Downloaded 16 times


















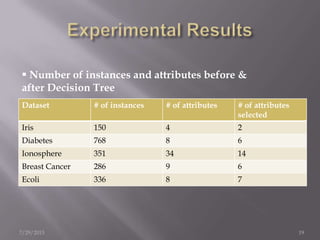
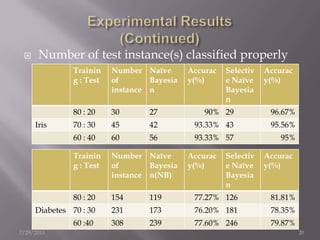
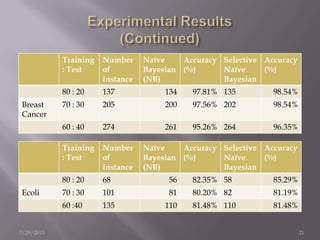
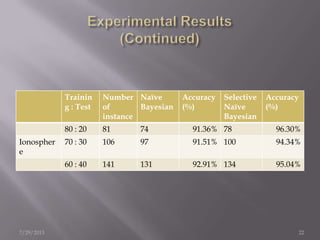
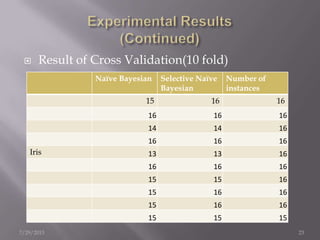
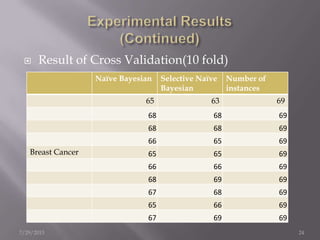
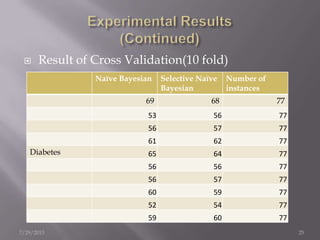
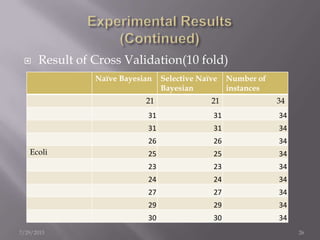
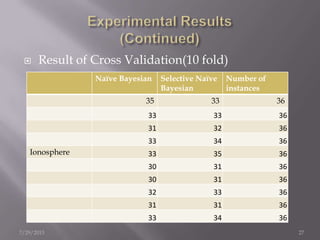



The document discusses the use of a Naïve Bayesian classifier and decision trees in machine learning, emphasizing their efficiency in analyzing large datasets with continuous data streams. It presents an experimental design comparing the accuracy of a selective Naïve Bayesian approach against traditional methods across various datasets. Key findings indicate that the selective approach can improve performance in terms of accuracy by focusing on relevant attributes, thus enhancing the learning process.






















































