Download to read offline











![Defining a Transform processing function
def preprocessing_fn(inputs):
x = inputs['x']
y = inputs['y']
s = inputs['s']
x_centered = x - tft.mean(x)
y_normalized = tft.scale_to_0_1(y)
s_int = tft.string_to_int(s)
return { 'x_centered': x_centered,
'y_normalized': y_normalized, 's_int': s_int}](https://image.slidesharecdn.com/simplifyingtrainingdeepservinglearningmodelswithbigdatainpythonusingtensorflow-pydataberlin-180725012319/85/Simplifying-training-deep-and-serving-learning-models-with-big-data-in-python-using-tensorflow-PyData-Berlin-12-320.jpg)
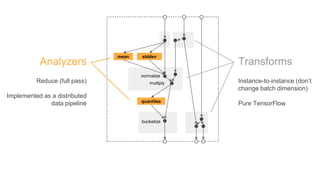
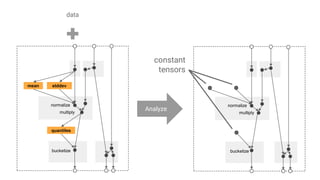




![Ooor from the chicago taxi data...
for key in taxi.DENSE_FLOAT_FEATURE_KEYS:
# Preserve this feature as a dense float, setting nan's to
the mean.
outputs[key] = transform.scale_to_z_score(inputs[key])
for key in taxi.VOCAB_FEATURE_KEYS:
# Build a vocabulary for this feature.
outputs[key] = transform.string_to_int(
inputs[key], top_k=taxi.VOCAB_SIZE,
num_oov_buckets=taxi.OOV_SIZE)
for key in taxi.BUCKET_FEATURE_KEYS:
outputs[key] = transform.bucketize(inputs[key],](https://image.slidesharecdn.com/simplifyingtrainingdeepservinglearningmodelswithbigdatainpythonusingtensorflow-pydataberlin-180725012319/85/Simplifying-training-deep-and-serving-learning-models-with-big-data-in-python-using-tensorflow-PyData-Berlin-22-320.jpg)





![So how does that impact Py[X]
forall X in {Big Data}-{Native Python Big Data}
● Double serialization cost makes everything more
expensive
● Python worker startup takes a bit of extra time
● Python memory isn’t controlled by the JVM - easy to go
over container limits if deploying on YARN or similar
● Error messages make ~0 sense
● Dependency management makes limited sense
● features aren’t automatically exposed, but exposing
them is normally simple](https://image.slidesharecdn.com/simplifyingtrainingdeepservinglearningmodelswithbigdatainpythonusingtensorflow-pydataberlin-180725012319/85/Simplifying-training-deep-and-serving-learning-models-with-big-data-in-python-using-tensorflow-PyData-Berlin-31-320.jpg)





![Which becomes
train_func = TFSparkNode.train(self.cluster_info,
self.cluster_meta, qname)
@pandas_udf("int")
def do_train(inputSeries1, inputSeries2):
# Sad hack for now
modified_series = map(lambda x: (x[0], x[1]),
zip(inputSeries1, inputSeries2))
train_func(modified_series)
return pandas.Series([0] * len(inputSeries1))
ljmacphee](https://image.slidesharecdn.com/simplifyingtrainingdeepservinglearningmodelswithbigdatainpythonusingtensorflow-pydataberlin-180725012319/85/Simplifying-training-deep-and-serving-learning-models-with-big-data-in-python-using-tensorflow-PyData-Berlin-39-320.jpg)







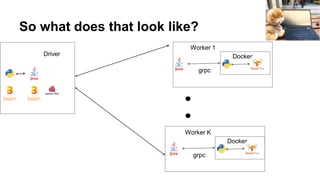
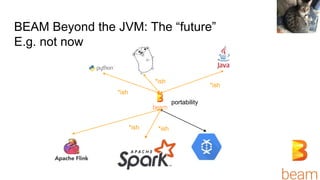
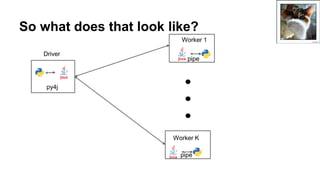
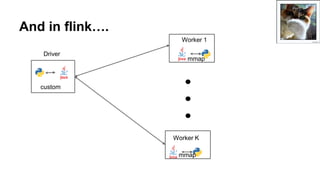
This document discusses simplifying training and serving deep learning models with big data in Python using TensorFlow, Apache Beam, and Apache Flink. It covers using TF.Transform to preprocess data, running TensorFlow models on Spark using TensorFlowOnSpark, and the progress being made on non-JVM support in Apache Beam and TensorFlow on Flink. It also briefly discusses other big data systems and the challenges of interacting with them from outside the Java Virtual Machine.


















































![How Big Brands are Taking Your Traffic in Alberta [Data Inside].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/howbigbrandsaretakingyourtrafficinalbertadatainside-260123180142-42d276f3-thumbnail.jpg?width=640&height=640&fit=bounds)




