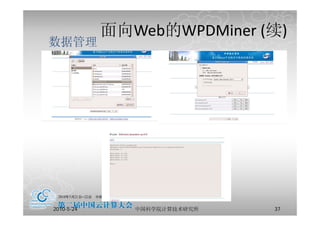
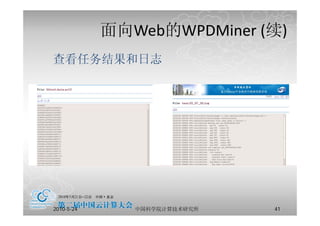
云计算的定义
• Wikipedia: Cl d computing i I
Wiki di Cloud i is Internet‐based
b d
computing, whereby shared resources, software
and information are provided to computers and
other devices on‐demand, like the electricity grid.
It describes a new supplement, consumption and
delivery model for IT services based on the Internet,
and it typically involves the provision of dynamically
scalable and often virtualized resources as a service
scalable and often virtualized resources as a service
over the Internet
2010-5-24 3
中国科学院计算技术研究所
4.
云计算的定义
• 云计算是一种基于互联网的、大众参与的计算模式,
云计算是 种基于互联网的 大众参与的计算模式
其计算资源(计算能力、存储能力、交互能力)是
动态、可伸缩、且被虚拟化的,以服务的方式提供
• 云计算是并行计算(Parallel Computing)、分布式计算
(Distributed Computing)和网格计算(Grid C
(Di ib d C i )和网格计算(G id Computing)
i )
的发展,或者说是这些计算机科学概念的商业实现
• 云 计 算 是 虚 拟 化 (Virtualization) 、 效 用 计 算 (Utility
Computing)、IaaS(基础设施即服务)、PaaS(平台即服
务)、SaaS(软件即服务)等概念混合演进并跃升的结
务) S S(软件即服务)等概念混合演进并跃升的结
果
2010-5-24 4
中国科学院计算技术研究所
参考资料
• J Dean and S Ghemawat: Mapreduce: Simplified Data
J. Dean and S. Ghemawat: Mapreduce: Simplified Data
Processing on Large Clusters, OSDI’04
• C. T. Chu, S. K. Kim, Y.A. Lin, Y. Y. Yu, G. Bradski, A. Y. Ng: Map‐
, , , , , g p
Reduce for Machine Learning on Multicore, NIPS’06
• C. Ranger, R. Raghuraman, A. penmetsa, G. Bradski, C.
Kozyrakis: Evaluating MapReduce for Multi‐core and
Multiprocessor System, HPCA’07
• E. Y. Chang, K.Z. Zhu, H. Wang, H. Bai: Psvm: Parallelizing
support vector machines on distributed computers, NIPS’07
• H. C. Yang, A. Dasdan, R. L. Hsiao, D. S. P: Map‐reduce‐
d d
merge: simplified relational data processing on large clusters,
Sigmod07
2010-5-24 45
中国科学院计算技术研究所
46.
参考资料
• T. Elsayed, J. Lin, D. W. Oard: Pairwise Document Similarity in
y , , y
Large Collections with MapReduce, ACL’08
• W.Z. Zhao, H. F. Ma, Q, He: Parallel K‐Means Clustering Based
on MapReduce, CloudCom’09
• C. Liu, H. C. Yang, J. L. Fan, L. W. He, Y. M. Wang: Distributed
Nonnegative Matrix Factorization for Web‐Scale Dyadic Data
Analysis on MapReduce, WWW’10
• h //l b
http://labs.google.com/papers/mapreduce.html
l / / d h l
• http://lucene.apache.org/hadoop
• h //
http://en.wikipedia.org/wiki/Cloud_computing
k d / k/ l d
2010-5-24 46
中国科学院计算技术研究所
47.
参考资料
• http://csrc.nist.gov/groups/SNS/cloud‐computing/index.html
p // g /g p / / p g/
• http://rgrossman.com/about‐cloud‐computing/
• http://www.ibm.com/developerworks/cn/java/j‐mahout/
p // / p / /j /j /
• http://www.infoq.com/news/2010/04/mahout‐03
2010-5-24 47
中国科学院计算技术研究所