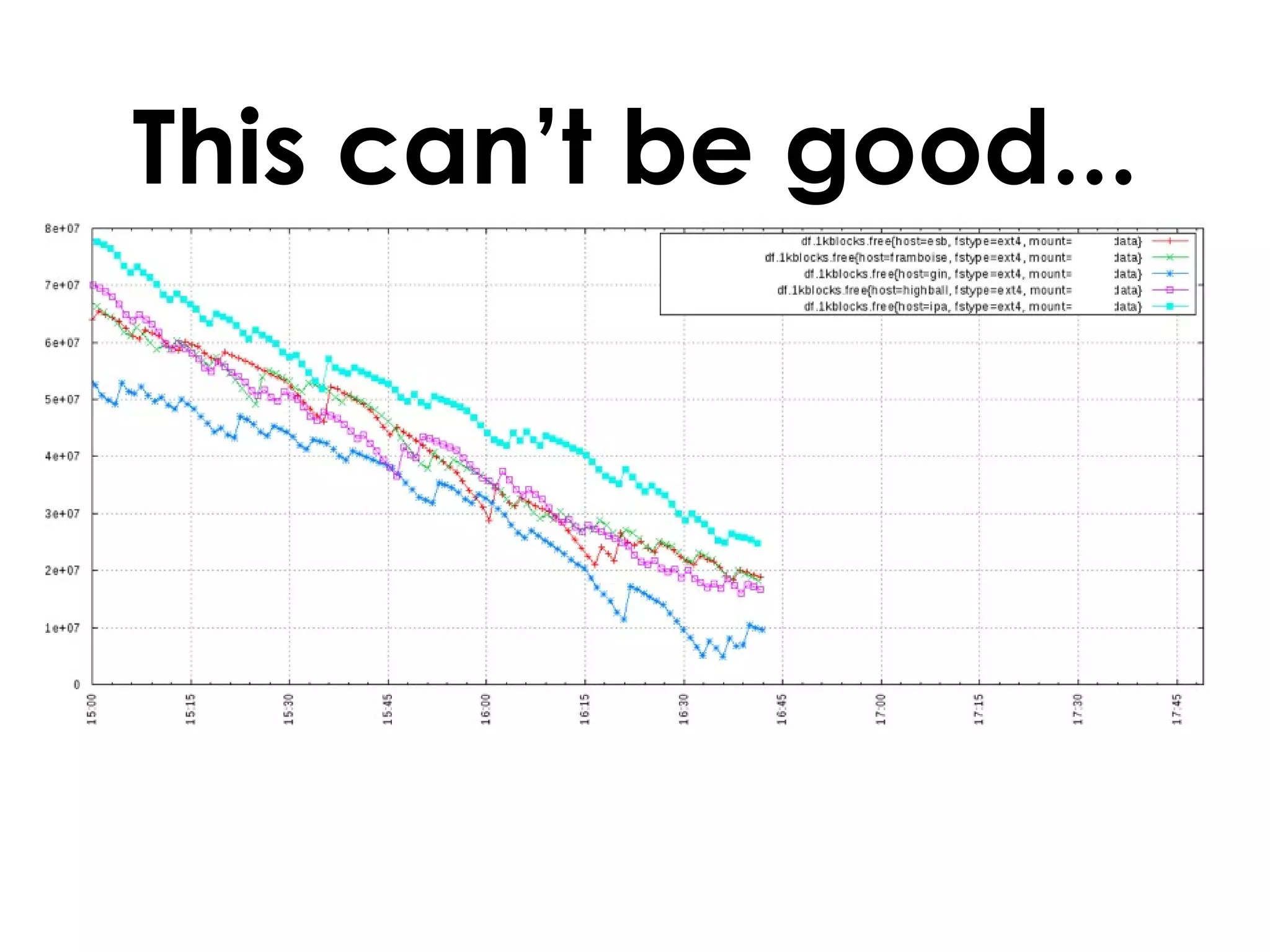
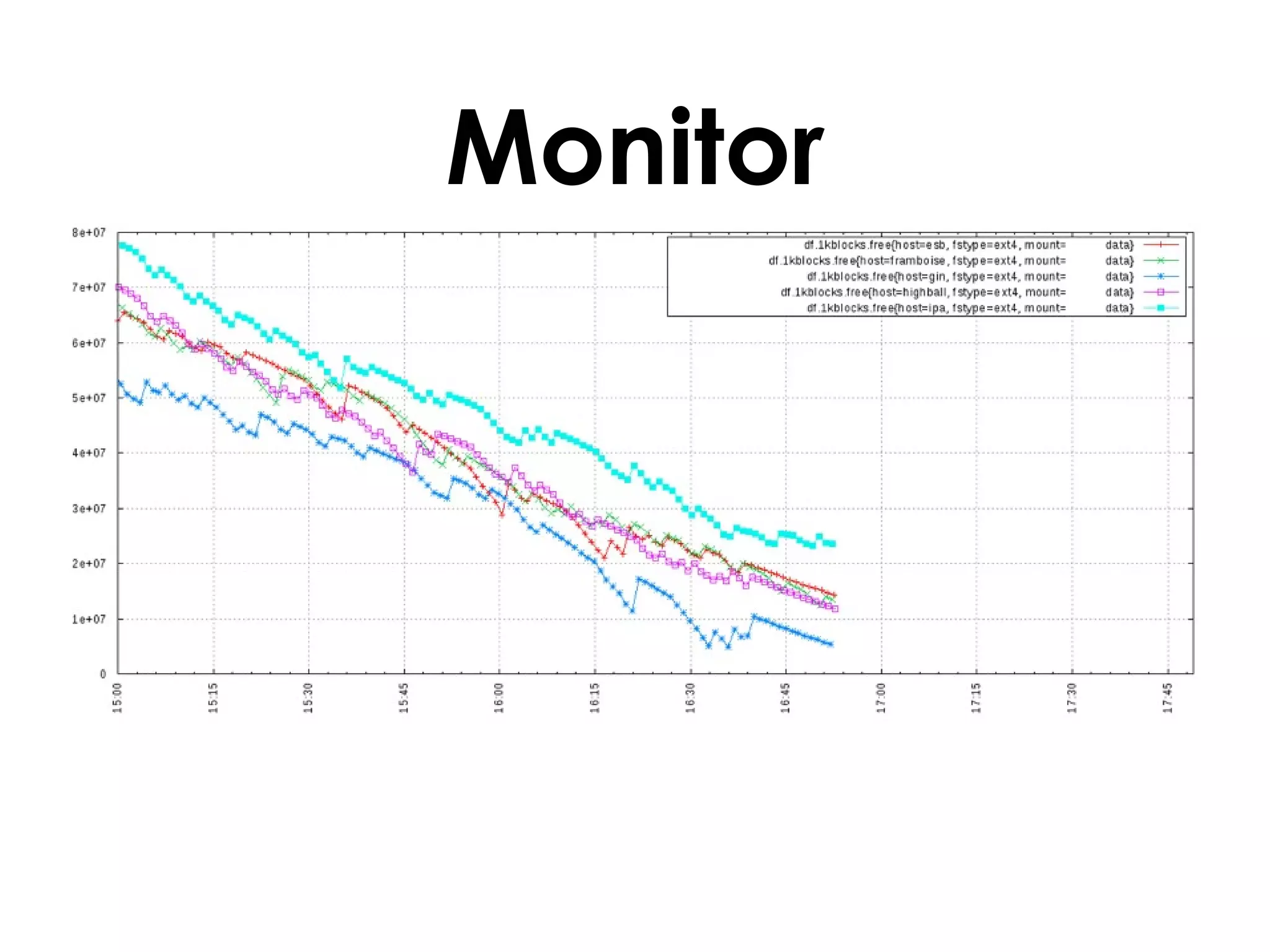
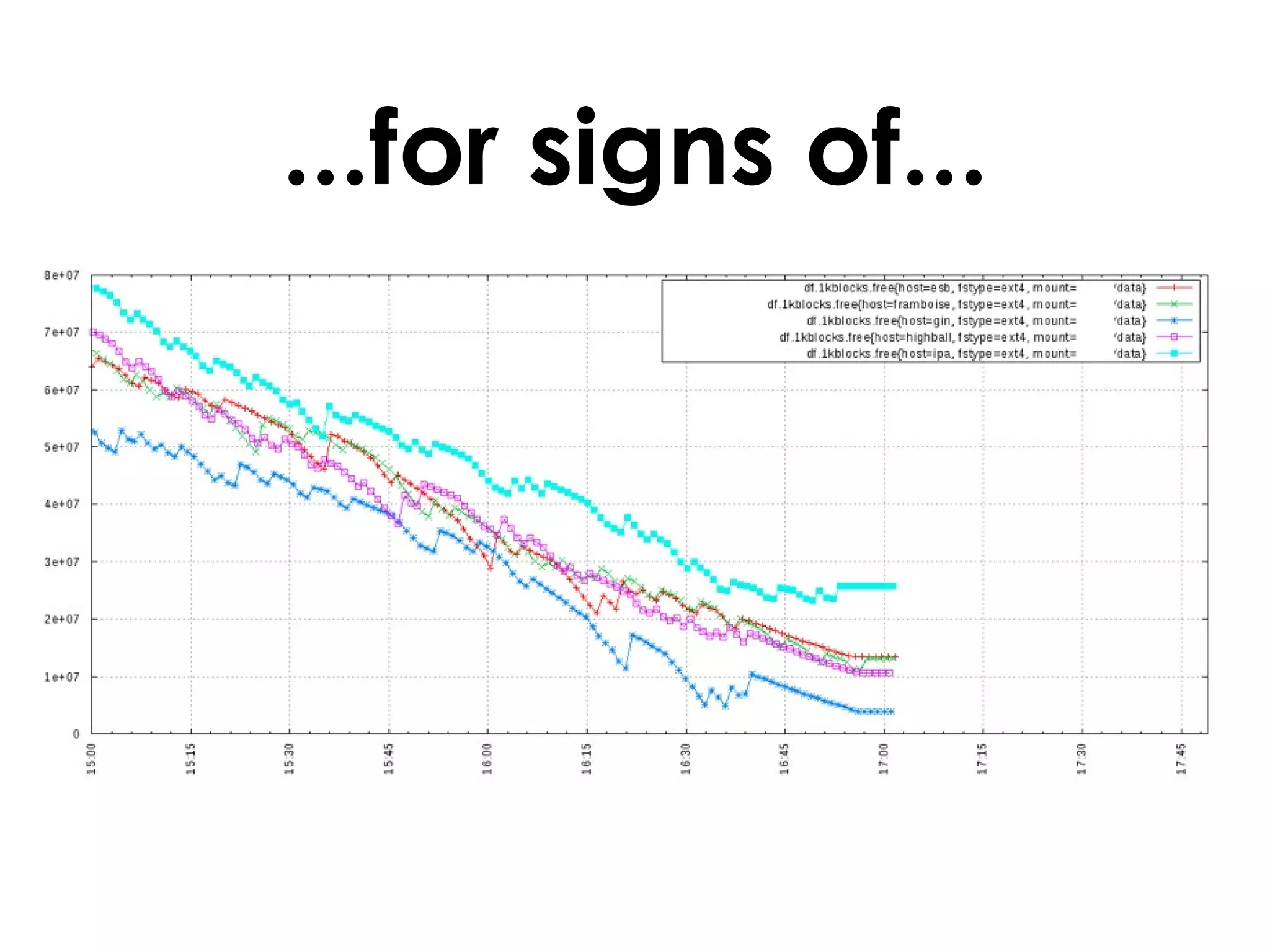
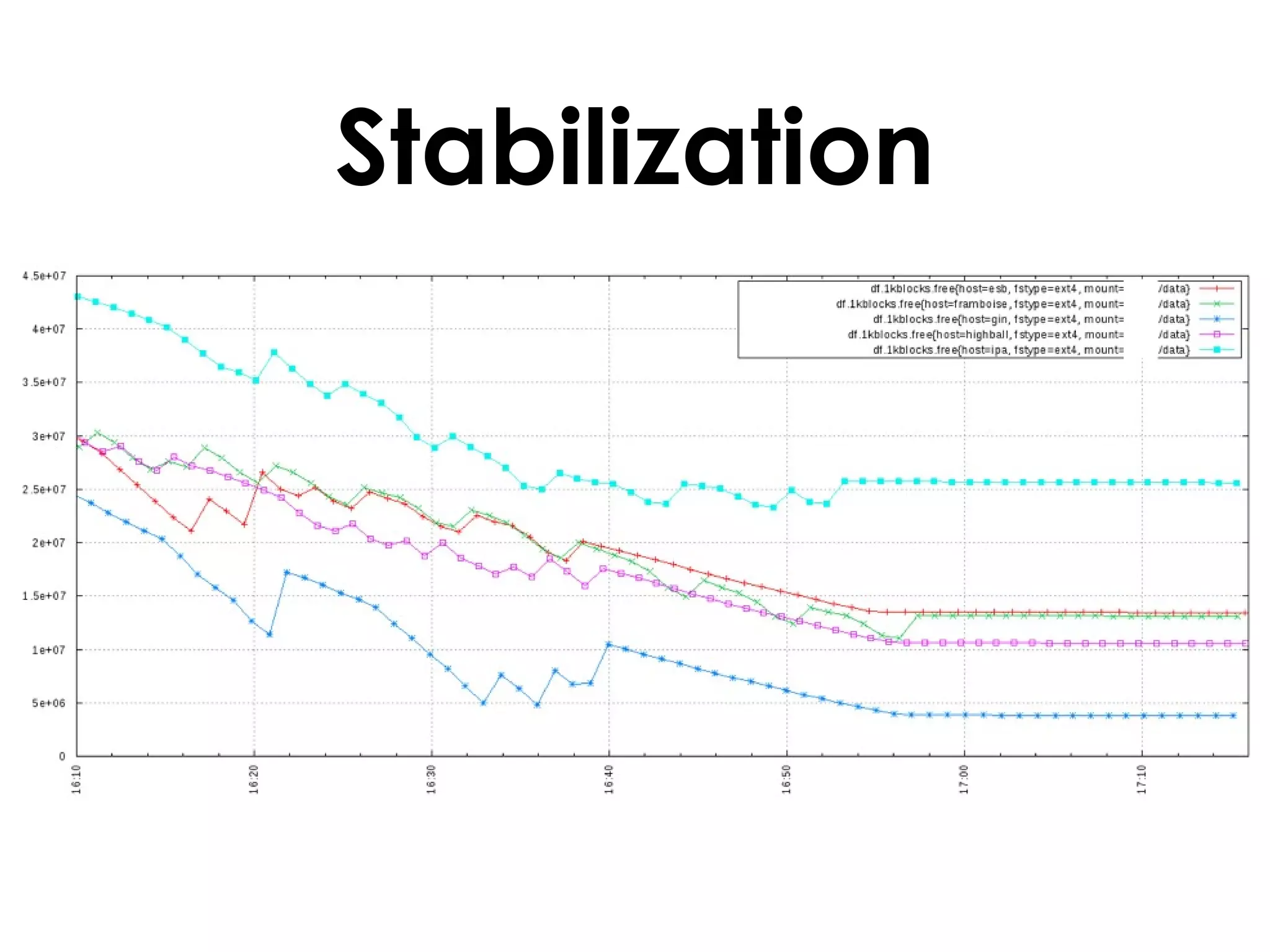
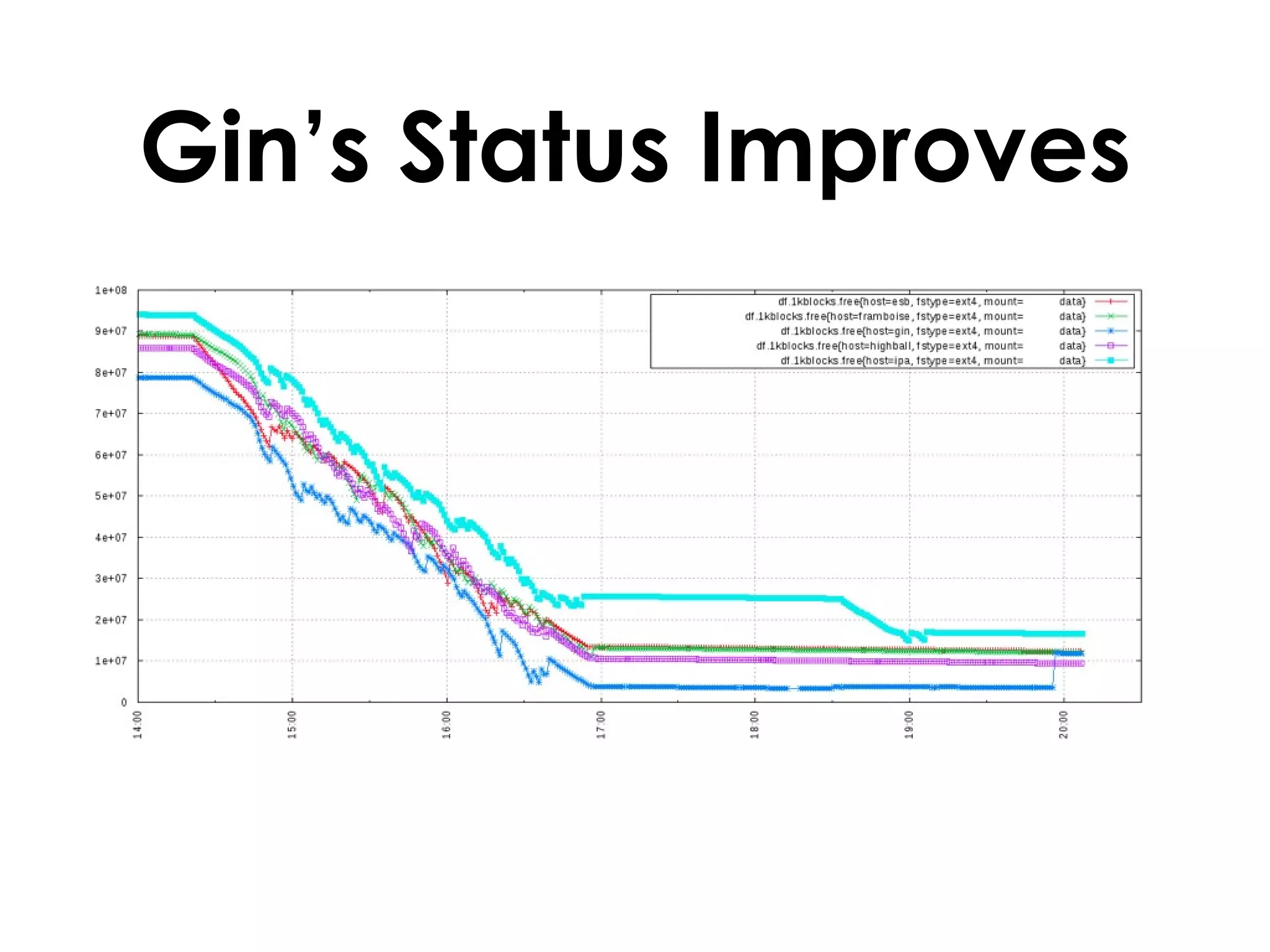
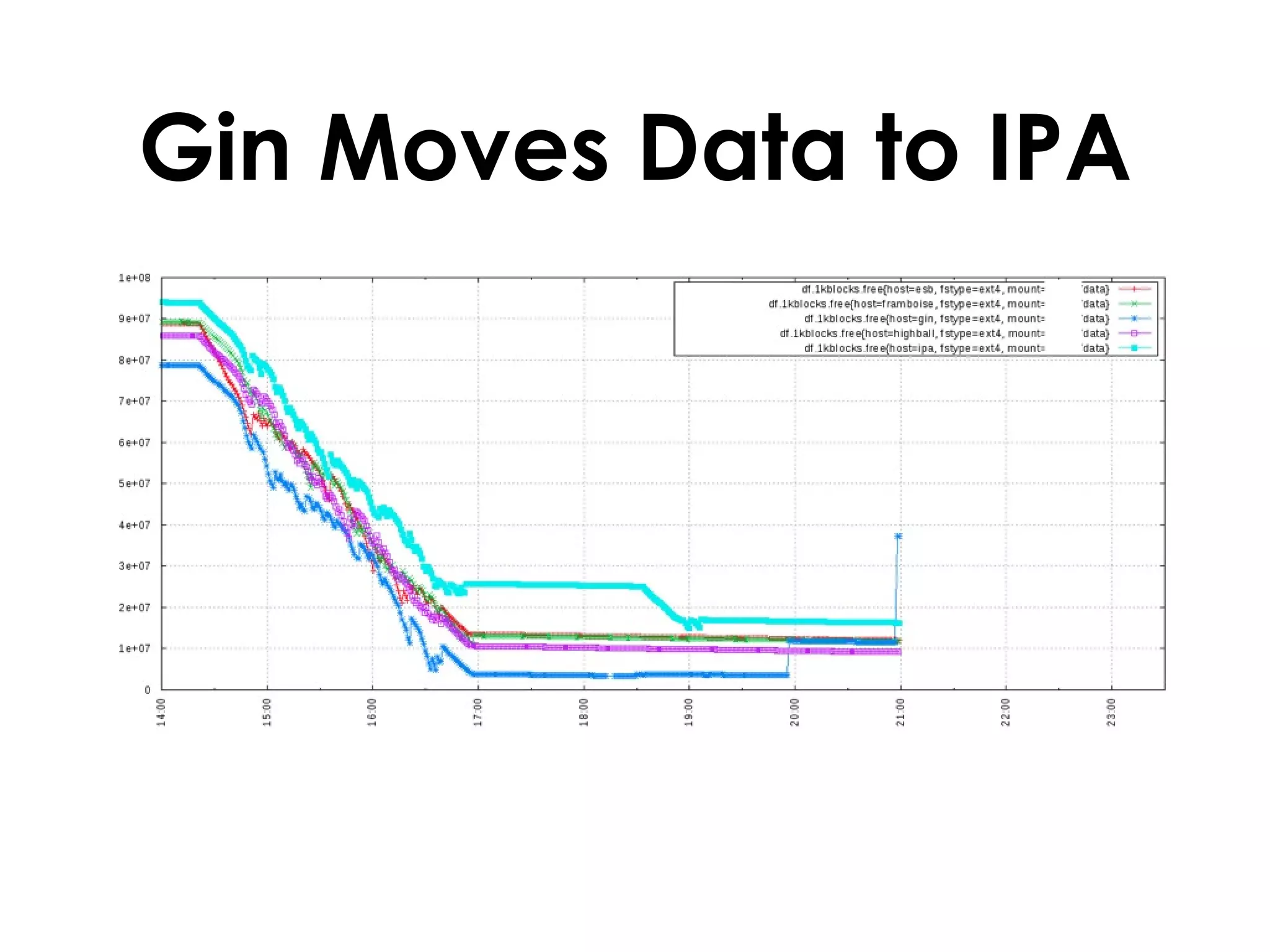
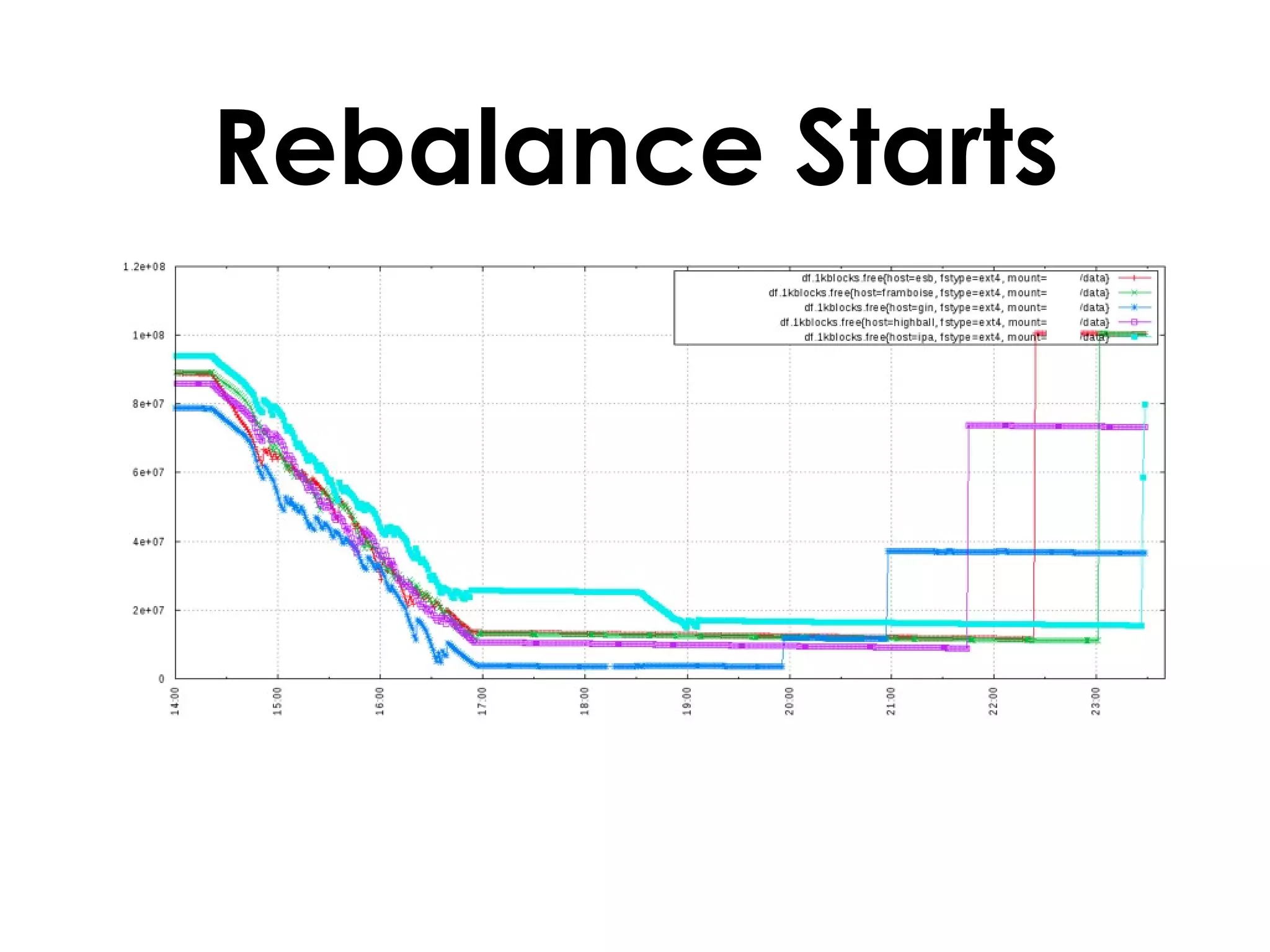
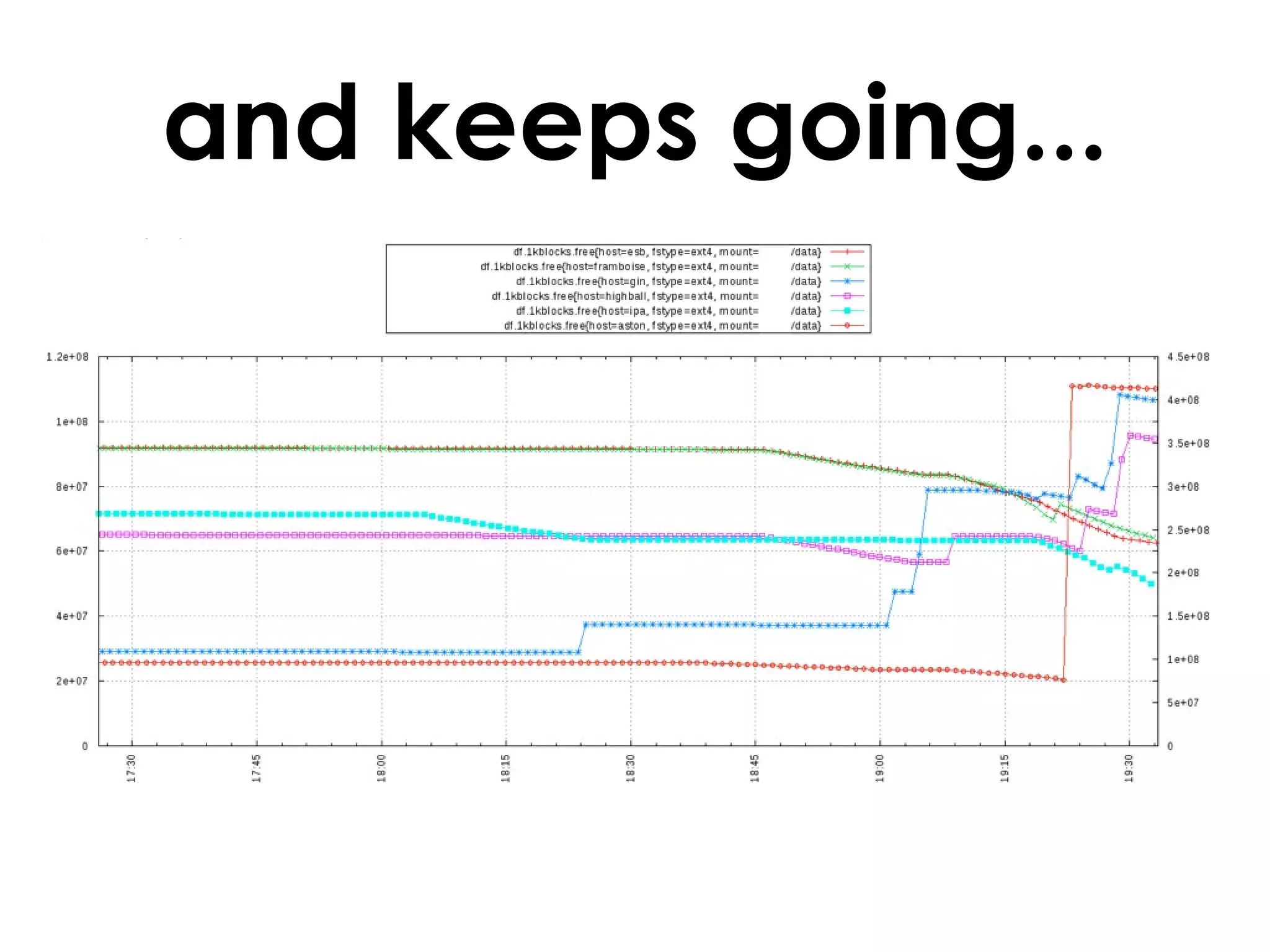
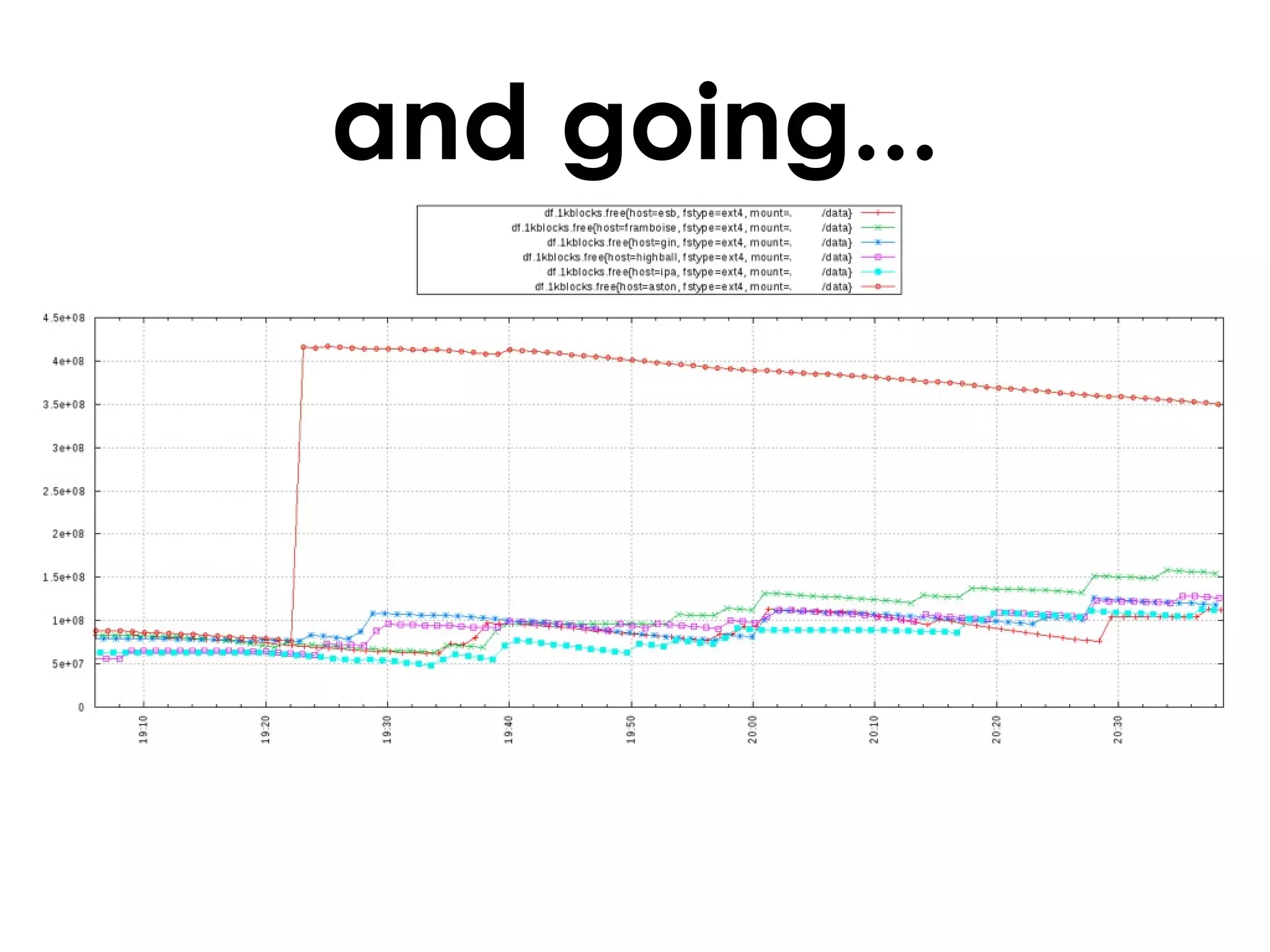
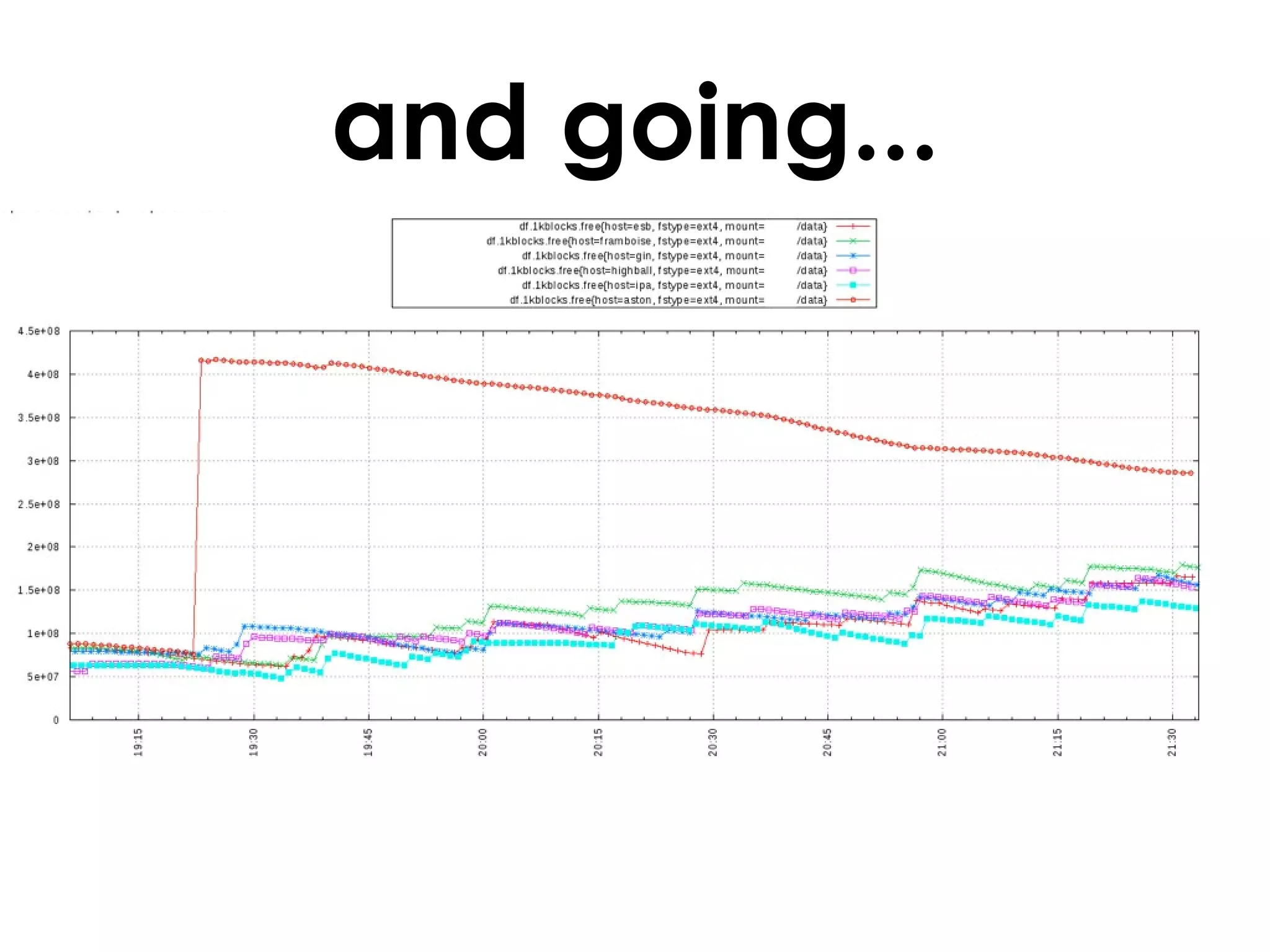
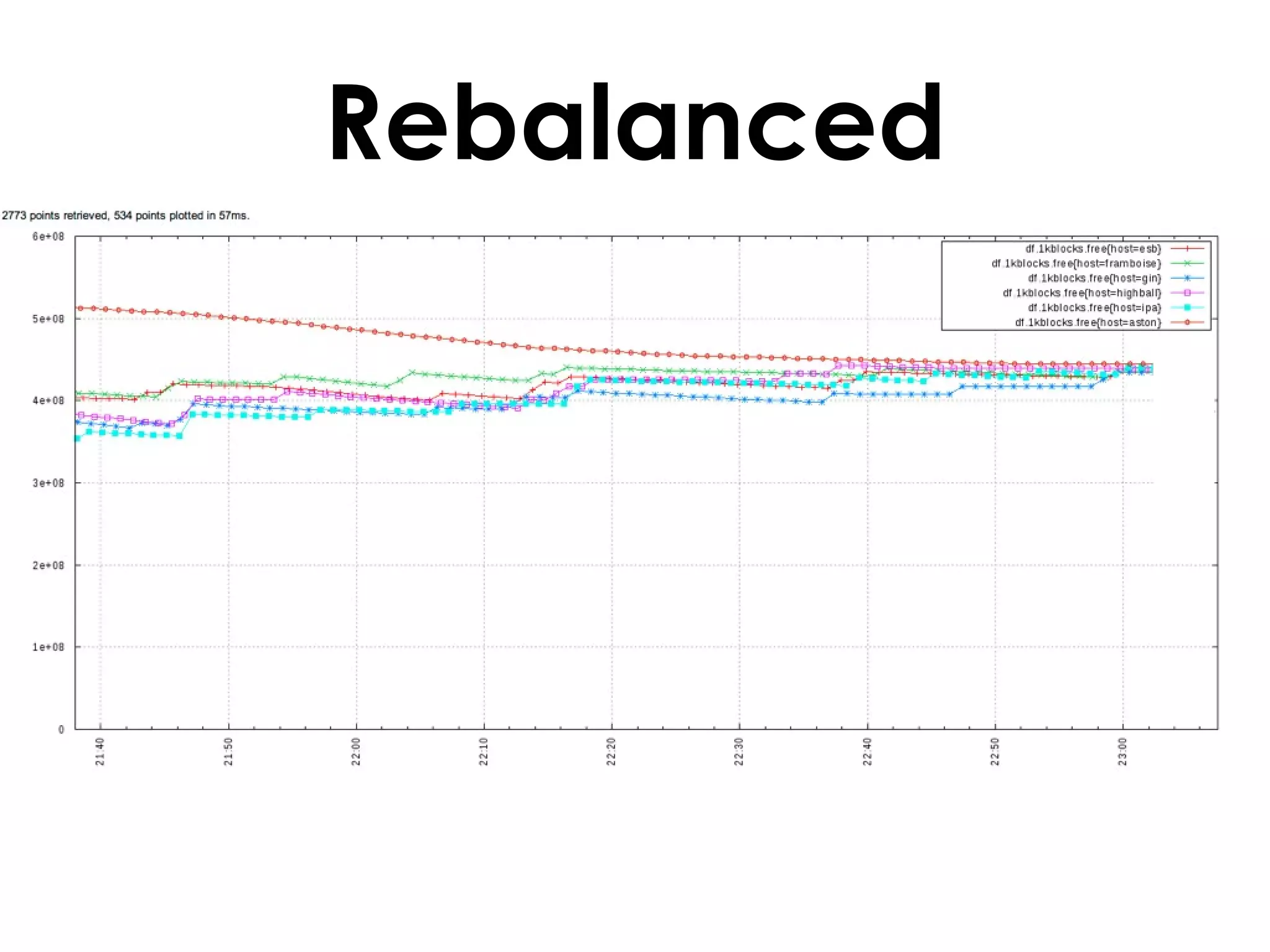
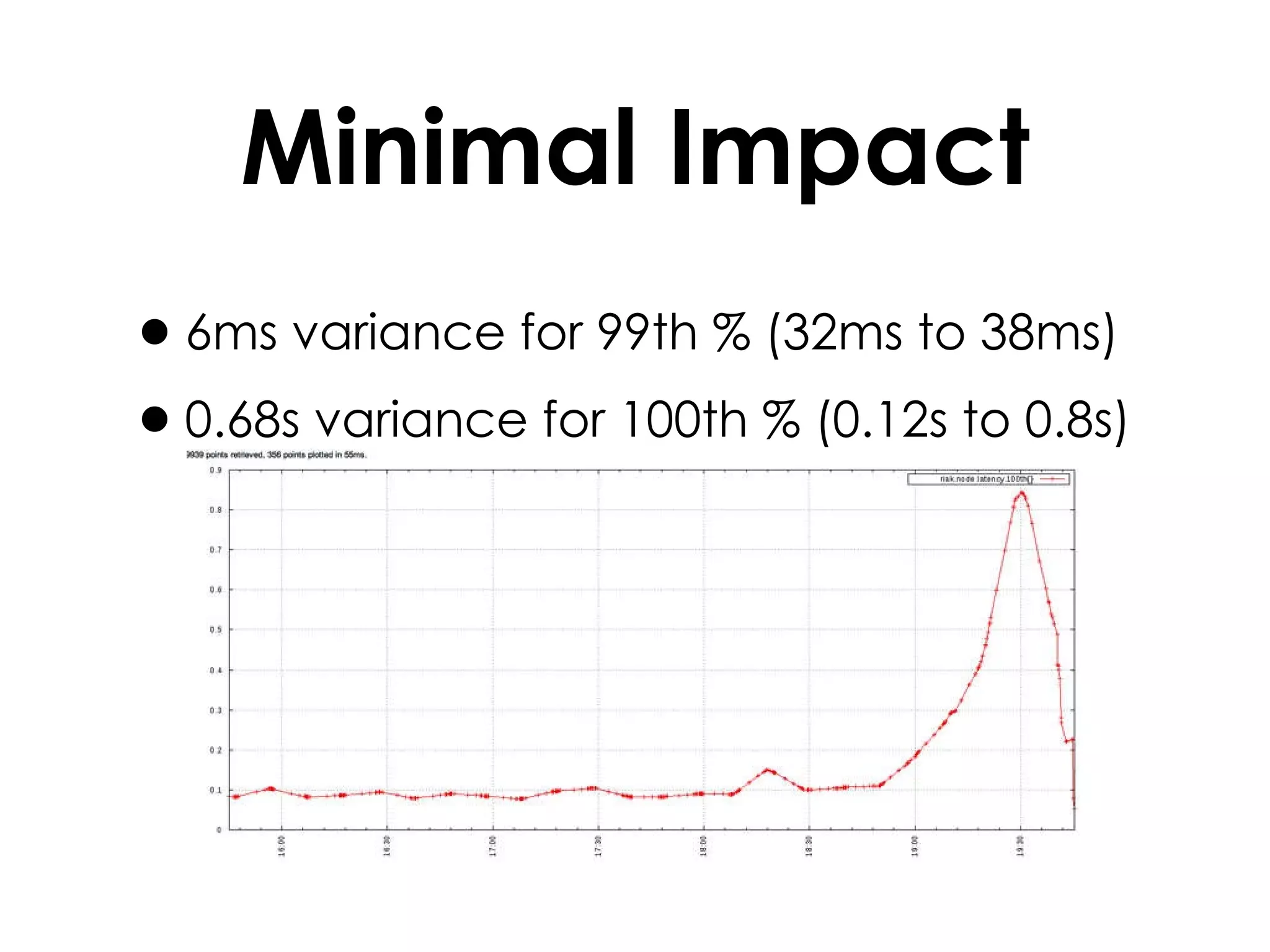
