release_python_day3_slides_201606.pdf
•
0 likes•7 views

the python training helps people learn python - part3

Recommended
Recommended
More Related Content
Similar to release_python_day3_slides_201606.pdf
Similar to release_python_day3_slides_201606.pdf (20)
More from Paul Yang
More from Paul Yang (20)
Recently uploaded
Recently uploaded (20)
release_python_day3_slides_201606.pdf
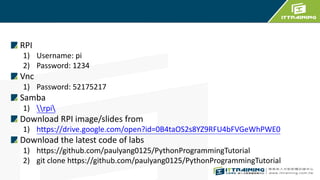
- 1. RPI 1) Username: pi 2) Password: 1234 Vnc 1) Password: 52175217 Samba 1) rpi Download RPI image/slides from 1) https://drive.google.com/open?id=0B4taOS2s8YZ9RFU4bFVGeWhPWE0 Download the latest code of labs 1) https://github.com/paulyang0125/PythonProgrammingTutorial 2) git clone https://github.com/paulyang0125/PythonProgrammingTutorial
- 3. Agenda of Python Programming Day 1 - Basic Python Day 2 - Advanced Python Day 3 - Web Scraping with Python Day 4 - Web application with python
- 7. Courses agenda – Day3 1. Introduction of web scraping 2. Setting up development environment 3. Retrieving HTML data 4. Parsing that data 5. Project1: Geocoordinates data from Wiki and display in GoogleMap 6. Storing the information 7. Advanced topics 8. Accessing APIs 9. Project2: Dress for the weather
- 13. Ethernet Cable DSL/Cable Modem Wall Jack Hub/Switch/Router • A LAN small distance MAN/WAN T1/T3/OC3, OC12,48 ROUTERS Datacenter Like Google / FB Web Server Database The Internet at a Glance
- 14. Application Layer Eg. HTTP, FTP, Email, telnet, … Transport Layer Eg. TCP, UDP Network Layer Eg. IP Link Layer Eg. Ethernet, WiFi Physical Layer Eg. Ethernet Cable, fiber-optics Segments Packets Frames Bits Data This class focus The Internet at a Glance
- 15. HTTP • HTTP: HyperText Transfer Protocol • Client-Server model • Request-Response pattern • Request and response sent using TCP streams • Stateless
- 16. HTTP – diff from HTML HTML: hypertext markup language • Definitions of tags that are added to Web documents to control their appearance HTTP: hypertext transfer protocol • The rules governing the conversation between a Web client and a Web server
- 17. HTTP – Request
- 18. HTTP – Response
- 19. HTTP - URL A URL is used to uniquely identify a resource over the web. Syntax : protocol://hostname:port/path-and-file-name Example : http://xxx.myplace.com:80/cgi-bin/t.html protocol (http, ftp, smtp,dns,news..etc) host name (name.domain name) port (usually 80 but many on 8080) directory path to the resource resource name
- 21. HTTP – status codes • 200 OK • 201 created • 202 accepted • 204 no content • 301 moved perm. • 302 moved temp • 304 not modified • 400 bad request • 401 unauthorized • 403 forbidden • 404 not found • 500 int. server error • 501 not impl. • 502 bad gateway • 503 svc not avail
- 29. RPI setup Python/the relevant modules installed Run setup_rpi.sh bashscript to install • Python3 • IPython • SMBUS/I2C/GPIO module • The package used in the class
- 30. SSH SSH sudo raspi-config -> ssh Enable or disable ssh server hostname –I #know IP #Linux ssh pi@<IP> ssh -Y pi@192.168.1.5 idle3 & #Windows putty https://www.raspberrypi.org/documentation/remote-access/ssh/
- 31. VNC server Remote desktop $sudo apt-get install tightvncserver $sudo tightvncserver https://www.raspberrypi.org/documentation/remote-access/vnc/
- 32. SAMBA • use the raspberry as a simple Network-Attached Storage (NAS) device, can share file with Windows and Linux $sudo apt-get install samba samba-common-bin $sudo nano /etc/samba/smb.conf workgroup = WORKGROUP wins support = yes $mkdir ~/share $sudo nano /etc/samba/smb.conf [PiShare] comment=Raspberry Pi Share path=/home/pi/share browseable=Yes writeable=Yes only guest=no create mask=0777 directory mask=0777 public=no #set yes for public access without password $sudo smbpasswd -a pi http://raspberrypihq.com/how-to-share-a-folder-with-a-windows-computer-from-a-raspberry-pi/
- 33. SAMBA RPIPiShare
