John Overdeck
1986年、ポーランドで開かれた第7回
国際数学オリンピックで銀メダルを獲得
した16歳のジョン・オーバーデックは、
co-founder ofTwo Sigma Investments
今、ビッグデータをかき集め、機械学習で分析するクオンツ
運用派の代表格
https://forbesjapan.com/articles/detail/12671
Stanford University 卒
US$5.5 billion (November 2018) vice president at Amazon.comREAL TIME NET WORTH
6,000億円以上
クオンツ運用は、高度な数学的テクニックを駆使し、マーケット(株式、
債券、為替、金利、コモディティ)や経済情勢などのデータをコンピュー
タで分析して作られた「数理モデル」に従って運用する投資スタイル
https://www.ifinance.ne.jp/glossary/fund/fun125.html
(間をあける)
これが現在の姿。数学と統計学を修得した彼は、今、ビッグデータをかき集め、機
械学習で分析するクオンツ運用派の代表格になっています。
Photo: Paul Harris / Getty Images
https://courrier.jp/news/archives/121792/
Marilyn vos Savant
IQ228! 「世界最高の天才」
AI
モンティ・ホール問題で有名な
もう一人。Marilyn vos Savantという女性です。彼女はIQ228という世界的な記録を
持っていて、ギネスに登場しています。
3.
Photo: Paul Harris/ Getty Images
驚くべき頭脳を持つ人たち
AI
二人のような人物はまれに見るすぐれた知能の持ち主だと思いますが、
Photo: Paul Harris / Getty Images
AI
ヒトの知能を上回るロボット
シンギュラリティ
Human
驚くべき頭脳を持つ人たち
今、そのヒトの知能を上回るロボットが出現する時期はもう間近ではないか、と言われ
ています。
そのような時期をシンギュラリティーと言います。
右の女性は、Ex MachinaというSF映画のロボットです。
4.
https://www.amazon.co.jp/gp/video/detail/B01KT8EB7U
Ex Machina 「機械仕掛けの神」
Ava
Caleb
bossNathan
AI
ロボットの名前はAvaと言います。左側のNathanがAvaを作り、彼は、真ん中の部下
ケイレブに、Avaが人間かロボットか、見分けられるかというチューリングテストを
行なうよう指示します。
Avaは、Nathanから逃れたいため、テストの最中、ケイレブに恋心を抱かせるように
振る舞い、結局、彼の心を支配して目的を達成しようとします。
SFですが、AIの正体がわからないと、シンギュラリティーはここまでいくのかと想像
して、怖くなるかもしれません。そこで、いくつかの例をとりあげながら、今のAIと
は一体どんなものか、見てみようと思います。
ワトソンが専門医でもわからなかったガンを特定した
膨大なゲノム情報を扱う がん医療に不可欠なAI
www.innervision.co.jp/ressources/pdf/innervision2017/iv201707_018.pdf
Watson for Genomics(WfG)
①
骨髄異形成症候群
+ 別の白血病を発症している可能性
3つの例を説明します。
はじめに、ワトソンです。東大の医科研が、ワトソンとスーパーコンピュータを使って、
専門医でもわからなかったガンを特定したというニュースはみなさん覚えておられるこ
とと思います。患者は、初め、専門医から骨髄異形成症候群と診断され、その治療を
しましたが効果がありませんでした。
そこに、ワトソンは、ゲノムの変異を、PubMedと呼ばれる世界中から集められた医学
関連の論文の知識と関連づけ、別の白血病を発症している可能性を指摘してくれました。
その治療法の効果があったということです。
これは、ビッグデータの中から適切なものを高速に探し出すということにあたり、従
来から行われていたAIにあたります。
https://ai.googleblog.com/2018/11/open-sourcing-bert-state-of-art-pre.html 3/6
move beyondexisting pre-training techniques. The Transformer model architecture,
developed by researchers at Google in 2017, also gave us the foundation we needed to
make BERT successful. The Transformer is implemented in our open source release, as
well as the tensor2tensor library.
Results with BERT
To evaluate performance, we compared BERT to other state-of-the-art NLP systems.
Importantly, BERT achieved all of its results with almost no task-speci c changes to the
neural network architecture. On SQuAD v1.1, BERT achieves 93.2% F1 score (a measure
of accuracy), surpassing the previous state-of-the-art score of 91.6% and human-level
score of 91.2%:
BERT also improves the state-of-the-art by 7.6% absolute on the very challenging GLUE
benchmark, a set of 9 diverse Natural Language Understanding (NLU) tasks. The amount
of human-labeled training data in these tasks ranges from 2,500 examples to 400,000
examples, and BERT substantially improves upon the state-of-the-art accuracy on all of
them:
tml 1/6
ned on small-data NLP tasks like question
esulting in substantial accuracy improvements
ets from scratch.
echnique for NLP pre-training called Bidirectional
formers, or BERT. With this release, anyone in the
-art question answering system (or a variety of other
ngle Cloud TPU, or in a few hours using a single GPU.
ilt on top of TensorFlow and a number of pre-trained
our associated paper, we demonstrate state-of-the-
g the very competitive Stanford Question Answering
training contextual representations — including
Generative Pre-Training, ELMo, and ULMFit.
els, BERT is the rst deeply bidirectional,
n, pre-trained using only a plain text corpus (in thishttps://ai.googleblog.com/2018/11/open-sourcing-bert-state-of-art-pre.html 1/6
answering and sentiment analysis, resulting in substantial accuracy improvements
compared to training on these datasets from scratch.
