Downloaded 18 times




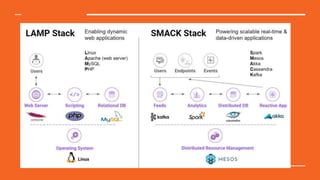





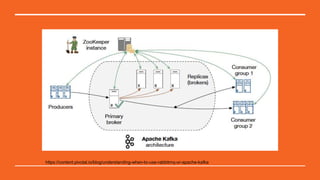
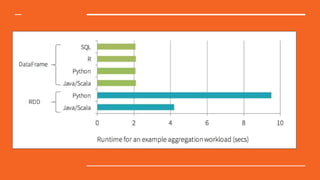




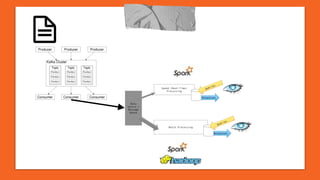





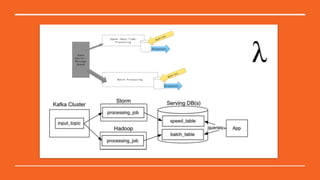
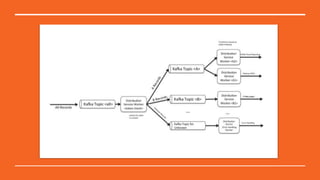
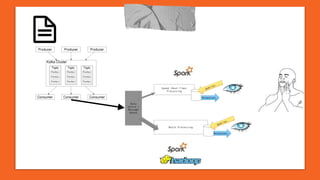





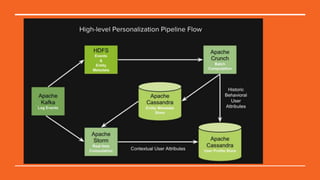





This document discusses Python in the big data ecosystem using the SMACK stack. SMACK stands for Spark, Kafka, Cassandra, Mesos, and Akka. Spark provides in-memory processing for speed and efficiency. Kafka handles data streaming. Cassandra provides scalable data storage across multiple computers. Mesos enables containerized environments for scalability and management. Akka supports high concurrency. The document outlines how SMACK is useful for mixed volume/velocity data, ETL/ELT processes, and near real-time analytics at scale. It provides examples of using each tool in the stack and discusses when SMACK is applicable.





















