- 34. Flask • A micro framework • No database abstraction layer, form validation, or any other components • Flask supports extensions >>> python WebServer.py * Running on http://127.0.0.1:5000/ (Press CTRL+C to quit) 127.0.0.1 - - [26/Apr/2016 04:14:41] "GET / HTTP/1.1" 200 - 127.0.0.1 - - [26/Apr/2016 04:15:23] "GET /index.html HTTP/1.1" 404 - 127.0.0.1 - - [26/Apr/2016 04:16:37] "GET /index.html HTTP/1.1" 404 - http://flask.pocoo.org/
- 35. Chrome and REST Client • Google browser and developer tools sudo apt-get install libxss1 libappindicator1 libindicator7 wget https://dl.google.com/linux/direct/google-chrome- stable_current_amd64.deb sudo dpkg -i google-chrome*.deb
- 36. Chrome and REST Client More on https://github.com/jarrodek/advanced-rest-client Go check and install chrome extension from https://chrome.google.com/webstore/detail/advanced-rest- client/hgmloofddffdnphfgcellkdfbfbjeloo
- 39. Urllib urllib.request urllib.request.urlopen urllib.error urllib.parse More on https://docs.python.org/3.2/library/urllib.request.html • urllib is a standard Python library and contains functions for requesting data across the web, handling cookies, and even changing metadata such as headers and your user agent • Python 3.x, urllib2 was renamed urllib
- 40. Urllib from urllib.request import urlopen html = urlopen("http://google.com/") <http.client.HTTPResponse at 0x1a77f66dbe0> print(html.read())
- 41. Exercise 14 – run web server Use our local flask server as the backend by executing the following in the command line #local - headless mode (no monitor) $ssh pi@<IP> ex. pi@192.168.1.5 More on https://www.raspberrypi.org/documentation/remote-access/ssh/unix.md #target (PI) $sudo python3 WebServer.py * Running on http://127.0.0.1:5000/ (Press CTRL+C to quit) 127.0.0.1 - - [11/Jun/2016 19:08:06] "GET / HTTP/1.1" 200 -
- 42. Exercise 14 – run web server Accessing webserver through opening browser in VNC More on https://www.raspberrypi.org/documentation/remote-access/ssh/unix.md
- 43. Exercise 14 – run web server • Setup ipyhton notebook server where can be accessed in local #target (PI) $jupyter notebook --generate-config $nano ~/.jupyter/jupyter_notebook_config.py # Set ip to '*' to bind on all interfaces (ips) for the public server c.NotebookApp.ip = '*' c.NotebookApp.open_browser = False c.NotebookApp.port = 9999 http://jupyter-notebook.readthedocs.io/en/latest/public_server.html
- 44. Exercise 14 – run web server #target (PI) $ jupyter notebook #local http://172.20.10.8:9999/tree open it by Google Chrome to Create a new notebooks named ex. web_ practice_1
- 45. Exercise 14 – run web server from urllib.request import urlopen html = urlopen("http://google.com/") print(html.read()) • Accessing by urlopen() by running the code below in ipython
- 46. BeautifulSoup it helps format and organize the messy web by fixing bad HTML and presenting us with easily-traversible Python objects representing XML structures $sudo apt-get install python-bs4 REMOTE INSTALL 1) $pip install beautifulsoup4 2) $pip3 install beautifulsoup4 LOCAL INSTALL 1) $ python setup.py install
- 47. BeautifulSoup (html → body → h1). XML/HTML objects structures
- 48. BeautifulSoup from urllib.request import urlopen from bs4 import BeautifulSoup as bs html = urllib.request.urlopen("http://localhost:5000/static/demo1.html") bsObj = bs(html.read(),"html.parser") print(bsObj.h1) #html → body → h1 , bsObj.body.h1 produces the same result print(bsObj.div) BS coverts byte string (html.read) into “html” hierarchy – DOM
- 49. Common problem using urllib: Connecting Reliably (1) html = urlopen("http://hostname/index.html") There are two main things that can go wrong in this line: 1) The page is not found on the server (or there was some error in retrieving it) 404 Page Not Found 2) The server is not found 500 Internal Server Error Throw the generic exception “HTTPError”
