Buffer Pool 设置
innodb_buffer_pool_size设置BufferPool的大小。
建议将除了连接使用的内存,操作系统使用的内存
之外的全部内存给Buffer Pool,不要靠操作系统的
OS Cache来缓冲缓存数据。
经验参考值:
n 48G内存:32G Buffer Pool
n 32G内存:20G Buffer Pool
n 24G内存:16G Buffer Pool
n 16G内存:10G Buffer Pool
JOIN 算法概述
Ø MySQL只有一 JOIN算法:Nested Loop Join
Ø Nested Loop Join:选择一张驱动表,用 联字
段循环匹配被驱动表
! FOR EACH ROW row1 IN table1 {
! FOR EACH ROW row2 IN table2 IF( 联条件) {
! result := row1 || row2;
! OUTPUT result;
! } }
Ø 支持条件下推(Push Down):先用条件过滤驱动
表和被驱动表,再把过滤后的结果集进行JOIN
67.
内连接
Ø 假定我们有一个如下形式的表T1、T2、T3的联
接查询:SELECT * FROM t1 INNER JOIN t2 ON c1(t1,t2) INNER JOIN
t3 ON c2 (t2,t3) WHERE c(t1,t2,t3)
Ø MySQL首先由优化器判定JOIN顺序,假设生成
执行计 为t1驱动t2驱动t3:
! FOR EACH ROW row1IN t1 IF (c(t1)){
! FOR EACH ROW row2 IN t2 IF (c1(t1,t2) && c(t2)) {
! FOR EACH ROW row3 IN t3 IF (c2(t2,t3) && c(t3)) {
! result := row1 || row2 || row3;
! OUTPUT result;
