Download as KEY, PPTX
































![Another example
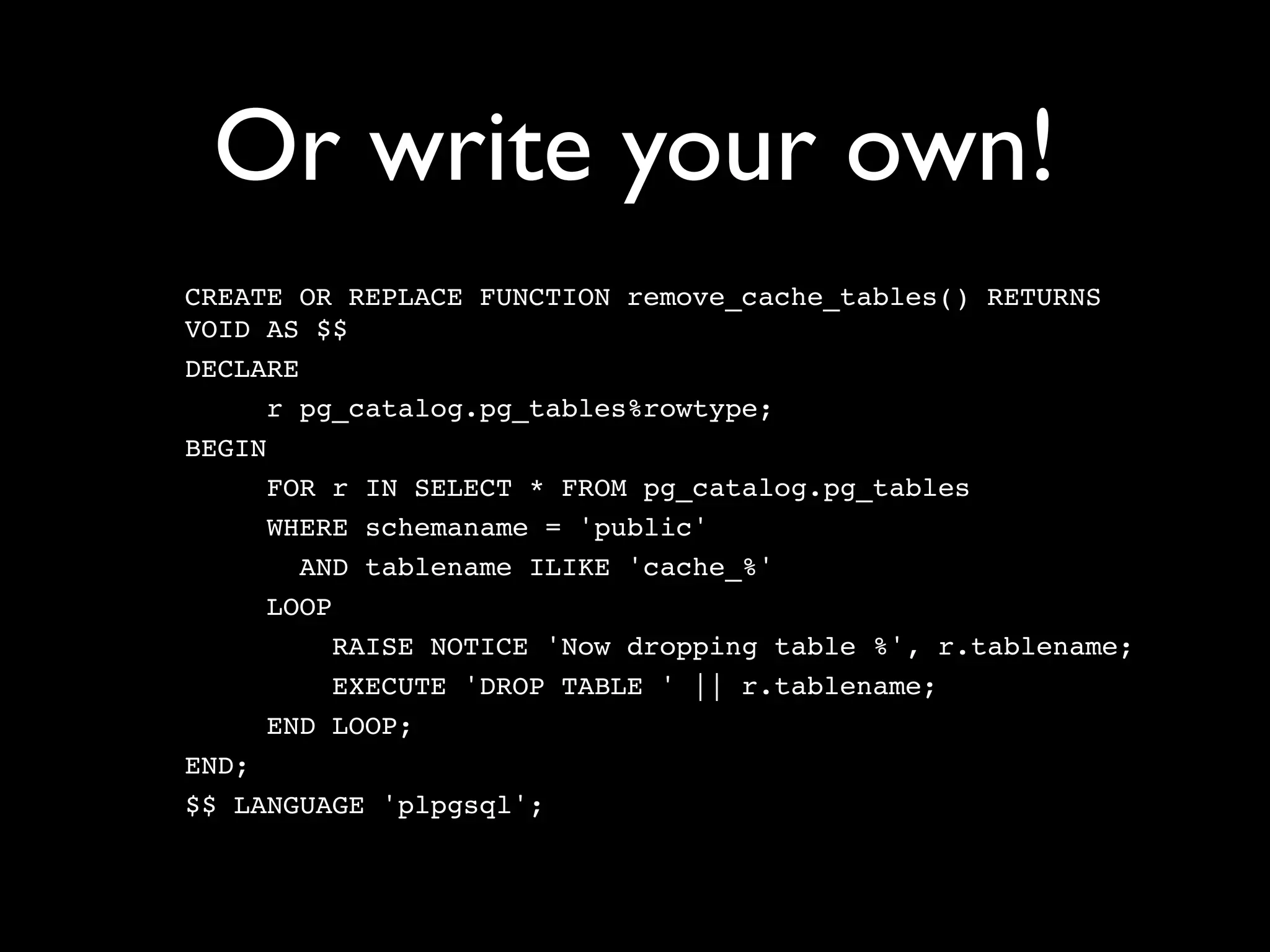
CREATE OR REPLACE FUNCTION store_hostname() RETURNS
TRIGGER AS $store_hostname$
BEGIN
NEW.hostname := 'http://' ||
substring(NEW.url, '(?:http://)?([^/]+)');
RETURN NEW;
END;
