Download to read offline






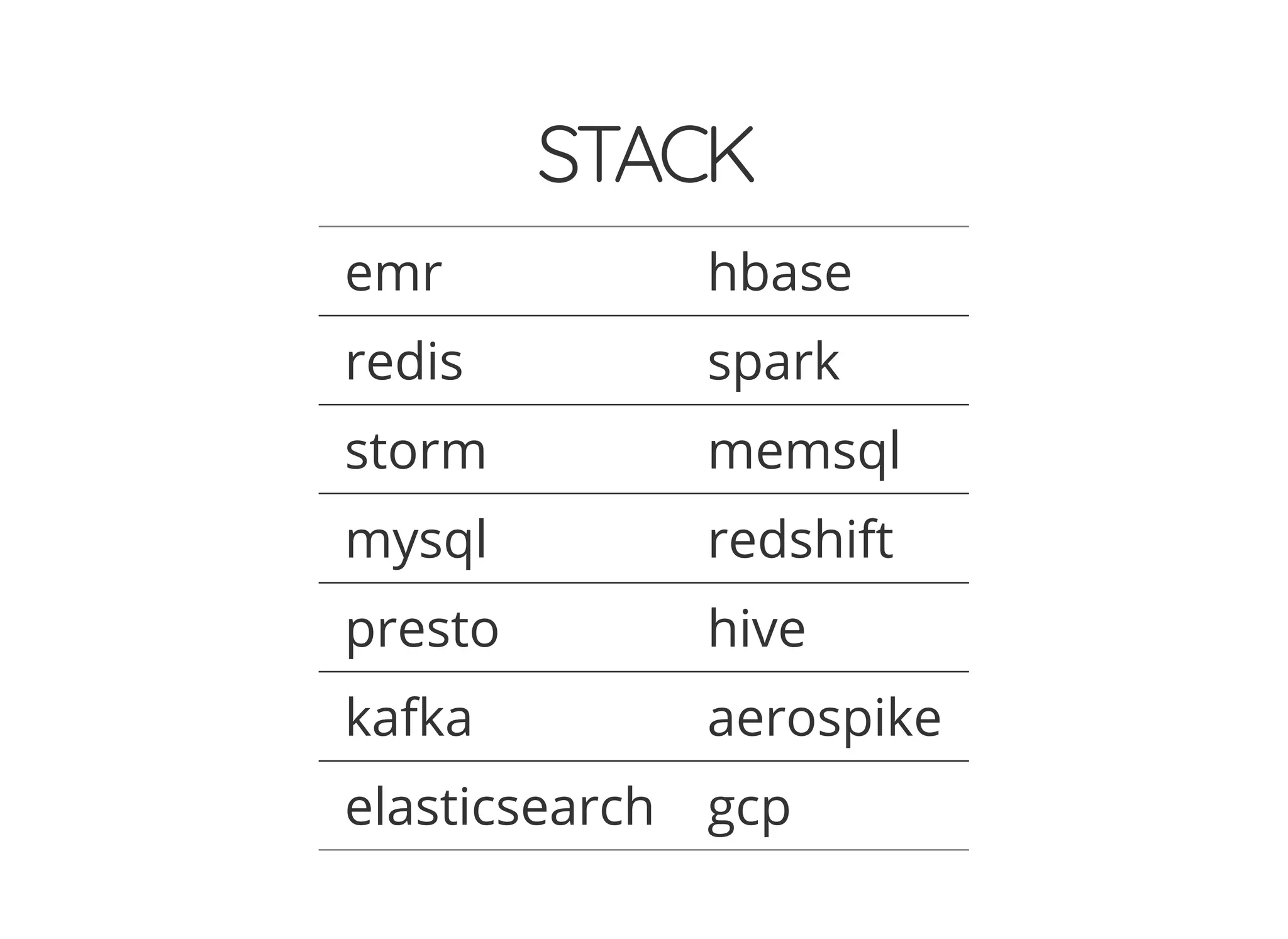


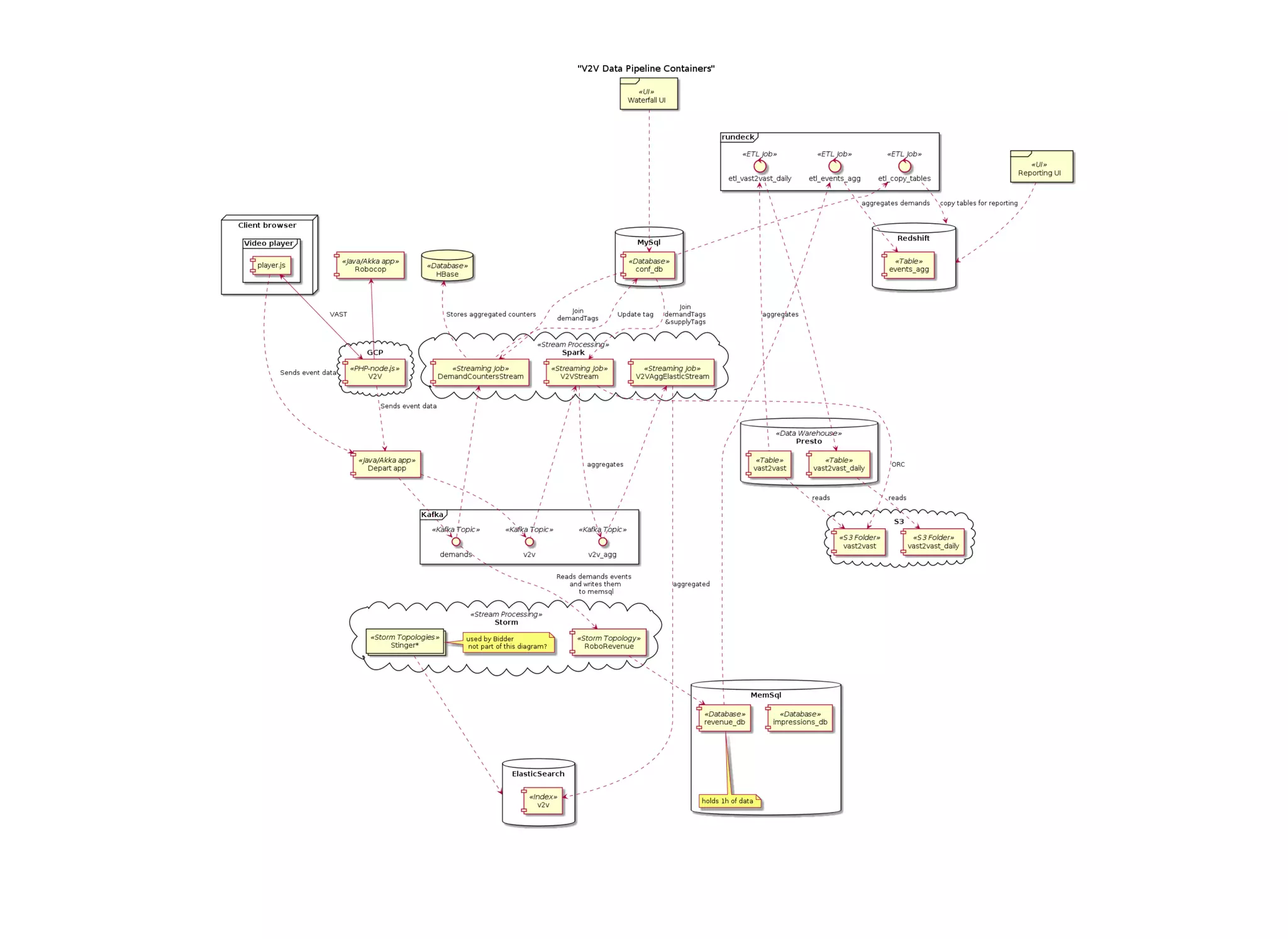




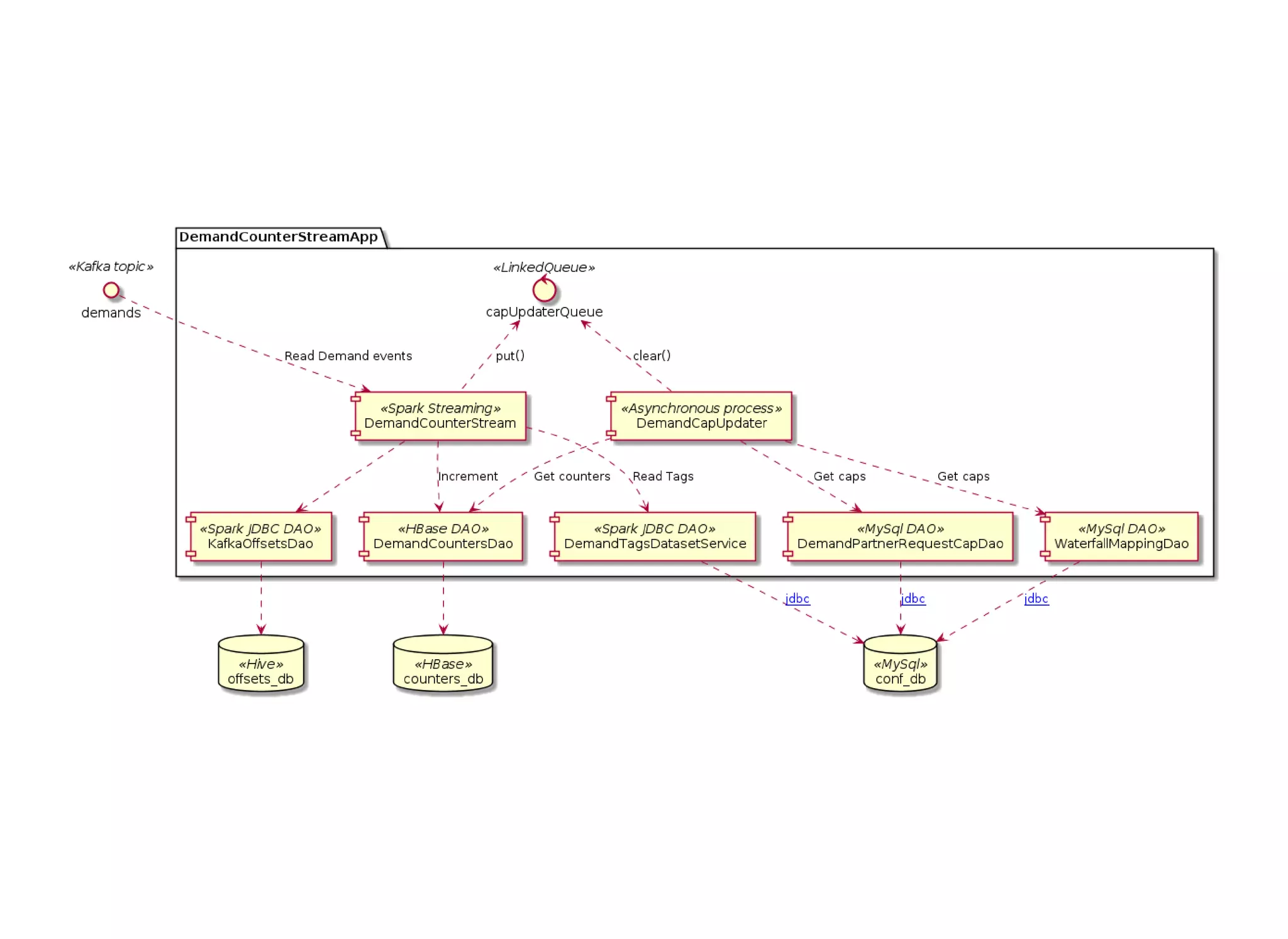



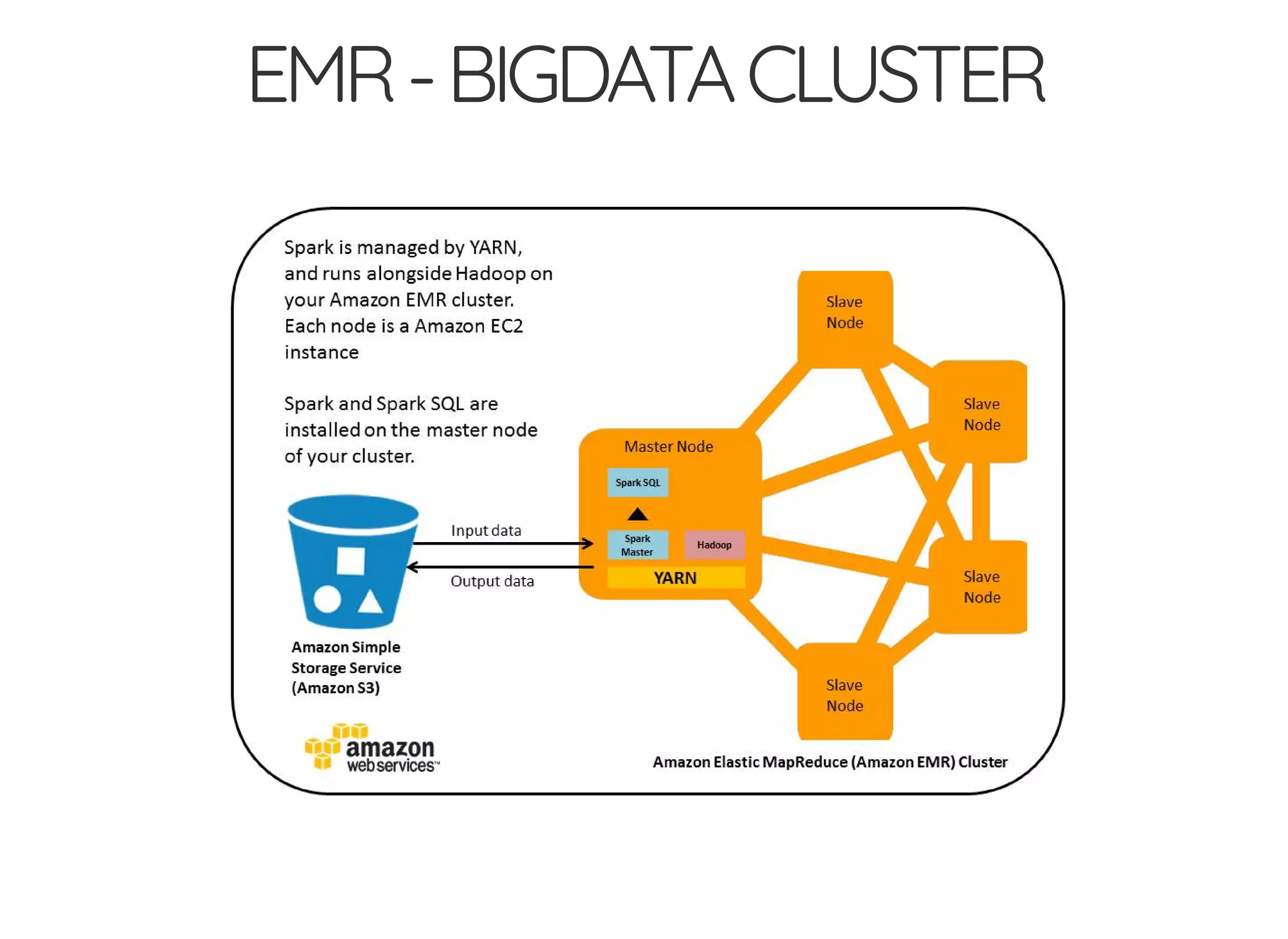
