Download as PDF, PPTX







![XPath
<html>
...
<div class="bla">
<a>legal</a>
</div>
...
</html>
html_doc = Nokogiri::HTML(html)
info = html_doc.xpath(
"//div[@class='bla']/a")
info.text
=> legal](https://image.slidesharecdn.com/rubyrobots-110813155040-phpapp02/85/Ruby-Robots-8-320.jpg)
![XPath
<table id="super"> >> html_doc = Nokogiri::HTML(html)
<tr> >> info = html_doc.xpath(
<td>L1C1</td> "//table[@id='super']/tr")
<td>L1C2</td> >> info.size
=> 3
</tr>
<tr>
>> info
<td>L2C1</td> => legal
<td>L2C2</td>
</tr> >> info[0].xpath("td").size
<tr> => 2
<td>L3C1</td>
<td>L3C2</td> >> info[2].xpath("td")[1].text
</tr> => "L3C2"
</table>](https://image.slidesharecdn.com/rubyrobots-110813155040-phpapp02/85/Ruby-Robots-9-320.jpg)






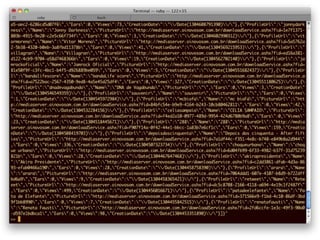
![>> body = RestClient.get(url)
>> json = JSON.parse(body)
>> content = json["Content"]
>> content.size
=> 16
AHA!!!
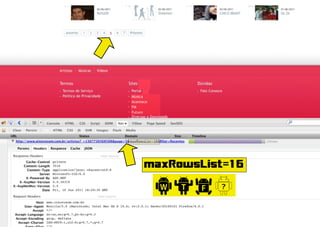
http://.../artistas?maxRowsList=1600&filter=Recentes
>> body = RestClient.get(url)
>> json = JSON.parse(a)
>> content = json["Content"]
>> content.size
=> 1600
http://.../artistas?maxRowsList=1600000&filter=Recentes
>> content.size
=> 9154
Bingo!!!](https://image.slidesharecdn.com/rubyrobots-110813155040-phpapp02/85/Ruby-Robots-20-320.jpg)
![>> b["Content"].map {|c| c["ProfileUrl"]}
["caravella", "tomleite", "jeffersontavares", "rodrigoaraujo",
"jorgemendes", "bossapunk", "daviddepiro", "freetools", "ironia",
"tiagorosa", "outprofile", "lucianokoscky",
"bandateatraldecarona", "tlounge", "almanaque", "razzyoficial",
"cretinosecanalhas", "cincorios", "ninoantunes", "caiocorsalette",
"alinedelima", "thelio", "grupodomdesamba", "ladoz",
"alexandrepontes", "poeiradgua", "betimalu", "leonardobessa",
"kamaross", "marcusdocavaco", "atividadeinformal", "angelkeys",
"locojohn", "forcamusic", "tiaguinhoabreu", "marcelonegrao",
"jstonemghiphop", "uniaoglobal", "bandaefex", "severarock",
"manitu", "sasso", "kakka", "xsopretty", "belepoke", "caixaazul",
"wknd", "bandastarven", "bleiamusic", "3porcentoaocubo",
"lucianoterra", "hipnoia", "influencianegra", "bandaursamaior",
"mariafreitas", "jessejames", "vagnerrockxe", "stageo3",
"lemoneight", "innocence", "dinda", "marcelocapela",
"paulocamoeseoslusiadas", "magnussrock", "bandatheburk",
"mercantes", "bandaturnerock", "flaviasaolli", "tonysagga",
"thiagoponde", "centeio", "grupodeubranco", "bocadeleao",
"eusoueliascardan", "notoriaoficial", "planomasterrock", "rofgod",
"dreemonphc", "chicobrant", "osz", "bandalightspeed",
"cavernadenarnia", "sergiobenevenuto", "viniciusdeoliveira", ...]](https://image.slidesharecdn.com/rubyrobots-110813155040-phpapp02/85/Ruby-Robots-21-320.jpg)
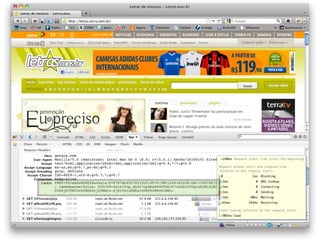
![>> html = RestClient.get("http://.../robomacaco")
>> html_doc = Nokogiri::HTML(html)
>> info = html_doc.xpath("//span[@class='name']")
>> info.text
=> "robo-macaco@hotmail.com
RIO DE JANEIRO - RJ - Brasil
21 9675-0199](https://image.slidesharecdn.com/rubyrobots-110813155040-phpapp02/85/Ruby-Robots-24-320.jpg)
![cookies
cookies = {}
c = "s_nr=12954999; s_v19=12978609471; ... __utmc=206845458"
cook = c.split(";").map {|i| i.strip.split("=")}
cook.each {|u| cookies[u[0]] = u[1]}
RestClient.get(url, :cookies => cookies)](https://image.slidesharecdn.com/rubyrobots-110813155040-phpapp02/85/Ruby-Robots-26-320.jpg)

