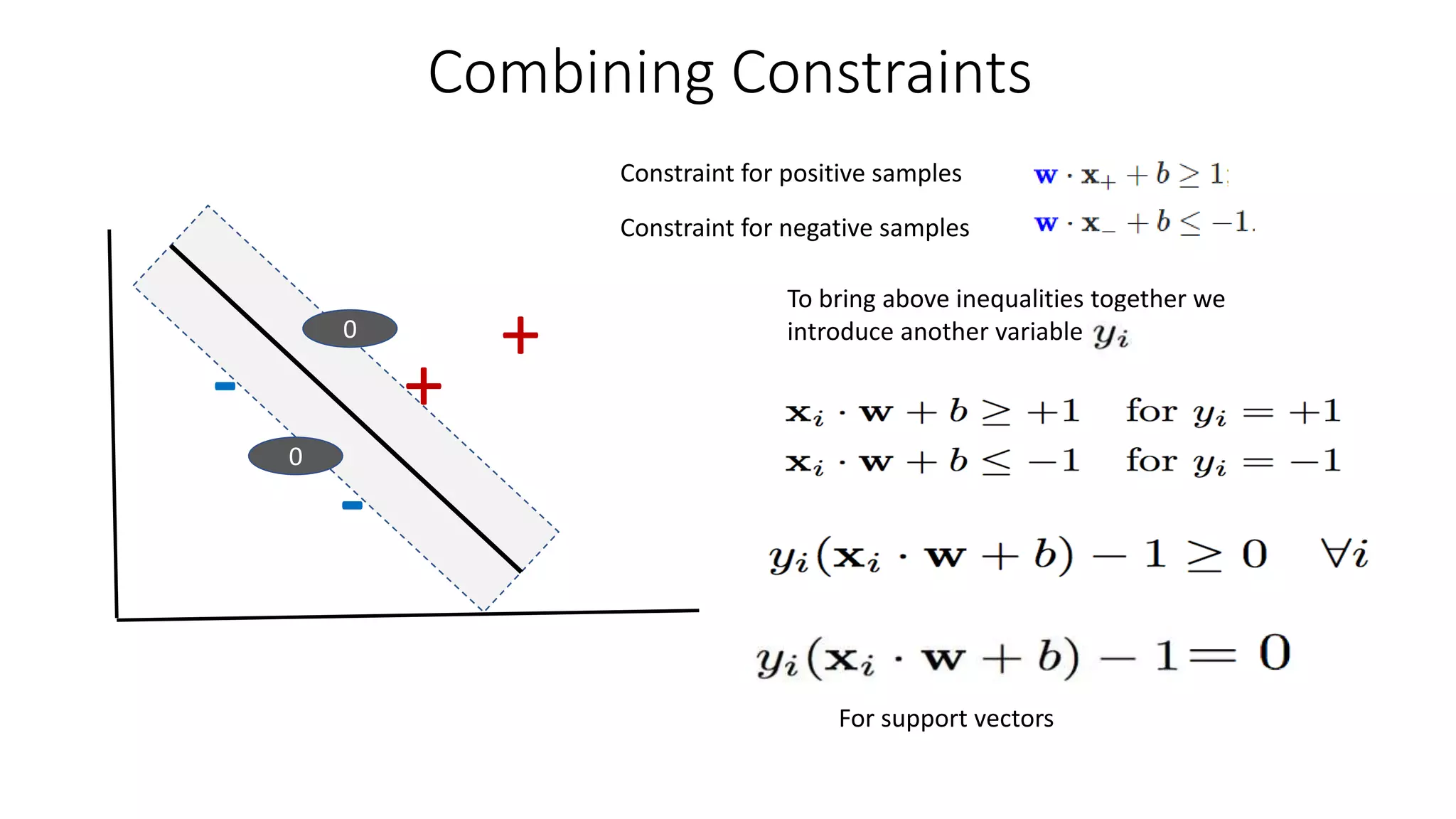
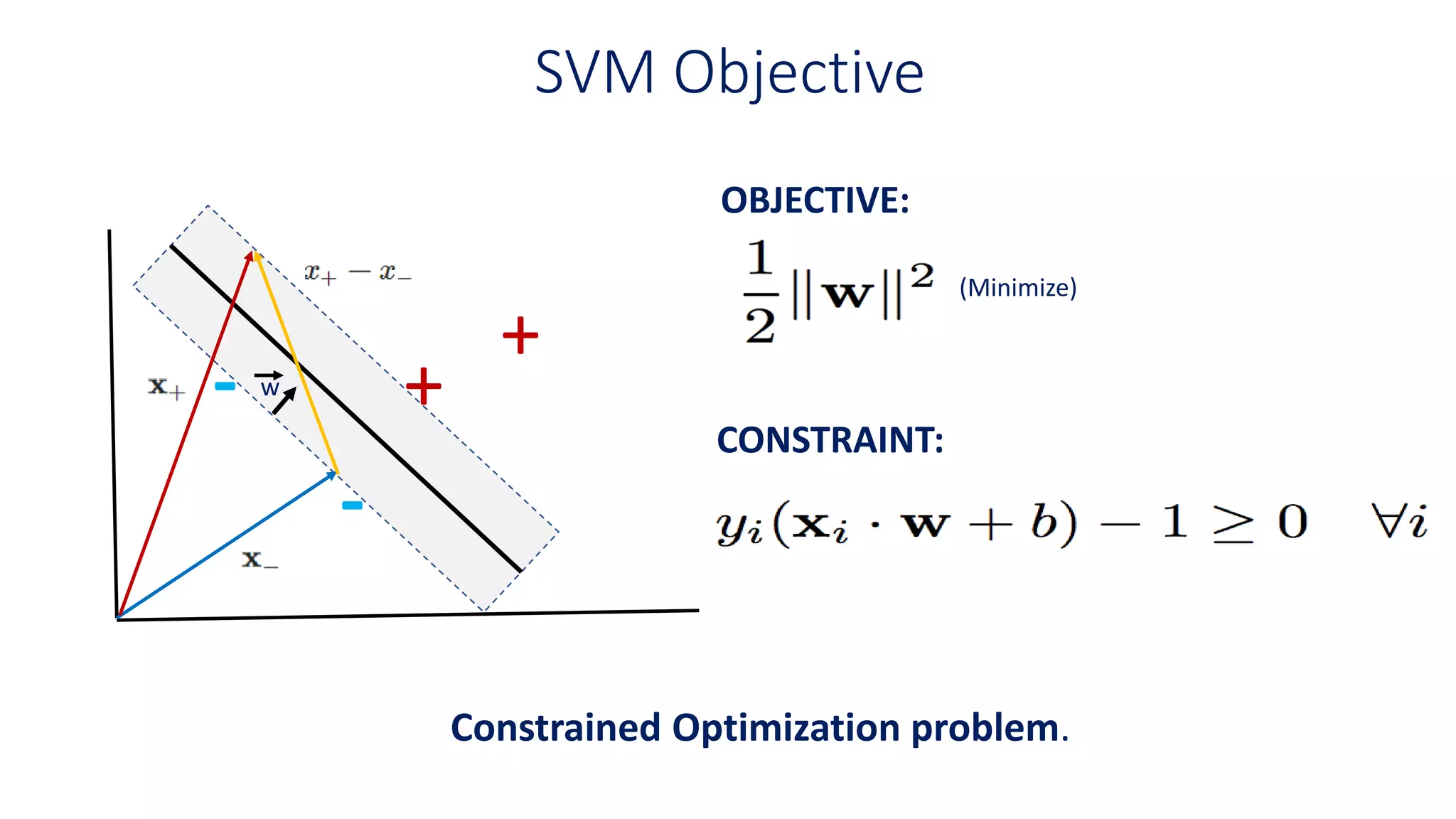
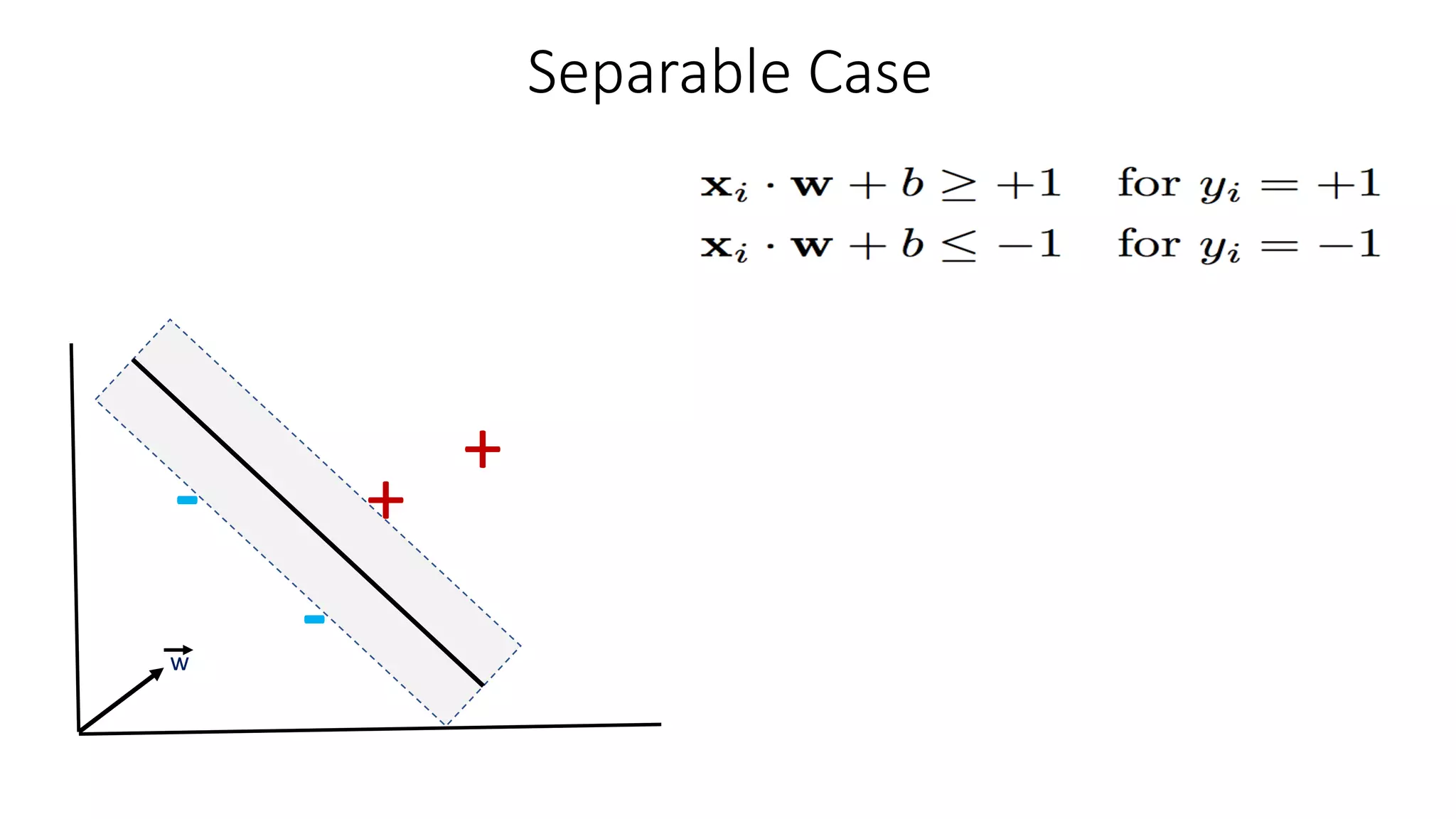
