Recommended
PPT
PDF
PDF
PDF
PDF
PDF
PDF
PDF
Mashup and new paradigm - マッシュアップ技術とインターネットの新しい潮流
PDF
Authoring Tools Comparision in Detail
PPTX
PHPカンファレンス2009 - 45分で分かる安全なWebアプリケーション開発のための発注・要件・検収
PDF
【13-B-3】 企業システムをマッシュアップ型に変えるには
PDF
XS Japan 2008 App Data Japanese
PDF
PDF
PDF
XS Japan 2008 Ganeti Japanese
PDF
PDF
PDF
PDF
PPTX
PDF
Cloud for Enterprise IT (Japanese)
PDF
PDF
PDF
PDF
PDF
PDF
Talk In Point Of Gc Once In While
PDF
SmartPhone development guide with CoffeeScript + Node + HTML5 Technology, for...
PPT
PPT
Scripting Layer for Android + Perl
More Related Content
PPT
PDF
PDF
PDF
PDF
PDF
PDF
PDF
Mashup and new paradigm - マッシュアップ技術とインターネットの新しい潮流
What's hot
PDF
Authoring Tools Comparision in Detail
PPTX
PHPカンファレンス2009 - 45分で分かる安全なWebアプリケーション開発のための発注・要件・検収
PDF
【13-B-3】 企業システムをマッシュアップ型に変えるには
PDF
XS Japan 2008 App Data Japanese
PDF
PDF
PDF
XS Japan 2008 Ganeti Japanese
PDF
PDF
PDF
PDF
PPTX
PDF
Cloud for Enterprise IT (Japanese)
PDF
PDF
PDF
PDF
PDF
PDF
Talk In Point Of Gc Once In While
More from Naoya Ito
PDF
SmartPhone development guide with CoffeeScript + Node + HTML5 Technology, for...
PPT
PPT
Scripting Layer for Android + Perl
PPT
Web-Gakkai Symposium 2010
PPT
Introduction to Algorithms#24 Shortest-Paths Problem
PPT
090518computing Huffman Code Length
PPT
PPT
PPT
PPT
PPT
PPT
PPT
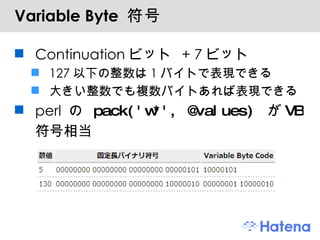
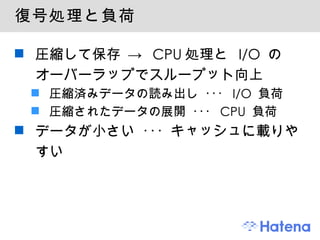
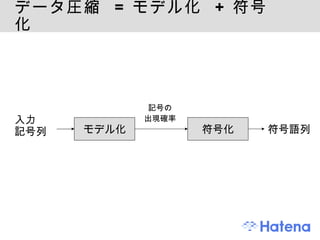
Perlで圧縮 1. Perl で圧縮 株式会社はてな / {Shibuya, Kansai}.pm 伊藤直也 2. アジェンダ モチベーション データ圧縮の概念 データの最適な表現を用いる手法 データの冗長性をなくす手法 そのほかの話題 Perl でデータ圧縮 Compress::* 系モジュール 符号化のモジュール 整数列の圧縮 まとめ 3. 4. 5. ディスクリードと圧縮 HDD vs メモリ -> 10 -6 ~ 10 -9 の差 HDD 上のデータのシーク ・・・ ディスクの回転待ち、ヘッドの移動に ms ∴ ディスクシーク回数を最小化したい OS ( カーネル ) ブロック単位での読み出し 連続したデータは近い場所に保存 アプリケーション B+ 木など最適なデータ構造の選択 圧縮して保存 -> 消費ブロック数を減らす 6. 復号処理と負荷 圧縮して保存 -> CPU処理と I/O のオーバーラップでスループット向上 圧縮済みデータの読み出し ・・・ I/O 負荷 圧縮されたデータの展開 ・・・ CPU 負荷 データが小さい ・・・ キャッシュに載りやすい 7. 