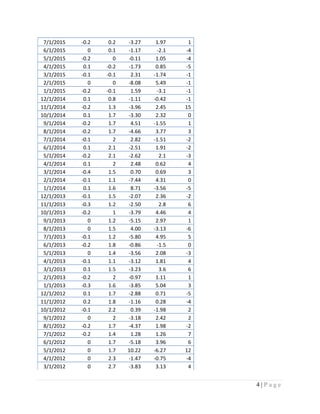
This document presents an analysis of the relationship between Walmart stock growth and various national economic indicators over time. It examines monthly stock returns for Walmart against factors like unemployment rates, inflation rates, and various stock market indices. Regression models will be used to analyze what relationships exist between the economic variables and Walmart's performance. The analysis will provide insight into how well Walmart's business is correlated with the overall health of the economy.






![17 | P a g e
Conclusion: null hypothesis is not rejected.
Because the |t-stat| = |1.29| less than the t-critical value of . 2.92 .
F-test below are x3 and x3
2
H0: 1= 2 = 0 [Note that 0 is not included.]
H1: j t least one value of j
Test statistic: F-stat =
p)-SSE/(n
1)SSR/(p
= (81.278/2) / (1092.15051/53) =1.97 [p=k+1=2+1, here]
Rejection region: F-stat > F-critical value, 2 d.f., 53 d.f.,
Conclusion: the null hypothesis is not rejected.
because the F-stat of 1.97 less than the F-critical value of. 3.96 .
(f) Scatter Plots of polynomials of degree 1, 3, 4 and 10.
Now we will try on plot our simple regression on a polynomial of different degrees to see if our
data will fit betters with a different degree of polynomials.
model so we can compare the other higher polynomial graphs with it.
Our second plot is of degree=3, which y is regressed on x, x2
, x3
. Our objective is to see if our data fits better.](https://image.slidesharecdn.com/58a400cd-b9fa-4d18-8b3d-511f665be3e0-170118193430/85/Sample_Regression-Project-9-320.jpg)







































