Downloaded 150 times

















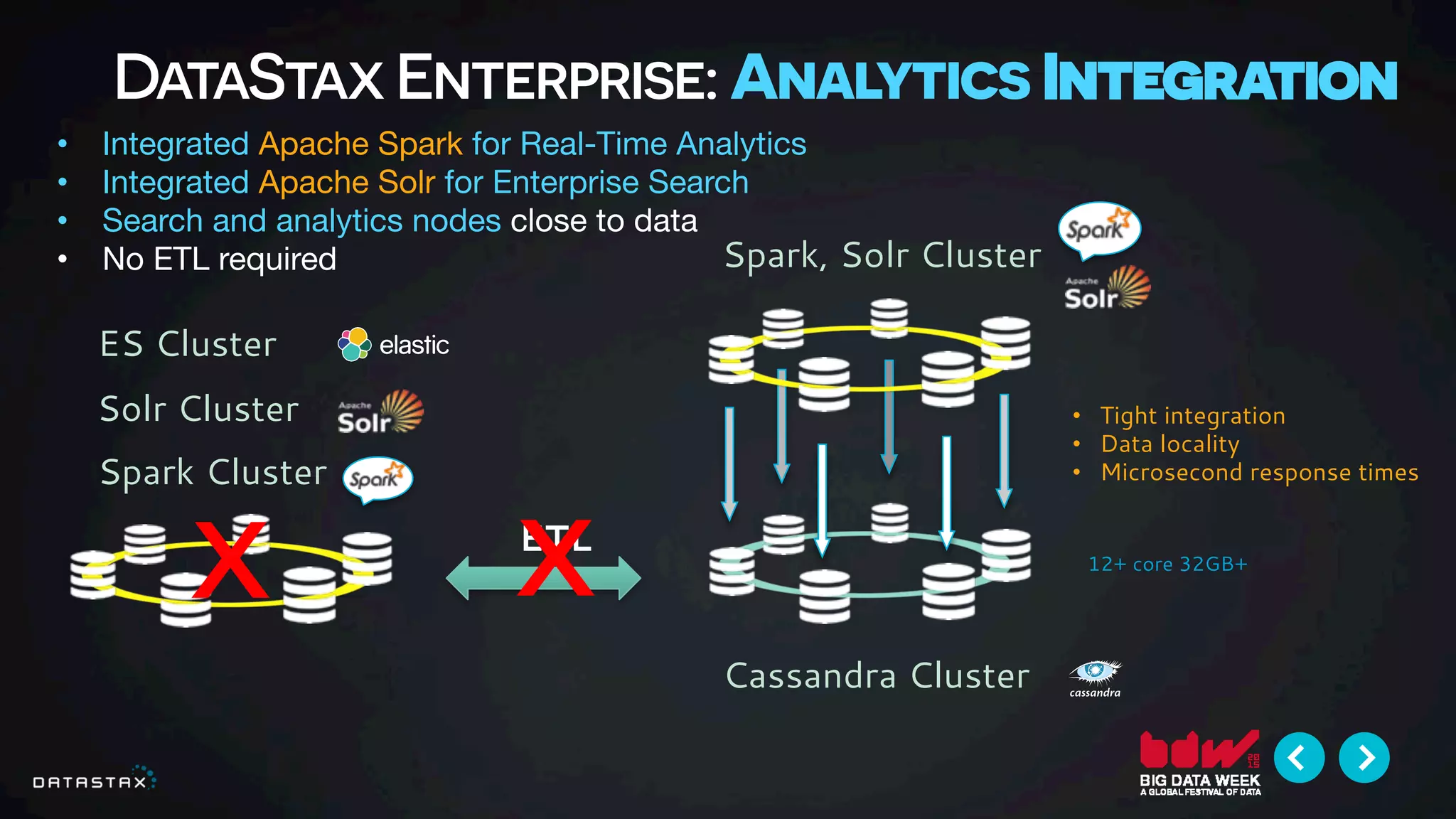




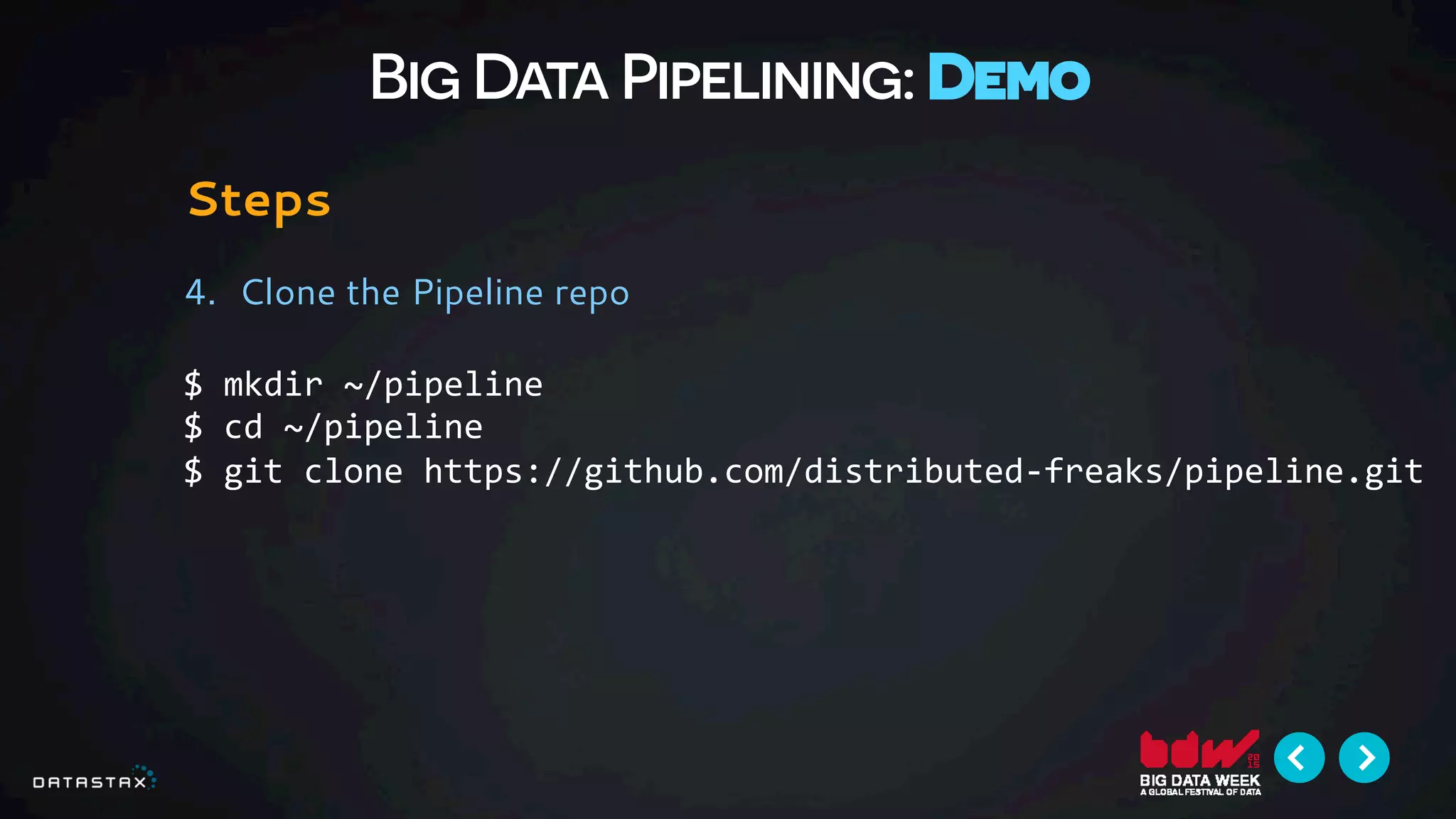


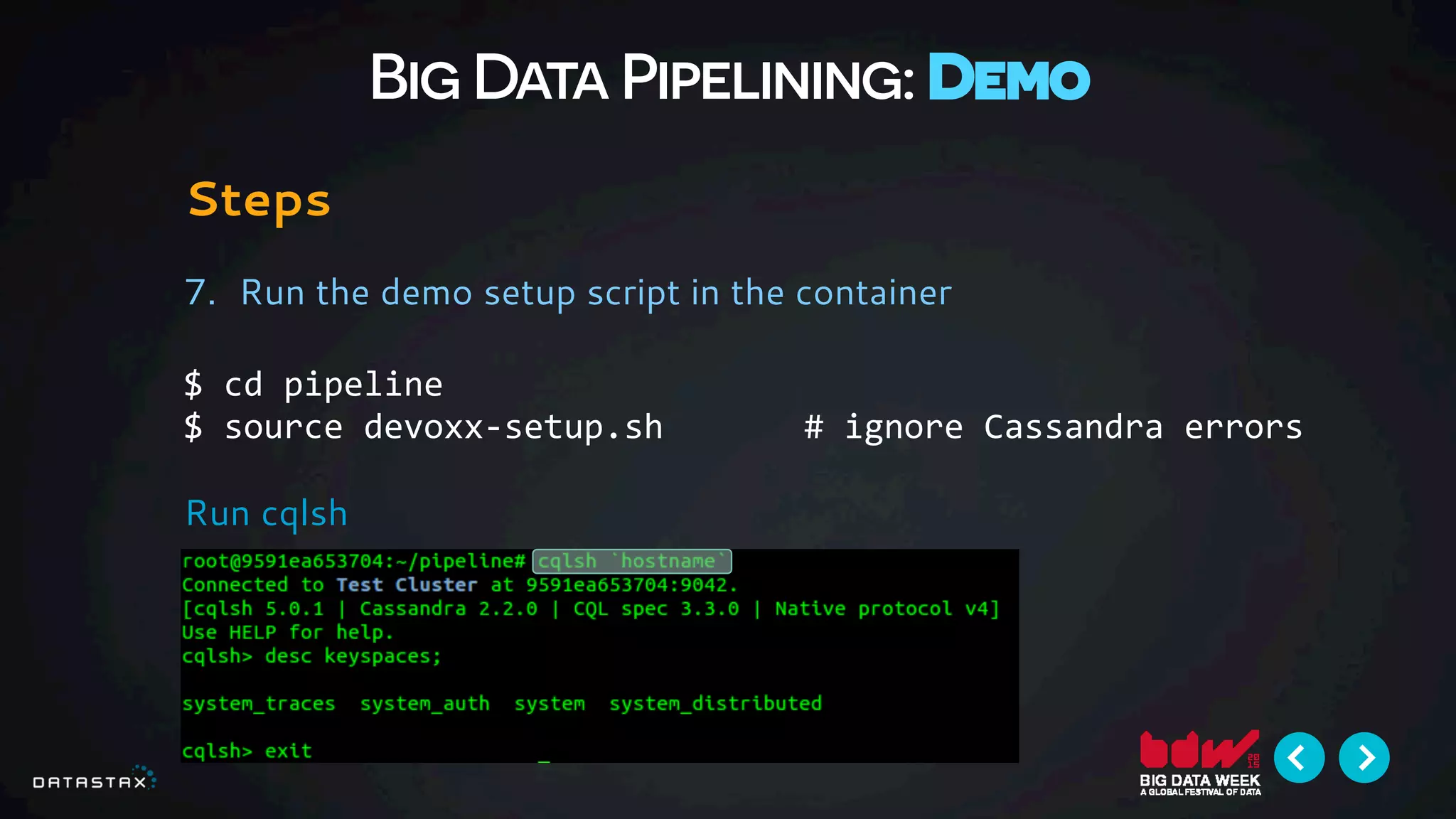
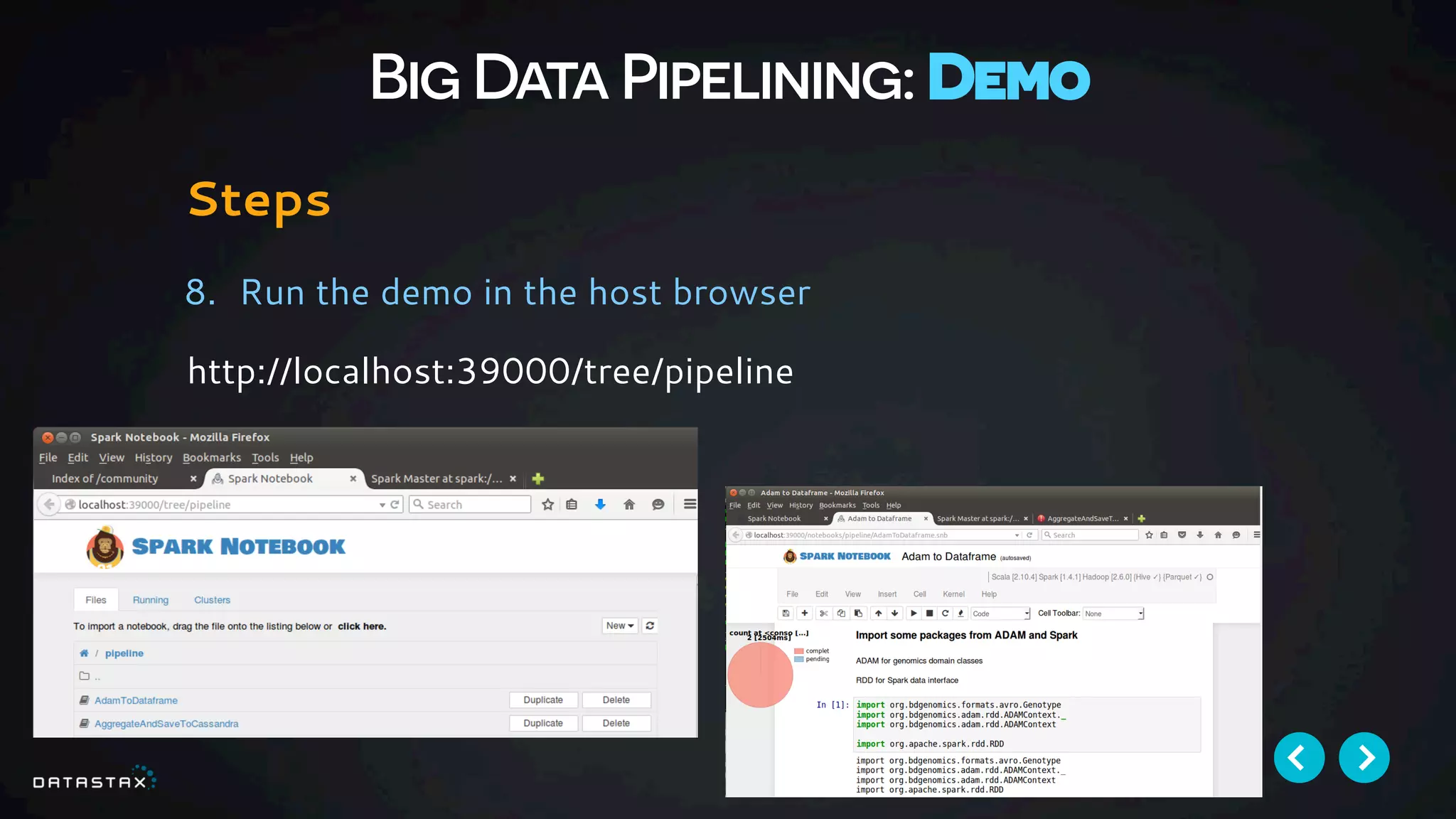












This document provides an overview and outline of a 1-hour introduction to building a big data pipeline using Docker, Cassandra, Spark, Spark-Notebook and Akka. The introduction is presented as a half-day workshop at Devoxx November 2015. It uses a data pipeline environment from Data Fellas and demonstrates how to use scalable distributed technologies like Docker, Spark, Spark-Notebook and Cassandra to build a reactive, repeatable big data pipeline. The key takeaway is understanding how to construct such a pipeline.













































































