More Related Content

PPT

PDF

PDF

PDF

PDF

PDF

PDF

PDF
Mashup and new paradigm - マッシュアップ技術とインターネットの新しい潮流 What's hot

PDF
Authoring Tools Comparision in Detail 
PPTX
PHPカンファレンス2009 - 45分で分かる安全なWebアプリケーション開発のための発注・要件・検収 
PDF
【13-B-3】 企業システムをマッシュアップ型に変えるには 
PDF
XS Japan 2008 App Data Japanese 
PDF

PDF

PDF
XS Japan 2008 Ganeti Japanese 
PDF

PDF

PDF

PDF

PDF

PDF
Cloud for Enterprise IT (Japanese) 
PPTX

PDF

PDF

PDF

PDF

PDF
Talk In Point Of Gc Once In While Viewers also liked

PDF

PDF
Topical keyphrase extraction from twitter 
PDF
Joint inference of named entity recognition and normalization for tweets 
PDF

PDF
はてなブックマークのトピックページの裏側 in YAPC::Asia Tokyo 2015 
PDF
『BrandSafe はてな』のアドベリフィケーションのしくみ 
PDF

PDF
はてなブックマークに基づく関連記事レコメンドエンジンの開発 
PPTX
Rによる特徴抽出 第48回R勉強会@東京(#TokyoR) 
PDF
野澤陽介(Yosuke nozawa)|自己紹介スライド 2014ver 
PPTX

PDF
はてなブックマークの新機能における自然言語処理の活用 
PPTX
インターネッツの繋がるしくみ(TCP/IP編) #sa_study 
PDF
More from Naoya Ito

PDF
SmartPhone development guide with CoffeeScript + Node + HTML5 Technology, for... 
PPT

PPT
Scripting Layer for Android + Perl 
PPT
Web-Gakkai Symposium 2010 
PPT
Introduction to Algorithms#24 Shortest-Paths Problem 
PPT
090518computing Huffman Code Length 
PPT