Combining Constraints
+
+
-
-
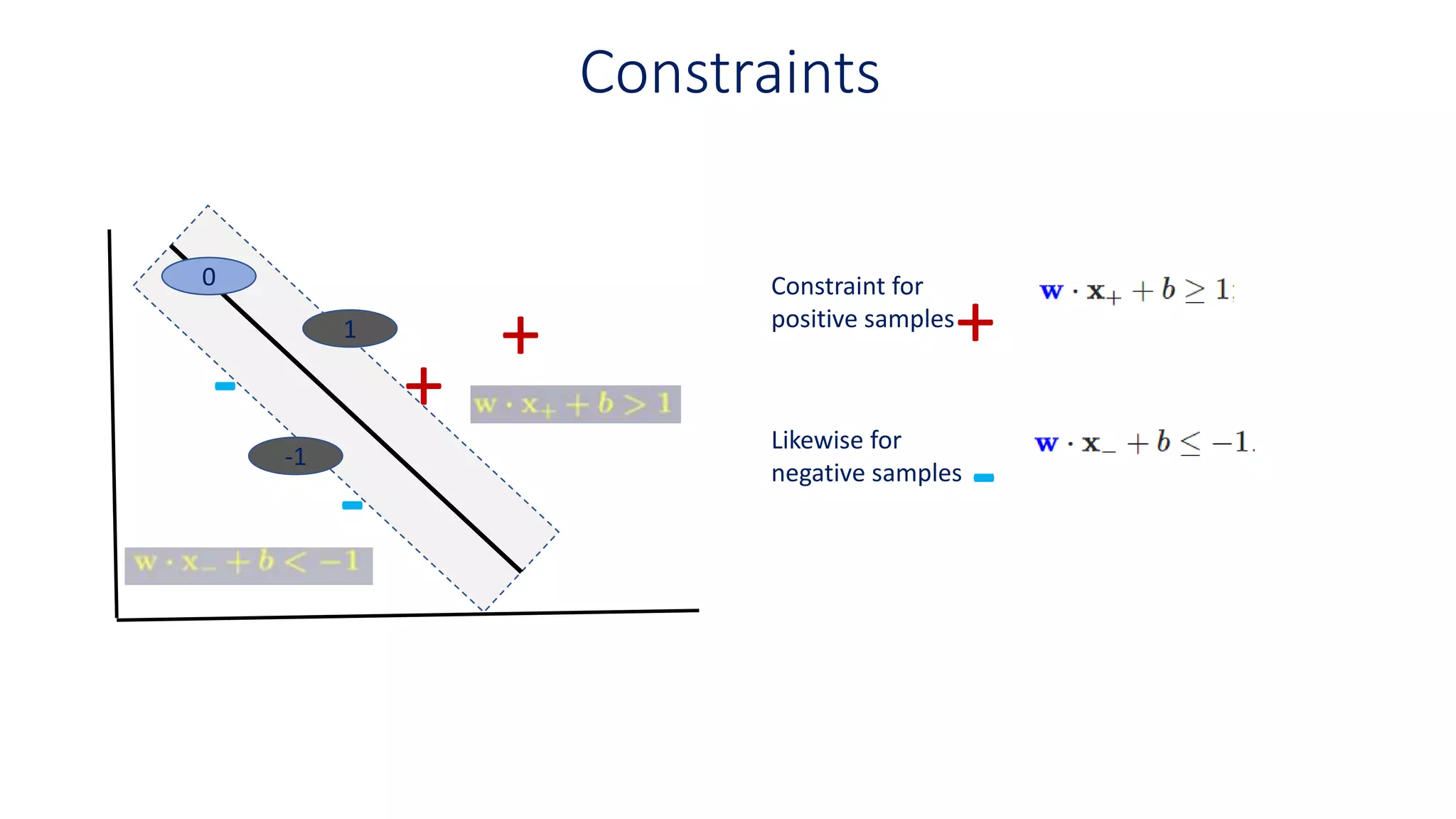
Constraint forpositive samples
Constraint for negative samples
0
0
To bring above inequalities together we
introduce another variable
For support vectors
19.