8. 前提 : 可逆圧縮と不可逆圧縮 今回扱うのは可逆 (lossless) 圧縮 主にテキスト圧縮の話 9. データ圧縮の基本 データの最適な表現を用いる 例: モールス信号 E : ・ A: ・ ー Q: ー ー ・ー データの冗長性をなくす 例: 連長圧縮法 (Run-Length) aaaaaa bbbbbbbb c d aaaa -> a6 b8 c1 d1 a4 10. 11. 頻出するものを短く、そうでないものは長く 晴、曇、雨、雪を符号化 2ビット の固定長符号 晴 00, 曇 01, 雨, 10, 雪 11 晴 晴 晴 晴 曇 晴 雨 曇 晴 晴 晴 雪 00 00 00 00 01 00 10 01 00 00 00 11 -> 24 ビット 可変長符号 晴 1, 曇 00, 雨 010, 雪 011 晴 晴 晴 晴 曇 晴 雨 曇 晴 晴 晴 雪 1 1 1 1 00 1 010 00 1 1 1 011 -> 18 ビット 12. データ圧縮 = モデル化 + 符号化 入力 記号列 モデル化 符号化 記号の 出現確率 符号語列 13. 先ほどの天気の例 モデル化 晴 > 曇 > 雨 > 雪 の順に起こりやすい -> 確率分布 符号化 確率分布に合わせて晴 1, 曇 00, 雨 010, 雪 011 という最適な符号語を割り当てる ( ハフマン符号 ) 接頭符号 (Prefix Code) ・・・ 全ての符号語が他の符号語の接頭語にもなっていない 1 00 010 011 14. モデル化と符号化の手法 モデル化 最も単純なもの: 無記憶情報源モデル 記号列の文脈を考慮しないモデル 例: aaa bb c -> a 3/6, b 2/6, c 1/6 高度なもの 有限文脈モデル、有限状態モデル PPM、Block Sorting、Dynamic Markov Chain 代表的な符号化手法 ハフマン符号 算術符号、Range Coder 15. 16. より進んだテキスト圧縮の例 PPM + 適応型算術符号 PPM で過去の文脈から次の記号の出現確率を予測 予測した確率分布を適応型の算術符号 ( 適応型 Range Coder など ) で符号化 BWT + MTF + Run-Length + 符号化 Block sorting(BWT) で文脈を揃える Move To Front + Run-Length で偏りのある整数列に変換 ハフマン符号もしくは Range Coder で符号化 bzip2 がこの方式 17. 18. 19. 20. 21. 22. 23. 整数の単調増加列の圧縮 単調増加する整数列 例: [ 1, 5, 7, 8, 10, 15, 23, 100, .... ] 検索エンジンの転置インデックスなど 差分を取る -> 可変長符号で符号化 例: [ 1, 4, 2, 1, 2, 5, 8, 77, ...] 小さい数字が出やすい 可変長符号 ・・・ VB符号、γ符号、δ符号 小さい数字ほど短く符号化できる手法 24. Variable Byte 符号 Continuationビット + 7ビット 127以下の整数は1バイトで表現できる 大きい整数でも複数バイトあれば表現できる perl の pack('w*', @values) が VB 符号相当 25. エントロピーと圧縮限界 エントロピー (平均情報量) H 0 = -ΣP(x) log P(x) 無記憶情報源 (zero-order) 高次のエントロピー ・・・ H 1 , H 2 ... 平均符号長をエントロピー以下には圧縮できない エントロピー以下まで圧縮した場合、情報の歪みなしで復元することができない 26. 27. 28. CPAN の圧縮ライブラリ Compress::* 系 符号化まで含めて一気通貫で、汎用的 代表的 ( で使えそう ) な実装 Compress::Zlib Compress::Bzip2 Compress::LZMA::Simple Compress::LZO Compress::PPMd 29. Compress::Zlib zlib の Perl バインディング deflate アルゴリズム LZSS + ハフマン符号 zlib, gzip 小さいオーバーヘッドゆえに高速、そこそこの圧縮率 広範囲で利用されている 符号化、復号化共に高速 枯れている ・・・「とりあえず zlib