PPT

PPT

PPT

PPT

PPT

PPT
はてなブックマークのシステムについて
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
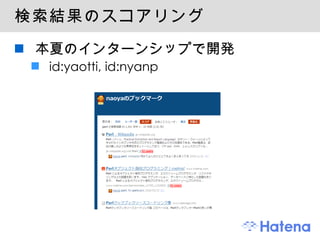
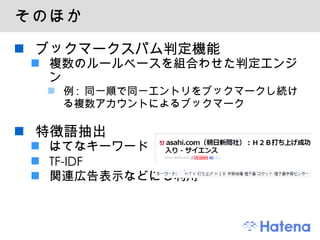
はてなブックマークのこれまで 2005/2 ベータ版リリース 2005/8 正式版リリース 2008/7 関連エントリー機能 株式会社プリファードインフラストラクチャー (PFI) と共同開発 2008/11 はてなブックマーク 2 システムリニューアル 全文検索 (w/ PFI) 、カテゴライズ etc 2009/4 Firefox 拡張 2009/5 はてなブックマークプラス 有料オプション - 7.
- 8.
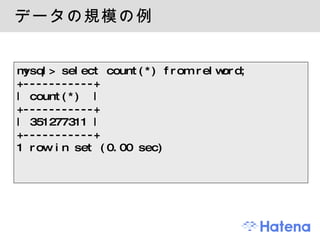
データの規模の例 mysql> selectcount(*) from relword; +-----------+ | count(*) | +-----------+ | 351277311 | +-----------+ 1 row in set (0.00 sec) - 9.
データの規模 レコード数 1,600万エントリー 4,700万 ブックマーク 5,000万 タグ データサイズ (MySQL MyISAM) エントリー 3GB ブックマーク 5.5GB タグ 4.8GB HTML 200GB超 (zlib で圧縮済み) - 10.
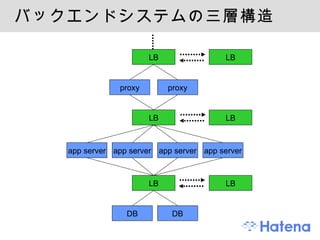
中規模 ~ 大規模ウェブサービス サーバ台数 httpd mysqld そのほか コードの規模 Perl コード 10 万行弱 (WAF 等抜きで 45,000 行 ) .pm ファイル 1,200 個強 (600 個 ) Google, Yahoo!, Amazon が超大規模とすると中規模くらい レコード数 千万件単位、データ規模は GB 単位 - 11.
- 12.
システム構成 基本は LAMP ウェブアプリ部分はオーソドックスな構成 Linux (Xen), Apache, MySQL, Perl 用途によってはサブシステムあり 検索用サーバー群 (PFI の Sedue 、自社開発の検索サーバ ) カテゴライズサーバー スペルミス修正サーバー 非同期タスク用に TheSchwartz 分散ファイルシステムに MogileFS etc. - 13.
プログラミング言語 Perl 5.8mod_perl WAF ・・・ Ridge ( 自社開発 ) O/R マッパ ・・・ DBIx::MoCo JavaScript Ten.js ( 自社開発 ) C++ Thrift メモリ要件、速度要求が厳しい箇所 - 14.
- 15.
- 16.
- 17.
- 18.
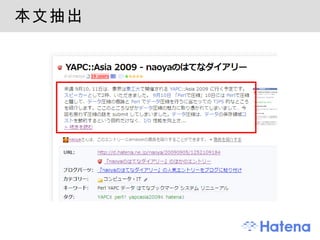
HTML::ExtractContent の仕組み正規表現だけで高速に ヒューリスティクスで " 本文らしさ " を判定 HTML を適当なブロック要素ごとに分割 各ブロックにスコアリング 本文っぽさでスコア増 ( 句読点、テキストノードの文字列長 etc) 本文っぽくなさでスコア減 ( リンクばかり並んでいる etc) つながっているブロックをまとめてクラスタにする 高スコアが続いたらクラスタ、低スコアが来たら切れ目 ブロックスコアの合計がクラスタのスコア スコアの一番高いクラスタが本文 詳しくは : http://d.hatena.ne.jp/tarao/20090322#1237750634 - 19.
HTML::LayeredExtractor ( 非公開) 新聞など ・・・ ExtractContent で OK 一部のサイト ・・・ 確実に抜き出せる別の方法 <!-- google_ad_section_start --> Web API ニコニコ動画、 YouTube 、 Amazon.co.jp 特定サイトはルールベースに処理 自社サイト、大手サイトは XPath で、など フィードを利用 複数試して一番良い結果を選択するメタエンジン Chain of Responsibility で順番に試して駄目なら ExtractContent に fallback - 20.
- 21.
- 22.
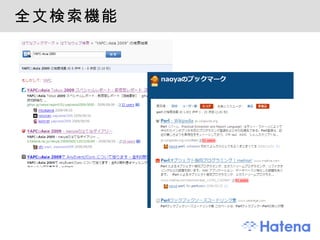
1. 全文書からの全文検索Sedue http://preferred.jp/sedue/ 圧縮 Suffix Arrays スコアリングのアルゴリズム よく知られた幾つかのヒューリスティクス ブックマーク数やブックマークされた時間を加味 文書登録 , 更新 ブックマークのタイミングに合わせて TheSchwartz で 1st ブックマークから数分後には検索可能 - 23.