! } } }
Ø 将行传给下一层被驱动表匹配时,先用条件进行
过滤, 少参与JOIN的行数
68.
外连接
Ø SQL同前例:
! FOR EACH ROW row1 IN t1 IF c1(t1) {
! BOOL f1 := FALSE;
! FOR EACH ROW row2 IN t2 IF c1(t1,t2) AND (f1 ? c2(t2) : TRUE) {
! BOOL f2 := FALSE;
! FOR EACH ROW row3 IN t3 IF c2(t2,t3) AND (f1&&f2 ? c3(t3) : TRUE) {
! IF (f1&&f2 ? TRUE : (c2(t2) AND c3(t3))) {
! result := row1 || row2 || row3; OUTPUT result; }
! f2 := TRUE; f1 := TRUE; }
! IF (!f2) {
! IF (f1 ? TRUE : c2(t2) && c(t1,t2,NULL)) {
! result := row1 || row2 || NULL; OUTPUT t; }
! f1 := TRUE; } }
! IF (!f1 && c(t1,NULL,NULL)) {
! result := row1||NULL||NULL; OUTPUT t; } }
Ø 经过测试,三张10000行的表用外连接平均比内
连接慢0.01s,内连接效率高于外连接。
MySQL 优化器概述
Ø MySQL优化器属于RBO(基于规则的优化器),
5.1版本后带有少量的CBO(基于 销的优化器)
特性。
Ø MySQL优化器缺陷:
n 不支持函数索引:WHERE func(col) = x 无法使用col字段上
的索引
n 不支持索引过滤 (Index Filter) 但支持索引覆盖扫描:
