Downloaded 265 times






























![Map
Set of key value pairs
Similar to HashMap in Java
Key must be unique
Key must be of chararray data type
Values can be any type
Key/value is separated by #
Map is enclosed by []](https://image.slidesharecdn.com/pig-workshop-130413093041-phpapp01/75/Pig-workshop-32-2048.jpg)
![Map - Example
[name#sudar, height#176, weight#80.5F]
[name#(sudar, muthu), height#176, weight#80.5F]
[name#(sudar, muthu), languages#(Java, Pig, Python
)]](https://image.slidesharecdn.com/pig-workshop-130413093041-phpapp01/75/Pig-workshop-33-2048.jpg)

![Schemas in Load statement
We can specify a schema (collection of datatypes) to `LOAD`
statements
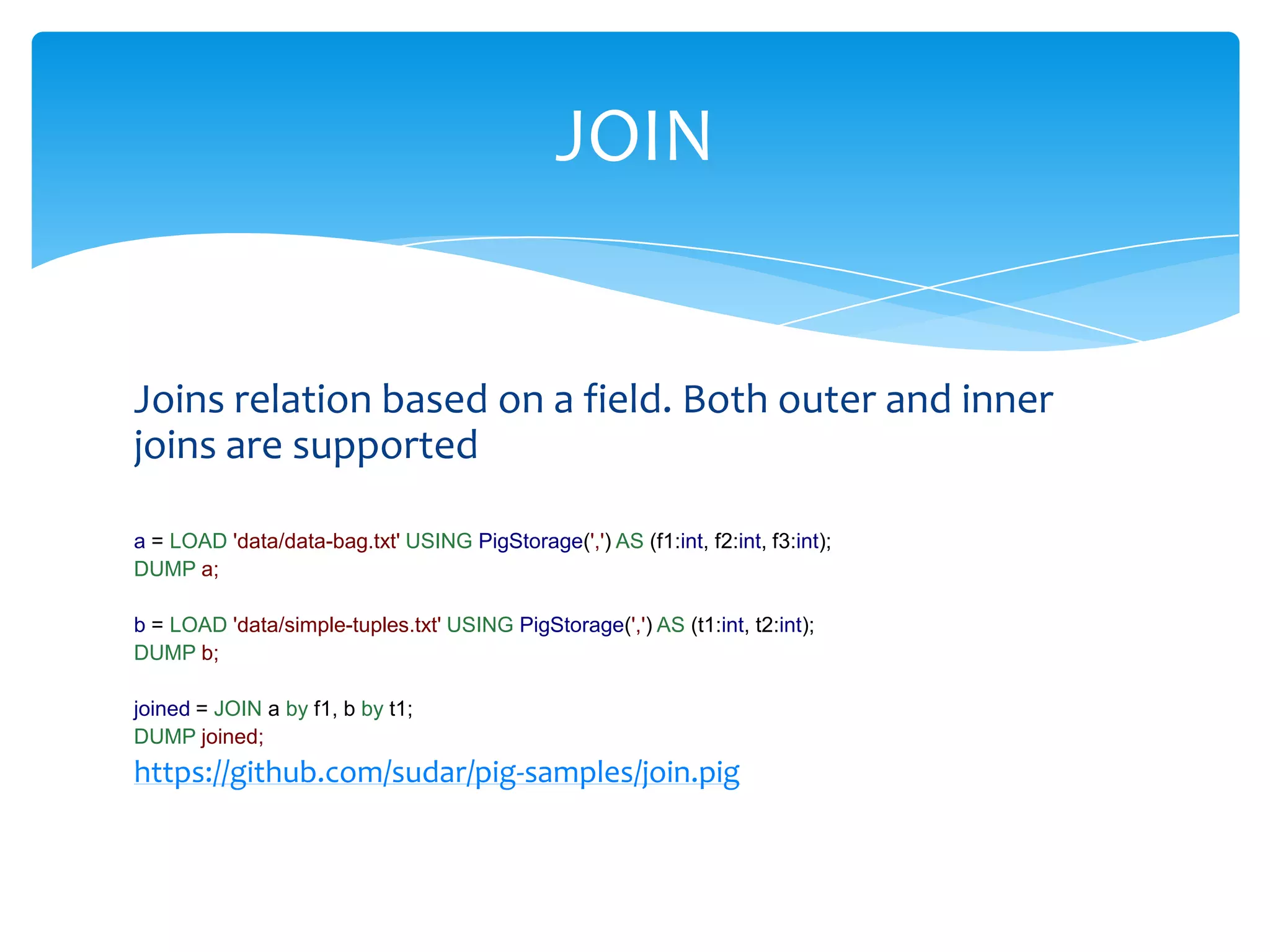
data = LOAD 'data/data-bag.txt' USING PigStorage(',') AS
(f1:int, f2:int, f3:int);
data = LOAD 'data/nested-schema.txt' AS
(f1:int, f2:bag{t:tuple(n1:int, n2:int)}, f3:map[]);](https://image.slidesharecdn.com/pig-workshop-130413093041-phpapp01/75/Pig-workshop-35-2048.jpg)

![Expressions - Example
data = LOAD 'data/nested-schema.txt' AS
(f1:int, f2:bag{t:tuple(n1:int, n2:int)}, f3:map[]);
by_pos = FOREACH data GENERATE $0;
DUMP by_pos;
by_field = FOREACH data GENERATE f2;
DUMP by_field;
by_map = FOREACH data GENERATE f3#'name';
DUMP by_map;
https://github.com/sudar/pig-samples/lookup.pig](https://image.slidesharecdn.com/pig-workshop-130413093041-phpapp01/75/Pig-workshop-37-2048.jpg)









































This document provides information about a Pig workshop being conducted by Sudar Muthu. It introduces Pig, describing it as a platform for analyzing large data sets. It outlines some key Pig components like the Pig Shell, Pig Latin language, libraries, and user defined functions. It also discusses why Pig is useful, highlighting aspects like its data flow model and ability to increase programmer productivity. Finally, it previews topics that will be covered in the workshop, such as loading and storing data, Pig Latin operators, and writing user defined functions.

























![Unit-5 [Pig] working and architecture.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/unit-5pig-240605082042-8125c633-thumbnail.jpg?width=640&height=640&fit=bounds)


















































