More Related Content

PDF
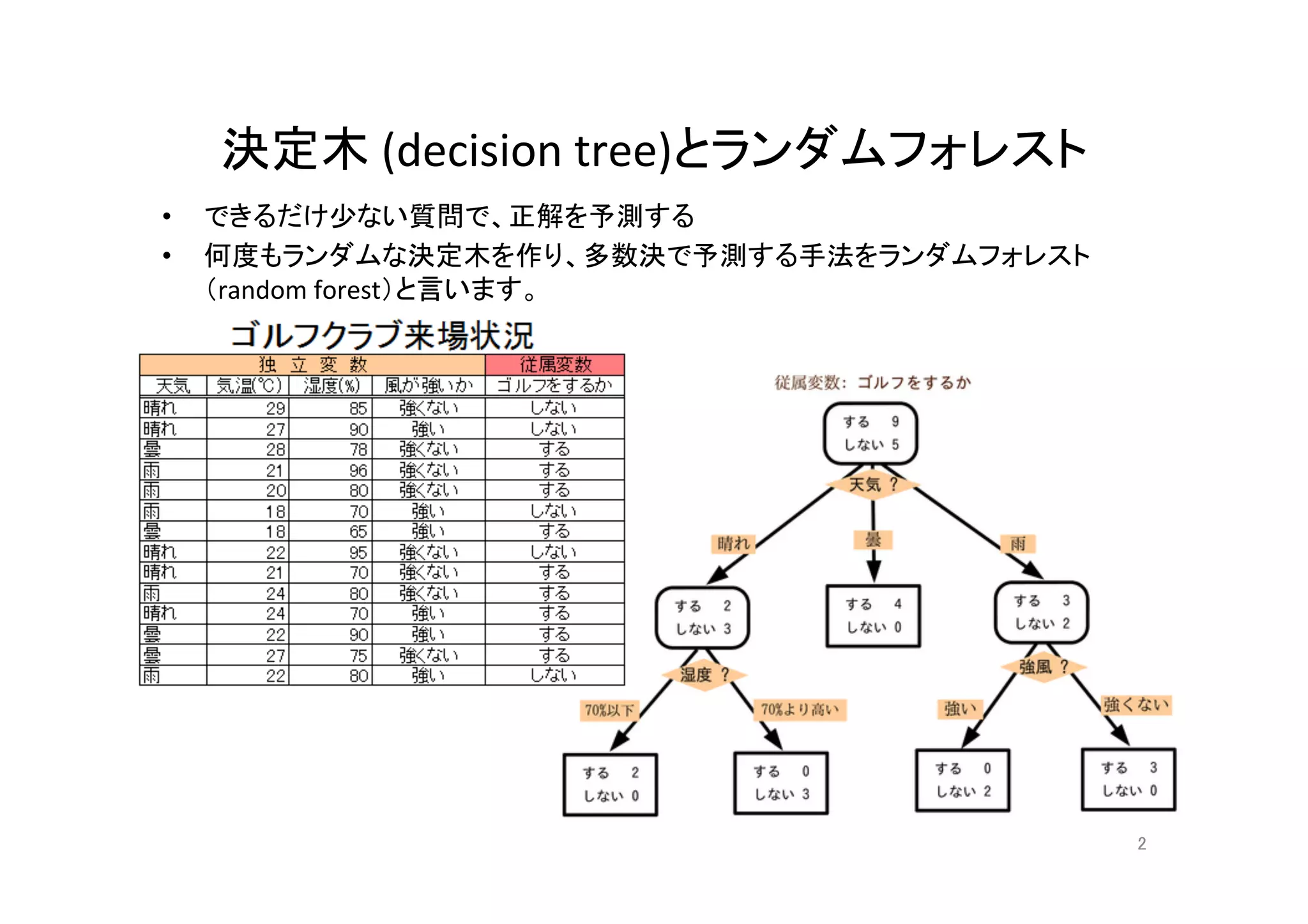
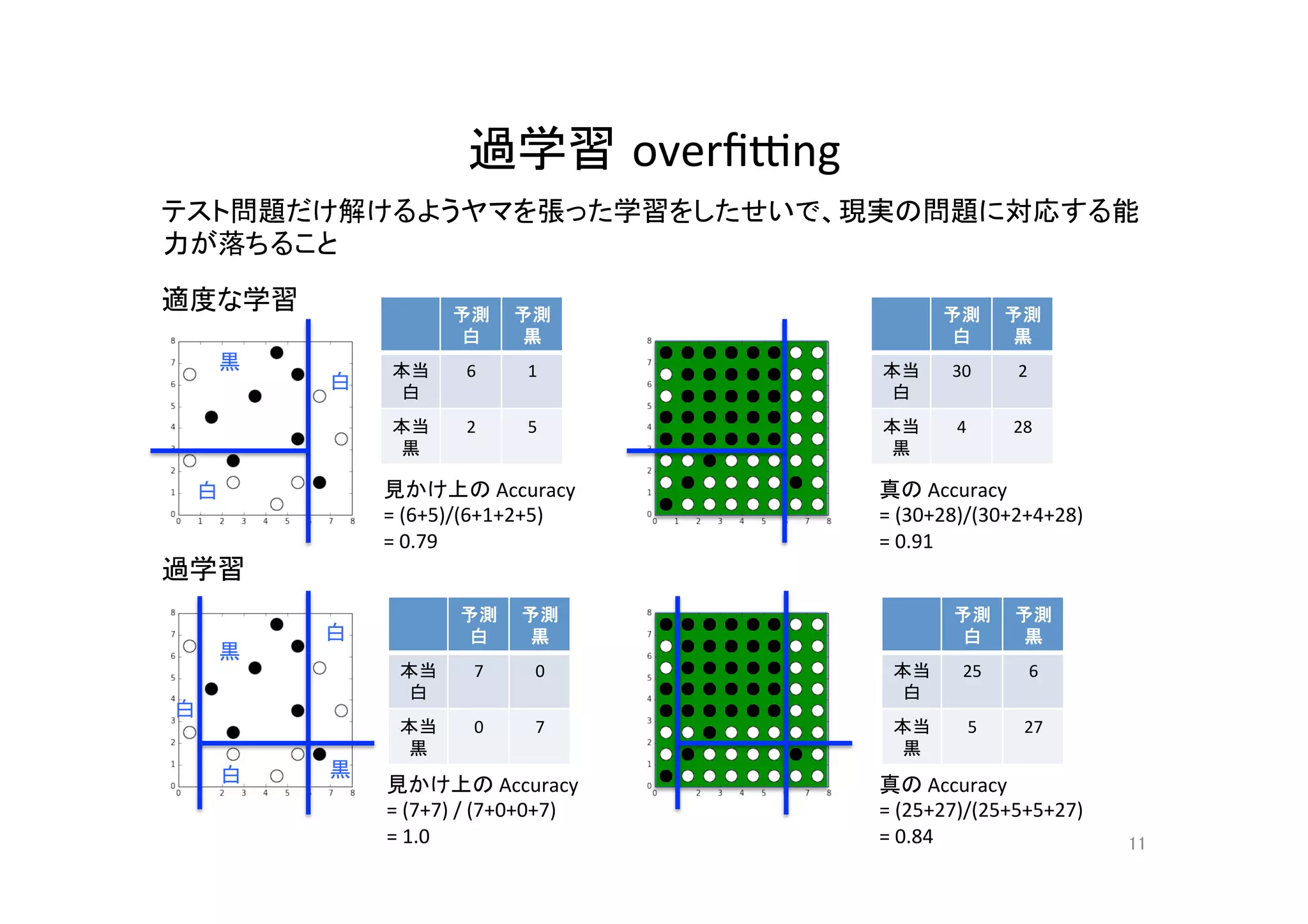
ランダムフォレストとそのコンピュータビジョンへの応用 
PDF

PDF

PDF

PDF

PDF
Introduction to ensemble methods for beginners 
PDF

PDF
Similar to 機械学習入門の入門

PPTX

PDF

PDF
Jubatusにおける大規模分散オンライン機械学習 
PDF
シリーズML-03 ランダムフォレストによる自動識別 
PDF

PPTX
非定常データストリームにおける適応的決定木を用いたアンサンブル学習 
PDF

PDF
機械学習によるモデル自動生成の一考察 ー 決定表と決定木によるアプローチ - 
PDF

PDF
分類問題 - 機械学習ライブラリ scikit-learn の活用 
PDF

PPTX

KEY

PDF

PDF

PPTX
20190725 taguchi decision_tree_for_pubshare 
PDF
CDLE Lt甲子園予選会 2021 #1 0527 01(itok) 
PDF
Machine learning for biginner 
PDF