n SELECT col1,col2,col3,col4 FROM t WHERE col1 > x AND col2 < y AND col3 >z; 无法利用
(col1,col2,col3)索引过滤col2和col3,需要回表查询。
n SELECT col1,col2,col3 FROM t WHERE col1 > x AND col2 < y AND col3 >z; 可以利用
(col1,col2,col3)索引扫描到col1,col2,col3的值不用回表。
n 无法自动优化子查询:MySQL无法将子查询优化为JOIN方式,
而是将子查询存为临时表(无索引),在外层SQL需要时调
用临时表数据进行匹配,这是效率非常低的执行方式,所以
尽量避免在SQL中使用子查询。
MySQL 优化器判定算法
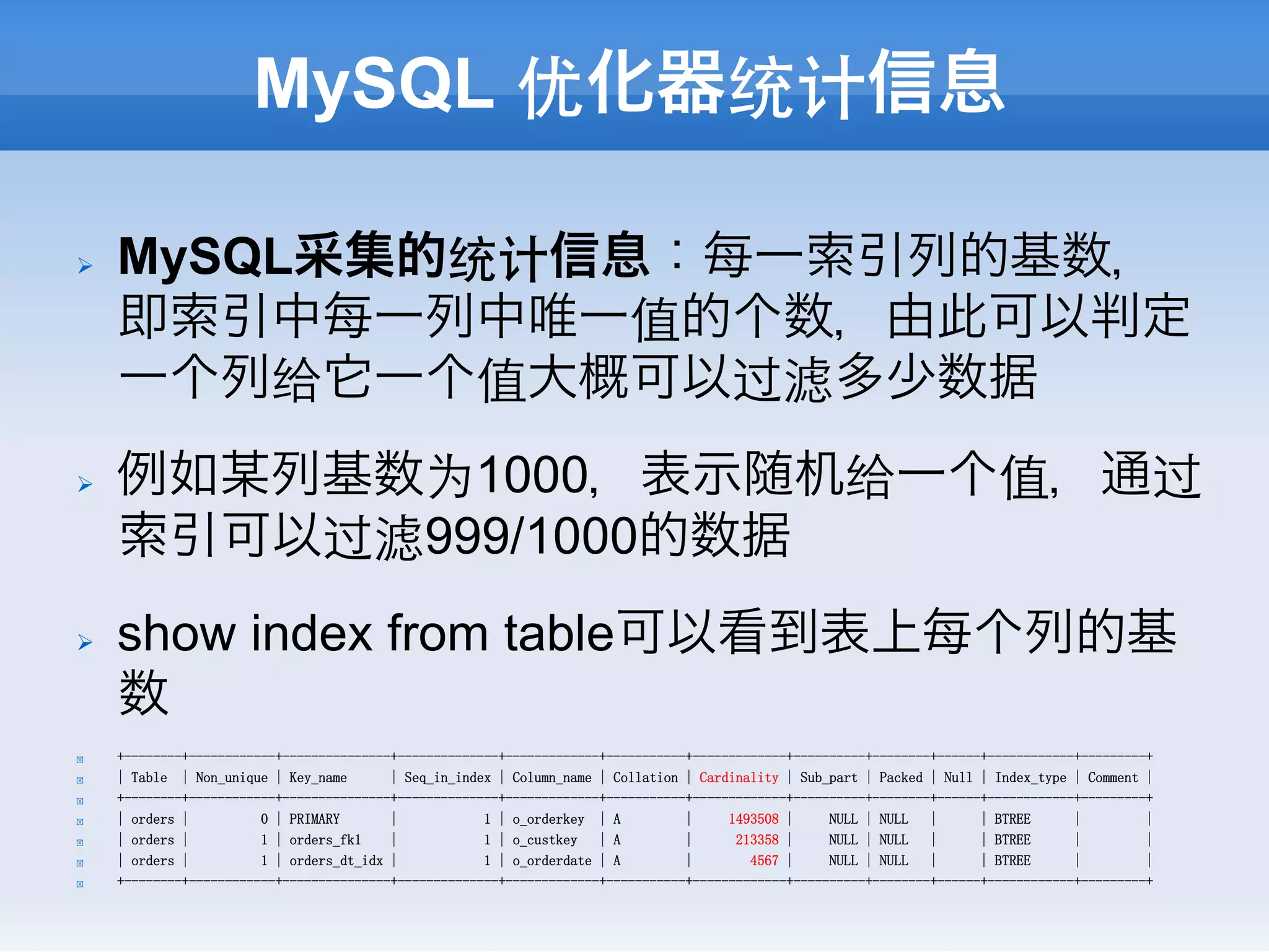
Ø MySQL利用索引的原则:尽可能用主键索引>尽
可能筛去更多的数据>尽可能使用⻓长度小的索引>
尽可能使用更多索引列。
! idx_Col1索引⻓长度368,过滤基数9000
! idx_Col3索引⻓长度128,过滤基数3000
! idx_Col1_Col2索引⻓长度768,过滤基数11000
! idx_Col2_Col3索引⻓长度255,过滤基数 9000
! SELECT Col1, Col2, Col3 FROM t WHERE col1 = x AND col2 = y AND col3
= z;
! 优先使用idx_Col2_Col3索引,因为过滤基数差不多,索引⻓长度小得多。
! SELECT Col1, Col2, Col3 FROM t WHERE col1 = x AND col3 = z;
! 优先使用idx_Col1索引,因为col1过滤基数远大于col3,而idx_Col1_Col2因
为索引⻓长度⻓长的多过滤基数却相近则不被使用