で」 短いテキストには向かない 30. Compress::Bzip2 libbzip2 の Perl バインディング Block Sorting + ハフマン符号 高い圧縮率、そこそこ高速な復号 符号化が zlib に比べて遅い (Block sorting が支配的 ) 復号はそこそこ高速 , zlib より遅い 処理時間を少し犠牲にしつつも、 zlib より高い圧縮率が欲しいとき やはり、短いテキストには向かない 31. Compress::LZMA::Simple liblzma LZMA ・・・ 7-Zip などで利用されている圧縮アルゴリズム Repeated Offsets, Binary Range Coder, 状態コンテキストベースのモデル化 , 最適マッチング 符号化が低速な代わりに非常に高い圧縮率と高速な復号 符号化はかなり遅い 圧縮率がかなり高い (bzip2 よりも高性能 ) 復号は bzip2 よりも高速、 zlib よりは低速 符号化は遅くても全く構わない、という場合に 例 : 静的アーカイブの配布 32. Compress::LZO LZO ライブラリのバインディング LZO ・・・ LZ77 ベース、圧縮率を犠牲に符号化 / 復号 ( 特に復号 ) 速度を高速化 圧縮率は高くないが、非常に高速 (wikipedia) 符号化は deflate と同程度 復号は "very fast" " in non-trivial cases able to exceed the speed of a straight memory-to-memory copy due to the reduced memory-reads. " 頻繁に更新されるデータや、復号のオーバーヘッドを極力小さく抑えたい時に 33. 34. 35. 36. 37. 整数列の圧縮 pack('w*', @values) 可変長バイト符号相当 Array::Gap ・・・ 差分取って VB 符号 http://d.hatena.ne.jp/naoya/20080906/1220685978 γ 符号 , δ 符号 , ゴロム / ライス符号 etc ビットレベルの整数符号化 組み込み、 CPAN の実装はないので自前で 38. 個人的な見解 汎用的なテキスト圧縮には zlib や LZMA 符号化、復号化共に要速度 ・・・ zlib 符号化は遅くても良い ・・・ LZMA も候補 整数列の圧縮は速度重視なら pack 、圧縮率重視なら δ 符号やゴロム符号を実装 昨年の Pathtraq の事例 (※) のような場合は自前でデータの特性に合った実装 ※ http://www.slideshare.net/kazuho/yapcasia-2008-tokyo-pathtraq-building-a-computationcentric-web-service 39. まとめ データ圧縮の概論と、 Perl での TIPS を紹介した I/O スループット向上のためにもデータ圧縮は重要 CPAN の Compress:: モジュールで汎用的な圧縮が可能 アプリケーションの性質に応じて使い分けると良い 場合によっては圧縮ルーチンを自前で実装すると良いことも 40. 41. 参考文献 Ian H. Witten, Alistair Moffat, Timothy C. Bell " Managing Gigabytes ", Morgan Kaufmann, 1999 植松友彦 " 文書データ圧縮アルゴリズム入門 ", CQ 出版 , 1994 岡野原大輔 , 小川秀明 , 藤本健 " よくわかる最新 データ圧縮技術の基本と仕組み ", 秀和システム , 2003





















![整数の単調増加列の圧縮 単調増加する整数列 例: [ 1, 5, 7, 8, 10, 15, 23, 100, .... ] 検索エンジンの転置インデックスなど 差分を取る -> 可変長符号で符号化 例: [ 1, 4, 2, 1, 2, 5, 8, 77, ...] 小さい数字が出やすい 可変長符号 ・・・ VB符号、γ符号、δ符号 小さい数字ほど短く符号化できる手法](https://image.slidesharecdn.com/perlcompression-090910022349-phpapp01/85/Perl-23-320.jpg)