This week, we open sourced a new technique for NLP pre-training called Bidirectional
Encoder Representations from Transformers, or BERT. With this release, anyone in the
world can train their own state-of-the-art question answering system (or a variety of other
models) in about 30 minutes on a single Cloud TPU, or in a few hours using a single GPU.
The release includes source code built on top of TensorFlow and a number of pre-trained
language representation models. In our associated paper, we demonstrate state-of-the-
art results on 11 NLP tasks, including the very competitive Stanford Question Answering
Dataset (SQuAD v1.1).
What Makes BERT Different?
BERT builds upon recent work in pre-training contextual representations — including
Semi-supervised Sequence Learning, Generative Pre-Training, ELMo, and ULMFit.
However, unlike these previous models, BERT is the rst deeply bidirectional,
unsupervised language representation, pre-trained using only a plain text corpus (in this
html 1/6
ets from scratch.
echnique for NLP pre-training called Bidirectional
sformers, or BERT. With this release, anyone in the
e-art question answering system (or a variety of other
ngle Cloud TPU, or in a few hours using a single GPU.
uilt on top of TensorFlow and a number of pre-trained
our associated paper, we demonstrate state-of-the-
g the very competitive Stanford Question Answering
-training contextual representations — including
, Generative Pre-Training, ELMo, and ULMFit.
els, BERT is the rst deeply bidirectional,
on, pre-trained using only a plain text corpus (in this
1/6
P tasks like question
accuracy improvements
training called Bidirectional
th this release, anyone in the
ng system (or a variety of other
a few hours using a single GPU.
ow and a number of pre-trained
we demonstrate state-of-the-
Stanford Question Answering
presentations — including
ng, ELMo, and ULMFit.
eeply bidirectional,
nly a plain text corpus (in thishttps://ai.googleblog.com/2018/11/open-sourcing-bert-state-of-art-pre.html 1/6
answering and sentiment analysis, resulting in substantial accuracy improvements
compared to training on these datasets from scratch.
This week, we open sourced a new technique for NLP pre-training called Bidirectional
Encoder Representations from Transformers, or BERT. With this release, anyone in the
world can train their own state-of-the-art question answering system (or a variety of other
models) in about 30 minutes on a single Cloud TPU, or in a few hours using a single GPU.
The release includes source code built on top of TensorFlow and a number of pre-trained
language representation models. In our associated paper, we demonstrate state-of-the-
art results on 11 NLP tasks, including the very competitive Stanford Question Answering
Dataset (SQuAD v1.1).
What Makes BERT Different?
BERT builds upon recent work in pre-training contextual representations — including
Semi-supervised Sequence Learning, Generative Pre-Training, ELMo, and ULMFit.
However, unlike these previous models, BERT is the rst deeply bidirectional,
unsupervised language representation, pre-trained using only a plain text corpus (in this
-pre.html 1/6
e built on top of TensorFlow and a number of pre-trained
In our associated paper, we demonstrate state-of-the-
ding the very competitive Stanford Question Answering
pre-training contextual representations — including
ing, Generative Pre-Training, ELMo, and ULMFit.
odels, BERT is the rst deeply bidirectional,
ation, pre-trained using only a plain text corpus (in thishttps://ai.googleblog.com/2018/11/open-sourcing-bert-state-of-art-pre.html 1/6
language representation models. In our associated paper, we demonstrate state-of-the-
art results on 11 NLP tasks, including the very competitive Stanford Question Answering
Dataset (SQuAD v1.1).
What Makes BERT Different?
BERT builds upon recent work in pre-training contextual representations — including
Semi-supervised Sequence Learning, Generative Pre-Training, ELMo, and ULMFit.
However, unlike these previous models, BERT is the rst deeply bidirectional,
unsupervised language representation, pre-trained using only a plain text corpus (in this
exact match (EM)
2018/11/4 Google AI Blog: Open Sourcing BERT: State-of-the-Art Pre-training for Natural Language Processing
simple task that can be generated from any text corpus: Given two sentences A and B, is
B the actual next sentence that comes after A in the corpus, or just a random sentence?
For example:
Training with Cloud TPUs
Everything that we’ve described so far might seem fairly straightforward, so what’s the
missing piece that made it work so well? Cloud TPUs. Cloud TPUs gave us the freedom
to quickly experiment, debug, and tweak our models, which was critical in allowing us to
move beyond existing pre-training techniques. The Transformer model architecture,
developed by researchers at Google in 2017, also gave us the foundation we needed to
make BERT successful. The Transformer is implemented in our open source release, as
well as the tensor2tensor library.
Results with BERT
To evaluate performance, we compared BERT to other state-of-the-art NLP systems.
