Profile
ブログ : http://blog.processtune.com
プロフィール: Facebook, Twitter or MVP
コミュニティ : .NETラボの運営スタッフ
Microsoft MVP : July 2010 ~ Jun 2022
Current expertise : MVP for Developer Technologies
システム構築のプロセス評価、改善、策定、
開発フレームワークの設計、実装管理、プリ
セールスやプロジェクトの立ち上げなど
#5 ポリグロットパーシステンスは、サービスの特性に合わせた永続化を行うという考え方です。ここで言うサービスの特性とは、書込が多く読込は必要時に行えばいいログとか、大量のデータを速く読込む必要のある分析ツールなど、サービスの目的によって優先させたいストレージ機能が異なることを指します。Azure Data Serviceでのポリグロットパーシステンスの概要は、巻末のリンクを参照してください。【図を解説】
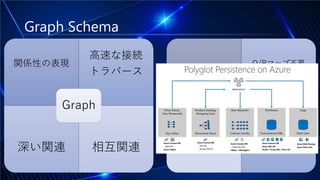
#6 Graphスキーマの場合、前頁でお話した「関係性の表現」「高速な接続トラバース」「深い関連」「相互関連」についてお話していきます。【クリック】
この図は、先ほどお話ししたAzure Data Serviceの記事の絵です。Graphモデルは記載されていませんが、Azureでは、これらの特性に合致したサービスはCosmos DBを使って解決することができます。パフォーマンス、コスト、セキュリティなどの複数の要因からGraphモデルを選択する場合、そのスキーマをどのように実装していくかという設計は、アーキテクチャに依存するものではありませんので、Graphモデルを保持できるデータストレージとそのスキーマにクエリできるミドルウェアであればあらゆる組合せの選択が可能です。今回は特に意味はありませんがneo4jとGremlinを使います。サンプルのユーザーストーリーとしては、複数のポップを行う関連が相互に必要なBIをやってみます。音楽のチャートデータをGraphスキーマに格納して、何かしらの関連が見つかれば関連と関連のレポートを文書化したドキュメントを作成してDocumentモデルのストレージに格納します。
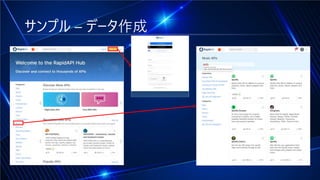
#8 サンプルは、まずデータを作ります。Rapid APIでは多くのOpen Date APIを扱うことができるので、そこで音楽データを収集します。まず、未登録の場合Rapid APIに登録してログインしたらmusicに行き「spotify」を検索します。
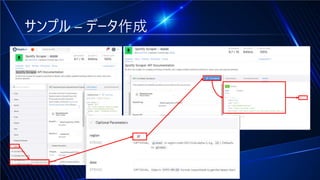
#9 Spotify Scraperを選択して「Chart」の「List Weekly Top Albums」を選択します。真ん中のペインの最下部の「Optional Parameters」の「region」に「JP」を入力してTest Endpointをクリックして200 Successが返ってきたらデータをコピーしてVisual Studio Codeに貼り付けます。
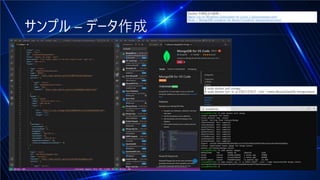
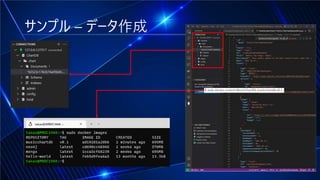
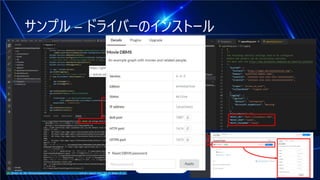
#10 これをひとまずMongo DBに入れておきます。以前.NETラボでお話ししたようにDockerのオフィシャルイメージとVisual Studio CodeのMongoDB Extentionを使います。WSL2で「$ sudo docker pull mongo」と「$ sudo docker run -d -p 27017:27017 --init --name MusicChartDb mongo:latest」を実行します。WLS2やDockerの説明はブログでも解説しています。
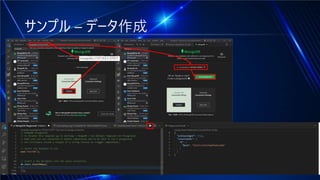
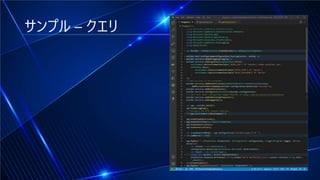
#11 Mongo DBが動いている状態でVisual Studio CodeのMongoDB ExtentionのPlaygroundを作成して編集します。「use(‘ChartDB‘);」で’ChartDBというデータベースが作成され「db.chart.insertMany」のところに先ほど取得したデータをペーストします。Playボタンをクリックして結果が表示されたらOKです。insertManyの括弧の中の鍵括弧の中に全部を貼り付けます。コピーしたJSONは1件ですが、tracksの中に複数の楽曲情報が入っており、該当の週のWeekly Top Songsというデータなので、複数週のデータを格納できますinsertManyで大丈夫です。




















![[db tech showcase Tokyo 2014] D33: Prestoで実現するインタラクティブクエリ by トレジャーデータ株式会社 斉藤太郎](https://cdn.slidesharecdn.com/ss_thumbnails/dbtstokyo2014d33presto-141120012543-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)



