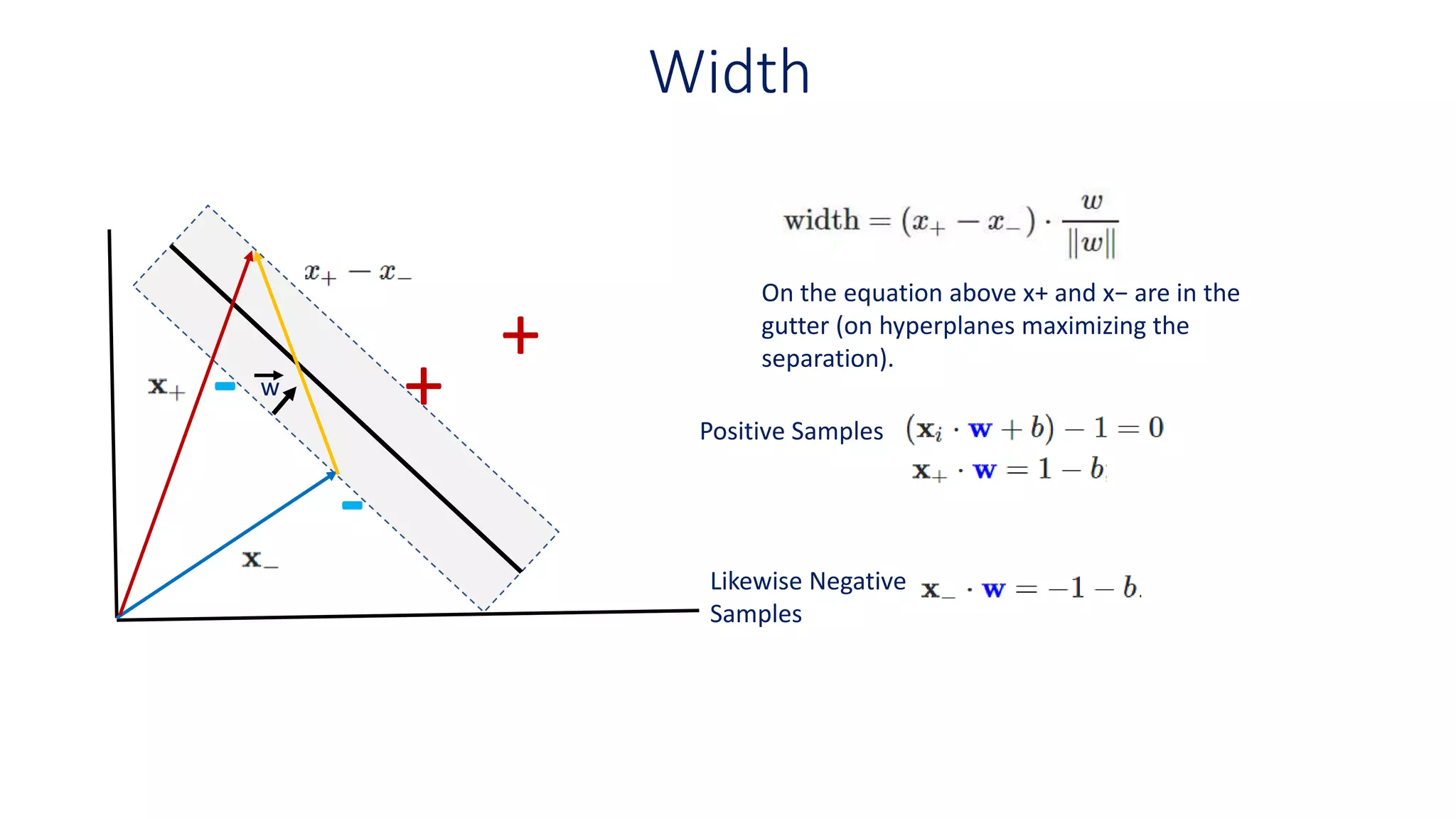
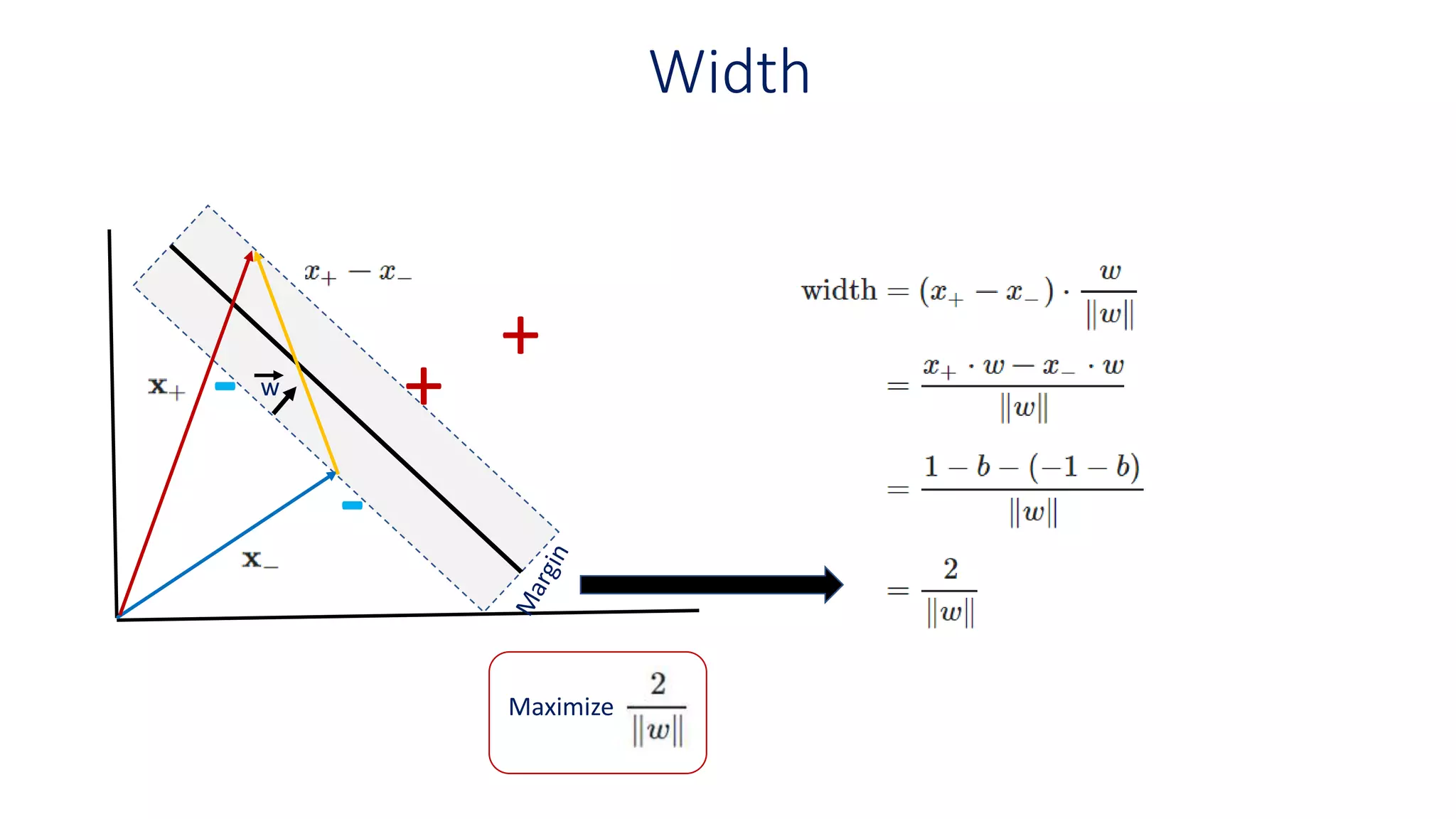
Width
+
+
-
-
w
On the equationabove x+ and x− are in the
gutter (on hyperplanes maximizing the
separation).