Importantly, BERT achieved all of its results with almost no task-speci c changes to the
neural network architecture. On SQuAD v1.1, BERT achieves 93.2% F1 score (a measure
of accuracy), surpassing the previous state-of-the-art score of 91.6% and human-level
score of 91.2%:
BERT also improves the state-of-the-art by 7.6% absolute on the very challenging GLUE
benchmark, a set of 9 diverse Natural Language Understanding (NLU) tasks. The amount
of human-labeled training data in these tasks ranges from 2,500 examples to 400,000
examples, and BERT substantially improves upon the state-of-the-art accuracy on all of
them:
BERTがヒトの読解力を上回った
③`
2018/11/23
ヒト
BERT
しかし、つい最近、GoogleのBERTというdeep learningが、ヒトの読解力を上回
る成果をあげたというニュースが入って衝撃が走りました。SQuAd(The
Stanford Question Answering Dataset)という、文章を理解しているかどうかを
多肢選択式で求めさせるテストで、ヒトを上回ったのです。
③`
学習のコースとは何ですか?
教授の科学を表す別の名前は何ですか?
ほとんどの教師はどこから資格を取得するのですか?
教師が生徒の学習に役立つものは何ですか?
先生はどこで教えているのでしょうか?
教師の役割は、しばしば正式で継続的であり、学校または
正式な教育の他の場所で行われます。多くの国で、教師にな
りたい人は、まず大学やカレッジから特定の専門資格や資
格を取得する必要があります。これらの職業的資格には、
教育学の研究、教育科学が含まれます。教師は他の専門家
のように、資格を得た後に継続して教育を受けなければな
らない場合があります。教師は、カリキュラムと呼ばれる学
習コースを提供し、学生の学習を促進するための授業計画
を使用することができます。
カリキュラム
ペダゴギー
大学やカレッジ
授業計画
大学やカレッジ
例えば、左に示すような文章を読んで、右のような問いかけで正しい答えはどれか、
という形式の問題に対して、BERTはヒトの正答率を上まわったのです。緑が正解を
表しています。
WikiPediaを事前に学習させてはいますが、それに加えて、ここにはdeep learning
の中でもtranformerという最新の技術が使われています。Tranformerというのは、
膨大な知識ベースを他の小さなデータベースにも継承できるようにしたものです。
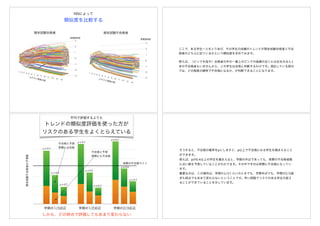
伝統的な統計的手法 時系列解析
autoregressive integrated movingaverage (ARIMA) model
AR
ARMA
ARIMA
as a model for y = f (x), traditionally,
artificial neural networks (ANN) model
time-series modeling
Box-Jenkinsy = f(t) = Xt
ARIMA(p, d, q) × (P, D, Q)S,
with p = non-seasonal AR order, d = non-seasonal differencing, q = non-seasonal
MA order, P = seasonal AR order, D = seasonal differencing, Q = seasonal MA
order, and S = time span of repeating seasonal pattern.
seasonal'ARIMA,
106
伝統的な統計的手法である時系列解析が使えます。ARとかARIMAと略されて呼ばれていま
す。季節性を考慮して作られた数理モデルもあります。
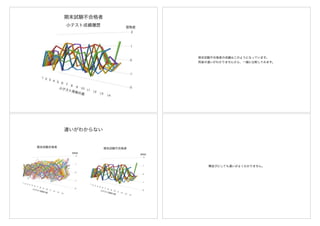
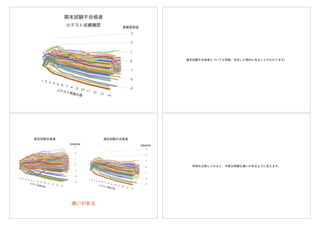
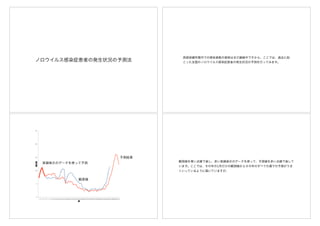
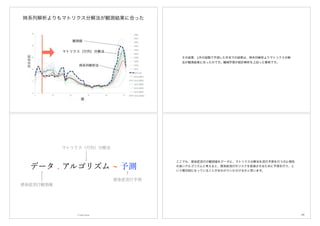
マトリクス(行列)にして考えてみる
週
年
ここにはどんな数値が入るだろうか
時系列ではなく
しかし、ここでは、時系列解析ではなく、年と週を行と列に持つマトリクス(行列)
にして考えてみようと思います。緑の部分は感染者数は少なく、黄色から赤くなるに
従って感染者数は多くなることを表しています。右下の空白の部分を予測しようとし
ています。






































![Solve [X^2=A], where A is a matrix](https://cdn.slidesharecdn.com/ss_thumbnails/solvex2ab09-170126130944-thumbnail.jpg?width=640&height=640&fit=bounds)


