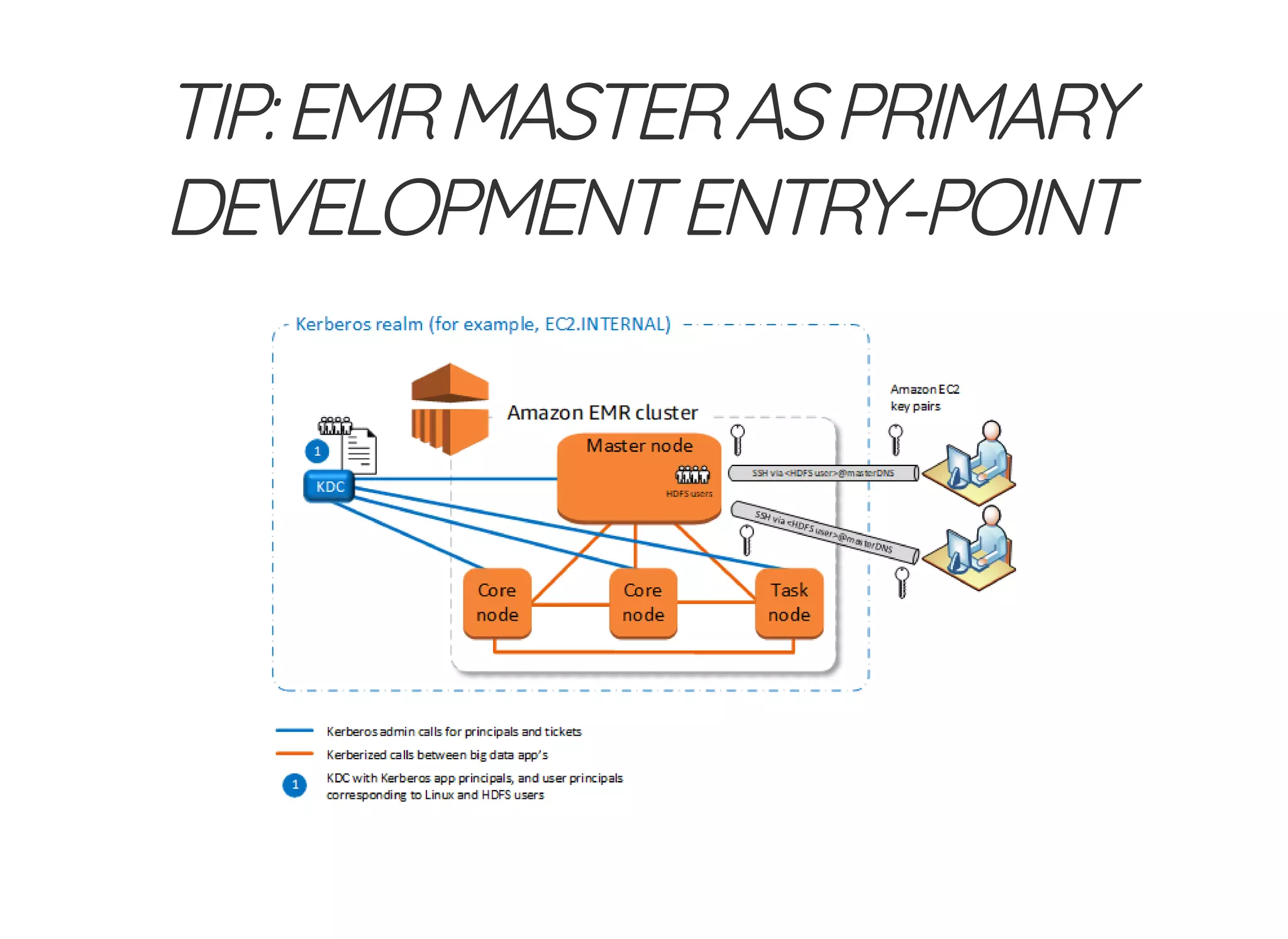














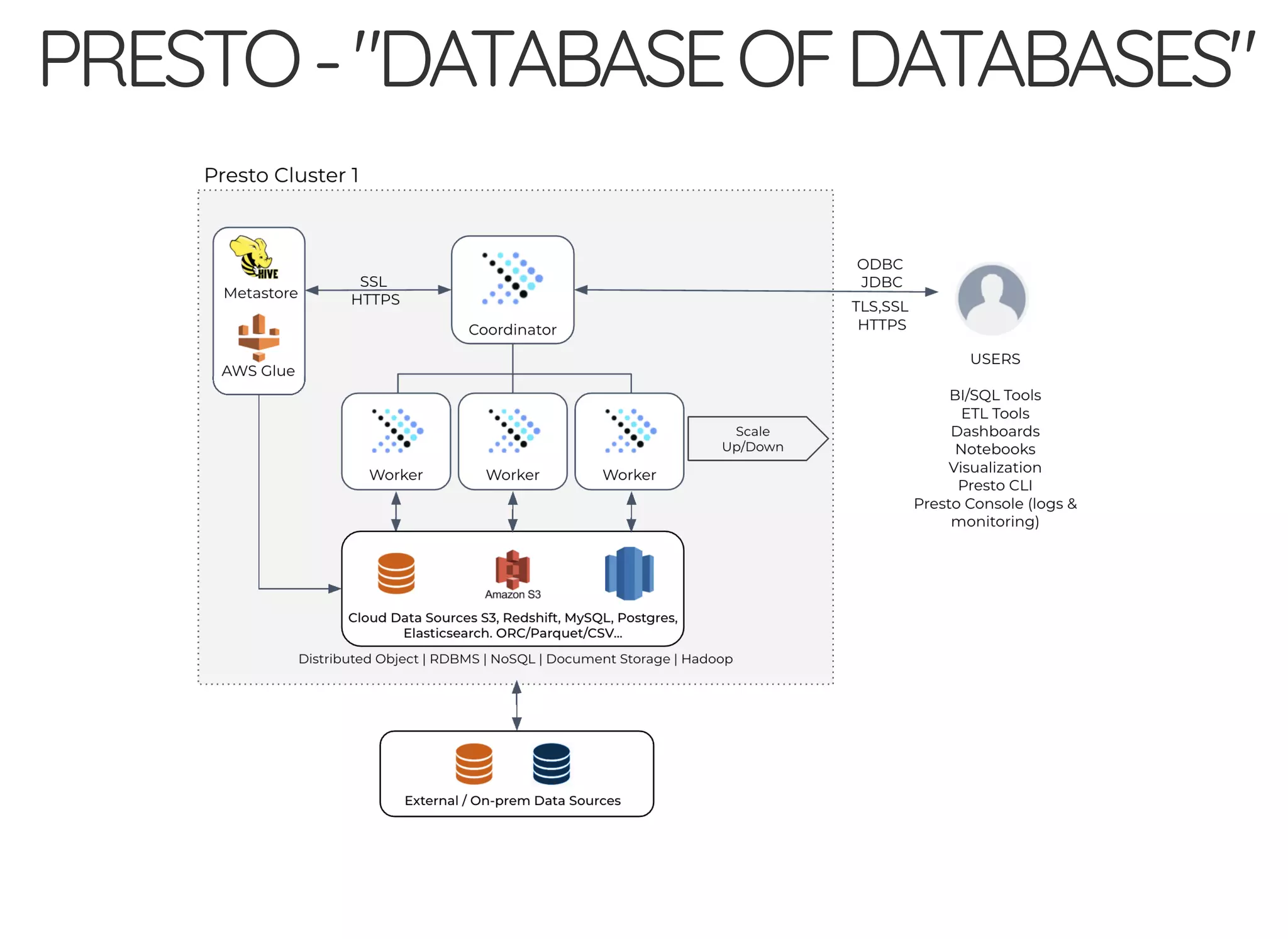


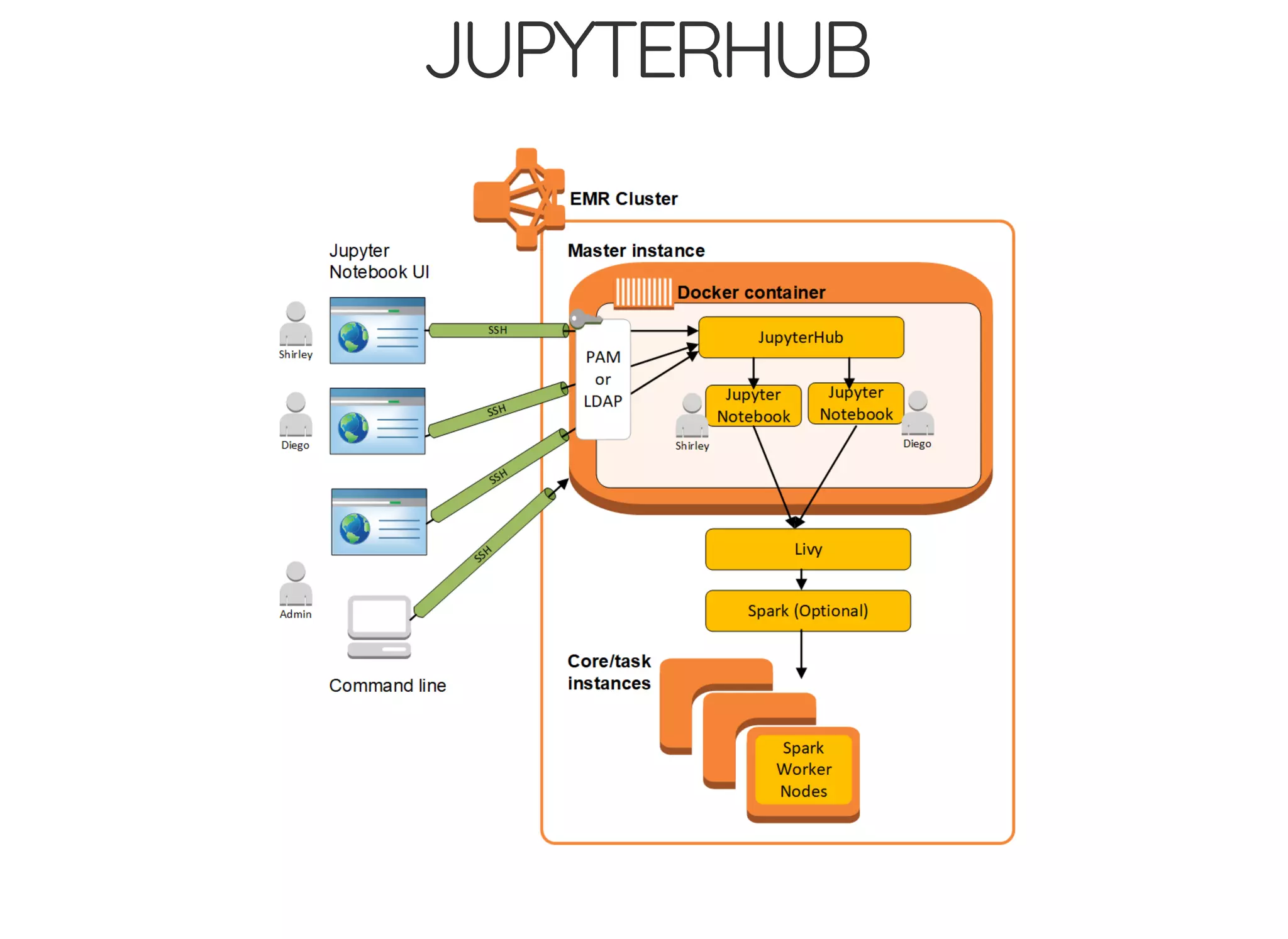
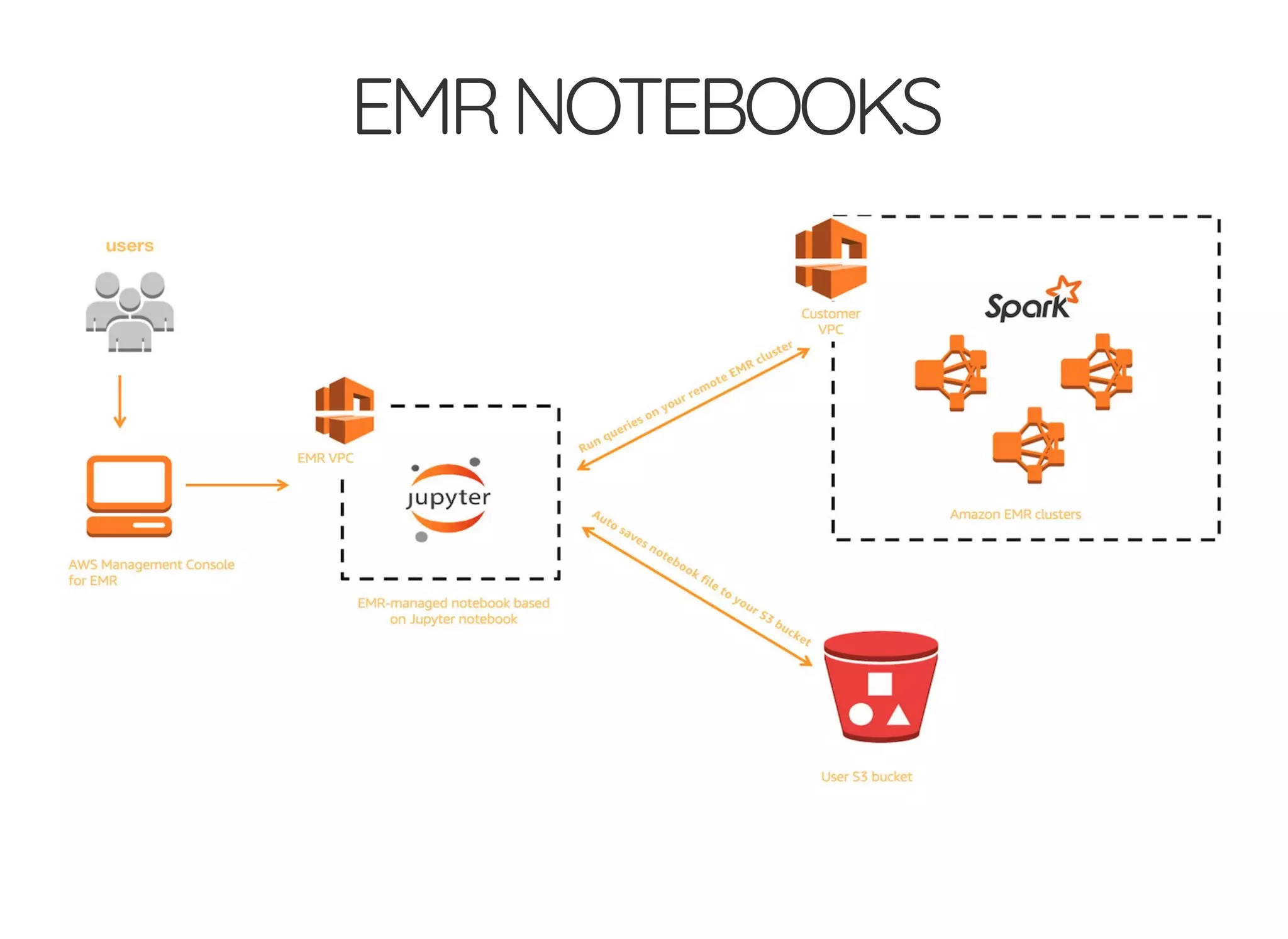
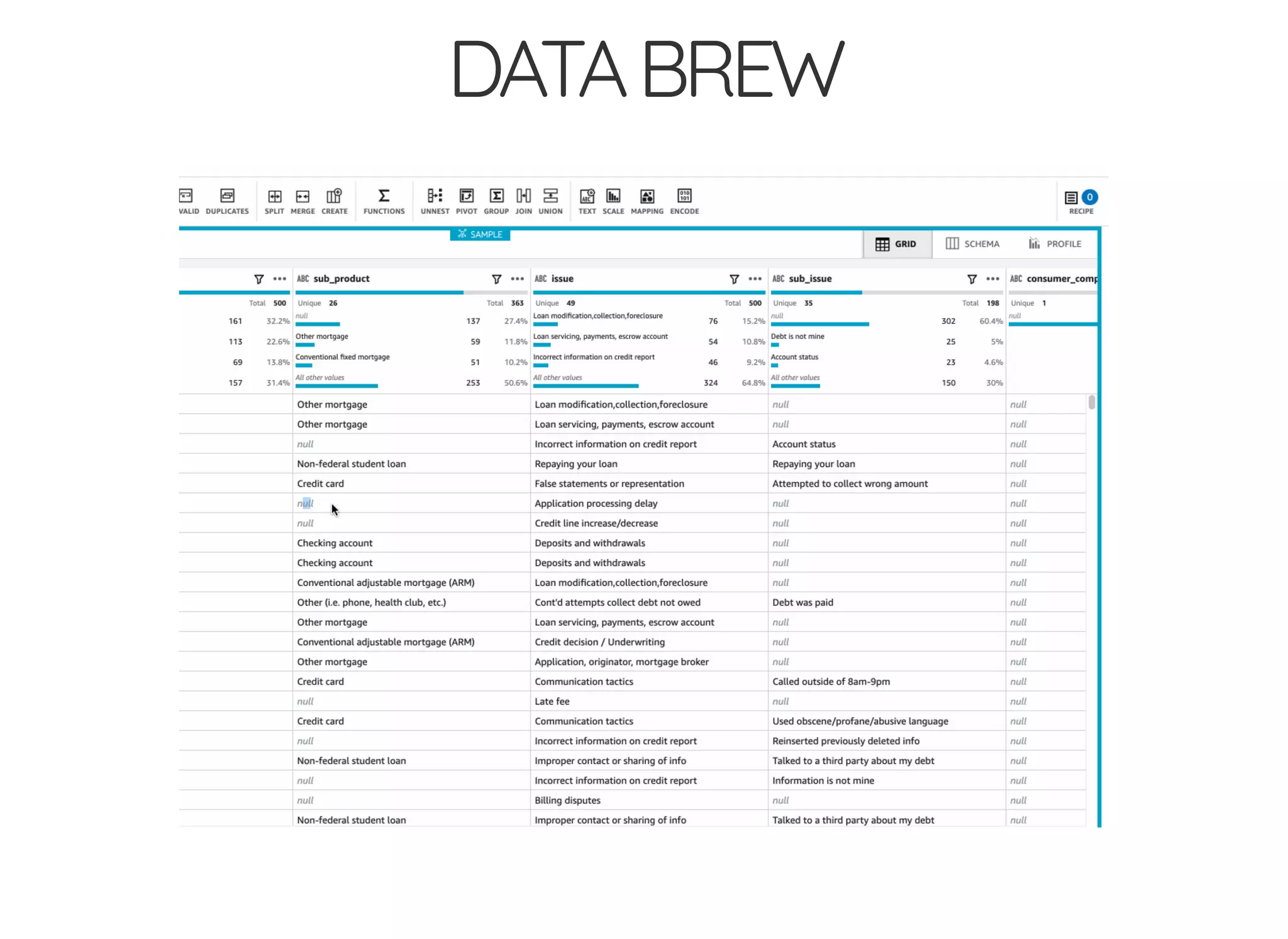