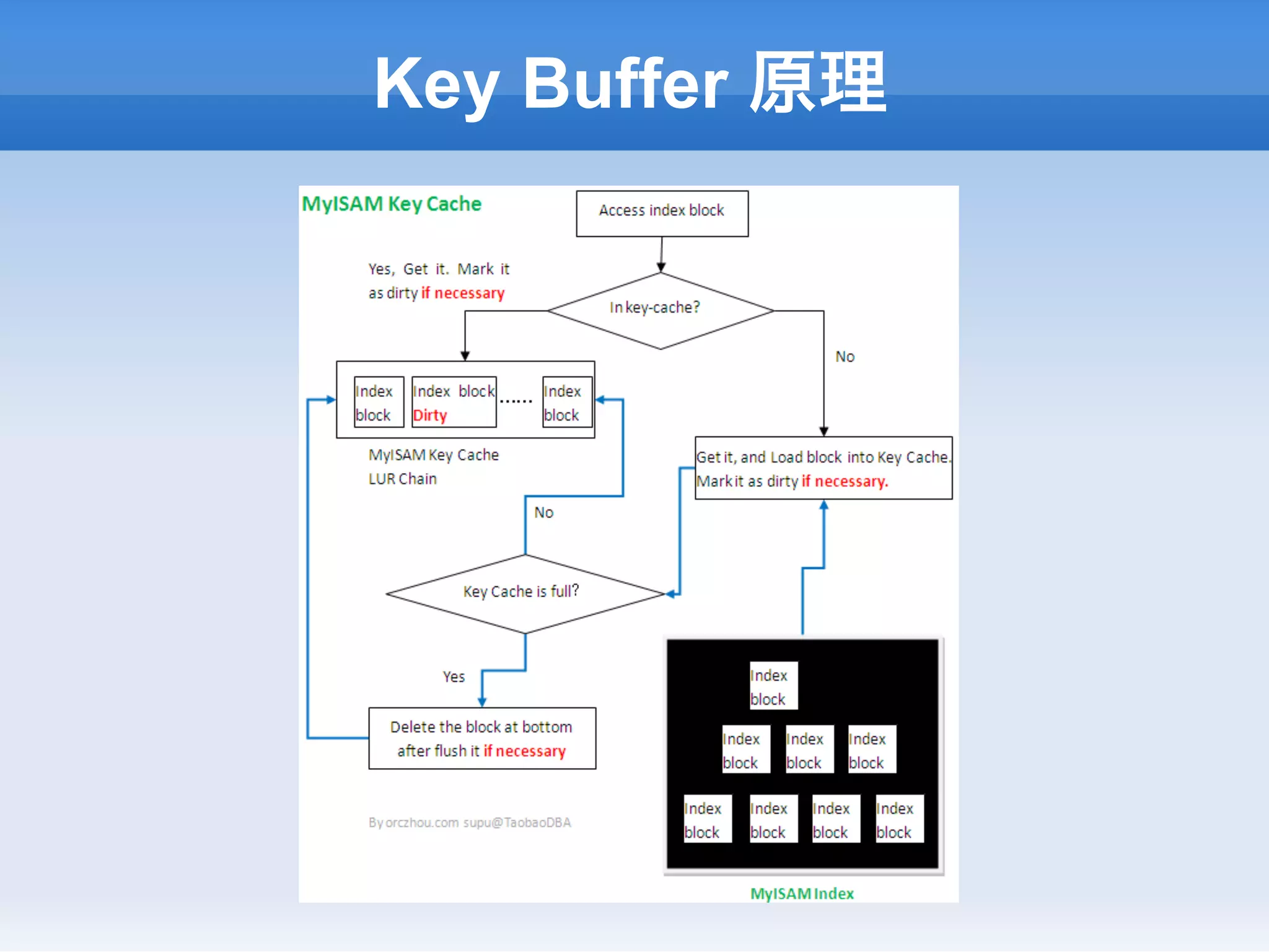
![MyISAM 并发插入
虽然MyISAM是表锁,但是如果只在数据文件末尾
插入数据,是可以并发的,通过concurrent_insert
变量控制:
n 0 – (Off):不允许并发插入
n 1 – (Default):如果数据文件没有空洞,可以在数据文件末尾并发
插入
n 2 – Enable:如果表在被使用则在数据文件末尾并发插入,如果
表没有被使用则一样在文件中找空洞插入 [建议]](https://image.slidesharecdn.com/random-130121204343-phpapp01/75/MySQL-18-2048.jpg)














![InnoDB 事务提交
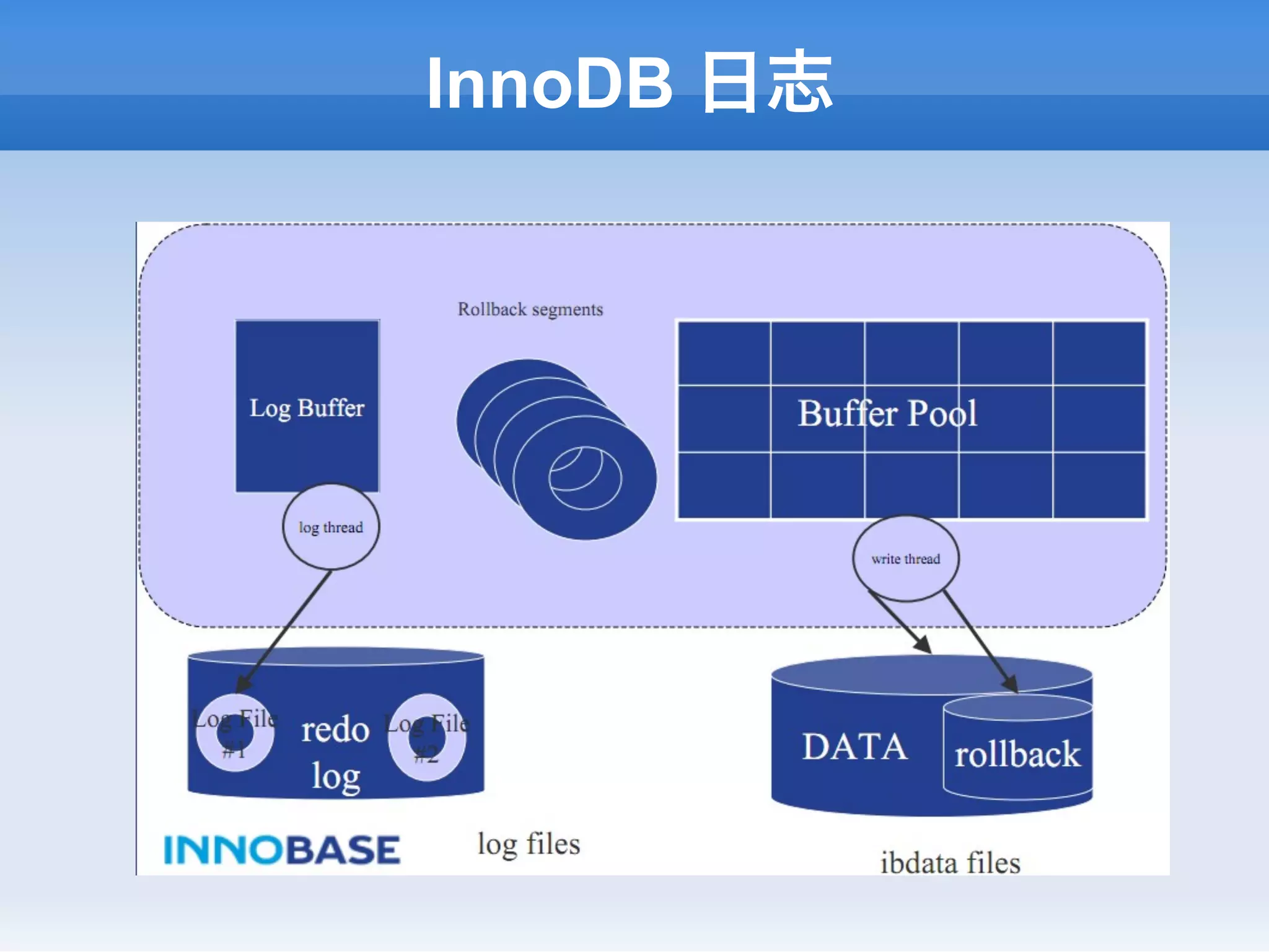
Ø Log Buffer中缓冲的日志在检查点或事务提交时
回写文件。
Ø Buffer Pool中的⻚页在检查点时回写磁盘。
Ø innodb_flush_log_at_trx_commit控制回写:
n 0: 每秒刷新日志到文件(不是磁盘)
n 1: 每次事务提交刷新日志到磁盘 [default]
n 2: 每次事务提交刷新日志到文件,每秒同步到磁盘 [建议]](https://image.slidesharecdn.com/random-130121204343-phpapp01/75/MySQL-40-2048.jpg)
![日志大小设置
Ø 更大的事务日志意味着什么?
n 可以记录更大的事务信息 [可以重做更大的事务]
n 可以记录更⻓长的事务历史 [可以重做更多的事务]
n 更少的检查点 [ 少磁盘IO]
n 更⻓长的 时间 [宕机重启时间更⻓长]
Ø 经验参考值:
n 64M的日志5分钟以内就可以
n 1G的日志全部重做需要30分钟以上
