Download as PDF, PPTX





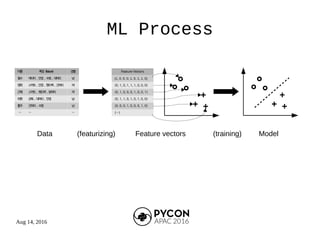








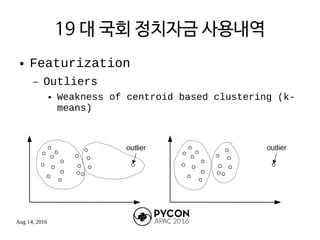






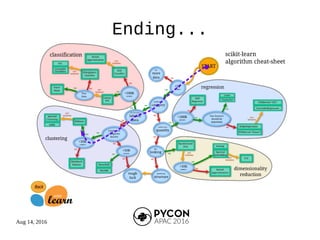


The document outlines the machine learning process and the speaker's background as a research engineer in a fintech startup, focusing on fraud detection using machine learning techniques. It details steps such as featurization, model training, and model evaluation, while addressing specific projects related to the 19th National Assembly's voting results and political funding usage. The speaker emphasizes the importance of proper data handling and model training while providing references to relevant code repositories.

![[20160813, PyCon2016APAC] 뉴스를 재미있게 만드는 방법; 뉴스잼](https://cdn.slidesharecdn.com/ss_thumbnails/random-160813075211-thumbnail.jpg?width=640&height=640&fit=bounds)







![PyCon APAC 2016 Regular Expression[A-Z]+](https://cdn.slidesharecdn.com/ss_thumbnails/pycon2016-160814073914-thumbnail.jpg?width=640&height=640&fit=bounds)




![[NEXT] Flask 로 Restful API 서버 만들기](https://cdn.slidesharecdn.com/ss_thumbnails/flask2-141209115126-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2016 데이터 그랜드 컨퍼런스] 2 5(빅데이터). 유비원 비정형데이터 중심의 big data 활용방안](https://cdn.slidesharecdn.com/ss_thumbnails/2-5-161125005035-thumbnail.jpg?width=640&height=640&fit=bounds)
![[9]ix.유엔진 사용자매뉴얼 gw리뉴얼_2차_110819](https://cdn.slidesharecdn.com/ss_thumbnails/9ix-gw2110819-110821223507-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





















![[DSC Europe 25] Paula Garcia Esteban -Building the Future: The Role of Data S...](https://cdn.slidesharecdn.com/ss_thumbnails/9ld1r1bsqpwve8qfvphy-paula-garcia-esteban-building-the-future-260122103838-4171f5cb-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Marcos Heidemann - Beyond the Hype: Making AI Coding Assistan...](https://cdn.slidesharecdn.com/ss_thumbnails/eexkhvldrjsopspdjbur-marcos-heidemann-beyond-the-hype-getting-real-value-out-of-ai-assisted-coding-260121115910-7e9d41ec-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Mikhail Rozhkov - AI Product Canvas: From Business Goals to T...](https://cdn.slidesharecdn.com/ss_thumbnails/d53doddtpgfqivmzqel6-mikhail-rozhkov-ai-product-canvas-v1-260121115910-9dd517a7-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DSC Europe 25] Srdj Stanisic - Local and Private AI in UX.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/vwmetykqmztgmokmmkfa-3-srdjan-stanisic-local-and-small-ai-in-ux-260120105855-55a31869-thumbnail.jpg?width=640&height=640&fit=bounds)