PPTX
0610 TECH & BRIDGE MEETING More from Mas Kot

PDF

PDF

PDF

PDF

PDF

PDF
Metabolic network and cheminformatics 
PDF

PDF

PDF

PDF

PDF
天然物生合成と環境物質代謝のケモインフォマティクス 
PDF
Metabolic Network Analysis 
PDF

PDF
文献データベース Literature Databases 
PDF
KNApSAcKデータベースを用いた昆虫・植物間化学的相互作用解析 
PDF
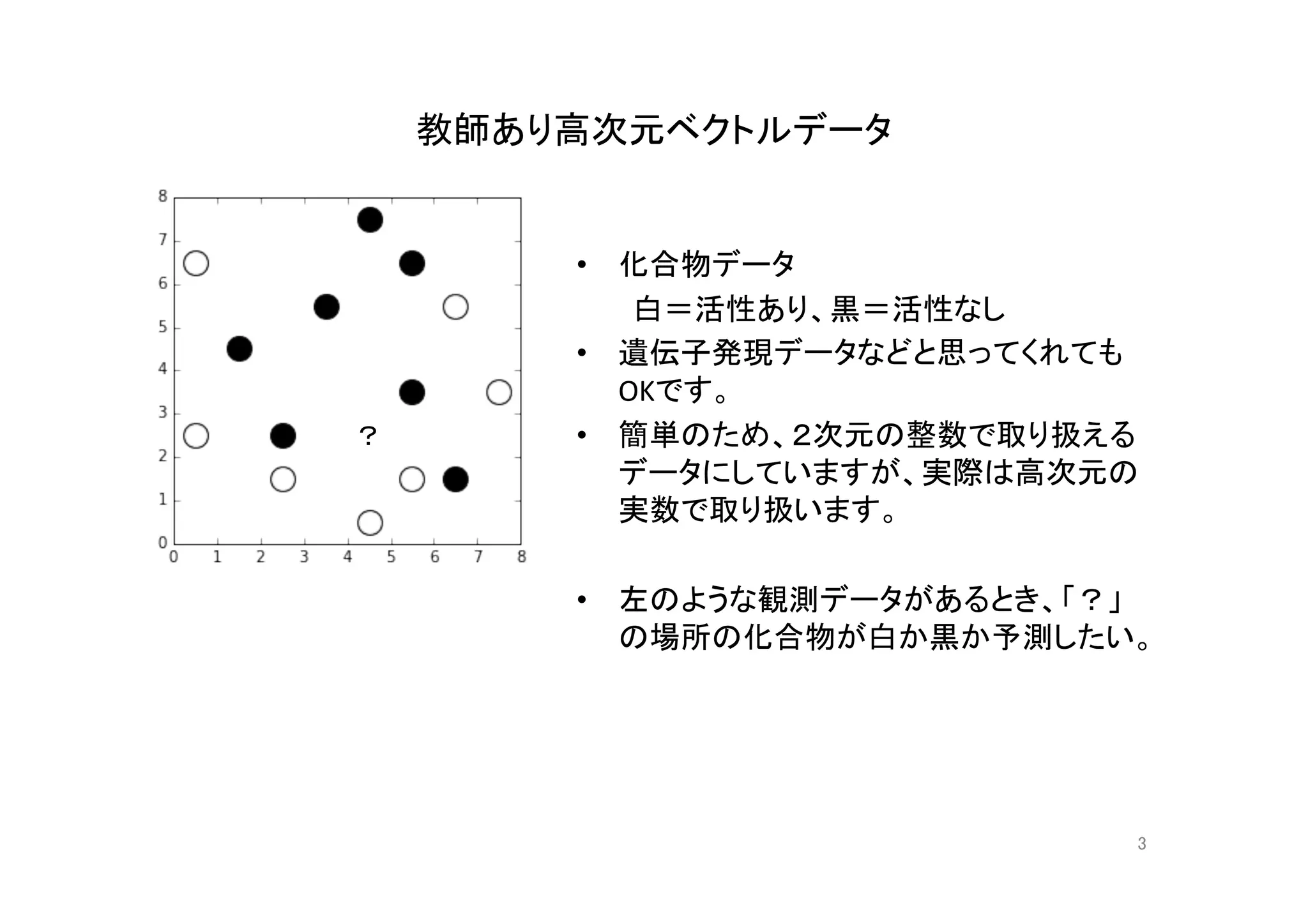
