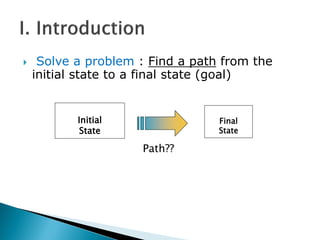
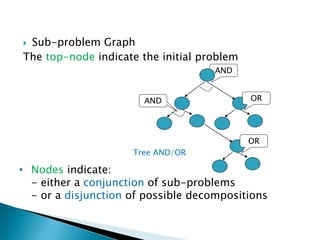
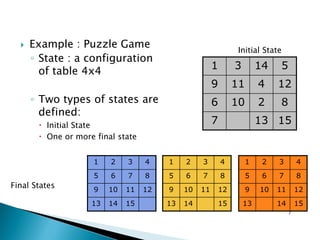
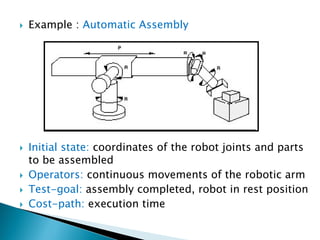
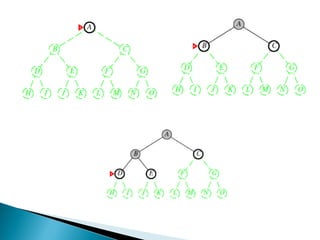
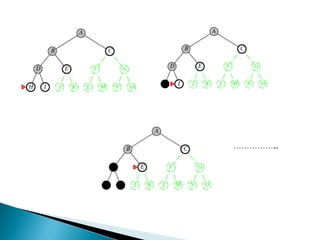
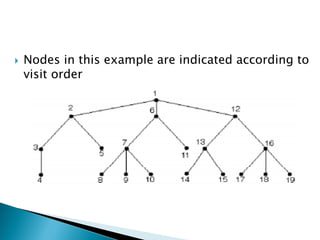
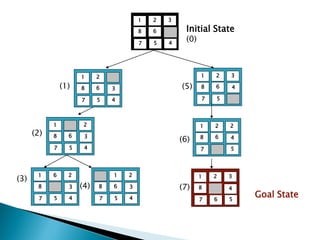
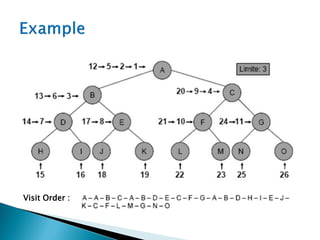
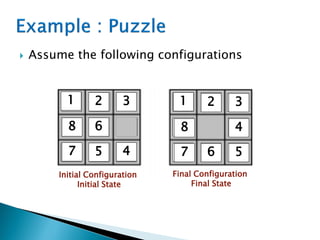
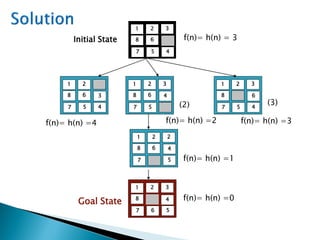
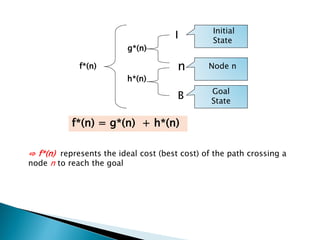
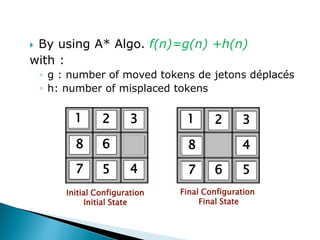
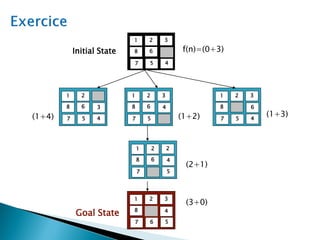
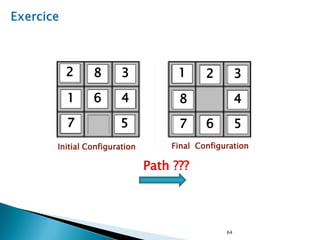
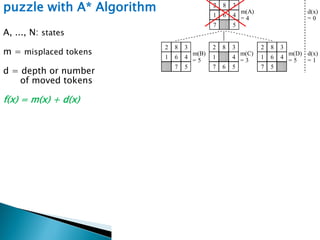
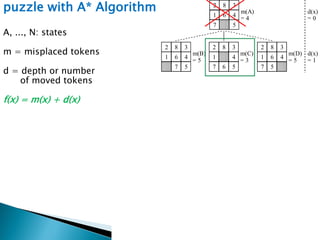
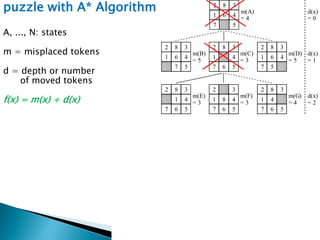
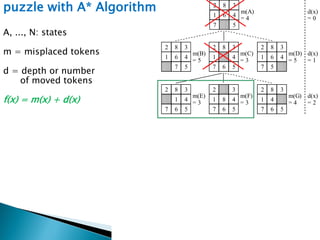
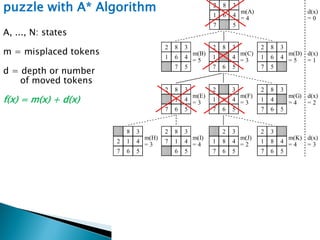
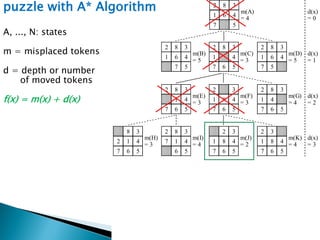
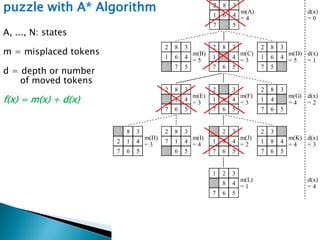
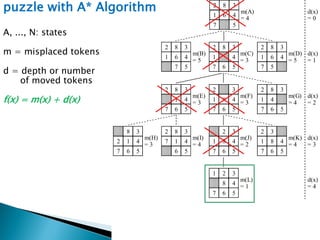
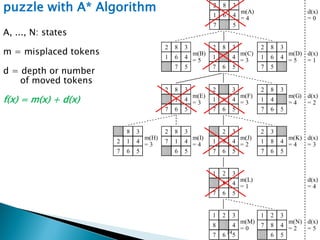
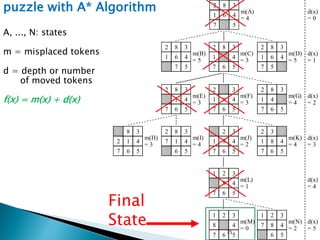
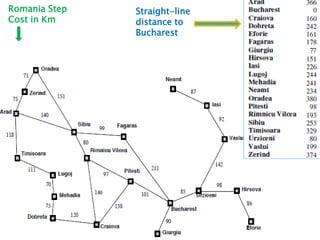
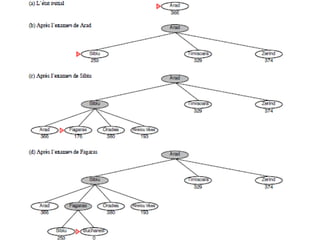
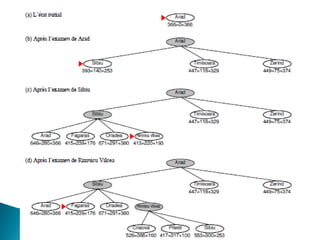
The document describes search algorithms for problem solving. It defines key concepts like state, node, problem representation, and search strategies. It then explains blind search algorithms like breadth-first search, depth-first search, depth-limited search, and iterative deepening search. Finally, it covers heuristic search algorithms like greedy search and A* search, which use an evaluation function and heuristic to guide the search towards more promising solutions.












![function Tree-Search (problem) returns a solution, or failure
List_toExplore ← Insert(Make-Node (Initial_State[problem]))
loop do
if List_toExplore is empty then return failure
else node ← Remove(List_toExplore)
if Goal-Test(problem, State(node)) then return node
else List_toExplore ←InsertAll(Expand(node, problem), List_toExplore)