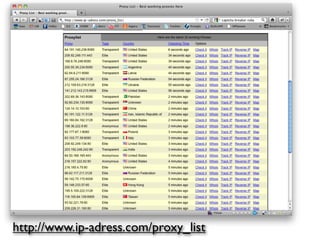
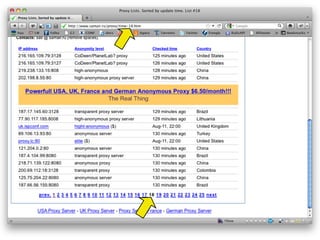
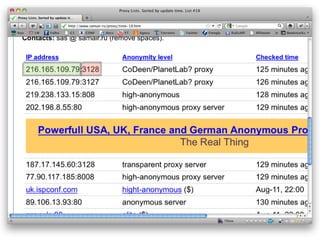
![>> response = RestClient.get(url)
>> html_doc = Nokogiri::HTML(response)
>> table = html_doc.xpath("//table
[@class='proxylist']")
>> lines = table.children
>> lines.shift # tira o cabeçalho
Text
IP
>> lines[1].text
=> "208.52.144.55 document.write(":"+i+r+i+r)
anonymous proxy server-2 minutes ago United States"](https://image.slidesharecdn.com/rubyrobots-110813155040-phpapp02/85/Ruby-Robots-32-320.jpg)
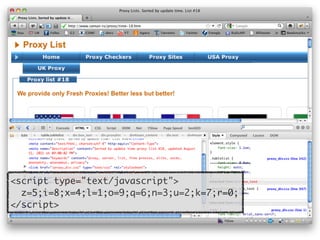

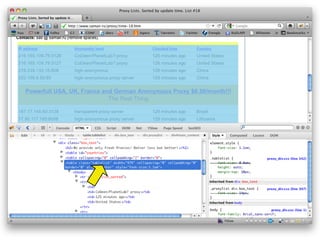
![<script type="text/javascript">
z=5;i=8;x=4;l=1;o=9;q=6;n=3;u=2;k=7;r=0;
</script>
>> script = html_doc.xpath("//script")[1]
>> eval script.text
>> z
=> 5
>> i
=> 8](https://image.slidesharecdn.com/rubyrobots-110813155040-phpapp02/85/Ruby-Robots-35-320.jpg)
![>> lines[1].text
=> "208.52.144.55 document.write(":"+i+r+i+r) anonymous
proxy server-2 minutes ago United States"
>> server = lines[1].text.split[0]
=> "208.52.144.55"
>> digits = lines[1].text.split(")")[0].split("+")
=> ["208.52.144.55document.write(":"", "i", "r", "i", "r"]
>> digits.shift
>> digits
=> ["i", "r", "i", "r"]
>> port = digits.map {|c| eval(c)}.join("")
=> "8080"
Voilà
RestClient.proxy = "http://#{server}:#{port}"](https://image.slidesharecdn.com/rubyrobots-110813155040-phpapp02/85/Ruby-Robots-36-320.jpg)
![mechanize
agent = Mechanize.new
site = "http://www.cantora.mus.br"
page = agent.get("#{site}/baixar")
form = page.form
form['visitor[name]'] = 'daniel'
form['visitor[email]'] = "danicuki@gmail.com"
page = agent.submit(form)
tracks = page.links.select { |l| l.href =~ /track/ }
tracks.each do |t|
file = agent.get("#{site}#{t})
file.save
end](https://image.slidesharecdn.com/rubyrobots-110813155040-phpapp02/85/Ruby-Robots-37-320.jpg)











The document discusses various topics related to web scraping and robots/bots using Ruby including: - Using the Anemone gem to crawl and parse URLs - Using Nokogiri to parse HTML and extract data using XPath queries - Making HTTP requests to APIs using RestClient and parsing JSON responses - Scraping dynamic content by executing JavaScript using Nokogiri - Techniques for handling proxies, cookies, and CAPTCHAs when scraping - Scaling scraping workloads using threads and queues in Ruby























































