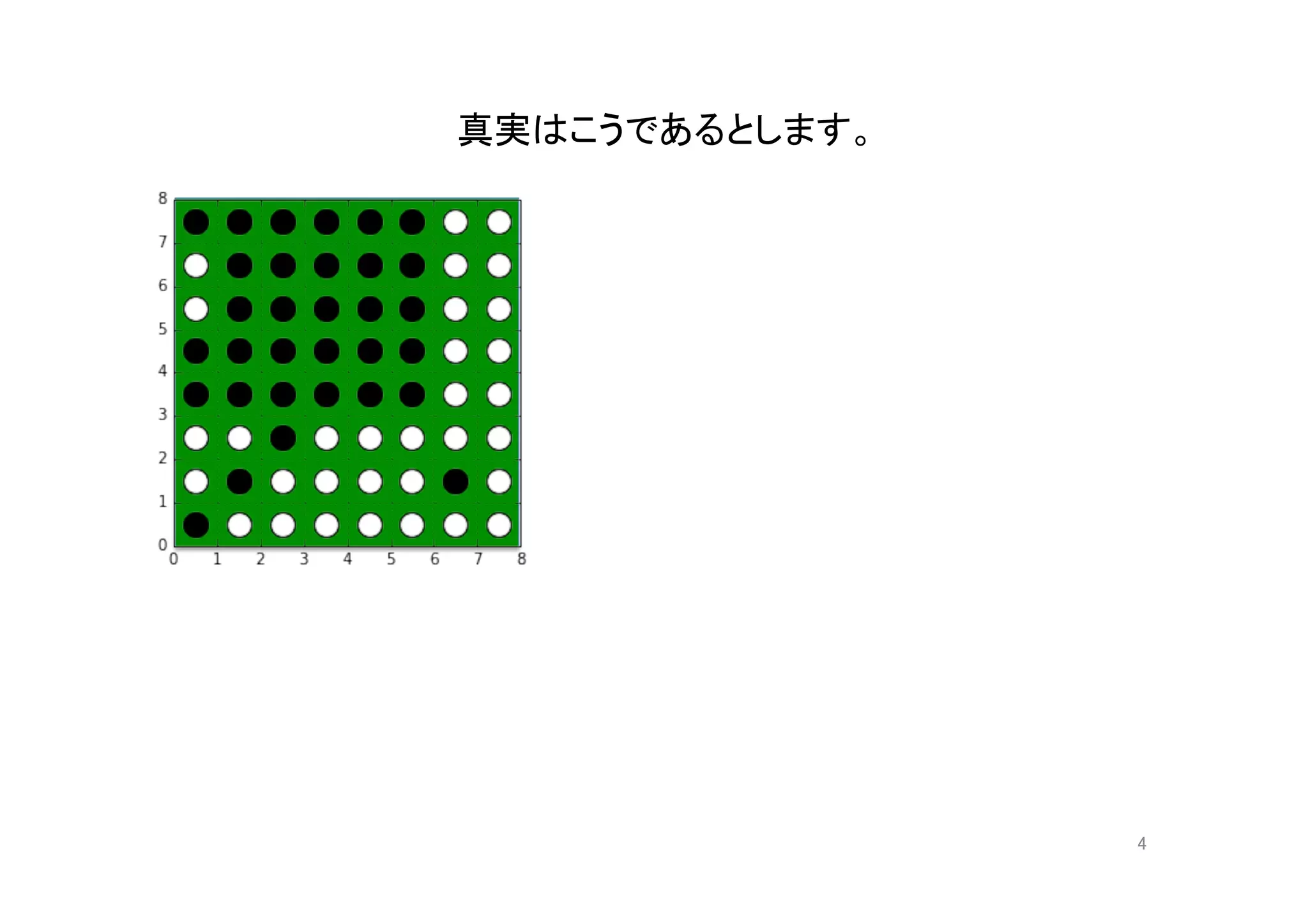
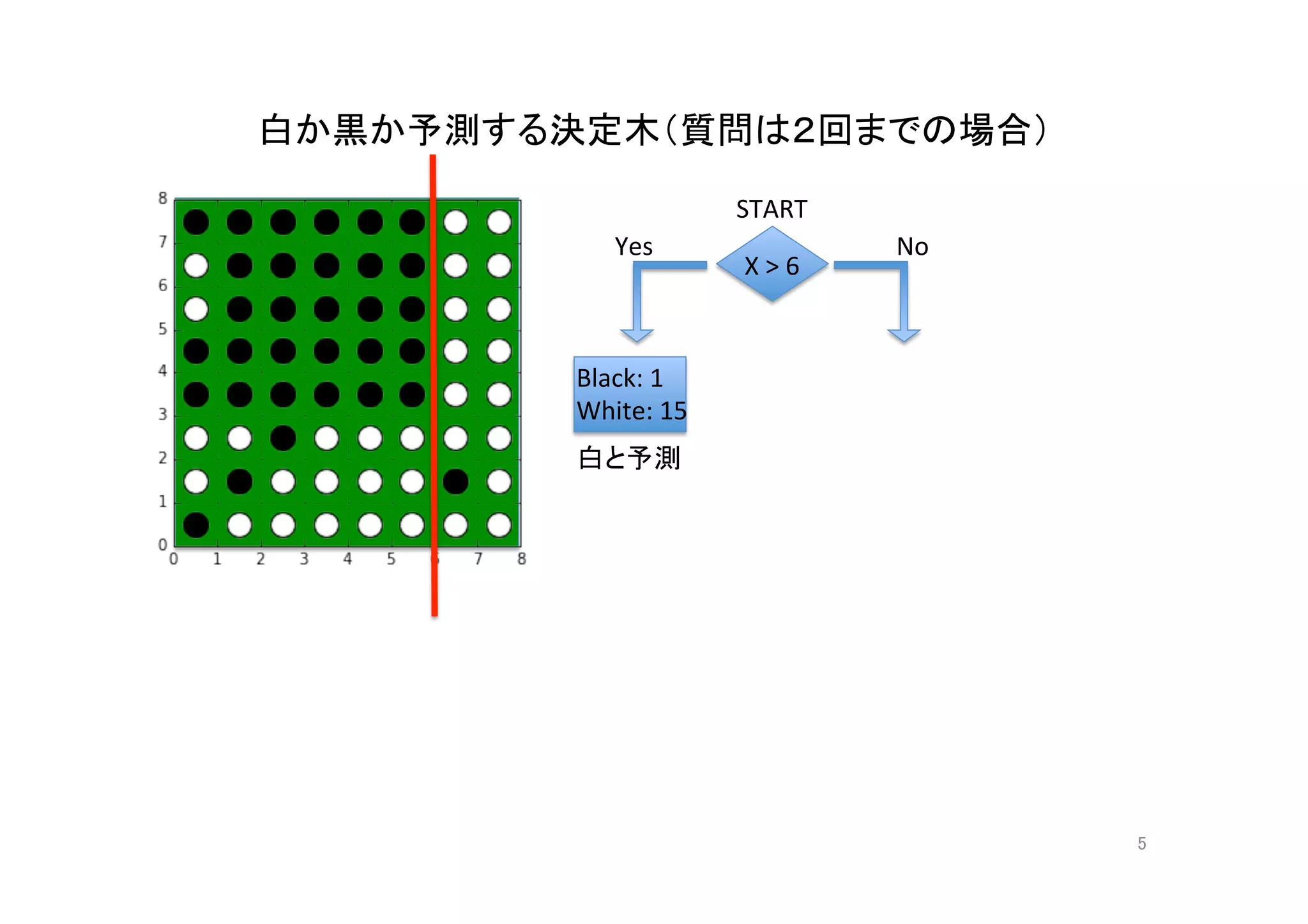
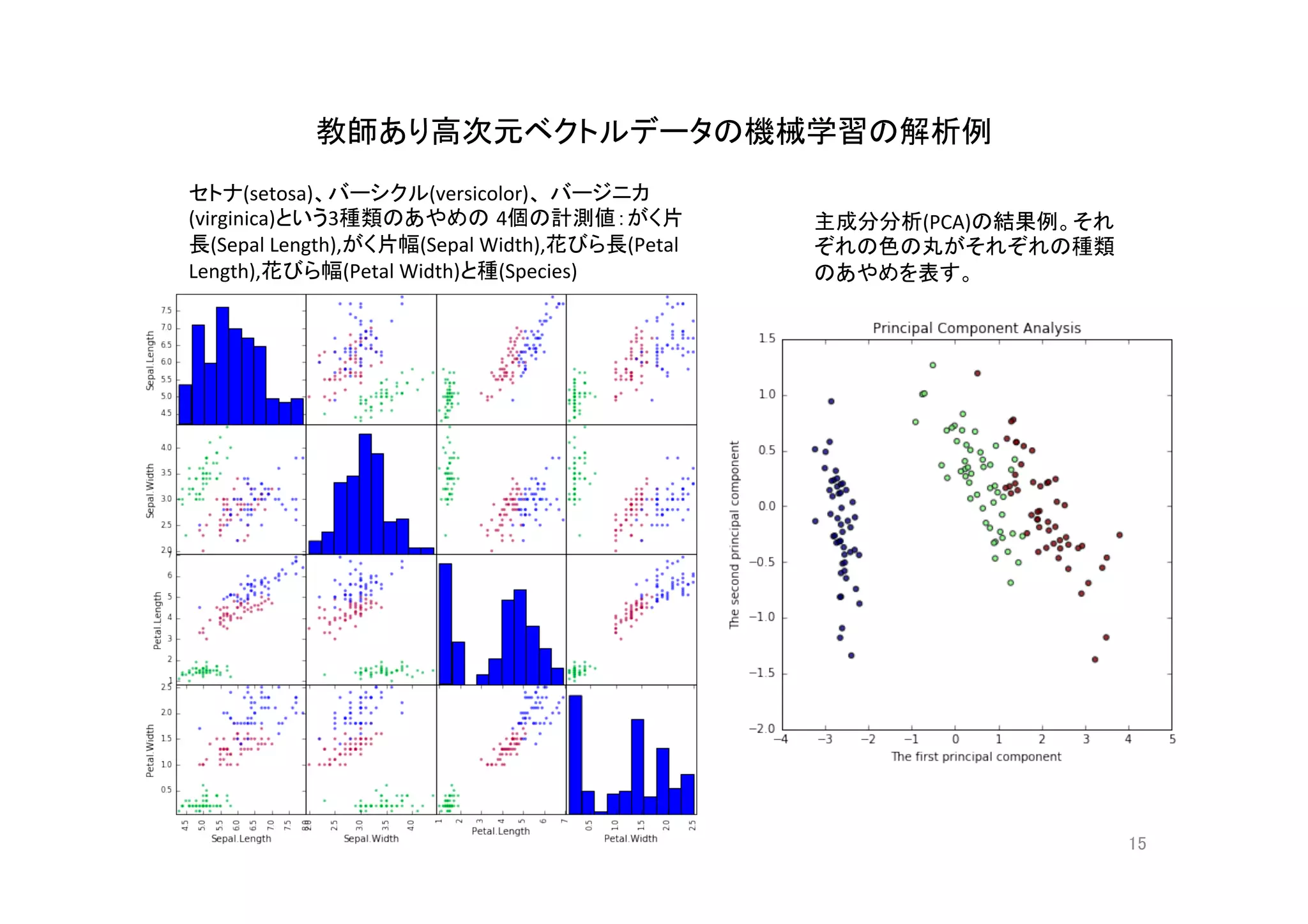
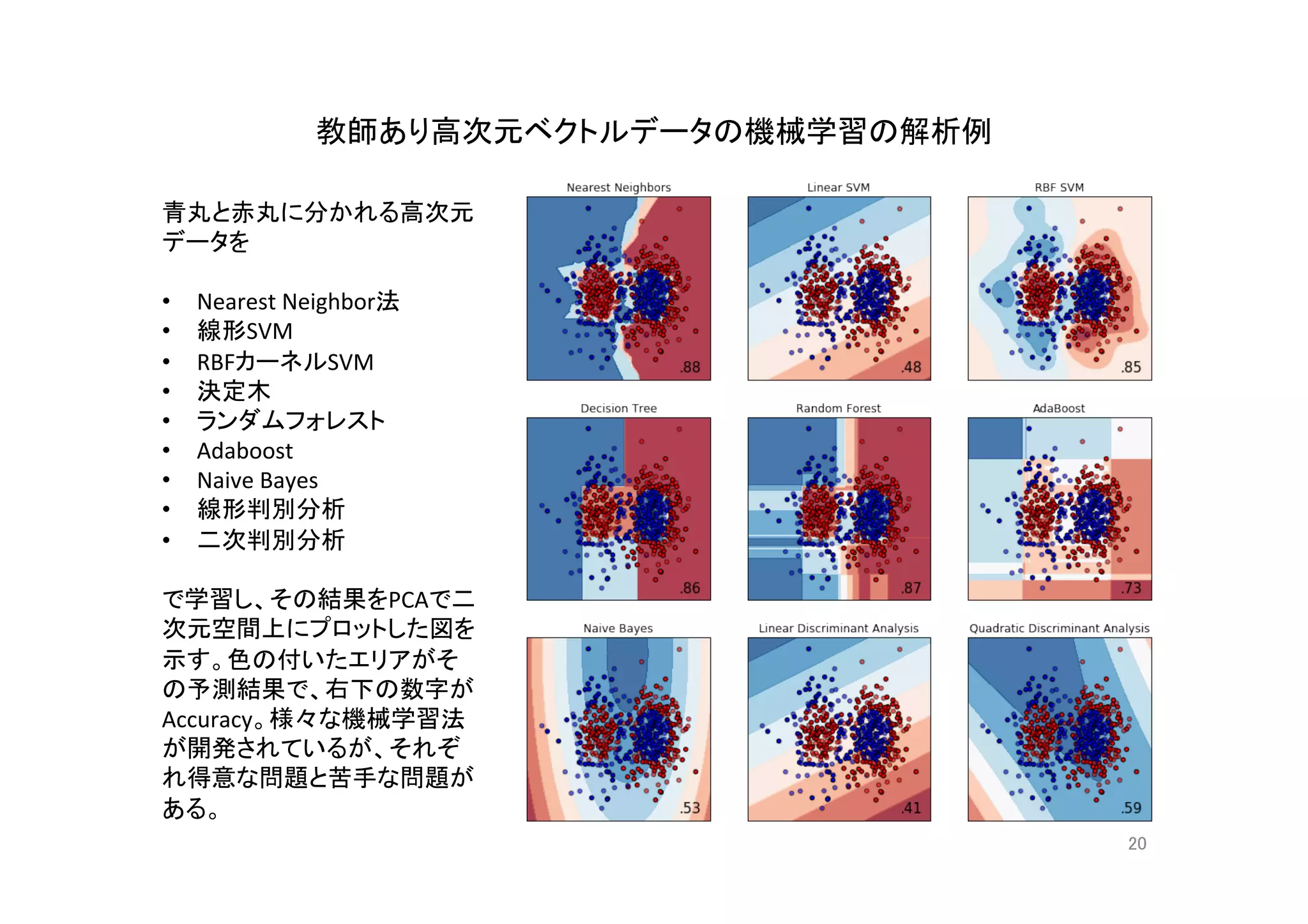
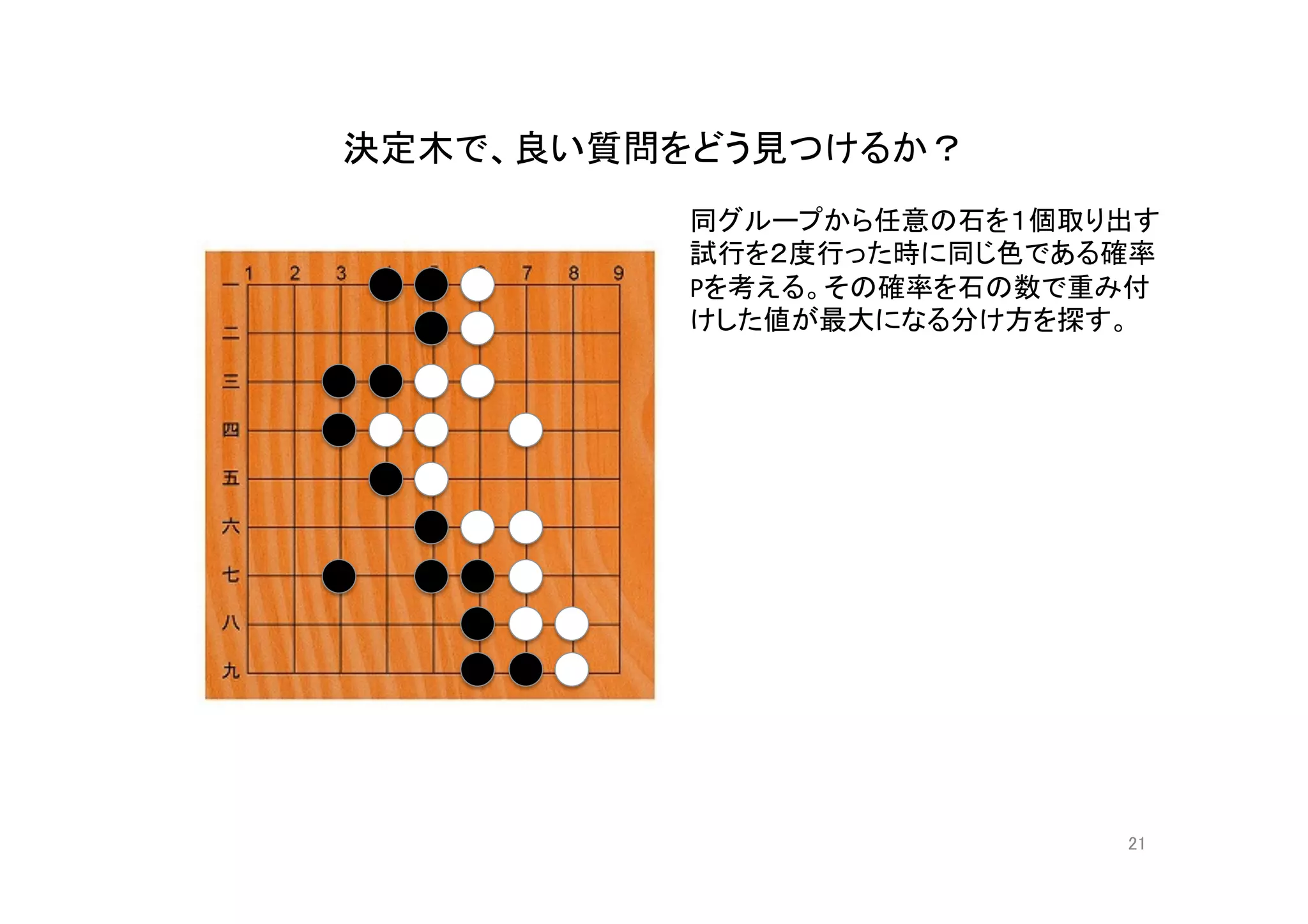
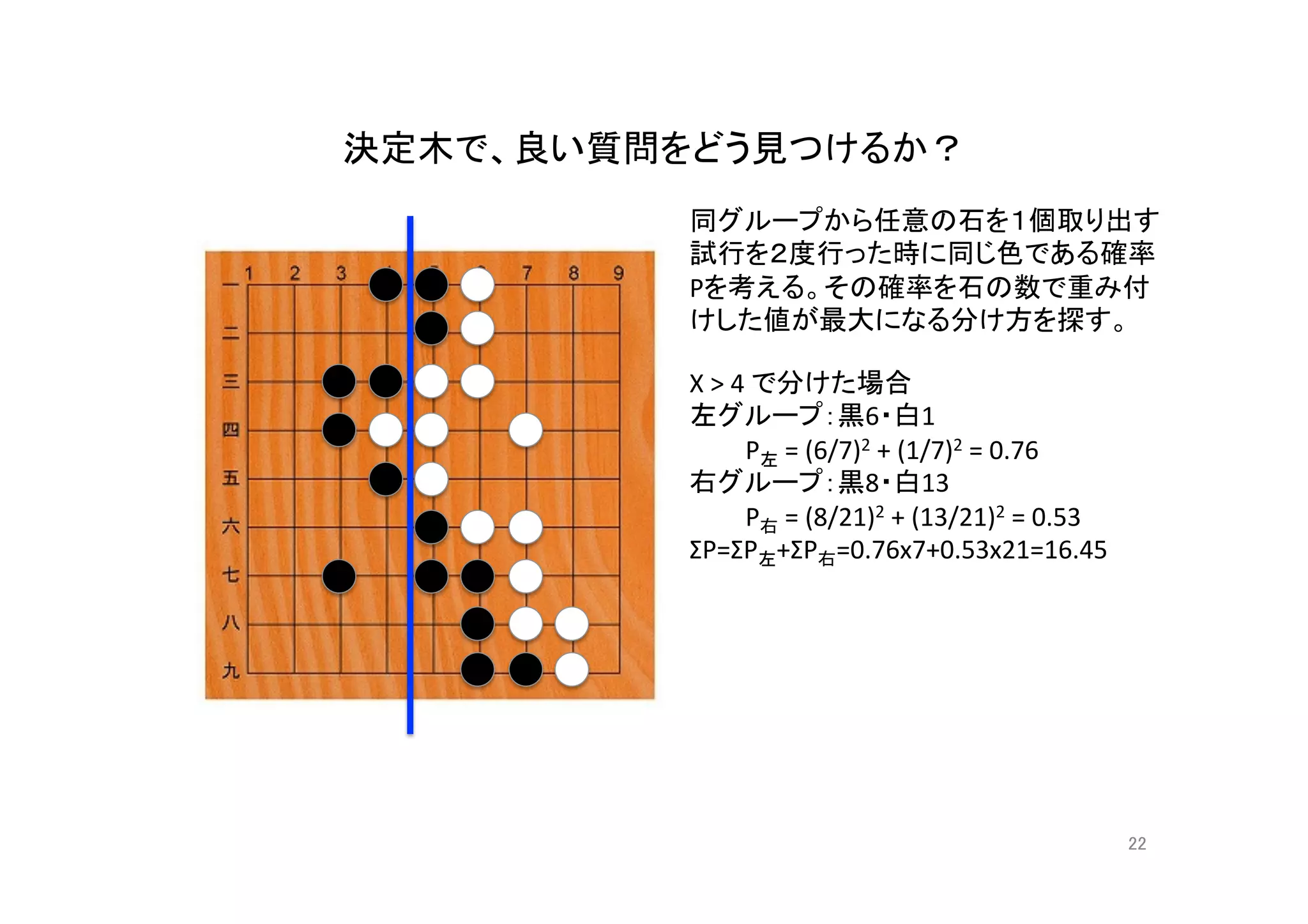
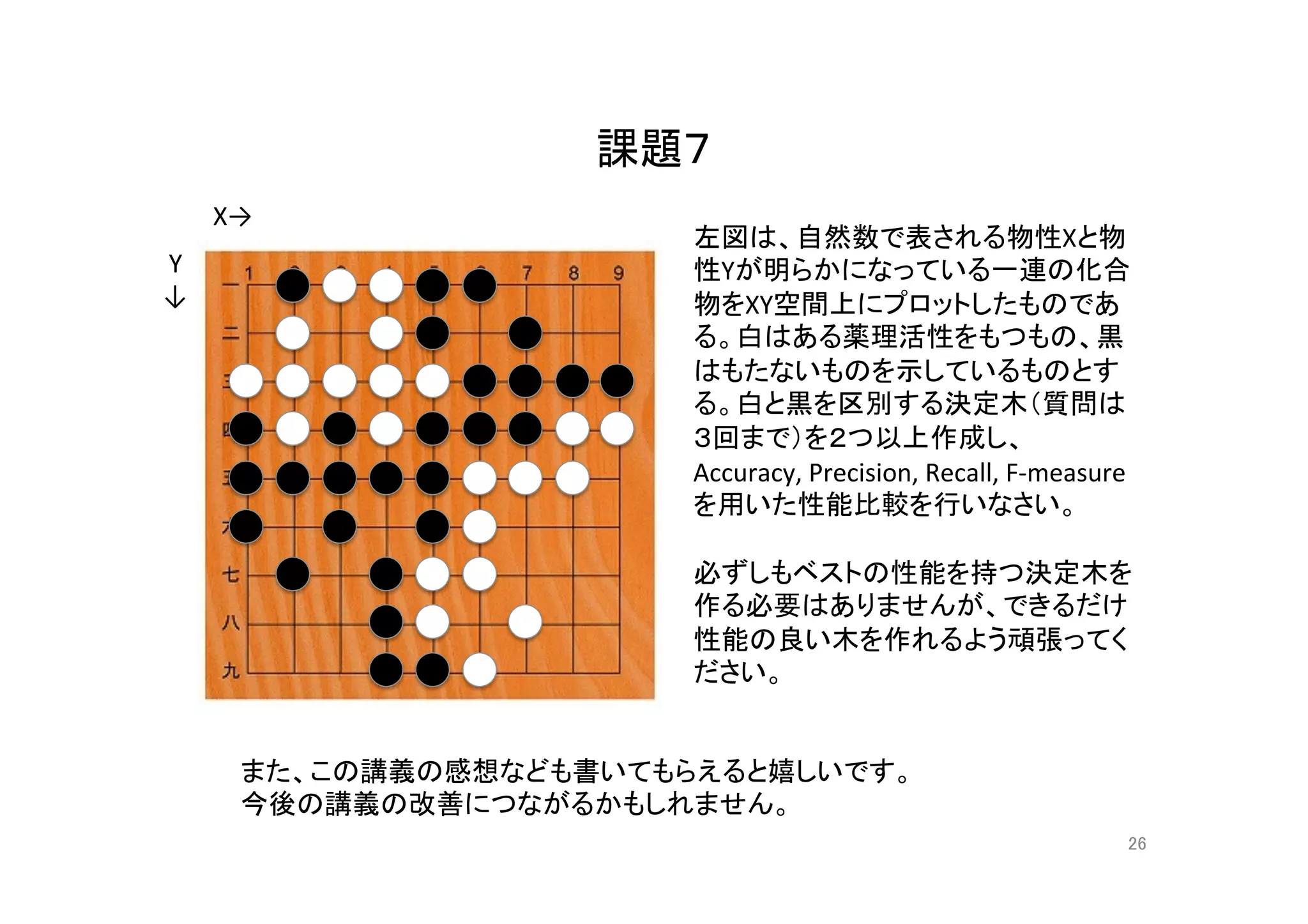
機械学習入門の入門
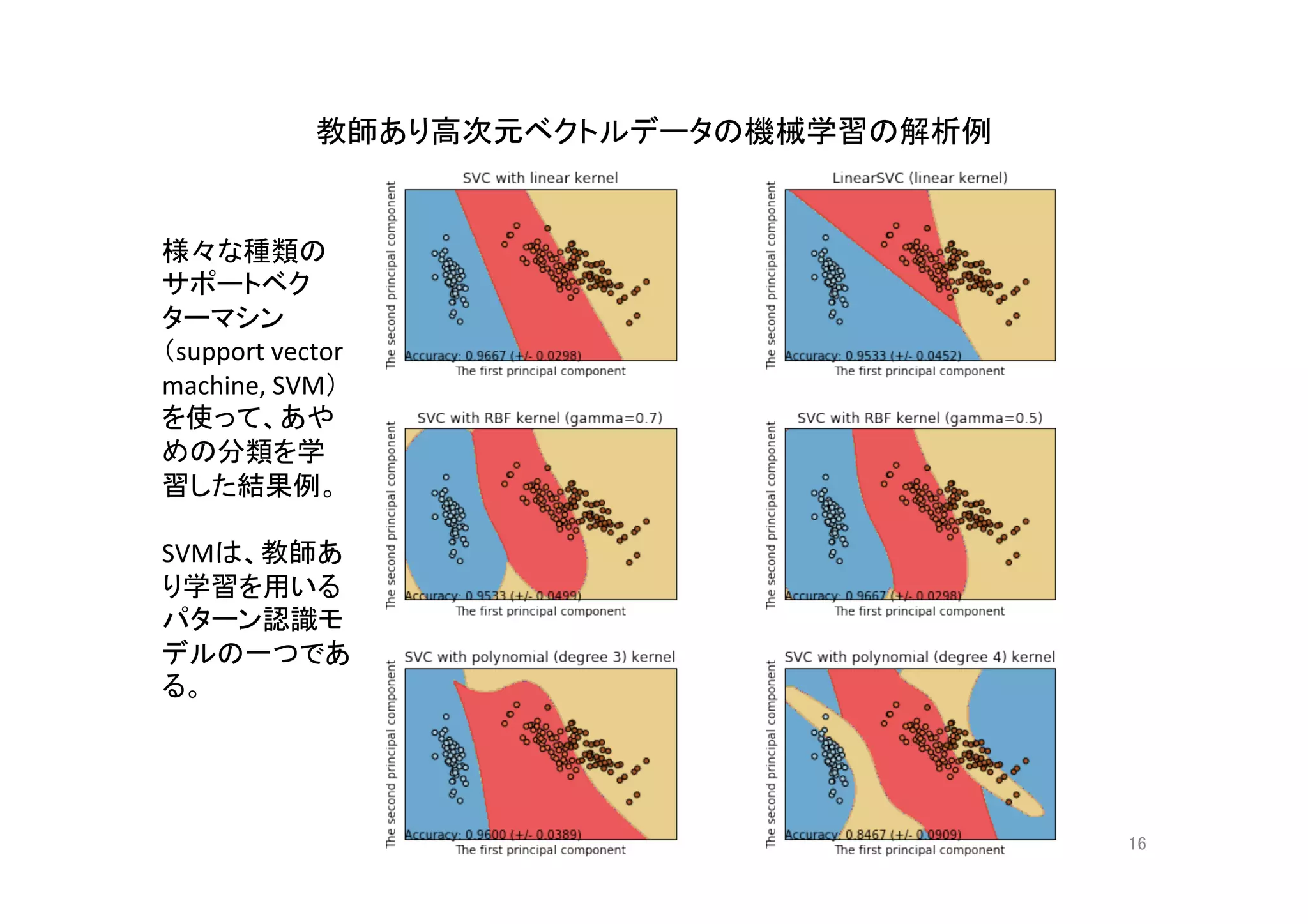
- 1.