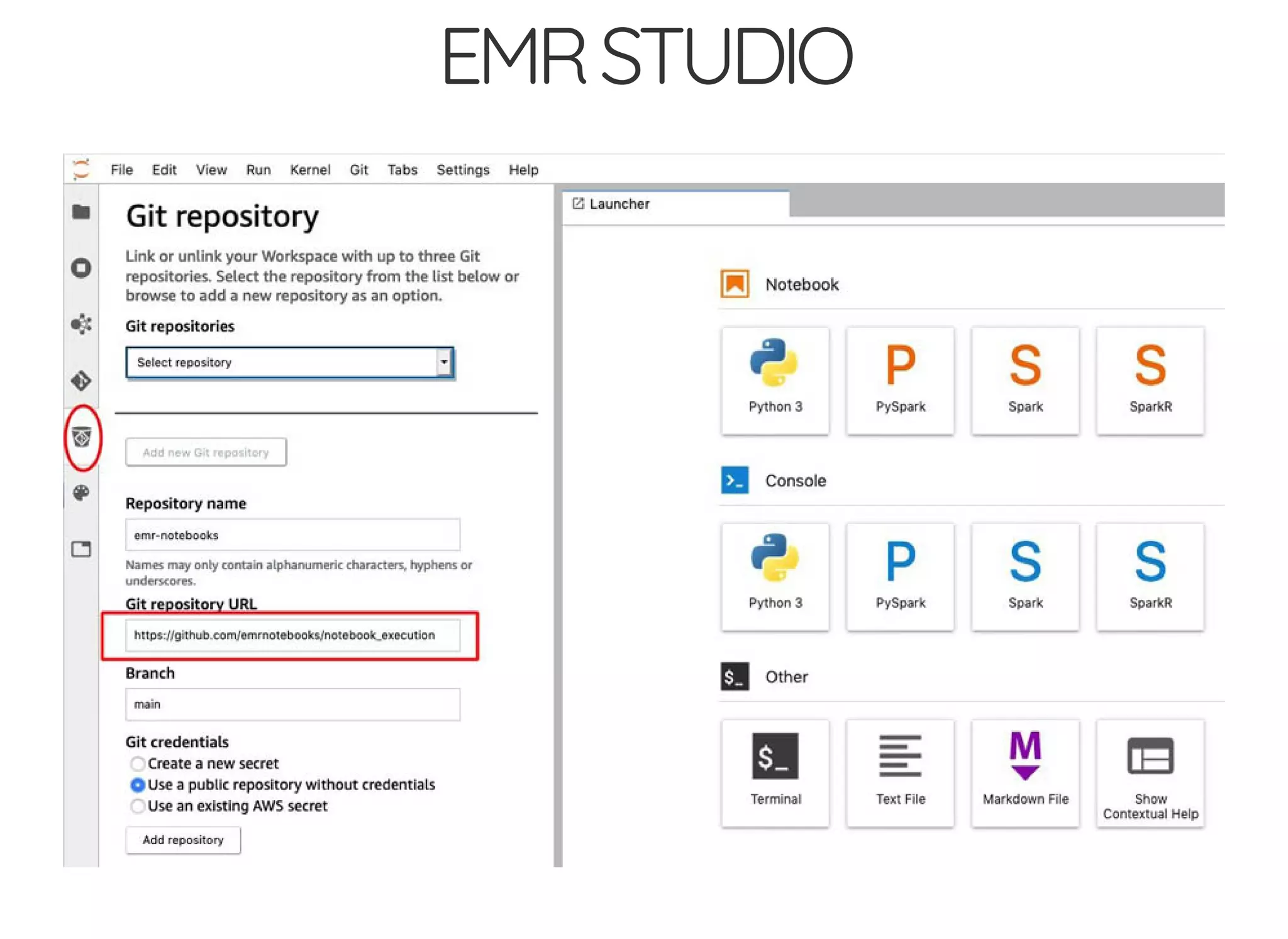


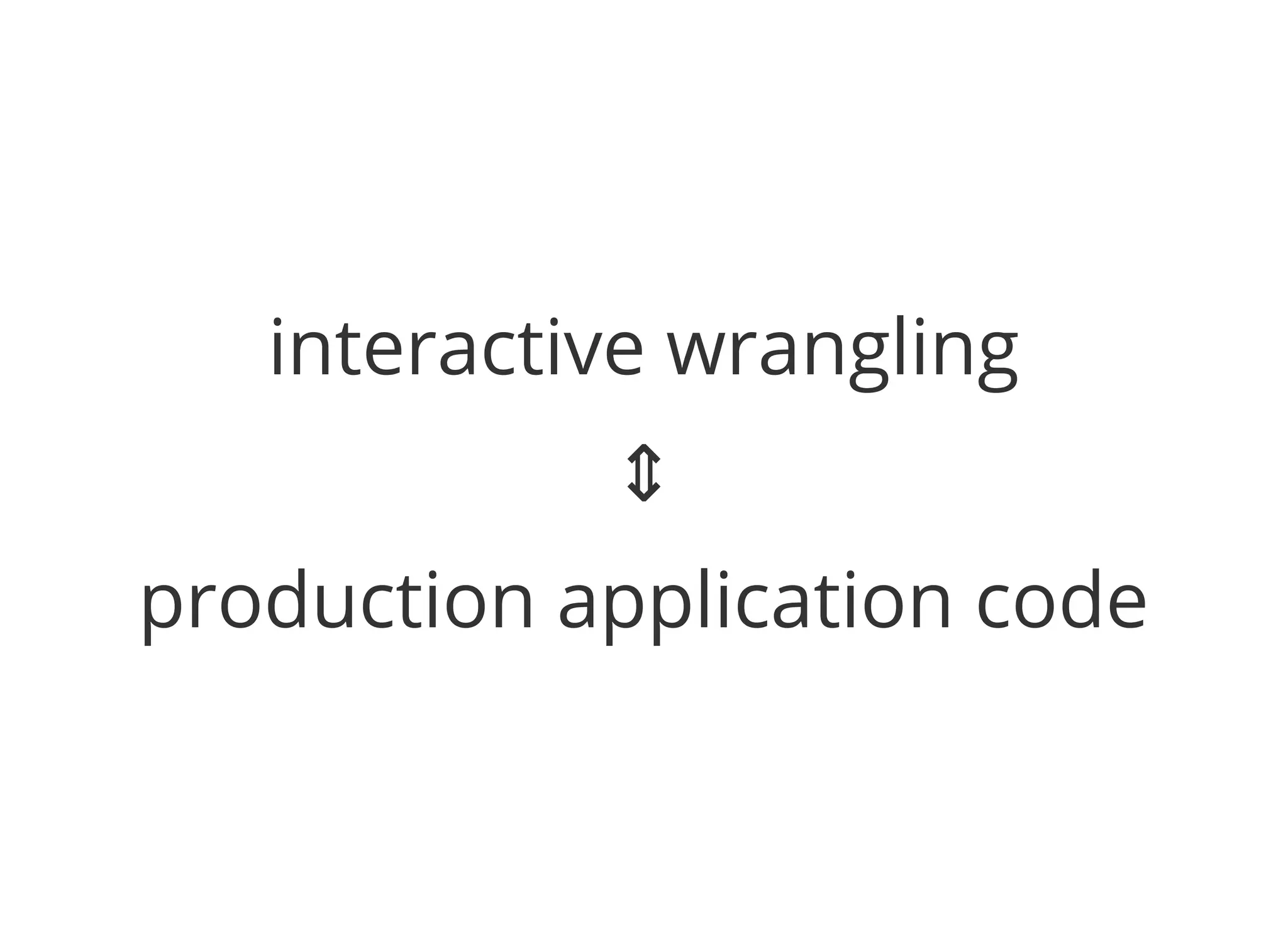







The document outlines the author's journey to enhance efficiency in data processing workflows using Spark, highlighting key needs such as creating repeatable environments, automating deployment, and debugging. It details the complexities encountered with big data applications, real-time decision-making, and the necessity for effective data access and ad-hoc querying. The author emphasizes the importance of versioning, shared dependencies, and an interactive environment for successful production and prototyping in data analytics.




![[OracleCode SF] In memory analytics with apache spark and hazelcast](https://cdn.slidesharecdn.com/ss_thumbnails/in-memoryanalyticswithapachesparkandhazelcast-oraclecode-03-01-2017-170302180618-thumbnail.jpg?width=640&height=640&fit=bounds)

![[OracleCode - SF] Distributed caching for your next node.js project](https://cdn.slidesharecdn.com/ss_thumbnails/distributedcachingforyournextnode-170302181006-thumbnail.jpg?width=640&height=640&fit=bounds)















































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)












