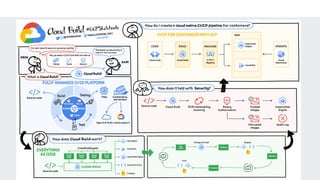
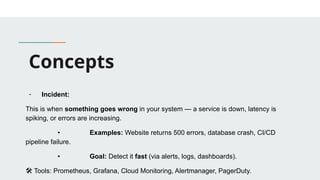
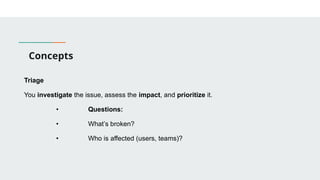
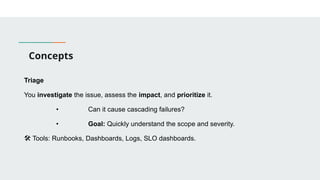
This presentation introduces the key principles of DevOps and Site Reliability Engineering (SRE). Learn how modern teams use automation, monitoring, CI/CD, and reliability practices to build scalable and resilient systems. Perfect for beginners and professionals seeking to understand the culture, tools, and mindset behind high-performing tech teams.


























































![Site-Reliability-Engineering-v2[6241].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/site-reliability-engineering-v26241-221023035909-82e9559b-thumbnail.jpg?width=640&height=640&fit=bounds)




