EndLoop](https://image.slidesharecdn.com/chapitre2final-231219185104-bb6e5871/85/problem-solve-and-resolving-in-ai-domain-probloms-19-320.jpg)
![function Expand( node, problem) returns a set of nodes
successors←
for each (action, result) in Successor-Function (problem, State[node]) do
N← new Node
Parent [N] ← node;
Action[N]←action;
State[N]←result
Path_Cost[N]←Path-Cost[node] + Step_Cost(State[node], (action, result))
Depth[N]←Depth[node] + 1
add N to successors
return successors](https://image.slidesharecdn.com/chapitre2final-231219185104-bb6e5871/85/problem-solve-and-resolving-in-ai-domain-probloms-20-320.jpg)





























































![[DSC Europe 25] Predrag Maletic - Scaling AI in Banking – Our Strategic Journ...](https://cdn.slidesharecdn.com/ss_thumbnails/qu2onv0aruwlvqtygmxx-predrag-maletic-scaling-ai-in-banking-260123083019-6cf1da1d-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Milos Belcevic - Product Professional's Journey to Full-Stack...](https://cdn.slidesharecdn.com/ss_thumbnails/1zovd6fgsycdg4wvgvls-milos-belcevic-product-professionals-journey-to-full-stack-product-developer-260123083019-d993120d-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Raul Cruz Bonilla - Harnessing GEN AI in Fashion, Luxury and ...](https://cdn.slidesharecdn.com/ss_thumbnails/me7nvup5thwqzwzblbvw-raul-cruz-harnessing-ai-en-luxury-260123083019-32ac5a43-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Josip Saban - Career building for data professionals.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/zroflcttkm1vmli0txea-josip-saban-career-building-for-data-professionals-260123083019-587cdb8c-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DSC Europe 25] Ekaterina Bubenko - Behind the Curtain: How Data Roles Collab...](https://cdn.slidesharecdn.com/ss_thumbnails/anmv6x8dstqbbzchoklr-ekaterina-bubenko-behind-the-curtain-how-data-roles-collaborate-in-the-ai-era-a-260123083019-4b252ec7-thumbnail.jpg?width=640&height=640&fit=bounds)