- 50. Common problem using urllib: Connecting Reliably (1) HTTP error can be handle by try and except to catch HTTP error # first situation (HTTP error) from urllib.error import HTTPError try: htmlConn = urlopen("http://localhost:5000/static/demo1.html") except HTTPError as e: print(e) #return null, break, or do some other "Plan B" else: #program continues. Note: If you return or break in the #exception catch, you do not need to use the "else" statement bsObj = bs(htmlConn.read(),"html.parser") print(bsObj.h1)
- 51. Common problem using urllib: Connecting Reliably(2) if htmlConn is None: print("URL is not found") else: #program continues pass If the server is not found, urlopen will returns a None object. This object is analogous to null in other programming languages.
- 52. html = urlopen("http://localhost:5000/static/demo1.html") bsObj = bs(htmlConn.read(),"html.parser") print(bsObj.fooTag)#noexistence return None print(bsObj.fooTag.someTag) # accessing None trigger exception AttributeError: 'NoneType' object has no attribute 'someTag' Even if the page is retrieved successfully, there is still the issue of the content on the page. If you attempt to access a tag that does not exist, bs returns None Common problem using urllib: Connecting Reliably(2)
- 53. try:#guard against these two situations badContent = bsObj.foo.anotherTag except AttributeError as e: print("Tag was not found") else: if badContent == None: print("Tag was not found") else: print(badContent) to explicitly check for both failure situations: Check the exception of accessing None object In case the tag doesn’t exist too Common problem using urllib: Connecting Reliably(2)
- 54. Exercise 15 – easy and organized way to handle issues during scraping Create getTitle(url) function to retrieve title data from html as well as prevent HTTPError, AttributeError and possible None object url: http://localhost:5000/static/demo1.html exercises/Exercises_Day3.ipynbc
- 57. searching for tags by attributes • Use findall() to extract a Python list of proper nouns • the most popular method in bs API • findAll(tagName, tagAttributes) • Unlike bsObj.tagName only get the first occurrence of the tag • get_text() separates the content from the tags and return “str” htmlConn = urlopen("http://localhost:5000/static/demo2.html") bsObj = bs(htmlConn,"html.parser") name_list = bsObj.findAll("span",{"class":"green"}) for n in name_list: print(type(n)) print(n.get_text()) Anna Pavlovna Scherer Empress Marya Fedorovna
- 58. searching for tags by attributes • The two functions you will likely use the most • findAll(tag, attributes, recursive, text, limit, keywords) • find(tag, attributes, recursive, text, keywords) • Recursive default is set to True – look at children and children’s children • Limit sets 1 == find() • keyword argument allows you to select tags that contain a particular attribute. %95 time only use tag and attribute bsObj.findAll("span", {"class":"green", "class":"red"}) #return the both red and green tag in the document bsObj.findAll({'h1','h2','h3'}) #return a list of all the header tags in a document bsObj.findAll(text="the prince") #find the number of times “the prince” print(len(nameList)) #7 bsObj.findAll(id="text") #same as bsObj.findAll("", {"id":"text"}) keyword argument is actually a technically redundant
- 60. BS objects BeautifulSoup objects 1) bs4.element.ResultSet Tag objects NavigableString objects The Comment object 1) Ex. <!--like this one--> by calling find and findAll Represent text within tag by calling string() [<span class="green">Anna Pavlovna Scherer</span>, <span class="green">Empress MaryaFedorovna</span>] Each in resultset , drilling down
- 61. Accessing by the location of tag Navigating Trees 1) Dealing with children and other descendants 2) Children are always exactly one tag below a parent, whereas descendants can be at any level in the tree below a parent Tr is children of table tag tr, th, td, img, and span are all descendants of the table tag All children are descendants, but not all descendants are children bsObj.body.h1 bsObj.div.findAll("img") BS func always deal with the descendant
