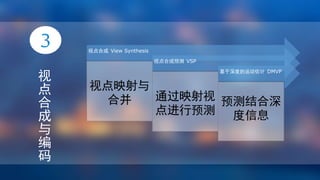
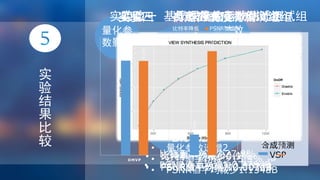
该文档是关于基于深度图的立体视频编码算法研究的毕业设计综述,涵盖了多种实验结果及数据分析。主要研究了纹理量化、深度运动估计和自适应亮度补偿等算法的性能比较,分析了比特率和峰值信噪比的变化趋势。研究结果表明,某些算法在减少比特率的同时提高了视频质量。