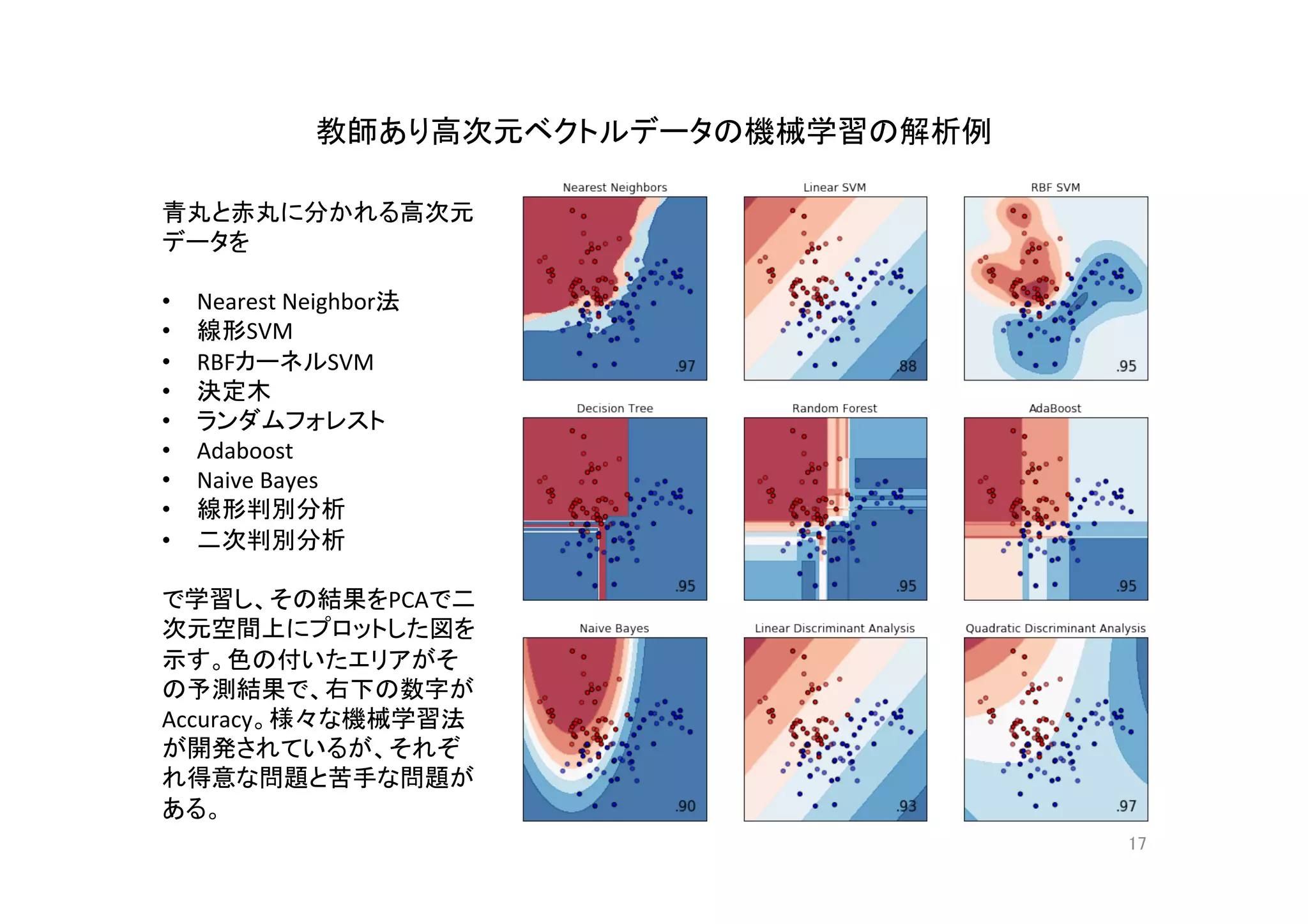
- 2.
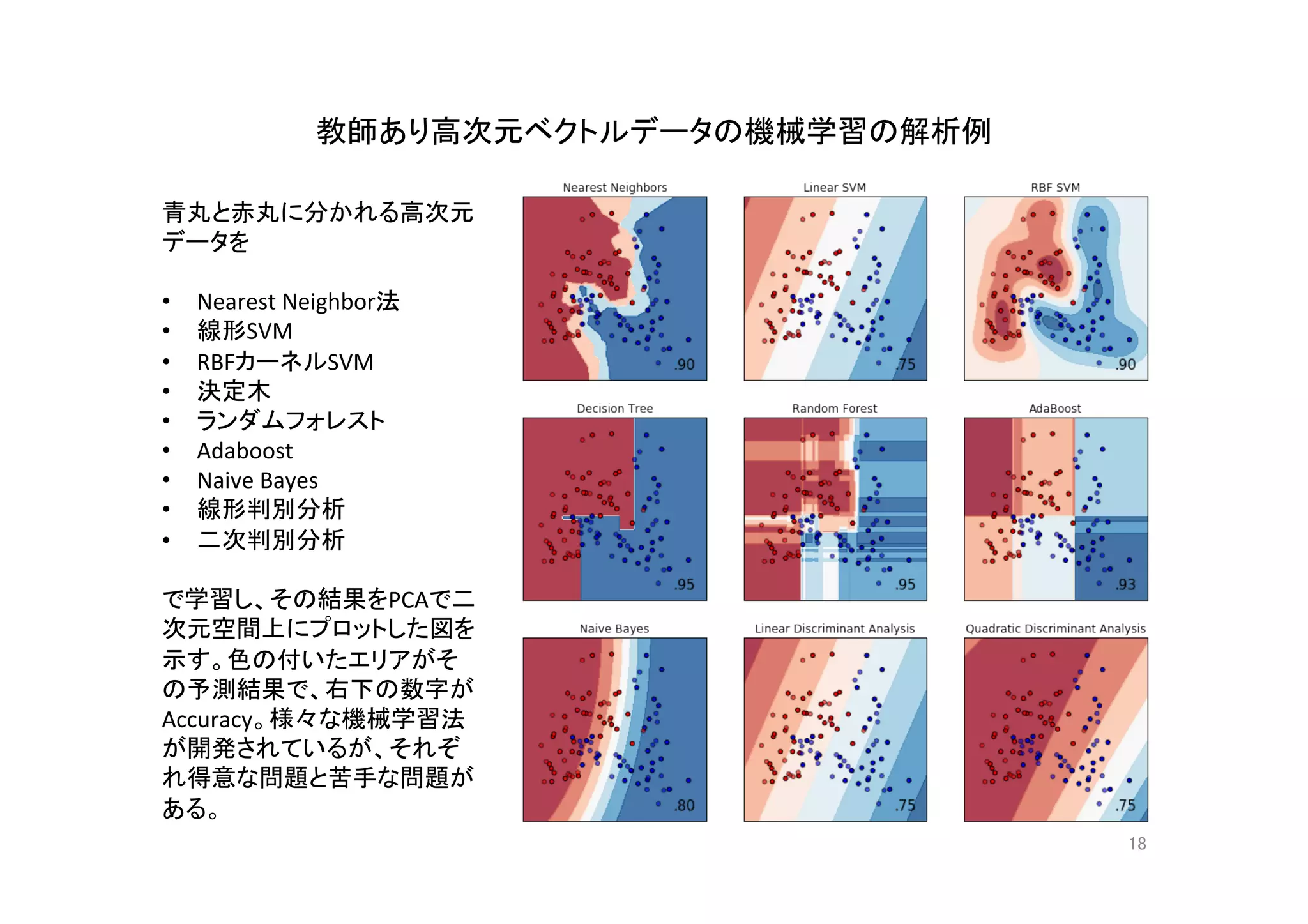
- 3.
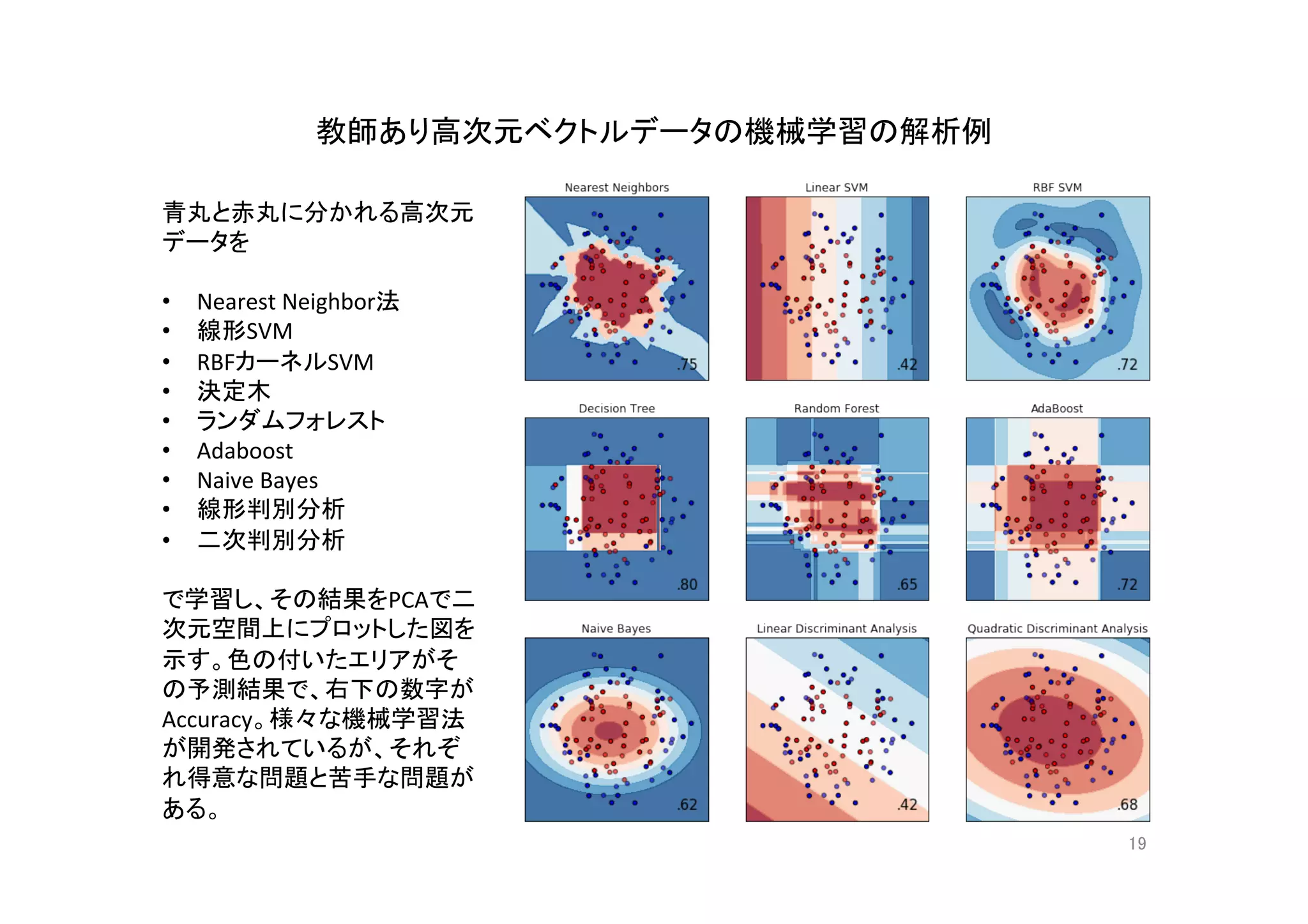
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
予測モデルの評価方法いろいろ
• Accuracy = (TP + TN) / (TP + FN + FP + TN)
– 正解率。予測結果全体と、答えがどれぐらい一致しているかを判断する指標。
• Precision = TP / (TP + FP)
– 適合率。予測を正と判断した中で、答えも正である割合。薬の設計などでは