- 63. Accessing by the location of tag htmlConn = urlopen("http://localhost:5000/static/demo3.html") bsObj = bs(htmlConn,"html.parser") for c in bsObj.find('table',{'id':"giftList"}).children: print(type(c)) print(c) for c in bsObj.find('table',{'id':"giftList"}).descendants: print(type(c)) print(c)
- 64. Accessing by the location of tag for sibling in bsObj.find("table",{"id":"giftList"}).tr.next_siblings: print(sibling) print all rows of products from the product table, except for the first title row Ignore title row next_siblings() function makes it trivial to collect data from tables, especially ones with title rows
- 66. BS + REGEX images = bsObj.findAll("img", {"src":re.compile(".*img.*.jpg")}) for image in images: print(image["src"]) import re html = urlopen("http://localhost:5000/static/demo3.html") bsObj = bs(html,"html.parser") images = bsObj.findAll("img“) May find extra image - hidden images, blank images used for spacing and aligning elements in modern website
- 67. Beyond BeautifulSoup Lxml 1) being very low level and heavily based on C. 2) it is very fast at parsing most HTML documents. HTML Parser 1) requires no installation
- 68. Project-1 (3-5)
- 70. Microformats
- 71. Microformats
- 73. XHTML geo snippet describing Taipei Taiwan: <!– 2. When used as one class, the separator must be a semicolon --> <span style="display: none" class="geo"> 25.033; 121.633 </span> <!– 1 .The multiple class approach --> <span class="geo-dms"> <span class="latitude"> 25°02ʹN </span> <span class="longitude"> 121°38ʹE </span> </span>
- 74. Google Maps Embed API https://developers.google.com/maps/documentation/embed/guide?authuser=1#_1
- 75. https://developers.google.com/maps/documentation/embed/guide?authuser=1#_1 Google Maps Embed API
- 76. Exercise 1. 前往 Google Developers Console。 2. Select a project, or create a new one. 3. Open the API Library in the Google Developers Console. If prompted, select a project or create a new one. Select the Enabled APIs link in the API section to see a list of all your enabled APIs. Make sure that the API is on the list of enabled APIs. If you have not enabled it, select the API from the list of APIs, then select the Enable API button for the API. 4. In the sidebar on the left, select Credentials. 5. 瀏覽器API 金鑰,請選取 [Add credentials] > [API key] > [Browser key] 來 建立。 a. Setup API 金鑰
- 78. Exercise 1. jupyter notebook #start server , can use ipython notebook 2. Access http://localhost:9999/ by any preferred browser 3. Type in setup codes and execute by “SHIFT + ENTER” from urllib.request import urlopen import urllib import requests #conda/pip install requests import sys from bs4 import BeautifulSoup as bs URL = " https://en.wikipedia.org/wiki/Taipei" b. Ipython Refer to Official_Project1_Day3.ipynb
- 79. req = requests.get(URL, headers={'User-Agent':"Mining the Wiki"}) soup = bs(req.text,"html.parser") geoTag = soup(class_='geo') #This code finds all the tags in the document geoTag = soup(True,'geo') geotag geoTag = soup.find(class_='geo-dms') lat = geoTag.find(True, 'latitude').string Lat geoTag = soup.find(True, 'geo') geoTag.string.split(';') b. Ipython 4. Type in connecting and parsing codes !"#$%&'()%##*+,-.+/012343567'89:29161;"<#$%&/='"#$%&'()%##*+,-.+/012343567'89:29161;"<#$%&/='"#$%&'()%##*+,-.+/012343567'8 9:29161;"<#$%&/> '35°55′45″N' ['35.92917', ' -86.85750'] Exercise
- 80. def geolookup(): geoTag = soup.find(True, 'geo') if geoTag and len(geoTag) > 1: lat = geoTag.find(True, 'latitude').string lon = geoTag.find(True, 'longitude').string print('a.Location is at', lat, lon) return lat,lon elif geoTag and len(geoTag) == 1: (lat, lon) = geoTag.string.split(';') (lat, lon) = (lat.strip(), lon.strip()) print('b. Location is at', lat, lon) return lat,lon else: print('No location found') 5. Mix together Exercise def geolookup_dms(): geoTag = soup.find(True, 'geo-dms') if geoTag and len(geoTag) > 1: lat = geoTag.find(True, 'latitude').string lon = geoTag.find(True, 'longitude').string print('Location is at', lat, lon) return lat,lon (lat, lon) = geolookup_dms()
