Download to read offline




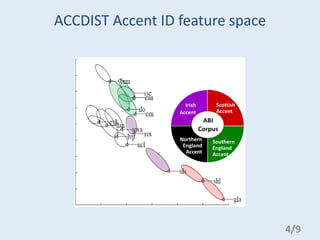







This document summarizes Maryam Najafian's research on acoustic model selection for recognizing regional accented speech. The research aims to use different automatic identification systems like phonotactic, i-vector, and ACCDIST-SVM features to select acoustic models for GMM-HMM and DNN-HMM based speech recognition of accents. The models are trained on British English and tested on 14 different accents from the ABI corpus. The document outlines the baseline identification systems, accent identification features, GMM-HMM adaptation techniques, comparisons of GMM-HMM and DNN-HMM, and the use of extra training and pre-training materials for DNN-HMMs.



