A customer added a new node to their Riak cluster to add capacity, but it caused the cluster to fill up disk space as the ring rebalanced. The Basho support team helped diagnose the issue and apply a hot fix without downtime. The fix prevented unused data from filling disks during rebalancing. Through monitoring and manually moving data, they stabilized the cluster with minimal performance impact and the customer's site remained operational throughout.
![In Production: Portrait of a Successful Failure Sean Cribbs @seancribbs [email_address]](https://image.slidesharecdn.com/riak-asuccessfulfailure-120210065736-phpapp01/75/Riak-a-successful-failure-1-2048.jpg)







![riak-admin join With Riak, it’s easy to add a new node. on aston: $ riak-admin join [email_address] Then you leave for a quick lunch.](https://image.slidesharecdn.com/riak-asuccessfulfailure-120210065736-phpapp01/75/Riak-a-successful-failure-10-2048.jpg)







![Relief It took 20 minutes to transfer the vnode (riak@gin)7> 19:34:00.574 [info] Starting handoff of partition riak_kv_vnode 411047335499316445744786359201454599278231027712 from riak@gin to riak@aston gin:~$ sudo netstat -nap | fgrep 10.36.18.245 tcp 0 1065 10.36.110.79:40532 10.36.18.245:8099 ESTABLISHED 27124/beam.smp tcp 0 0 10.36.110.79:46345 10.36.18.245:53664 ESTABLISHED 27124/beam.smp (riak@gin)7> 19:54:56.721 [info] Handoff of partition riak_kv_vnode 411047335499316445744786359201454599278231027712 from riak@gin to riak@aston completed: sent 3805730 objects in 1256.14 seconds](https://image.slidesharecdn.com/riak-asuccessfulfailure-120210065736-phpapp01/75/Riak-a-successful-failure-22-2048.jpg)