- 81. from IPython.display import Iframe from IPython.core.display import display api = 'key=“yourKEY”‘ maptype = '&maptype=satellite‘ zoom = "&zoom=18“ google_maps__view_url = embedRawUrl + mode + api + "&q={0}+{1}".format(lat, lon) google_maps__view_url display(IFrame(google_maps__view_url, '600px', '400px') 6. Displaying in Google Map Exercise 'https://www.google.com/maps/embed/v1/search?key=YOURKEY&q=35°55′45″N+86°51′27″W'
- 82. embedRawUrl = 'https://www.google.com/maps/embed/v1/‘ lat_long = "&location={0},{1}".format(lat, lon) mode = "streetview?“ google_maps__view_url = embedRawUrl + mode + api + lat_long google_maps__view_url display(IFrame(google_maps__view_url, '600px', '400px')) 7. Displaying streetview in Google Map 'https://www.google.com/maps/embed/v1/streetview?key=YOURKEY&location=35.92917,-86.85750' Exercise
- 84. Three major data • want your scrapers to write to a database • collect some documents off the Internet and put them on your hard drive • media files • Save URL • Save file
- 85. Media File • Storing media files • Two ways: Save URL or save file • Both have their advantages/disadvantages http://www.tutorialspoint.com/python/
- 86. Media File from urllib.request import urlopen from urllib.request import urlretrieve from bs4 import BeautifulSoup as bs from urllib.error import HTTPError html = urlopen("http://www.tutorialspoint.com/python/") baseURL = 'http://www.tutorialspoint.com' bsObj = bs(html,"html.parser") imageLocation = bsObj.find(“a”, {“title”: "tutorialspoint"}).find("img")["src"] imageLocation = baseURL + imageLocation urlretrieve (imageLocation, "logo.jpg") If you only need to download a single file 'http://www.tutorialspoint.com/python/images/logo.png'
- 88. Exercise 17 Download all media File 2. retrieve_absoluteURL() http://www.tutorialspoint.com /theme/js/script-min-v4.js -> http://tutorialspoint.com/theme/js/script-min-v4.js 1. retrieve_mediaDownloadPaths() 3. create_localFilePath() exercises/Exercises_Day3.ipynb
- 89. CSV • Storing data to CS • CSV, or comma-separated values, is one of the most popular file formats in which to store spreadsheet data. • Supported by MS excel or openoffice fruit,cost apple,1.00 banana,0.30 pear,1.25
- 90. CSV Create and write data into CSV import csv filename = "test.csv" try: csvFile = open(filename, 'w') writer = csv.writer(csvFile,lineterminator='n') writer.writerow(('數字', '數字加2', '數字乘2')) for i in range(10): writer.writerow((i, i+2, i*2)) except csv.Error as e: print('file %s, line %d: %s' % (filename, writer.line_num, e)) finally: csvFile.close()
- 92. RDMS – SQLite Content credited: http://www-03.ibm.com/ibm/history/ibm100/us/en/icons/reldb/ • two other major closed source database systems: Microsoft’s SQL Server and Oracle’s DBMS • Mysql is the most popular open source relational database used by youtube, facebook Flat file DB Rational
- 93. RDMS – SQLite • Setup database (Database_setup.py) • Connecting to an SQLite database • Creating a new SQLite database • Adding new columns • Populate your data • Inserting and updating rows
- 94. RDMS – SQLite • Retrieving data • Querying the database - Selecting rows • The tuples cursor • The dictionary cursor
- 98. Crawling through form and login • How do I access information behind a login screen • Forms and logins are an integral part of these types of sites and almost impossible to avoid • Focus on HTTP PUT methods using Requests lib (like GET request with urllib)
- 99. Submitting a Basic Form <h2>請輸入你的大名!(PHP)</h2> <form method="post" action="hello.php"> 姓: <input type="text" name="firstname"><br> 名: <input type="text" name="lastname"><br> <input type="submit" value="Submit" id="submit"> </form> • Most web forms consist of a few HTML fields, a submit button, and an “action” page, where the actual form processing is done • HTML forms help them format POST requests