Positive Samples
Likewise Negative
Samples
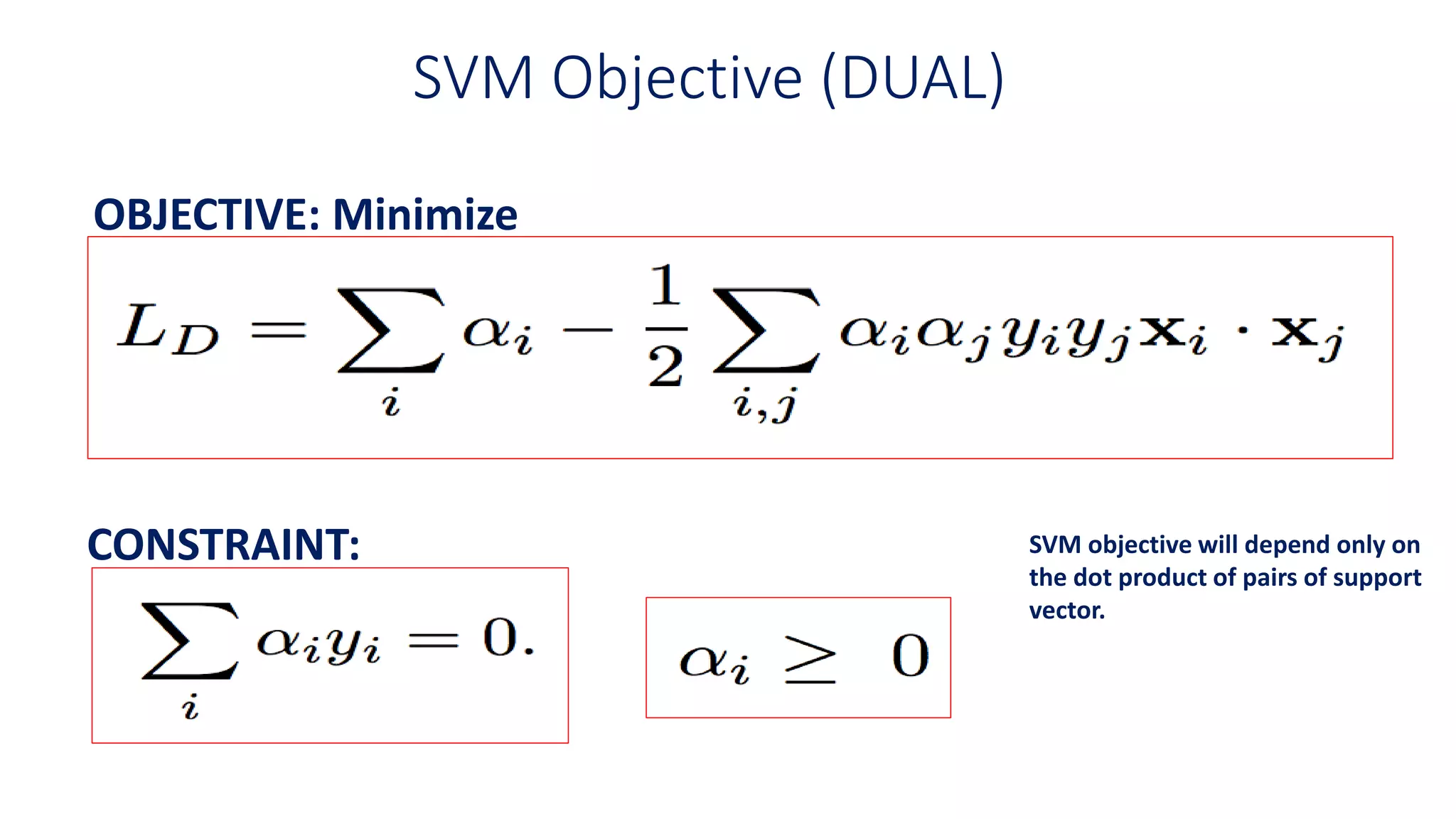
SVM Objective (DUAL)
OBJECTIVE:Minimize
CONSTRAINT: SVM objective will depend only on
the dot product of pairs of support
vector.
26.
Decision Rule
So whethera new sample will be
on the right of the road depends
on the dot product of the
support vectors and the
unknown sample.
27.