一般に、Precisionが高い予測モデルが良しとされる。
• Recall = TP / (TP + FN)
– 再現率、回収率ともいう。答えが正の中で、予測が正とされた割合。病気の
診断などでは一般に、Recallが高い予測モデルが良しとされる。
• F-measure = 2 x Precision x Recall / (Precision + Recall)
– F値。PresicionとRecallの調和平均。一般にPrecisionとRecallは逆相関の関係
にあるので、バランスの良い予測をするためにF値を考えることがある。
• 「精度」という言葉はAccuracyの意味だったりPrecisionの意味だったり曖
昧なので、使用には注意されたい。
13
活性ありと予測 活性なしと予測
活性あり(陽性) True Posi@ve (TP) False Nega@ve (FN)
活性なし(陰性) False Posi@ve (FP) True Nega@ve (TN)
- 14.
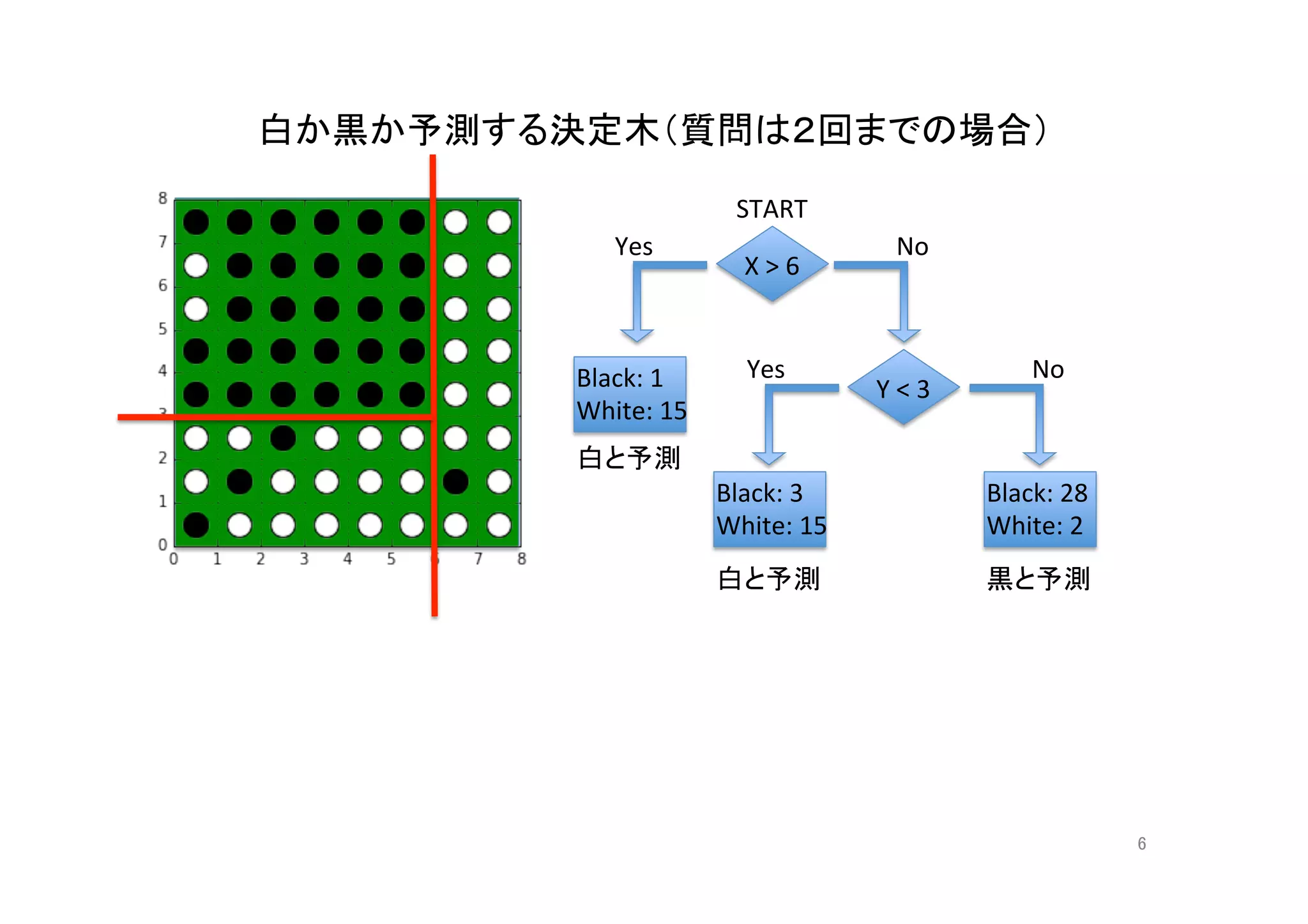
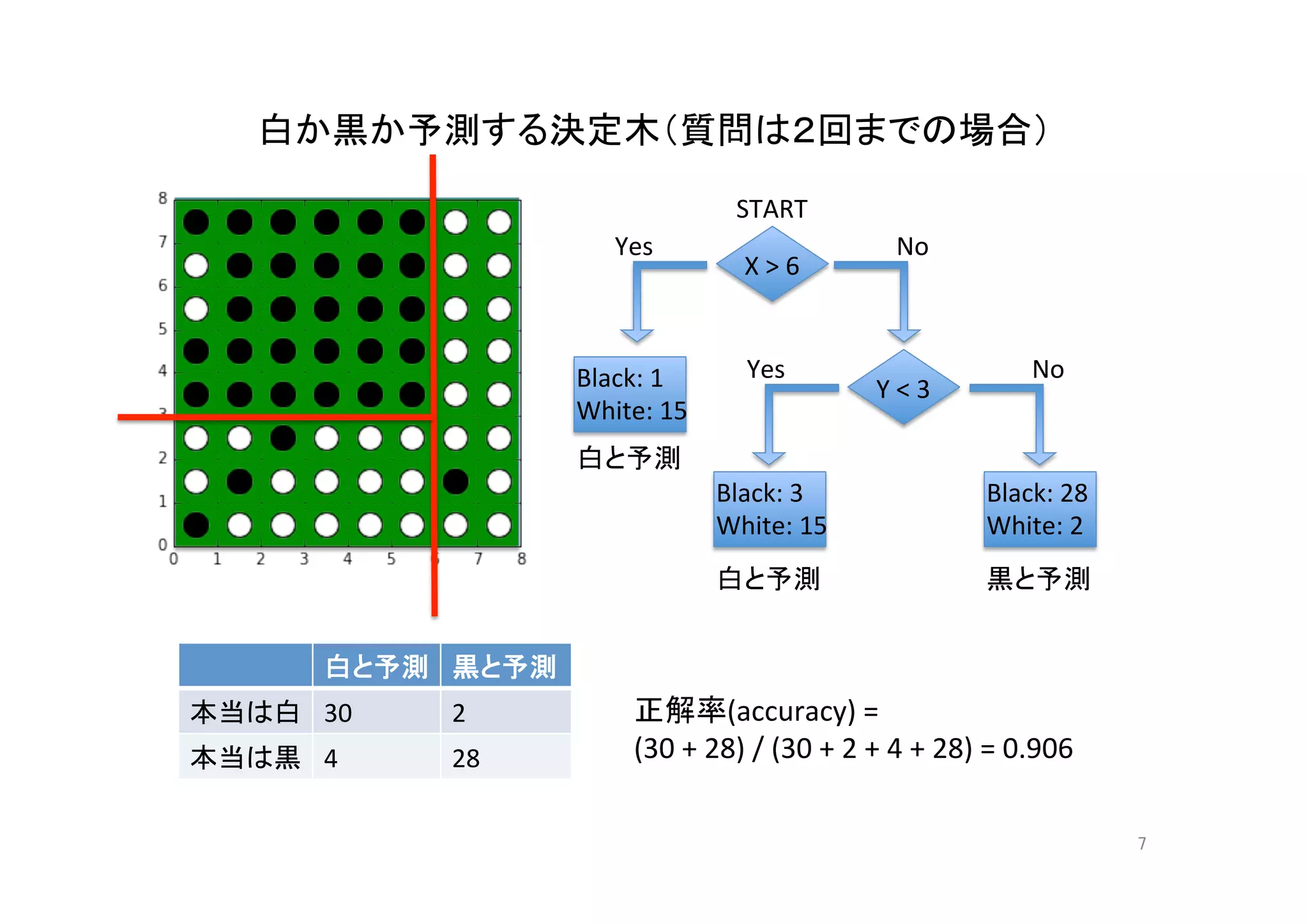
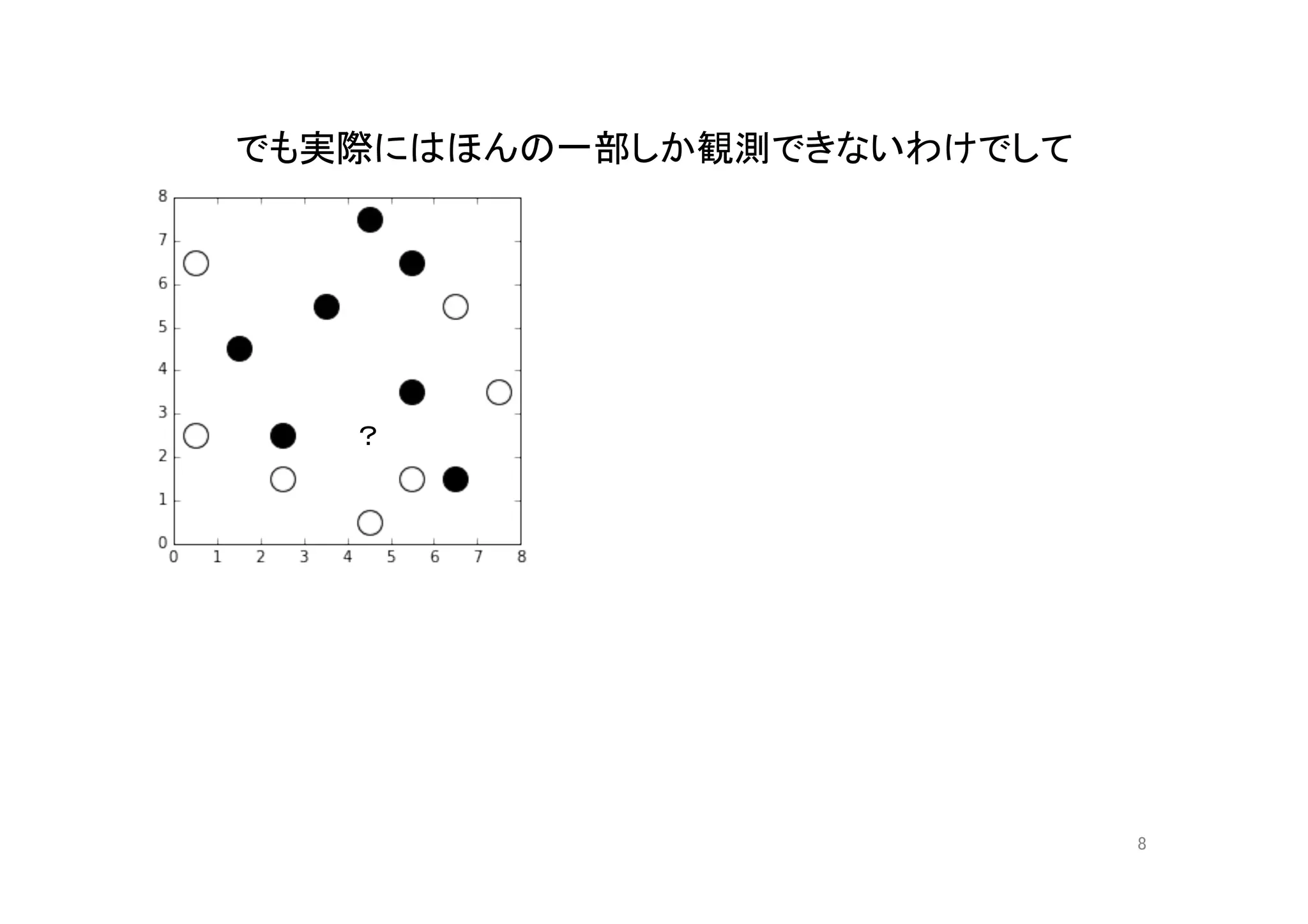
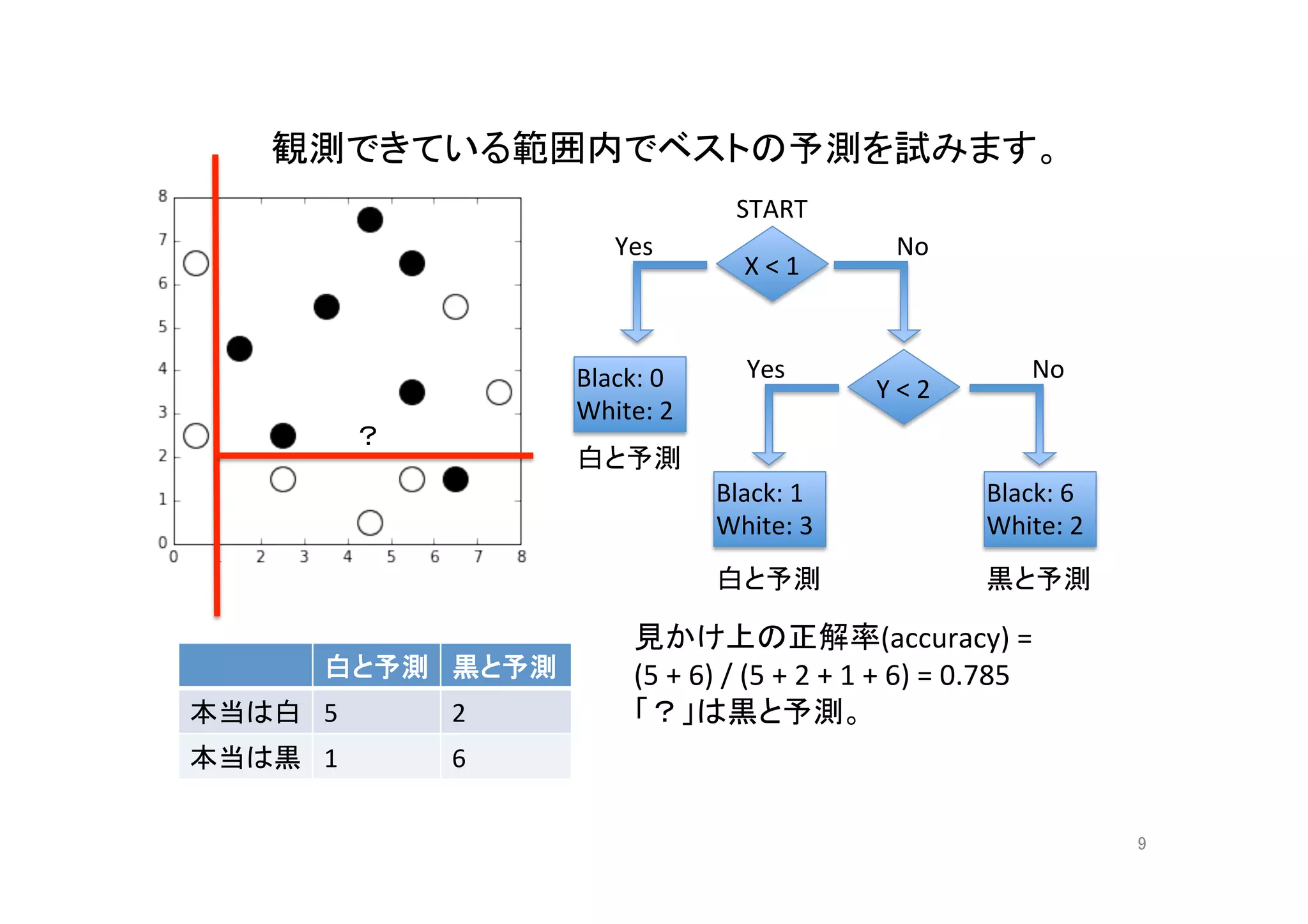
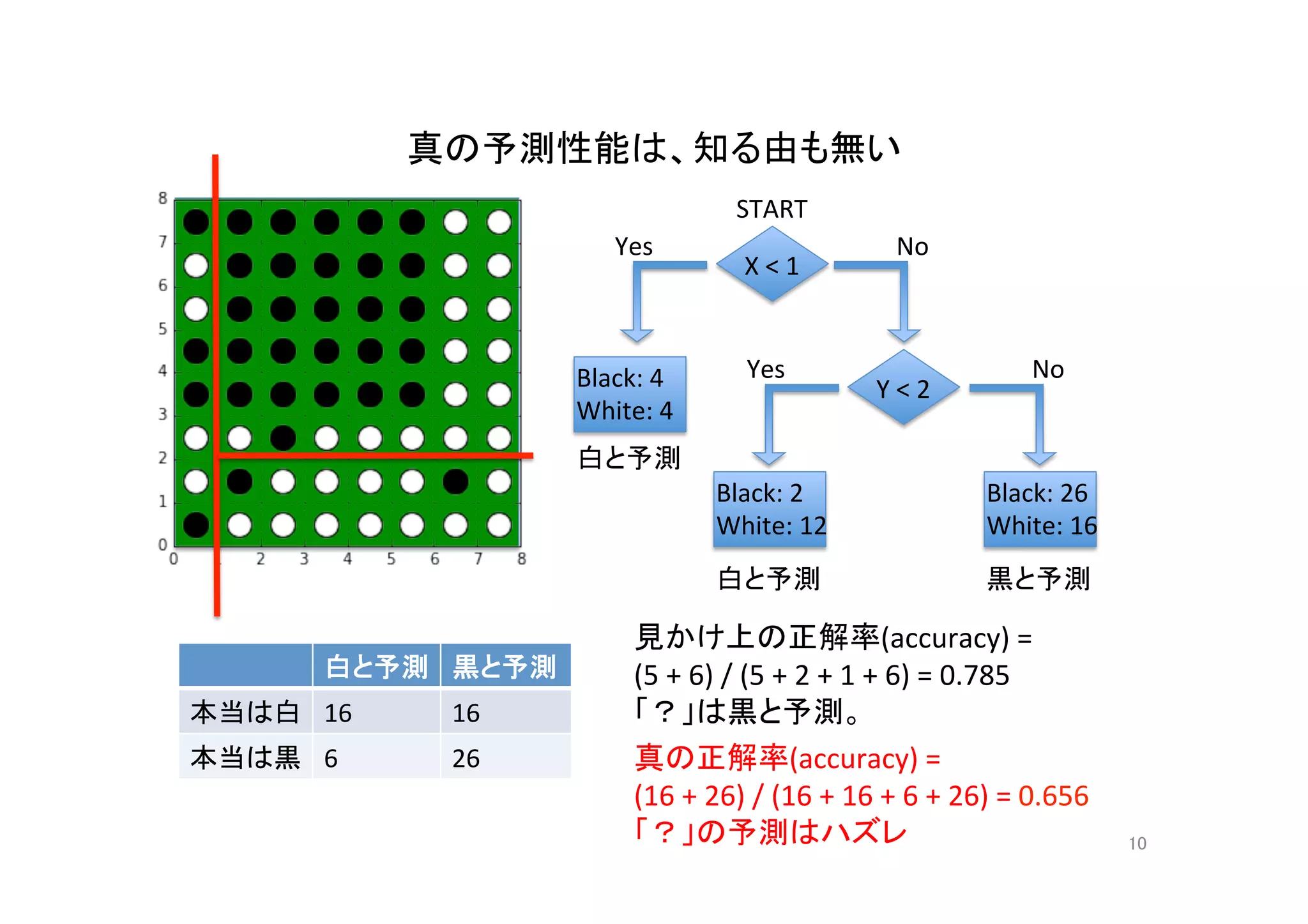
決定木(質問は3回まで)の
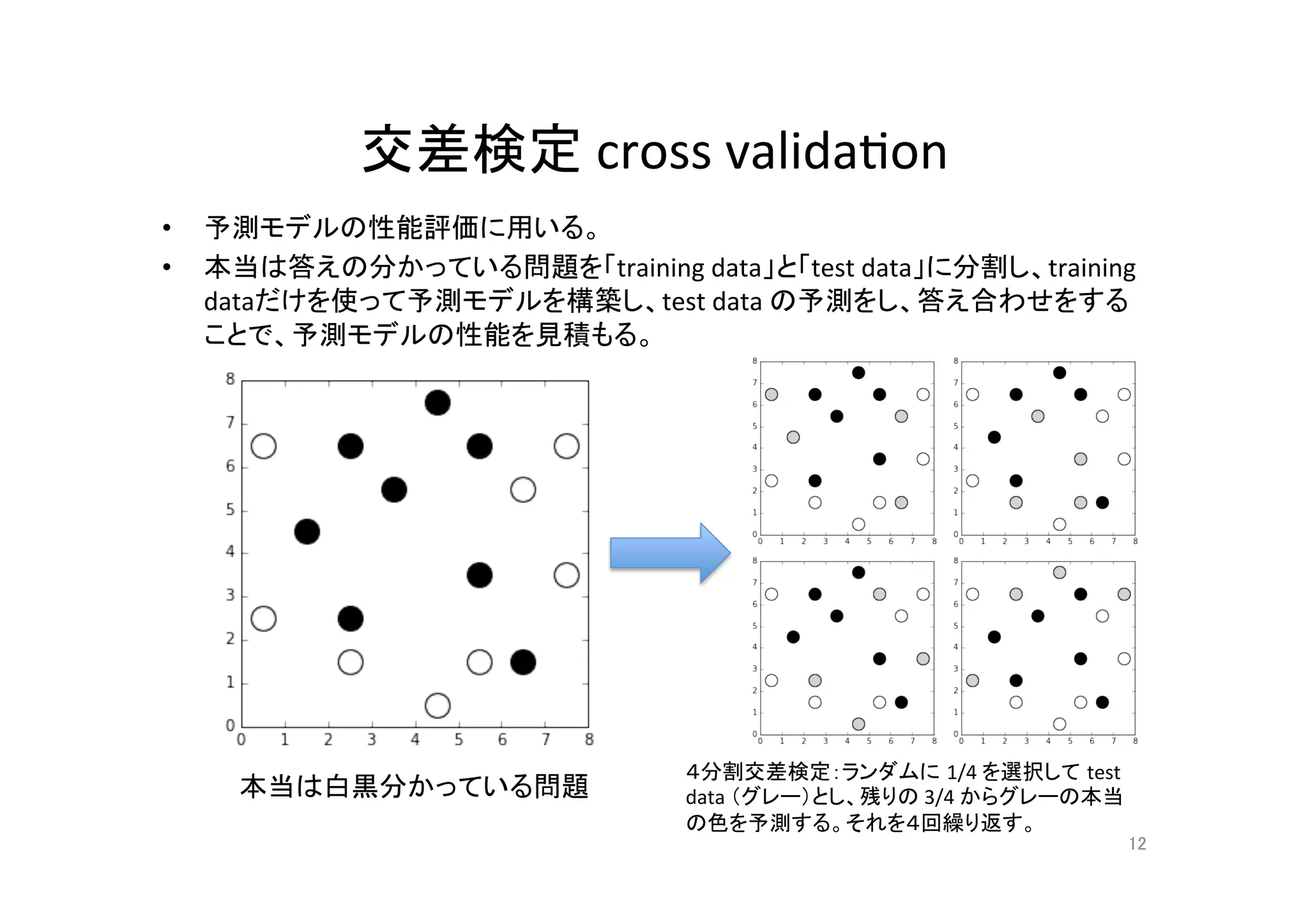
4分割交差検定 4-fold cross valida@on
14
答え
白
白
白 白
白
白
白
白
白
白 白 黒
黒
黒
黒
黒
予測
白
予測
黒
本当
白
1 1
本当
黒
2 0
予測
白
予測
黒
本当
白
2 0
本当
黒
0 2
予測
白
予測
黒
本当
白
2 0
本当
黒
2 0
予測
白
予測
黒
本当
白
2 0
本当
黒
0 2
Accuracy =
(1+0)/4 = 0.25
Precision =
1/(1+2) = 0.33
Recall =
1/(1+1) = 0.50
F-measure =
0.40
Accuracy =
(2+2)/4 = 1.0
Precision =
2/(2+0) = 1.0
Recall =
2/(2+0) = 1.0
F-measure =
1.0
Accuracy =
(2+0)/4 = 0.50
Precision =
2/(2+2) = 0.50
Recall =
2/(2+0) = 1.0
F-measure =
0.67
Accuracy =
(2+2)/4 = 1.0
Precision =
2/(2+0) = 1.0
Recall =
2/(2+0) = 1.0
F-measure =
1.0
Accuracy =
0.6875
Precision =
0.71
Recall =
0.88
F-measure =
0.77
予測モデルの
平均性能
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.