![Hot Patch We patched their live, production system while still under load. (on all nodes) riak attachl(riak_kv_bitcask_backend).m(riak_kv_bitcask_backend).Module riak_kv_bitcask_backend compiled: Date: November 12 2011, Time: 04.18Compiler options: [{outdir,"ebin"}, debug_info,warnings_as_errors, {parse_transform,lager_transform}, {i,"include"}]Object file: /usr/lib/riak/lib/riak_kv-1.0.1/ebin/riak_kv_bitcask_backend.beamExports: api_version/0 is_empty/1callback/3 key_counts/0delete/4 key_counts/1drop/1 module_info/0fold_buckets/4 module_info/1fold_keys/4 put/5fold_objects/4 start/2get/3 status/1...](https://image.slidesharecdn.com/riak-asuccessfulfailure-120210065736-phpapp01/75/Riak-a-successful-failure-26-2048.jpg)
![Bingo! And the new code did what we expected. {ok, R} = riak_core_ring_manager:get_my_ring().[riak_core_vnode_master:get_vnode_pid(Partition, riak_kv_vnode) || {Partition,_} <- riak_core_ring:all_owners(R)].(riak@gin)19> [riak_core_vnode_master:get_vnode_pid(Partition, riak_kv_vnode) || {Partition,_} <- riak_core_ring:all_owners(R)].22:48:07.423 [notice] Unused data directories exist for partition "11417981541647679048466287755595961091061972992 ": "/data/riak/bitcask/11417981541647679048466287755595961091061972992"22:48:07.785 [notice] Unused data directories exist for partition "582317058624031631471780675535394015644160622592 ": "/data/riak/bitcask/582317058624031631471780675535394015644160622592"22:48:07.829 [notice] Unused data directories exist for partition "782131735602866014819940711258323334737745149952 ": "/data/riak/bitcask/782131735602866014819940711258323334737745149952"[{ok,<0.30093.11>},...](https://image.slidesharecdn.com/riak-asuccessfulfailure-120210065736-phpapp01/75/Riak-a-successful-failure-27-2048.jpg)







![Thank You http://basho.com/resources/downloads/ https://github.com/basho/riak/ [email_address]](https://image.slidesharecdn.com/riak-asuccessfulfailure-120210065736-phpapp01/75/Riak-a-successful-failure-43-2048.jpg)














![How does Riak compare to Cassandra? [Cassandra London User Group July 2011]](https://cdn.slidesharecdn.com/ss_thumbnails/cassandralondonugjuly2011-110720110309-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)































