Downloaded 20 times




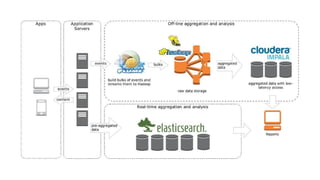

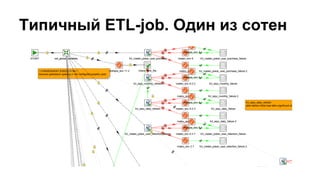




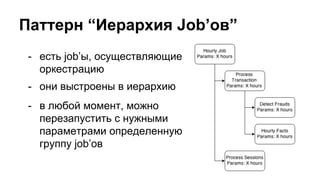




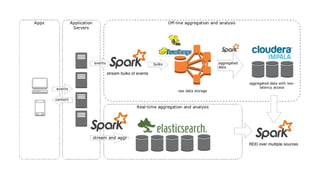


Документ представляет собой обсуждение использования ETL-процессов с Apache Spark для BI-платформ, включая примеры работы с игровыми данными и архитектуру систем. Основное внимание уделяется проблемам, связанным с устаревшими методологиями и недостатками существующих решений, таким как deployment и мониторинг. В документе также обсуждаются перспективы применения технологий, таких как Spark Streaming и интеграция с Elasticsearch.

























![[Не]практичные типы](https://cdn.slidesharecdn.com/ss_thumbnails/random-120710152756-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