- 100. Submitting a Basic Form import requests params = {'firstname': ‘Paul', 'lastname': ‘Yang'} r = requests.post("http://localhost:5000/demo_submit_form_1", data=params) print(r.text) • Submitting a form with the Requests library Here basically php is written down
- 101. A modern web form • Mixing different web elements Content credited : http://post.oreilly.com/client/o/oreilly/forms/quicksignup.cgi
- 103. Radio Buttons, Checkboxes • Two things need to worry - the name of the element and its value <form method="GET" action="someProcessor.php"> <h2>請輸入你的名</h2><br> <input type="radio" name="firstname" value="Paul" />Paul<br> <input type="radio" name="firstname" value="Jack" />Jack<br> <h2>請輸入你的姓</h2><br> <input type="radio" name="lastname" value="Yang" />Yang<br> <input type="radio" name="lastname" value="Wang" />Wang<br> <input type="submit" value="Submit" /> </form>
- 104. Radio Buttons, Checkboxes import requests params = {'firstname': 'Paul', 'lastname': 'Yang'} r = requests.get("http://localhost:5000/demo_submit_form_1",params=params) print(r.text) • Submitting a form using GET method with the Requests library Use requests for GET too but need to use “params” instead of data
- 105. Execise20 - Know using GET or POST • Run flask server by • sudo python WebServer.py • Open the URLs by Google Chrome • Form by PUT method • http://localhost:5000/python_demo/demo5.html • Form by PUT method • http://localhost:5000/python_demo/demo6.html • Enter your first name(名) and last name (姓)
- 106. Execise20 - Know using GET or POST • Check it by looking at URL input and the developer tool(press ctrl+shift + i) GET with “params” ? Firstname..etc PUT with form data
- 107. Submitting a File <h2>上傳你的檔案!</h2> <form action="/upload" method="post" enctype="multipart/form-data">上傳 jpg, png, or gif格式: <input type="file" name="file"><br> <input type="submit" value="Upload File"> </form> import requests files = {'file': open('./upload/apple_store.jpg', 'rb')} r = requests.post("http://localhost:5000/upload",files=files) print(r.text) http://localhost:5000/python_demo/demo7.html
- 108. Cookie • How is this different from a login form, which lets you exist in a permanent “logged in” state throughout your visit to the site? • Most modern websites use cookies to keep track of who is logged in and who is not. Once a site authenticates your login credentials a it stores in your browser a cookie, which usually contains a server-generated token, timeout, and tracking information <h2>Log In Here!</h2> Warning: Your browser must be able to use cookies in order to view our site! <form method="post" action="welcome.php"> Username (use anything!): <input type="text" name="username"><br> Password (try "password"): <input type="password" name="password"><br> <input type="submit" value="Login"> </form> Visit http://pythonscraping.com/pages/cookies/login.html
- 109. Cookie • How is this different from a login form, which lets you exist in a permanent “logged in” state throughout your visit to the site? • Most modern websites use cookies to keep track of who is logged in and who is not. Once a site authenticates your login credentials a it stores in your browser a cookie, which usually contains a server-generated token, timeout, and tracking information import requests params = {'username': 'Ryan', 'password': 'password'} r = requests.post("http://pythonscraping.com/pages/cookies/welcome.php", params) print("Cookie is set to:") print(r.cookies.get_dict()) print("-----------") print("Going to profile page...") r = requests.get("http://pythonscraping.com/pages/cookies/profile.php",cookies=r.cookies) print(r.text) Cookie is set to: {'username': 'Ryan', 'loggedin': '1'} ----------- Going to profile page... Hey Ryan! Looks like you're still logged into the site!