$store_hostname$ LANGUAGE plpgsql;](https://image.slidesharecdn.com/postgresqlil-techtalks-121114034330-phpapp02/75/PostgreSQL-40-2048.jpg)



































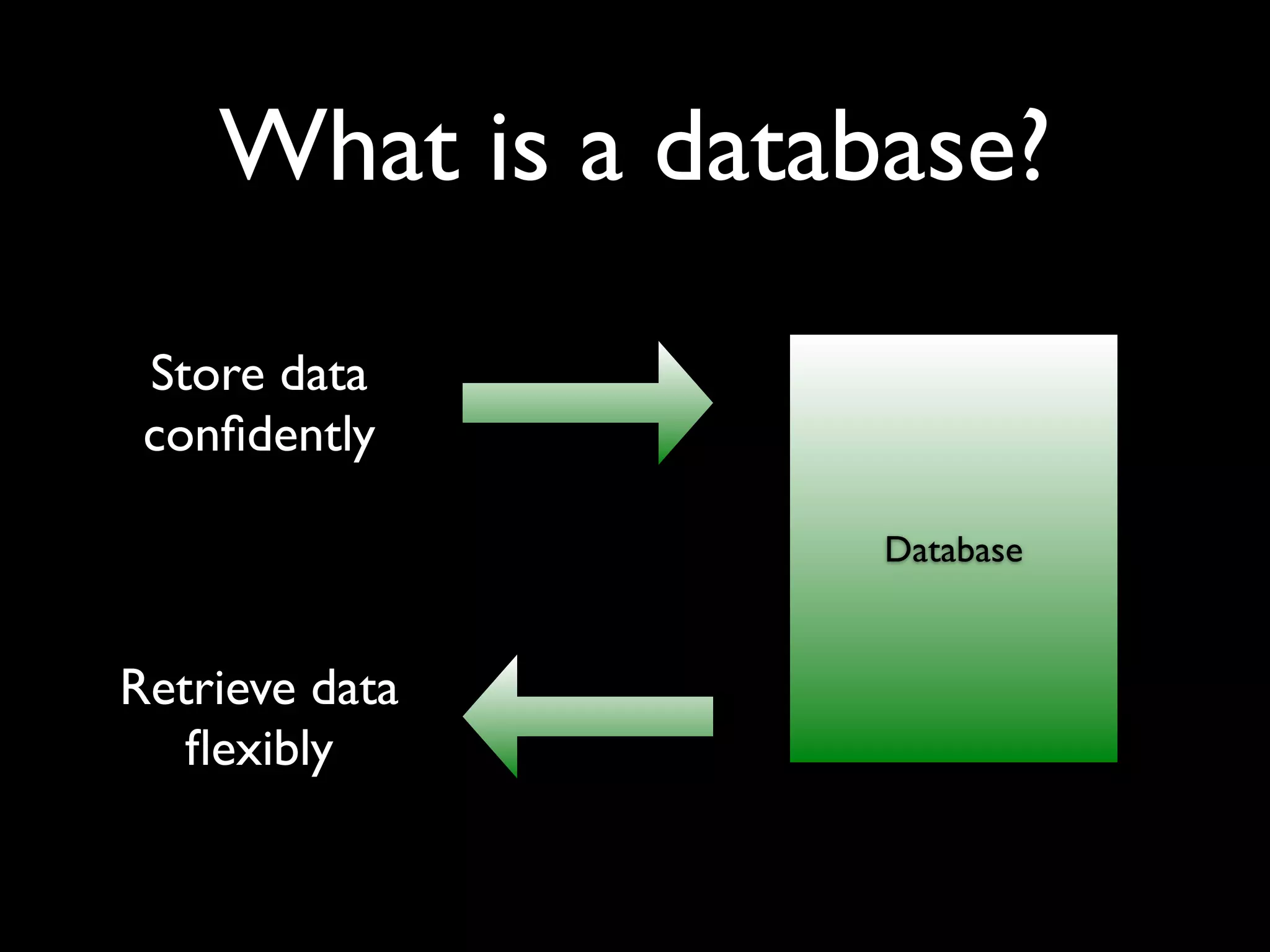
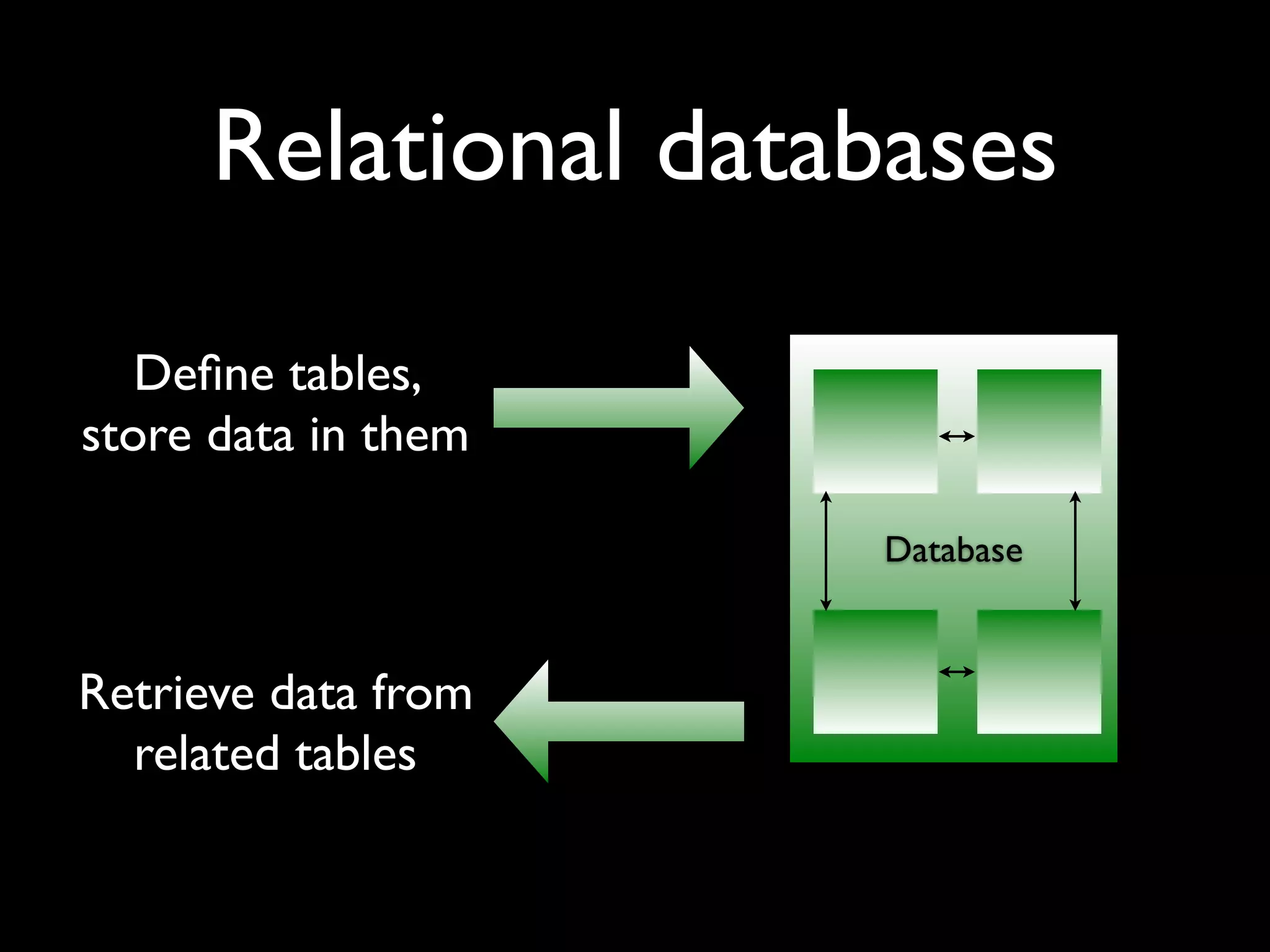
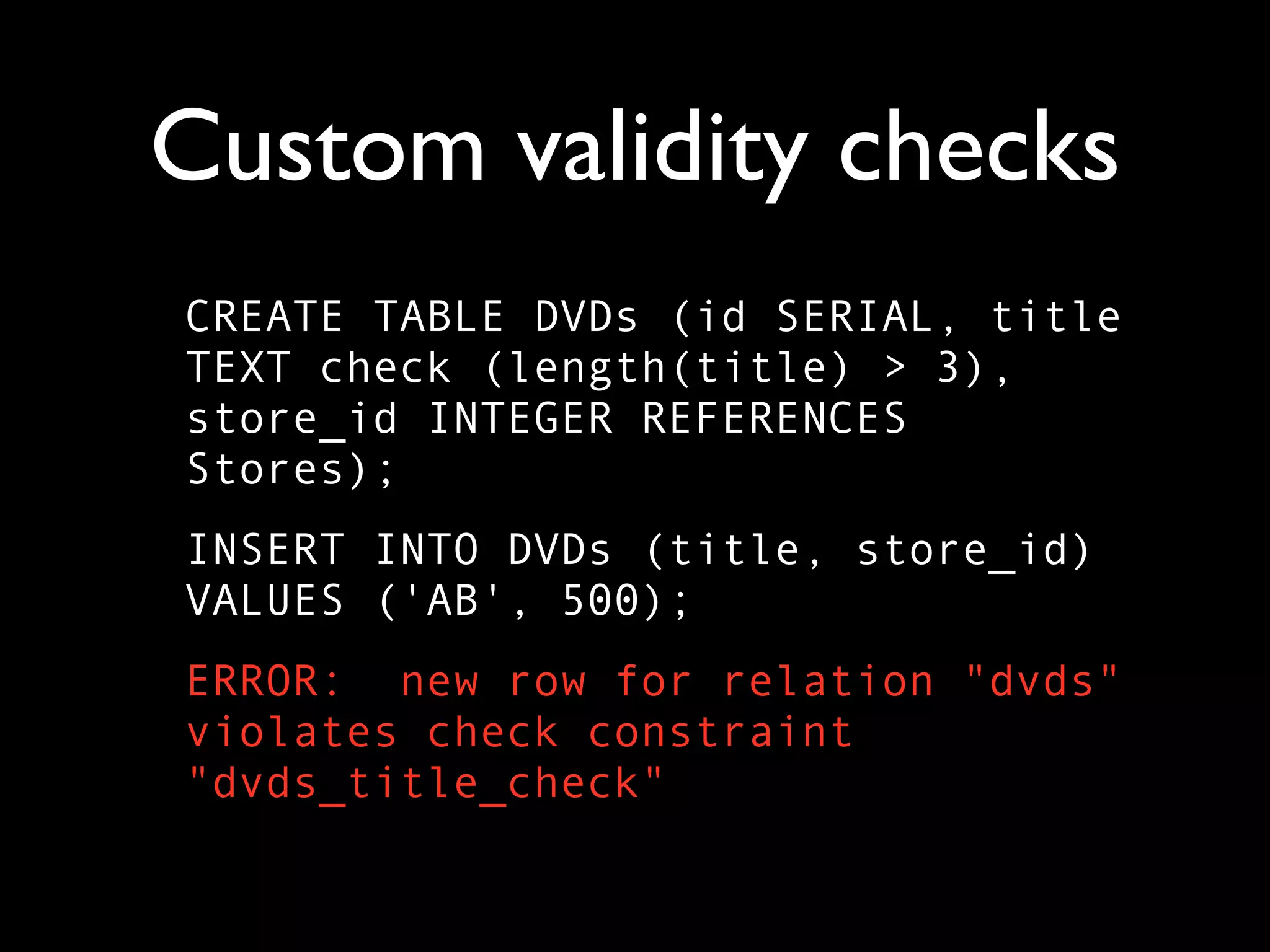
