





















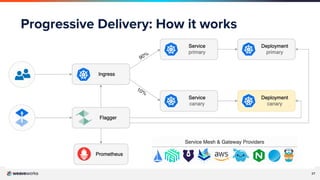
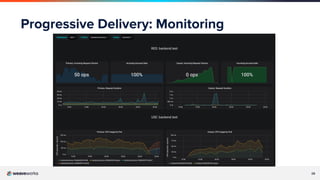
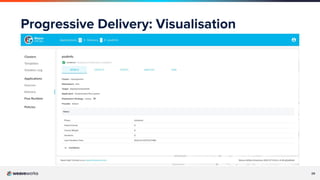






The document covers a webinar led by Chris Lavery, a Senior Site Reliability Engineer at Weaveworks, discussing GitOps and Site Reliability Engineering (SRE). It highlights the importance of data-driven decisions, service level indicators (SLIs), service level objectives (SLOs), and the role of progressive delivery in managing deployment risks. The presentation emphasizes balancing feature availability with deployment velocity to enhance both operational efficiency and service reliability.






































![Site-Reliability-Engineering-v2[6241].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/site-reliability-engineering-v26241-221023035909-82e9559b-thumbnail.jpg?width=640&height=640&fit=bounds)
















