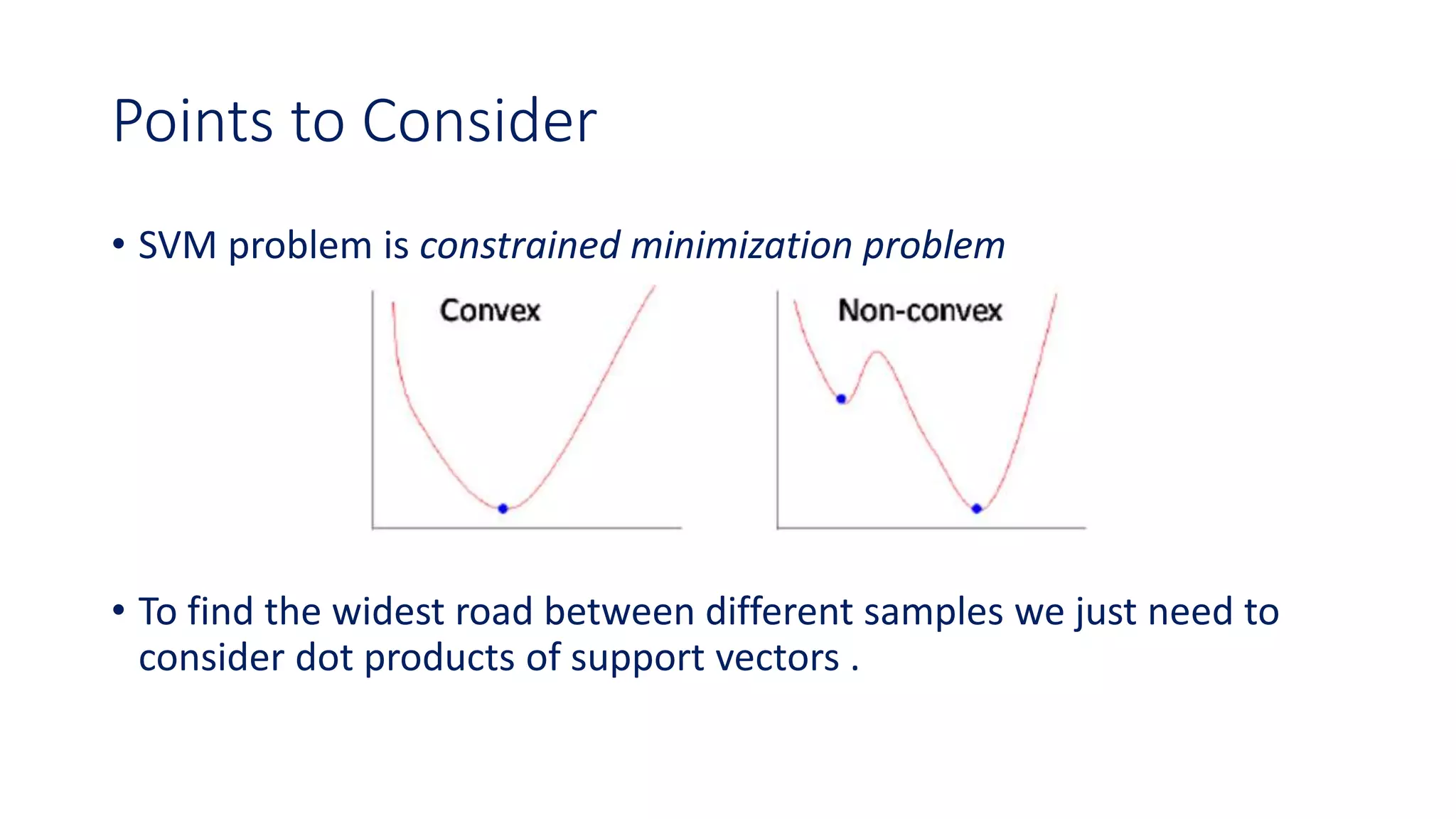
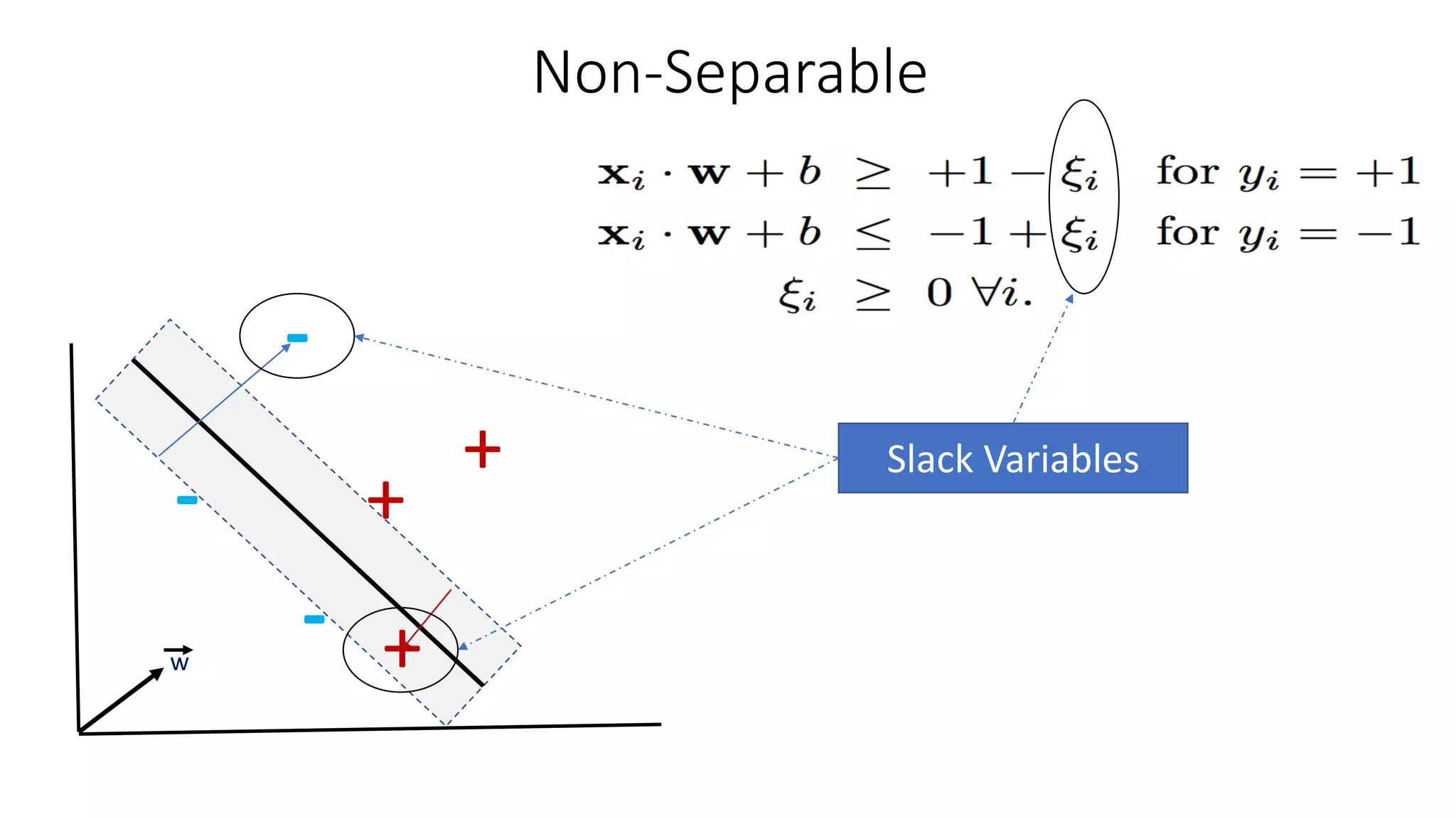
Points to Consider
•SVM problem is constrained minimization problem
• To find the widest road between different samples we just need to
consider dot products of support vectors .