- 110. Cookie • the session is a data structure that an application uses to store temporary data that is useful only during the time a user is interacting with the application, it is also specific to the user. import requests session = requests.Session() params = {'username': ‘paul', 'password': 'password'} s = session.post("http://pythonscraping.com/pages/cookies/welcome.php", params) print("Cookie is set to:") print(s.cookies.get_dict()) print("-----------") print("Going to profile page...") s = session.get("http://pythonscraping.com/pages/cookies/profile.php") print(s.text) Cookie is set to: {'username': ‘paul', 'loggedin': '1'} ----------- Going to profile page... Hey username! Looks like you're still logged into the site!
- 111. HTTP basic access authentication import requests from requests.auth import AuthBase from requests.auth import HTTPBasicAuth auth = HTTPBasicAuth(‘paul', 'password') r = requests.post(url="http://pythonscraping.com/pages/auth/login.php", auth= auth) print(r.text) Content credited: http://php.net/manual/en/features.http-auth.php
- 112. Execise-21 • Try the previous codes • Submitting a File • HTTP basic access authentication
- 113. Accessing APIs (3-8)
- 114. application programming interfaces • Provide nice, convenient interfaces between multiple disparate applications • “API” has been commonly understood as meaning “web application API.” • request to an API via HTTP for some type of data, and the API will return this data in the form of XML or JSON. • Sport • ESPN provides APIs for athlete information, game scores, and more • Music • Spotify • Map • Google Content credited: http://apievangelist.com/2013/01/28/virtualized-api-stacks/
- 115. application programming interfaces http://freegeoip.net/json/103.235.46.39 {"ip":"103.235.46.39","country_code":"HK","country_name":"Hong Kong","region_code":"", "region_name":"","city":"Central District","zip_code":"","time_zone":"Asia/Hong_Kong", "latitude":22.2833,"longitude":114.15,"metro_code":0} JSON return by freegeoip API ipAddress
- 117. Authentication All methods of API authentication generally revolve around the use of a token of some sort, which is passed to the web server with each API call made. http://developer.echonest.com/api/v4/artist/songs?api_key=<your api key here> %20&name=guns%20n%27%20roses&format=json&start=0&results=100 #get song list 'https://www.google.com/maps/embed/v1/streetview?key=YOURKEY&location=35.92917,- 86.85750' #get googlemap token = "<your api key>" webRequest = urllib.request.Request("http://myapi.com", headers={"token":token}) html = urlopen(webRequest)
- 119. Passing JSON Use Python “json” lib • parse JSON from strings or files or convert Python dictionaries or lists into JSON strings. • Load(): parse(decode) JSON into dict • Dump(), encode python data type into JSON format import json obj = [[ 1 , 2 , 3 ], 123 , 123.123 , 'abc' ,{ 'key1' :( 1 , 2 , 3 ), 'key2' :( 4 , 5 , 6 )}] encodedjson = json.dumps(obj) print(repr(obj)) print(encodedjson) [[1, 2, 3], 123, 123.123, 'abc', {'key2': (4, 5, 6), 'key1': (1, 2, 3)}] #python data [[1, 2, 3], 123, 123.123, "abc", {"key2": [4, 5, 6], "key1": [1, 2, 3]}] #JSON