n 我们设置为3个1G的日志](https://image.slidesharecdn.com/random-130121204343-phpapp01/75/MySQL-41-2048.jpg)












![Query Cache 设置
Ø 配置参数:
n query_cache_type:
n OFF:不对SELECT结果集缓存
n ON:对SELECT结果集缓存 [默认]
n DEMAND:只有当SELECT语句中显示写明“SQL_CACHE”时候才对
结果集缓存 [推荐]
n query_cache_size:Query Cache大小
n query_cache_limit:可缓存的最大结果集,默认1MB
n query_cache_min_res_unit:内存分配最小单位,默认4KB
Ø 经验参考值:
n InnoDB应该 闭QCache,因为InnoDB有MVCC
n MyISAM如果 实数据很少变化,可以测试常用SQL的结果集
大小,设置为最常用的SQL的结果集](https://image.slidesharecdn.com/random-130121204343-phpapp01/75/MySQL-54-2048.jpg)

























![可选方案
Ø 水平拆分
l 相同拆分键的数据在一起
l 同一分区键的数据可以JOIN
Ø 垂直拆分
l 可以不分库
l 功能之间调用只能使用程序接口
Ø 中间件
l 自动分库,对应用透明
l 扩展不 活
l 发难度较大,不适合中小企业
Ø 程序分库[推荐]
l 可自定义分库规则
l 活扩展
l 无需中间件,直连数据库](https://image.slidesharecdn.com/random-130121204343-phpapp01/75/MySQL-82-2048.jpg)














































