Increasing Model Complexity
•Non linear dataset with n features (~n-dimensional)
• Match the complexity of the data by the complexity of the model.
Linear Classifier ?
• Improve accuracy by transforming
input feature space.
For datasets with a lot of features,
it becomes next to impossible to try out all
interesting transformations.
https://www.youtube.com/watch?v=3liCbRZPrZA
35.
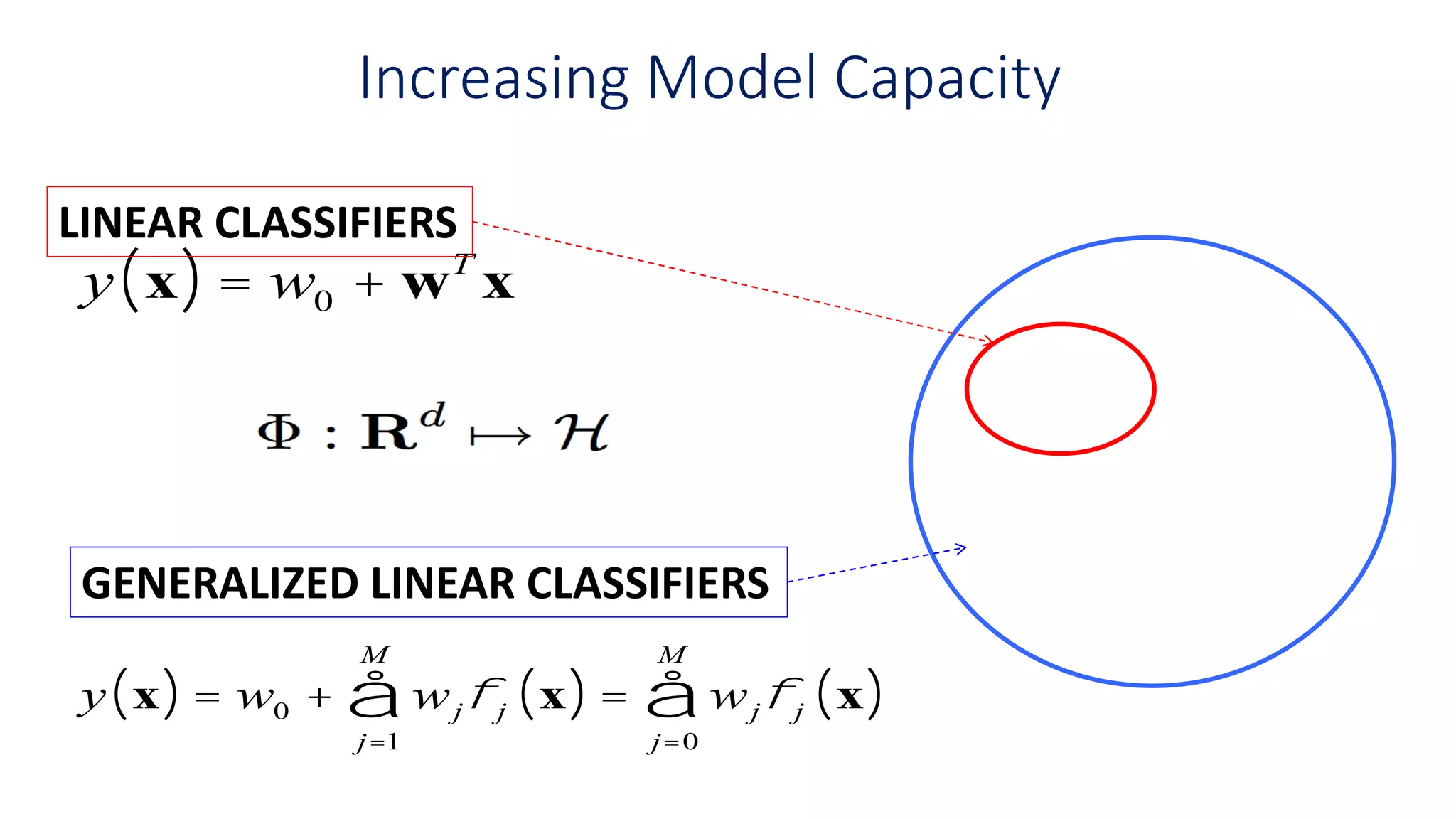
Increasing Model Capacity
yx( ) = w0 + wT
x
y x( ) = w0 + wjfj x( )
j=1
M
å = wjfj x( )
j=0
M
å
LINEAR CLASSIFIERS
GENERALIZED LINEAR CLASSIFIERS
36.