- 120. Passing JSON import json from urllib.request import urlopen def getCountry(ipAddress): response = urlopen("http://freegeoip.net/json/"+ipAddress).read().decode('utf-8') responseJson = json.loads(response) return responseJson.get("country_code") print(getCountry("103.235.46.39")) http://freegeoip.net/json/103.235.46.39
- 121. Project-2 (3-9)
- 123. Idea tell what ppl should wear and if need an umbrella based on their location by using the parameters below to determine Rain Cloudiness Temperature Wind Humidity Description {'cloudiness': 76, 'description': 'light rain', 'humidity': 100, 'rain': 0.03, 'temperature': 295.297, 'wind': 3.57}
- 124. • Get user’s city id • Get user’s arrival date and time User Input • Get a 5-Day Forecast • parse the data in forecast to covert to readable format • determine what user should wear Process Recommend ation Output Idea
- 127. Requirement Implement the following requirement by using function a. Setup openweathermap account and get the developer key b. Configure to import all required modules c. Get where user is and look up city id accordingly d. Get a 5-Day Forecast from openweathermap e. Get the arrival date and time f. Get the forecast for the required date and time g. parse the data in forecast to covert to readable format h. to determine what should wear i. test and finish
- 128. Exercise 1. 前往 https://home.openweathermap.org/users/sign_up to create a new account 2. Go to the account setting to create the key and copy it 3. put city.list.json on the same folder where you run ipython( *.ipynb) 4. Run ipyton notebook command a. Setup
- 138. Reference Raspberry Pi and Python online resource 1) https://www.raspberrypi.org/documentation/remote-access/ssh/ 2) https://www.raspberrypi.org/documentation/remote-access/vnc/ 3) http://raspberrypihq.com/how-to-share-a-folder-with-a-windows-computer-from-a- raspberry-pi/ 4) http://raspberrypihq.com/how-to-share-a-folder-with-a-windows-computer-from-a- raspberry-pi/ 5) http://flask.pocoo.org/ 6) https://github.com/jarrodek/advanced-rest-client 7) https://docs.python.org/3.2/library/urllib.request.html 8) https://www.raspberrypi.org/documentation/remote-access/ssh/unix.md 9) http://jupyter-notebook.readthedocs.io/en/latest/public_server.html
- 139. BACKUP BACKUP
- 140. RPI image BACKUP http://raspberrypi.stackexchange.com/questions/311/how-do-i-backup-my-raspberry-pi If you are running Linux then you can use the dd command to make a full backup of the image: dd if=/dev/sdx of=/path/to/image or for compression: dd if=/dev/sdx | gzip > /path/to/image.gz Where sdx is your SD card. To restore the backup, you reverse the commands: dd if=/path/to/image of=/dev/sdx or when compressed: gzip -dc /path/to/image.gz | dd of=/dev/sdx http://lifehacker.com/how-to-clone-your-raspberry-pi-sd-card-for-super-easy-r-1261113524 https://www.raspberrypi.org/documentation/installation/installing-images/linux.md
- 141. Scanning IP range $nmap -sP -n 172.20.10.1-30 Nmap scan report for 172.20.10.1 Host is up (1.0s latency). Nmap scan report for 172.20.10.3 Host is up (1.0s latency). Nmap scan report for 172.20.10.15 Host is up (0.0013s latency). Nmap done: 30 IP addresses (3 hosts up) scanned in 15.63 seconds #windows Advanced IP scanner http://www.stevendobbelaere.be/how-to-do-a-network-ip-range-scan-with-nmap/
- 142. Connecting between client to server Not just at the browser level
- 143. Connecting between client to server