2. 個人のブックマークからの全文検索"マイブックマーク全文検索" Perl で独自の全文検索システムを開発 オーソドックスな転置インデックス方式 ユーザー毎にインデックスを構築 動的に更新可能 id:naoya プロトタイプ -> id:r_kurain ( 倉井龍太郎 ), id:tarao が中心に開発 - 24.
転置インデックス 辞書 ->含む文書のID 列 (Postings List) の索引 ... perl => [1, 5, 20, 333, 350, 362 ...] python => [8, 10, 11, 52 ...] ruby => [1, 10, 21, 333, 350, 428 ...] ... - 25.
転置インデックスの構成 二つのインデックス 辞書が N-gram のインデックス ノイズが少なく、且つ検索漏れして欲しくないデータ用のインデックス タイトル、コメント、タグ、 URL 文字列など 辞書が形態素解析のインデックス 本文テキスト (by ExtractContent) などノイズの多い箇所 MeCab ( はてなキーワード + MeCab 辞書 ) 検索は両者から行って、結果をマージ Postings List には文書 ID と単語出現位置を記録 スニペットの表示やスコアリングに出現位置が必要 [ 10: 2, 100, 108, ... ] - 26.
転置インデックスの構成 (続き ) 転置インデックスの圧縮 Postings List の差分を取って VB 符号 ( 相当 ) Array::Gap http://d.hatena.ne.jp/naoya/20080906/1220685978 転置インデックスの保存に Lux IO Lux の KVS Perl バインディング Lux::IO (id:antipop) シンプルで高速 ユーザー毎にファイルひとつ。本システムの運用に最適 索引を作り直したかったらファイルを削除して再構築 分散したいなら、ユーザー ID などでパーティショニング - 27.
- 28.
- 29.
スコアリングの手法の一部 (続き ) クエリがタイトル等に含まれているかどうか 複数クエリ語の近傍度 クエリの出現位置 ・・・ 前半であるほど良 クエリのマッチの仕方 ( 単語境界かどうか etc) TF-IDF ブックマーク数 文書の新鮮度 文書の 1st ブックマーク日時 特定の URL にボーナス Wikipedia, d.hatena.ne.jp/keyword など ルートドキュメント - 30.
- 31.
- 32.
- 33.
- 34.
スペルミス修正サーバー クエリ語に対して修正候補を返す C++ と Perl ・・・ Thrift スコアリングエンジンを C++ で、問い合わせは Perl で スペルミス修正のアルゴリズム はてなキーワードを辞書に補正 N-gram 索引を使って候補を絞り、 Jaro-Winkler 距離 ( 編集距離のようなもの ) で近似度を測定 詳しくは google "Kansai.pm スペルミス " - 35.
- 36.
レコメンドエンジン BSimPFI のレコメンドエンジン ブックマークのタグを入力 ほかも幾つか試したがタグの精度が圧倒的に良かった タグは記事推薦に非常に有効 Perl とのやりとり C++ で書かれたエンジンと Perl アプリ Thrift を利用して RPC で - 37.
- 38.
文書分類エンジン BDog自社開発の文書分類エンジン C++ で実装、 Thfirt で Perl から利用 本文テキスト (by ExtractContent) から単語ベクトルを作って判定 ベイジアンフィルタ Complement Naive Bayes http://d.hatena.ne.jp/tkng/20081217/1229475900 特定のクラスに偏りがある場合、 Naive Bayes よりも精度が向上 動的な学習により精度向上 ユーザーによるカテゴリ修正で ... 過学習防止のため対象は特定ユーザーに限定 - 39.
- 40.
- 41.
各所で TheSchwartz を活用 TheSchwartz Six Apart 社開発のジョブキューフレームワーク CPAN 検索、スパム判定などブックマーク追加後に各種更新処理が発生 同期処理だとユーザーを待たせる TheSchwartz で非同期化 HTML を取得し本文抽出 / スパム判定 / カテゴリ判定 / Sedue への更新要求 / マイブックマーク検索エンジンへの更新要求 / はてなキーワード抽出 / リンク抽出 / favicon を取得 / AccountDiscovery / スクリーンショット撮影 ... - 42.