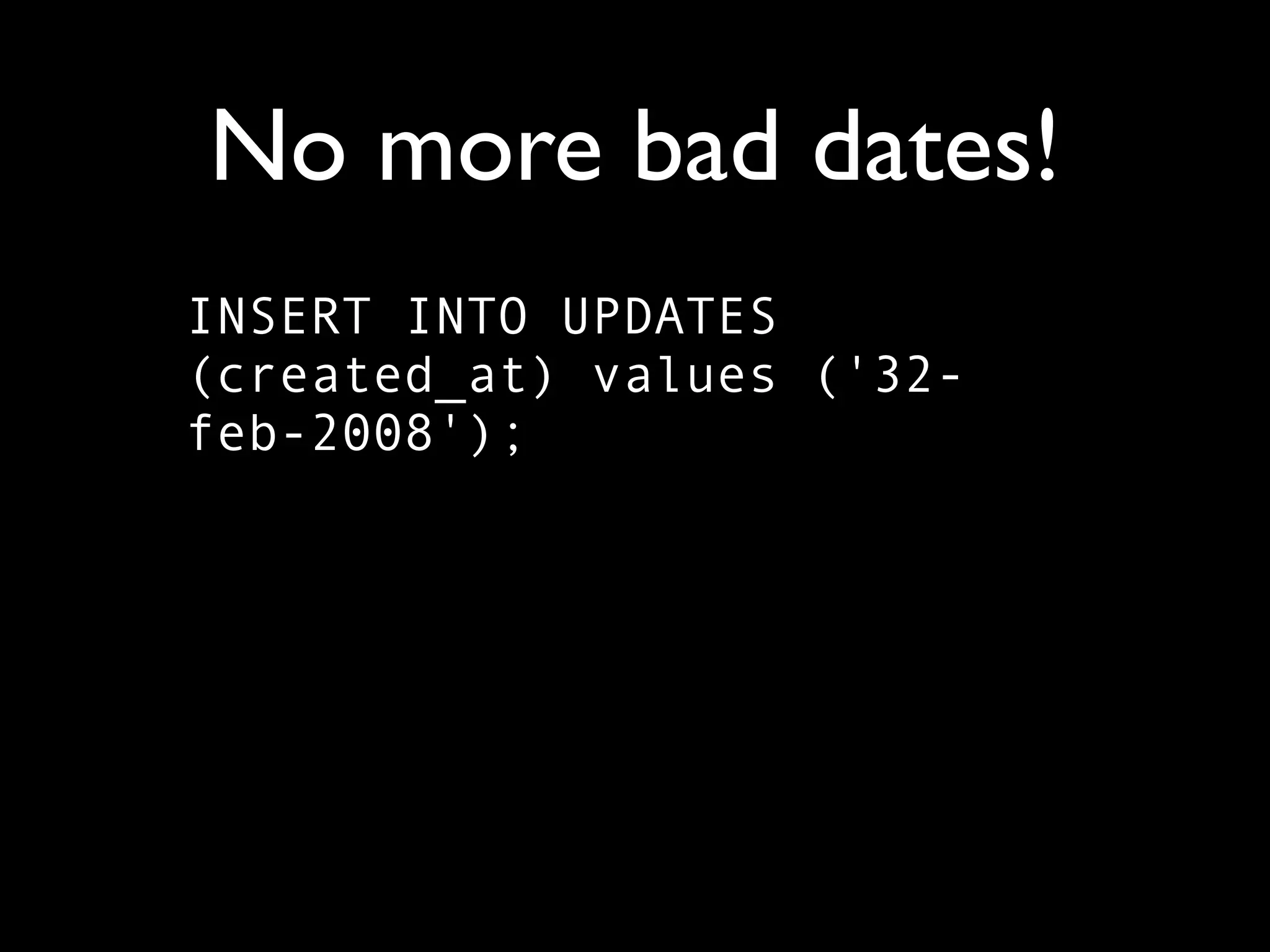
The document is a comprehensive overview of PostgreSQL, detailing its features, advantages over other databases like MySQL, and various functionalities including data types, indexing, and concurrency control. It covers technical aspects such as transactions, custom validity checks, and object-oriented tables, as well as its open-source nature and community support. The author emphasizes PostgreSQL's scalability, reliability, and ease of use for both developers and administrators, alongside a call for further exploration of its capabilities.












![[pgday.Seoul 2022] PostgreSQL구조 - 윤성재](https://cdn.slidesharecdn.com/ss_thumbnails/pgday2022-postgresql-20221112-221114014106-bbfb1955-thumbnail.jpg?width=640&height=640&fit=bounds)










































