KERNEL TRICK
y x() = w0 + wT
x
y x( ) = w0 + wjfj x( )
j=1
M
å
LD = ai -
1
2
aia j yi yjf xi( )f x j( )i, j
å
i
å
LD = ai -
1
2
aia j yi yjxix j
i, j
å
i
å
37.
Kernel Trick
• Fora given pair of vectors (in a lower-dimensional feature space) and
a transformation into a higher-dimensional space, there exists a
function (The Kernel Function) which can compute the dot product in
the higher-dimensional space without explicitly transforming the
vectors into the higher-dimensional space first
LD = ai -
1
2
aia j yi yjf xi( )f x j( )i, j
å
i
å
K xi , x j( ) = f xi( )f x j( )
KERNEL FUNCTION
LD = ai -
1
2
aia j yi yj K xi ,x j( )i, j
å
i
å
SVM Hyperparameters
• ParameterC : Penalty parameter
• Parameter gamma : Specific to Gaussian RBF
• Large Value of parameter C => small margin
• Small Value of parameter C => Large margin
• Large Value of parameter gamma => small gaussian
• Small Value of parameter gamma => Large gaussian








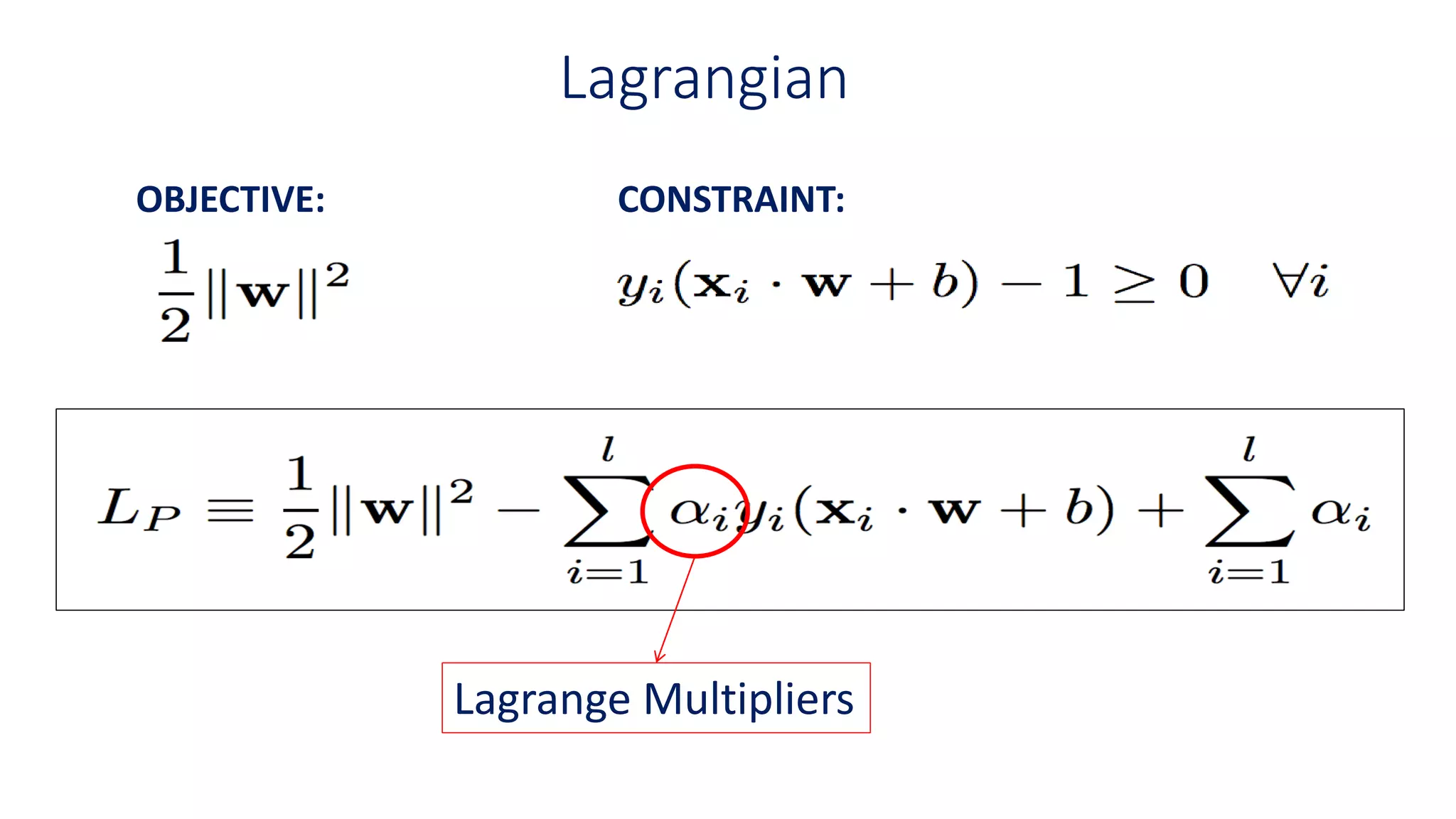



















































![SVM[Support vector Machine] Machine learning](https://cdn.slidesharecdn.com/ss_thumbnails/svm-250403184638-1cd9afdb-thumbnail.jpg?width=640&height=640&fit=bounds)






