- 43.
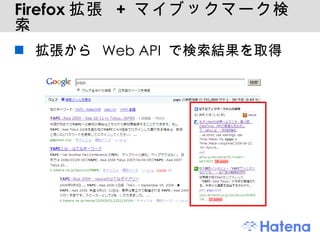
Firefox 拡張Firefox Add-ons XUL http://subtech.g.hatena.ne.jp/secondlife/20090402/1238661633 id:secondlife, id:nanto_vi が中心に開発 オープンソース http://github.com/hatena/hatena-bookmark-xul はてなブックマークの各種機能を JSON API にして、 Firefox から利用 拡張用に追加した API の一部は公開 API としてもリリース - 44.
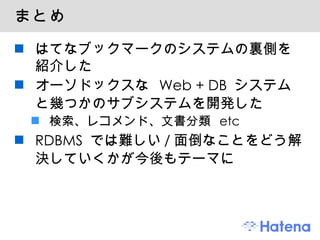
雑感 Web +DB システムの一歩外の開発をここ一年ぐらいで色々した 検索、レコメンド、Firefox拡張 ... なかなか楽しい 新しい体験をエンドユーザーに提供できる - 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
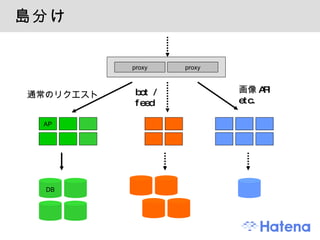
Squid によるキャッシュSquid Reverse Proxy でキャッシュ ゲスト向けコンテンツ bot 向けコンテンツ 一部の API ○○ users 画像のバックエンドの API など - 52.
memcached によるキャッシュアプリケーションフレームワークに memcached キャッシュ機能 ページを丸ごと memcached にキャッシュする機能 ユーザー毎の設定パラメータをまとめて SHA1 キーを作り、同じ設定のユーザーには同じキャッシュを返す機能 Template::Plugin::Cache longtail はキャッシュしない ○○ users を閾値に - 53.
クライアント表示に関する工夫 昨今では定番の手法を実施 gzip圧縮 静的ファイルの Expires を 1年に 更新される可能性のあるものは別ディレクトリで管理 CSS, JavaScript ファイルは git の commit + path の SHA1 をクエリパラメータに 例: /js/foo.js?sha1hogehoge 静的ファイルを別ドメイン -> Cookie 分の転送を削減 - 54.
クライアント表示に関する工夫 (続き ) JavaScript による遅延ロード 広告の遅延ロード 広告表示でページ表示が待たされない Google の広告、自社広告 - 55.
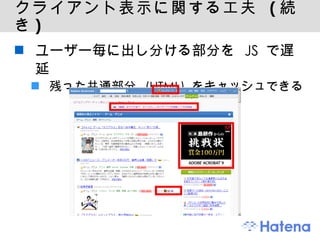
- 56.
雑感 一般的な Web + DB システムの運用は苦労が減った ハードウェアの進歩、特にメモリ容量 各種ノウハウがウェブや書籍等で公開されている JavaScript の遅延ロードをうまく使うと高速化に寄与できる箇所が多い RDBMS だけでは難しい規模 / 要件をどうするかが面白い 検索エンジンを作る、レコメンドエンジンを作る、文書分類エンジンを作る ... etc. - 57.
- 58.
- 59.




















![転置インデックス 辞書 -> 含む文書のID 列 (Postings List) の索引 ... perl => [1, 5, 20, 333, 350, 362 ...] python => [8, 10, 11, 52 ...] ruby => [1, 10, 21, 333, 350, 428 ...] ...](https://image.slidesharecdn.com/hatenabookmarkyapc2009-090911065220-phpapp01/85/slide-24-320.jpg)
![転置インデックスの構成 二つのインデックス 辞書が N-gram のインデックス ノイズが少なく、且つ検索漏れして欲しくないデータ用のインデックス タイトル、コメント、タグ、 URL 文字列など 辞書が形態素解析のインデックス 本文テキスト (by ExtractContent) などノイズの多い箇所 MeCab ( はてなキーワード + MeCab 辞書 ) 検索は両者から行って、結果をマージ Postings List には文書 ID と単語出現位置を記録 スニペットの表示やスコアリングに出現位置が必要 [ 10: 2, 100, 108, ... ]](https://image.slidesharecdn.com/hatenabookmarkyapc2009-090911065220-phpapp01/85/slide-25-320.jpg)