More Related Content

PPTX

PPTX

PPTX

PPTX

PPTX

PPTX

PPTX

PPTX
What's hot

PPTX

PPTX

PPTX

PPTX

PPTX
Robot frontier lesson3 2018 
PDF

PDF
2014年5月21日「パーティクルフィルタの癖から知るロボットへの確率的手法の正しい適用方法」---第58回システム制御情報学会研究発表講演会チュートリアル講演 
PDF
LL Ring Recursive ライトニングトーク 
PPTX

PPTX
Robot frontier lesson1 2018 
PPTX
Robot frontier lesson2 2018 
PPTX

PPTX
More from Ryuichi Ueda

PPTX
PythonとJupyter Notebookを利用した教科書「詳解確率ロボティクス」の企画と執筆 
PPTX

PPTX

PPTX

PPTX
第32回信号処理シンポジウム「Raspberry PiとROSを�使ったロボットシステム」 
PPTX

PPTX
シェル芸勉強会にみる、コミュニティを通じたIT学習 
PPTX

PPTX

PDF
poster of PFoE used in ICRA 2018 
PPTX
2017年10月18日 シェル芸勉強会 meets バイオインフォマティクス vol.1 スライド 
PPTX

PPTX

PPTX

PPTX
direct use of particle filters for decision making 
PPTX
Searching Behavior of a Simple Manipulator only with Sense of Touch Generated... 
PPTX

PPTX

PDF

PPTX
確率ロボティクス第九回
- 1.
- 2.
- 3.
- 4.
- 5.
問題の例
• スイカ割り
– 自分とスイカの相対姿勢がはっきり分からない
–他者からの情報で
• スイカ割り(目隠しをしなくても)
– 実は目隠しをしなくても相対姿勢が絶対的に
分かっているわけではない
– 単なる程度の問題で、実世界では常に不確かさが伴う
– ロボットにやらせると大変でしょう?
• 枠組みや問題の複雑さを知っておくことが設計の際に重要
Oct. 7, 2015 確率ロボティクスと移動ロボットの行動生成 5
- 6.
- 7.
- 8.
- 9.
問題の大きさ
• 状態が100個、行動が2種類の場合
• MDP
–方策のパターンは2^100通り
– 価値反復を使うと
O(状態数・行動数・タスクの長さ)
で方策を1個選ぶことができる
• POMDP
– belは100個の上で定義される関数
• 無限に存在
– 無限にあるものに対する方策のパターンは無限
Oct. 7, 2015 確率ロボティクスと移動ロボットの行動生成 9
- 10.
- 11.
- 12.
- 13.
- 14.
方法1(AMDPと呼ばれる手法群)
• 信念の数を有限個に近似
• 例[Roy99]
– 距離センサを持つ移動ロボットのナビゲーション問題
– 4次元の状態空間を作る
• xyqを離散化
• 位置推定の分布がどれだけ曖昧か数値化して離散化
• 状態遷移はなんとか計算
– 得られる行動
• 自己位置が分からなくならないように壁沿いを走る
Oct. 7, 2015 確率ロボティクスと移動ロボットの行動生成 14
- 15.
方法2(QMDP, 他)
• MDPの計算結果を利用する
–状態遷移の法則性が分かっているが、ロボットが
自分の状態を完全に分からない場合に使える
• 例[Littman95]
– 確率密度関数belと価値関数Vから価値の
期待値を計算
Oct. 7, 2015 確率ロボティクスと移動ロボットの行動生成 15
- 16.
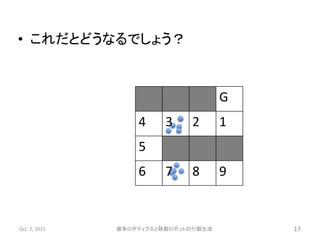
• 例
– 下のような碁盤の目の環境を考える
–1マスが1状態
– 行動は上下左右
– 同じ重みを持ったパーティクル10個が分布
– タスクはゴール(G)に
最短歩数で到達すること
– 数字はコスト
– 灰色のところに入ろうとすると
戻される
– 問題
• 一番「価値の高い」行動は?
Oct. 7, 2015 確率ロボティクスと移動ロボットの行動生成 16
3 2 1 G
4 3 2 1
5 4
6 5 6 7
- 17.
- 18.
probabilistic flow control[ueda2015]
•手前味噌ですが・・・
• 期待値計算において
「重み = パーティクルの重み/価値」とする
– ゴールに近いパーティクルが
行動決定に大きな影響を与える
• 投機的な行動が生成され、
ロボットがゴールを探すようになる
– ただしこれでもデッドロックは
発生する
• 問題を完全には解いていないので
• 研究は続く・・・
Oct. 7, 2015 確率ロボティクスと移動ロボットの行動生成 18
G
4 3 2 1
5
6 7 8 9
重み1/3
重み1/7
- 19.












![方法1(AMDPと呼ばれる手法群)
• 信念の数を有限個に近似
• 例[Roy 99]
– 距離センサを持つ移動ロボットのナビゲーション問題
– 4次元の状態空間を作る
• xyqを離散化
• 位置推定の分布がどれだけ曖昧か数値化して離散化
• 状態遷移はなんとか計算
– 得られる行動
• 自己位置が分からなくならないように壁沿いを走る
Oct. 7, 2015 確率ロボティクスと移動ロボットの行動生成 14](https://image.slidesharecdn.com/probrobotlesson9-151125062921-lva1-app6892/85/slide-14-320.jpg)
![方法2(QMDP, 他)
• MDPの計算結果を利用する
– 状態遷移の法則性が分かっているが、ロボットが
自分の状態を完全に分からない場合に使える
• 例[Littman95]
– 確率密度関数belと価値関数Vから価値の
期待値を計算
Oct. 7, 2015 確率ロボティクスと移動ロボットの行動生成 15](https://image.slidesharecdn.com/probrobotlesson9-151125062921-lva1-app6892/85/slide-15-320.jpg)

![probabilistic flow control[ueda2015]
• 手前味噌ですが・・・
• 期待値計算において
「重み = パーティクルの重み/価値」とする
– ゴールに近いパーティクルが
行動決定に大きな影響を与える
• 投機的な行動が生成され、
ロボットがゴールを探すようになる
– ただしこれでもデッドロックは
発生する
• 問題を完全には解いていないので
• 研究は続く・・・
Oct. 7, 2015 確率ロボティクスと移動ロボットの行動生成 18
G
4 3 2 1
5
6 7 8 9
重み1/3
重み1/7](https://image.slidesharecdn.com/probrobotlesson9-151125062921-lva1-app6892/85/slide-18-320.jpg)
